Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Cara kerja basis pengetahuan Amazon Bedrock
Amazon Bedrock Knowledge Bases membantu Anda memanfaatkan Retrieval Augmented Generation (RAG), teknik populer yang melibatkan pengambilan informasi dari penyimpanan data untuk menambah respons yang dihasilkan oleh Large Language Models (). LLMs Saat Anda menyiapkan basis pengetahuan dengan sumber data Anda, aplikasi Anda dapat menanyakan basis pengetahuan untuk mengembalikan informasi guna menjawab kueri baik dengan kutipan langsung dari sumber atau dengan respons alami yang dihasilkan dari hasil kueri.
Dengan Pangkalan Pengetahuan Amazon Bedrock, Anda dapat membangun aplikasi yang diperkaya oleh konteks yang diterima dari kueri basis pengetahuan. Ini memungkinkan waktu yang lebih cepat untuk memasarkan dengan mengabstraksi dari pengangkatan pipa bangunan yang berat dan memberi Anda solusi out-of-the-box RAG untuk mengurangi waktu pembuatan aplikasi Anda. Menambahkan basis pengetahuan juga meningkatkan efektivitas biaya dengan menghilangkan kebutuhan untuk terus melatih model Anda untuk dapat memanfaatkan data pribadi Anda.
Diagram berikut menggambarkan secara skematis bagaimana RAG dilakukan. Basis pengetahuan menyederhanakan pengaturan dan implementasi RAG dengan mengotomatiskan beberapa langkah dalam proses ini.
Pra-pemrosesan data tidak terstruktur
Untuk mengaktifkan pengambilan yang efektif dari data pribadi yang tidak terstruktur (data yang tidak ada di penyimpanan data terstruktur), praktik umum adalah mengubah data menjadi teks dan membaginya menjadi potongan-potongan yang dapat dikelola. Potongan atau potongan kemudian dikonversi menjadi embeddings dan ditulis ke indeks vektor, sambil mempertahankan pemetaan ke dokumen asli. Embeddings ini digunakan untuk menentukan kesamaan semantik antara kueri dan teks dari sumber data. Gambar berikut menggambarkan pra-pemrosesan data untuk database vektor.
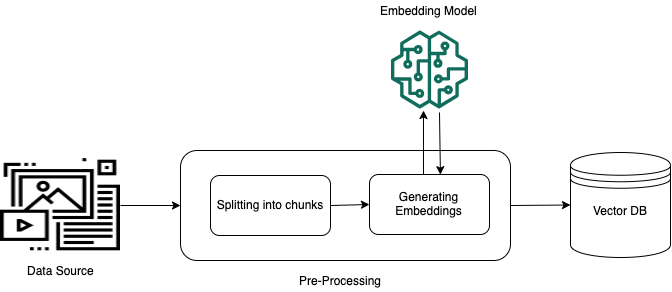
Penyematan vektor adalah serangkaian angka yang mewakili setiap potongan teks. Sebuah model mengubah setiap potongan teks menjadi serangkaian angka, yang dikenal sebagai vektor, sehingga teks dapat dibandingkan secara matematis. Vektor-vektor ini dapat berupa bilangan floating-point (float32) atau bilangan biner. Sebagian besar model embeddings yang didukung oleh Amazon Bedrock menggunakan vektor floating-point secara default. Namun, beberapa model mendukung vektor biner. Jika Anda memilih model penyematan biner, Anda juga harus memilih model dan penyimpanan vektor yang mendukung vektor biner.
Vektor biner, yang hanya menggunakan 1 bit per dimensi, tidak semahal penyimpanan seperti vektor floating-point (float32), yang menggunakan 32 bit per dimensi. Namun, vektor biner tidak setepat vektor floating-point dalam representasi teksnya.
Contoh berikut menunjukkan sepotong teks dalam tiga representasi:
| Representasi | Nilai |
|---|---|
| Teks | “Amazon Bedrock menggunakan model foundation berkinerja tinggi dari perusahaan AI terkemuka dan Amazon.” |
| vektor Floating-point | [0.041..., 0.056..., -0.018..., -0.012..., -0.020...,
...] |
| vektor biner | [1,1,0,0,0, ...] |
Eksekusi runtime
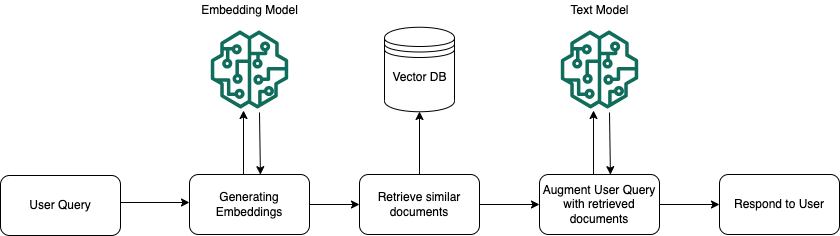
Saat runtime, model embedding digunakan untuk mengonversi kueri pengguna menjadi vektor. Indeks vektor kemudian ditanyakan untuk menemukan potongan yang semantik mirip dengan kueri pengguna dengan membandingkan vektor dokumen dengan vektor kueri pengguna. Pada langkah terakhir, prompt pengguna ditambah dengan konteks tambahan dari potongan yang diambil dari indeks vektor. Prompt di samping konteks tambahan kemudian dikirim ke model untuk menghasilkan respons bagi pengguna. Gambar berikut mengilustrasikan bagaimana RAG beroperasi saat runtime untuk menambah respons terhadap kueri pengguna.
Untuk mempelajari lebih lanjut tentang cara mengubah data Anda menjadi basis pengetahuan, cara menanyakan basis pengetahuan Anda setelah Anda mengaturnya, dan penyesuaian yang dapat Anda terapkan ke sumber data selama proses konsumsi, lihat topik berikut:
Topik
