Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Sentimen yang ditargetkan
Sentimen yang ditargetkan memberikan pemahaman terperinci tentang sentimen yang terkait dengan entitas tertentu (seperti merek atau produk) dalam dokumen masukan Anda.
Perbedaan antara sentimen dan sentimen yang ditargetkan adalah tingkat granularitas dalam data output. Analisis sentimen menentukan sentimen dominan untuk setiap dokumen masukan, tetapi tidak menyediakan data untuk analisis lebih lanjut. Analisis sentimen yang ditargetkan menentukan sentimen tingkat entitas untuk entitas tertentu di setiap dokumen input. Anda dapat menganalisis data output untuk menentukan produk dan layanan tertentu yang mendapatkan umpan balik positif atau negatif.
Misalnya, dalam serangkaian ulasan restoran, pelanggan memberikan ulasan berikut: “Taco itu enak dan stafnya ramah.” Analisis ulasan ini menghasilkan hasil sebagai berikut:
Analisis sentimen menentukan apakah sentimen keseluruhan dari setiap ulasan restoran positif, negatif, netral, atau campuran. Dalam contoh ini, sentimen keseluruhan positif.
Analisis sentimen yang ditargetkan menentukan sentimen untuk entitas dan atribut restoran yang disebutkan pelanggan dalam ulasan. Dalam contoh ini, pelanggan membuat komentar positif tentang “taco” dan “staf”.
Sentimen yang ditargetkan memberikan output berikut untuk setiap pekerjaan analisis:
Identitas entitas yang disebutkan dalam dokumen.
-
Klasifikasi jenis entitas untuk setiap entitas yang disebutkan.
Sentimen dan skor sentimen untuk setiap entitas disebutkan.
Kelompok penyebutan (kelompok referensi bersama) yang sesuai dengan satu entitas.
Anda dapat menggunakan konsol atau API untuk menjalankan analisis sentimen yang ditargetkan. Konsol dan API mendukung analisis real-time dan analisis asinkron untuk sentimen yang ditargetkan.
Amazon Comprehend mendukung sentimen yang ditargetkan untuk dokumen dalam bahasa Inggris.
Untuk informasi tambahan tentang sentimen yang ditargetkan, termasuk tutorial, lihat Ekstrak sentimen granular dalam teks dengan Amazon Comprehend Targeted Sentiment di
Topik
Jenis entitas
Sentimen yang ditargetkan mengidentifikasi jenis entitas berikut. Ini menetapkan jenis entitas OTHER jika entitas tidak termasuk dalam kategori lain. Setiap entitas yang disebutkan dalam file output mencakup jenis entitas, seperti"Type": "PERSON".
| Jenis Entitas | Definisi |
|---|---|
| PRIBADI | Contohnya termasuk individu, kelompok orang, nama panggilan, karakter fiksi, dan nama hewan. |
| LOKASI | Lokasi geografis seperti negara, kota, negara bagian, alamat, formasi geologi, badan air, landmark alam, dan lokasi astronomi. |
| ORGANISASI | Contohnya termasuk pemerintah, perusahaan, tim olahraga, dan agama. |
| FASILITAS | Bangunan, bandara, jalan raya, jembatan, dan struktur buatan manusia permanen lainnya dan perbaikan real estat. |
| MEREK | Organisasi, kelompok, atau produsen barang komersial tertentu atau lini produk. |
| BARANG_KOMERSIAL | Setiap barang non-generik yang dapat dibeli atau diperoleh, termasuk kendaraan, dan produk besar yang hanya memiliki satu barang yang diproduksi. |
| FILM | Sebuah film atau acara televisi. Entitas bisa berupa nama lengkap, nama panggilan, atau subtitle. |
| MUSIK | Sebuah lagu, penuh atau sebagian. Juga, koleksi kreasi musik individu, seperti album atau antologi. |
| BUKU | Sebuah buku, diterbitkan secara profesional atau diterbitkan sendiri. |
| PERANGKAT LUNAK | Produk perangkat lunak yang dirilis secara resmi. |
| GIM | Sebuah permainan, seperti video game, permainan papan, permainan umum, atau olahraga. |
| PERSONAL_TITLE | Gelar dan kehormatan resmi seperti Presiden, PhD, atau Dr. |
| ACARA | Contohnya termasuk festival, konser, pemilihan, perang, konferensi, dan acara promosi. |
| DATE | Setiap referensi ke tanggal atau waktu, apakah spesifik atau umum, apakah absolut atau relatif. |
| KUANTITAS | Semua pengukuran bersama dengan unitnya (mata uang, persen, angka, byte, dll.). |
| TAMBAHAN | Atribut, karakteristik, atau sifat suatu entitas, seperti “kualitas” suatu produk, “harga” telepon, atau “kecepatan” CPU. |
| LAINNYA | Entitas yang tidak termasuk dalam kategori lainnya. |
Kelompok referensi bersama
Sentimen yang ditargetkan mengidentifikasi kelompok referensi bersama di setiap dokumen masukan. Kelompok referensi bersama adalah sekelompok penyebutan dalam dokumen yang sesuai dengan satu entitas dunia nyata.
Dalam contoh ulasan pelanggan berikut, “spa” adalah entitas, yang memiliki tipe entitasFACILITY. Entitas memiliki dua sebutan tambahan sebagai kata ganti (“it”).

Organisasi file keluaran
Pekerjaan analisis sentimen yang ditargetkan membuat file keluaran teks JSON. File berisi satu objek JSON untuk setiap dokumen masukan. Setiap objek JSON berisi bidang-bidang berikut:
-
Entitas — Array entitas yang ditemukan dalam dokumen.
-
File — Nama file dari dokumen input.
-
Baris - Jika file input adalah satu dokumen per baris, Entitas berisi nomor baris dokumen dalam file.
catatan
Jika sentimen yang ditargetkan tidak mengidentifikasi entitas apa pun dalam teks input, ia mengembalikan array kosong sebagai hasil Entitas.
Contoh berikut menunjukkan Entitas untuk file input dengan tiga baris input. Format input adalah ONE_DOC_PER_LINE, sehingga setiap baris input adalah dokumen.
{ "Entities":[
{entityA},
{entityB},
{entityC}
],
"File": "TargetSentimentInputDocs.txt",
"Line": 0
}
{ "Entities": [
{entityD},
{entityE}
],
"File": "TargetSentimentInputDocs.txt",
"Line": 1
}
{ "Entities": [
{entityF},
{entityG}
],
"File": "TargetSentimentInputDocs.txt",
"Line": 2
}Entitas dalam larik Entitas mencakup pengelompokan logis (disebut grup referensi bersama) dari entitas yang disebutkan terdeteksi dalam dokumen. Setiap entitas memiliki struktur keseluruhan sebagai berikut:
{"DescriptiveMentionIndex": [0],
"Mentions": [
{mentionD},
{mentionE}
]
} Entitas berisi bidang-bidang ini:
-
Sebutan — Array penyebutan entitas dalam dokumen. Array mewakili grup referensi bersama. Lihat Kelompok referensi bersama sebagai contoh. Urutan penyebutan dalam array Mentions adalah urutan lokasi mereka (offset) dalam dokumen. Setiap penyebutan mencakup skor sentimen dan skor kelompok untuk penyebutan itu. Skor kelompok menunjukkan tingkat kepercayaan bahwa penyebutan ini milik entitas yang sama.
-
DescriptiveMentionIndex— Satu atau lebih indeks ke dalam array Mentions yang memberikan nama terbaik untuk grup entitas. Misalnya, entitas dapat memiliki tiga sebutan dengan nilai Teks “ABC Hotel,” “ABC Hotel,” dan “it.” Nama terbaik adalah “ABC Hotel,” yang memiliki DescriptiveMentionIndex nilai [0,1].
Setiap penyebutan mencakup bidang-bidang berikut
-
BeginOffset— Offset ke dalam teks dokumen tempat penyebutan dimulai.
-
EndOffset— Offset ke dalam teks dokumen tempat penyebutan berakhir.
GroupScore— Keyakinan bahwa semua entitas yang disebutkan dalam grup berhubungan dengan entitas yang sama.
Teks — Teks dalam dokumen yang mengidentifikasi entitas.
Jenis — Jenis entitas. Amazon Comprehend mendukung berbagai jenis entitas.
Skor — Model keyakinan bahwa entitas relevan. Rentang nilai adalah nol hingga satu, di mana seseorang adalah kepercayaan tertinggi.
MentionSentiment— Berisi sentimen dan skor sentimen untuk disebutkan.
Sentimen — Sentimen penyebutan. Nilai meliputi: POSITIF, NETRAL, NEGATIF, dan CAMPURAN.
SentimentScore— Memberikan kepercayaan model untuk setiap sentimen yang mungkin. Rentang nilai adalah nol hingga satu, di mana seseorang adalah kepercayaan tertinggi.
Nilai Sentimen memiliki arti sebagai berikut:
-
Positif — Entitas menyebutkan sentimen positif.
-
Negatif — Entitas menyebutkan sentimen negatif.
-
Campuran — Entitas menyebutkan sentimen positif dan negatif.
-
Netral — Penyebutan entitas tidak mengungkapkan sentimen positif atau negatif.
Dalam contoh berikut, entitas hanya memiliki satu penyebutan dalam dokumen input, jadi nol (penyebutan pertama dalam array Mentions). DescriptiveMentionIndex Entitas yang diidentifikasi adalah ORANG dengan nama “I.” Skor sentimen netral.
{"Entities":[ { "DescriptiveMentionIndex": [0], "Mentions": [ { "BeginOffset": 0, "EndOffset": 1, "Score": 0.999997, "GroupScore": 1, "Text": "I", "Type": "PERSON", "MentionSentiment": { "Sentiment": "NEUTRAL", "SentimentScore": { "Mixed": 0, "Negative": 0, "Neutral": 1, "Positive": 0 } } } ] } ], "File": "Input.txt", "Line": 0 }
Analisis waktu nyata menggunakan konsol
Anda dapat menggunakan konsol Amazon Comprehend untuk berjalan secara real-time. Sentimen yang ditargetkan Gunakan teks sampel atau tempel teks Anda sendiri ke dalam kotak teks input, lalu pilih Analisis.
Di panel Insights, konsol menampilkan tiga tampilan analisis sentimen yang ditargetkan:
-
Teks yang dianalisis - Menampilkan teks yang dianalisis dan menggarisbawahi setiap entitas. Warna garis bawah menunjukkan nilai sentimen (positif, netral, negatif, atau campuran) yang diberikan analisis ke entitas. Konsol menampilkan pemetaan warna di sudut kanan atas kotak teks yang dianalisis. Jika Anda mengarahkan kursor ke entitas, konsol akan menampilkan panel popup yang berisi nilai analisis (tipe entitas, skor sentimen) untuk entitas.
-
Hasil - Menampilkan tabel yang berisi baris untuk setiap penyebutan entitas yang diidentifikasi dalam teks. Untuk setiap entitas, tabel menunjukkan skor entitas dan entitas. Baris ini juga mencakup sentimen utama dan skor untuk setiap nilai sentimen. Jika ada beberapa sebutan dari entitas yang sama, yang dikenal sebagai aKelompok referensi bersama, tabel menampilkan penyebutan ini sebagai kumpulan baris yang dapat dilipat yang terkait dengan entitas utama.
Jika Anda mengarahkan kursor ke baris entitas dalam tabel Hasil, konsol akan menyoroti penyebutan entitas di panel teks Dianalisis.
-
Integrasi aplikasi - Menampilkan nilai parameter permintaan API dan struktur objek JSON yang dikembalikan dalam respons API. Untuk deskripsi bidang dalam objek JSON, lihatOrganisasi file keluaran.
Contoh analisis real-time konsol
Contoh ini menggunakan teks berikut sebagai input, yang merupakan teks input default yang disediakan konsol.
Hello Zhang Wei, I am John. Your AnyCompany Financial Services, LLC credit card account 1111-0000-1111-0008 has a minimum payment of $24.53 that is due by July 31st. Based on your autopay settings, we will withdraw your payment on the due date from your bank account number XXXXXX1111 with the routing number XXXXX0000. Customer feedback for Sunshine Spa, 123 Main St, Anywhere. Send comments to Alice at sunspa@mail.com. I enjoyed visiting the spa. It was very comfortable but it was also very expensive. The amenities were ok but the service made the spa a great experience.
Panel teks Dianalisis menunjukkan output berikut untuk contoh ini. Arahkan mouse Anda ke teks Zhang Wei untuk melihat panel popup untuk entitas ini.
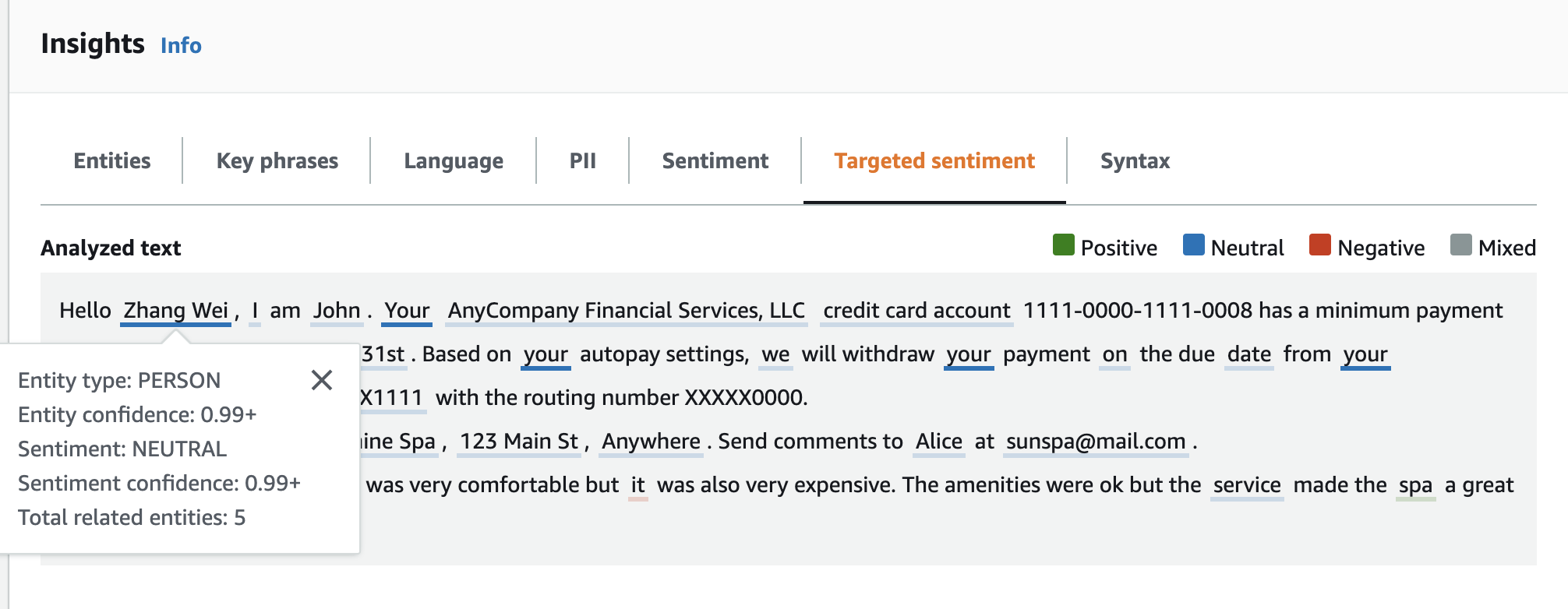
Tabel Hasil memberikan detail tambahan tentang setiap entitas, termasuk skor entitas, sentimen utama, dan skor untuk setiap sentimen.
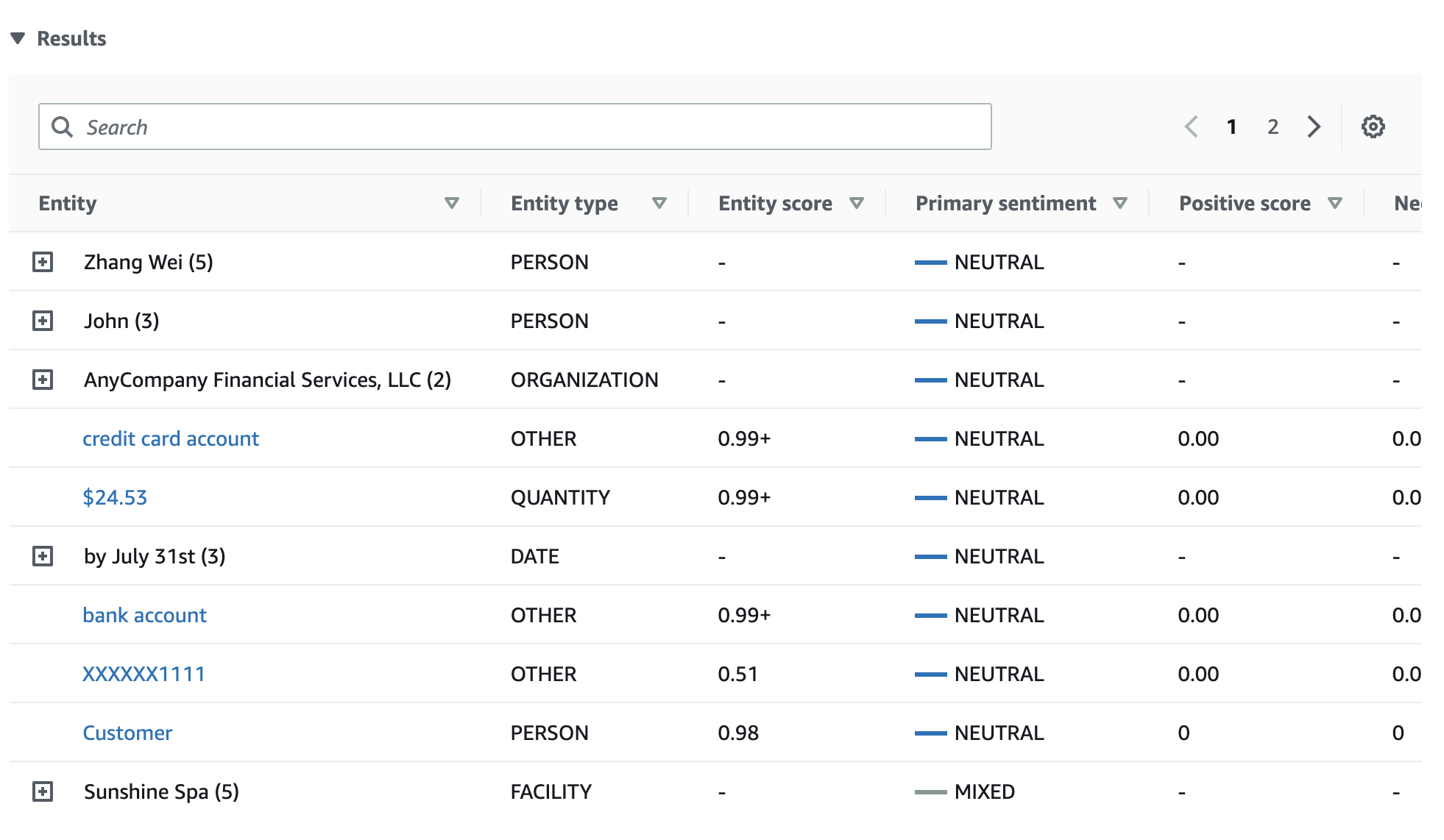
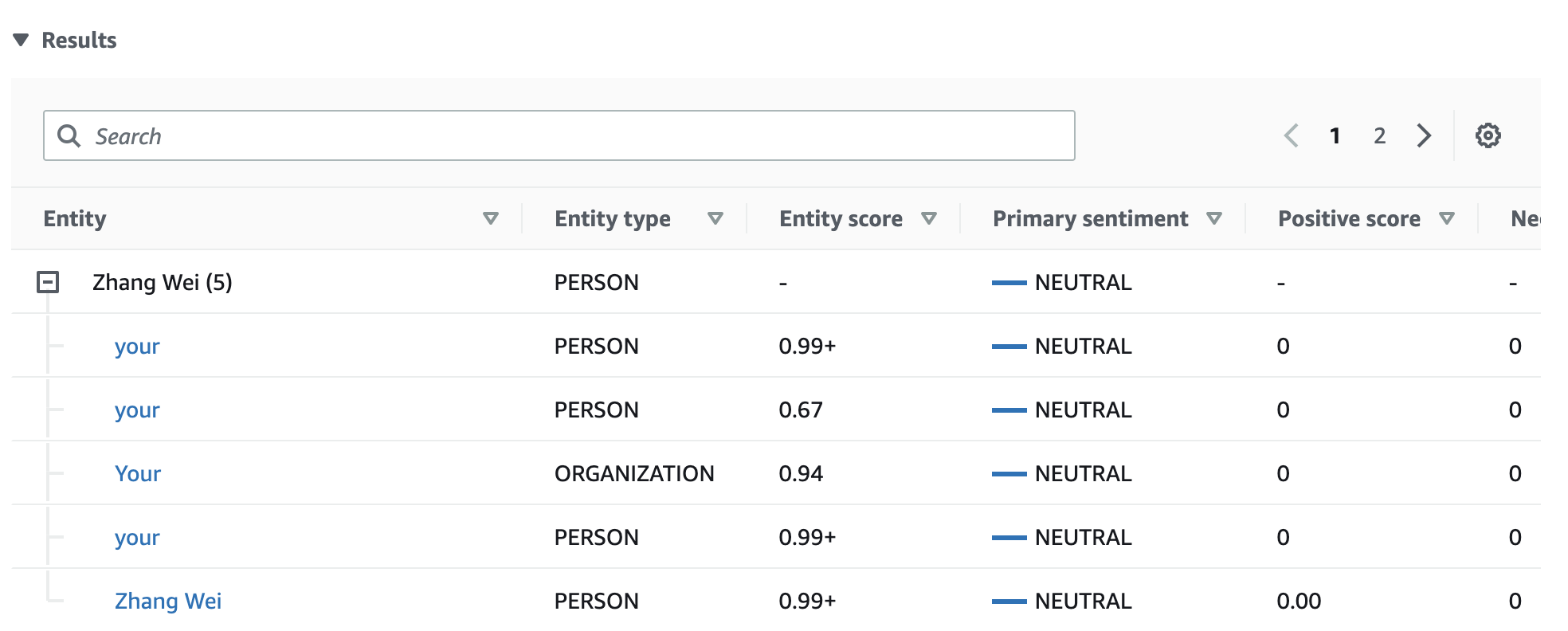
Dalam contoh kami, analisis sentimen yang ditargetkan mengakui bahwa setiap penyebutan Anda dalam teks input adalah referensi ke entitas orang Zhang Wei. Konsol menampilkan penyebutan ini sebagai satu set baris yang dapat dilipat yang terkait dengan entitas utama.
Panel integrasi Aplikasi menampilkan objek JSON yang dihasilkan DetectTargetedSentiment API. Lihat bagian berikut untuk contoh lengkapnya.
Contoh output sentimen yang ditargetkan
Contoh berikut menunjukkan file output dari pekerjaan analisis sentimen yang ditargetkan. File input terdiri dari tiga dokumen sederhana:
The burger was very flavorful and the burger bun was excellent. However, customer service was slow. My burger was good, and it was warm. The burger had plenty of toppings. The burger was cooked perfectly but it was cold. The service was OK.
Analisis sentimen yang ditargetkan dari file input ini menghasilkan output berikut.
{"Entities":[
{
"DescriptiveMentionIndex": [
0
],
"Mentions": [
{
"BeginOffset": 4,
"EndOffset": 10,
"Score": 0.999991,
"GroupScore": 1,
"Text": "burger",
"Type": "OTHER",
"MentionSentiment": {
"Sentiment": "POSITIVE",
"SentimentScore": {
"Mixed": 0,
"Negative": 0,
"Neutral": 0,
"Positive": 1
}
}
}
]
},
{
"DescriptiveMentionIndex": [
0
],
"Mentions": [
{
"BeginOffset": 38,
"EndOffset": 44,
"Score": 1,
"GroupScore": 1,
"Text": "burger",
"Type": "OTHER",
"MentionSentiment": {
"Sentiment": "NEUTRAL",
"SentimentScore": {
"Mixed": 0.000005,
"Negative": 0.000005,
"Neutral": 0.999591,
"Positive": 0.000398
}
}
}
]
},
{
"DescriptiveMentionIndex": [
0
],
"Mentions": [
{
"BeginOffset": 45,
"EndOffset": 48,
"Score": 0.961575,
"GroupScore": 1,
"Text": "bun",
"Type": "OTHER",
"MentionSentiment": {
"Sentiment": "POSITIVE",
"SentimentScore": {
"Mixed": 0.000327,
"Negative": 0.000286,
"Neutral": 0.050269,
"Positive": 0.949118
}
}
}
]
},
{
"DescriptiveMentionIndex": [
0
],
"Mentions": [
{
"BeginOffset": 73,
"EndOffset": 89,
"Score": 0.999988,
"GroupScore": 1,
"Text": "customer service",
"Type": "ATTRIBUTE",
"MentionSentiment": {
"Sentiment": "NEGATIVE",
"SentimentScore": {
"Mixed": 0.000001,
"Negative": 0.999976,
"Neutral": 0.000017,
"Positive": 0.000006
}
}
}
]
}
],
"File": "TargetSentimentInputDocs.txt",
"Line": 0
}
{
"Entities": [
{
"DescriptiveMentionIndex": [
0
],
"Mentions": [
{
"BeginOffset": 0,
"EndOffset": 2,
"Score": 0.99995,
"GroupScore": 1,
"Text": "My",
"Type": "PERSON",
"MentionSentiment": {
"Sentiment": "NEUTRAL",
"SentimentScore": {
"Mixed": 0,
"Negative": 0,
"Neutral": 1,
"Positive": 0
}
}
}
]
},
{
"DescriptiveMentionIndex": [
0,
2
],
"Mentions": [
{
"BeginOffset": 3,
"EndOffset": 9,
"Score": 0.999999,
"GroupScore": 1,
"Text": "burger",
"Type": "OTHER",
"MentionSentiment": {
"Sentiment": "POSITIVE",
"SentimentScore": {
"Mixed": 0.000002,
"Negative": 0.000001,
"Neutral": 0.000003,
"Positive": 0.999994
}
}
},
{
"BeginOffset": 24,
"EndOffset": 26,
"Score": 0.999756,
"GroupScore": 0.999314,
"Text": "it",
"Type": "OTHER",
"MentionSentiment": {
"Sentiment": "POSITIVE",
"SentimentScore": {
"Mixed": 0,
"Negative": 0.000003,
"Neutral": 0.000006,
"Positive": 0.999991
}
}
},
{
"BeginOffset": 41,
"EndOffset": 47,
"Score": 1,
"GroupScore": 0.531342,
"Text": "burger",
"Type": "OTHER",
"MentionSentiment": {
"Sentiment": "POSITIVE",
"SentimentScore": {
"Mixed": 0.000215,
"Negative": 0.000094,
"Neutral": 0.00008,
"Positive": 0.999611
}
}
}
]
},
{
"DescriptiveMentionIndex": [
0
],
"Mentions": [
{
"BeginOffset": 52,
"EndOffset": 58,
"Score": 0.965462,
"GroupScore": 1,
"Text": "plenty",
"Type": "QUANTITY",
"MentionSentiment": {
"Sentiment": "NEUTRAL",
"SentimentScore": {
"Mixed": 0,
"Negative": 0,
"Neutral": 1,
"Positive": 0
}
}
}
]
},
{
"DescriptiveMentionIndex": [
0
],
"Mentions": [
{
"BeginOffset": 62,
"EndOffset": 70,
"Score": 0.998353,
"GroupScore": 1,
"Text": "toppings",
"Type": "OTHER",
"MentionSentiment": {
"Sentiment": "NEUTRAL",
"SentimentScore": {
"Mixed": 0,
"Negative": 0,
"Neutral": 0.999964,
"Positive": 0.000036
}
}
}
]
}
],
"File": "TargetSentimentInputDocs.txt",
"Line": 1
}
{
"Entities": [
{
"DescriptiveMentionIndex": [
0
],
"Mentions": [
{
"BeginOffset": 4,
"EndOffset": 10,
"Score": 1,
"GroupScore": 1,
"Text": "burger",
"Type": "OTHER",
"MentionSentiment": {
"Sentiment": "POSITIVE",
"SentimentScore": {
"Mixed": 0.001515,
"Negative": 0.000822,
"Neutral": 0.000243,
"Positive": 0.99742
}
}
},
{
"BeginOffset": 36,
"EndOffset": 38,
"Score": 0.999843,
"GroupScore": 0.999661,
"Text": "it",
"Type": "OTHER",
"MentionSentiment": {
"Sentiment": "NEGATIVE",
"SentimentScore": {
"Mixed": 0,
"Negative": 0.999996,
"Neutral": 0.000004,
"Positive": 0
}
}
}
]
},
{
"DescriptiveMentionIndex": [
0
],
"Mentions": [
{
"BeginOffset": 53,
"EndOffset": 60,
"Score": 1,
"GroupScore": 1,
"Text": "service",
"Type": "ATTRIBUTE",
"MentionSentiment": {
"Sentiment": "NEUTRAL",
"SentimentScore": {
"Mixed": 0.000033,
"Negative": 0.000089,
"Neutral": 0.993325,
"Positive": 0.006553
}
}
}
]
}
],
"File": "TargetSentimentInputDocs.txt",
"Line": 2
}
}