Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Langkah 4: Mempersiapkan output Amazon Comprehend untuk visualisasi data
Untuk mempersiapkan hasil sentimen dan pekerjaan analisis entitas untuk membuat visualisasi data, Anda menggunakan dan. AWS Glue Amazon Athena Pada langkah ini, Anda mengekstrak file hasil Amazon Comprehend. Kemudian, Anda membuat AWS Glue crawler yang mengeksplorasi data Anda dan secara otomatis mengkatalogkannya dalam tabel di. AWS Glue Data Catalog Setelah itu, Anda mengakses dan mengubah tabel ini menggunakan Amazon Athena, layanan kueri tanpa server dan interaktif. Setelah Anda menyelesaikan langkah ini, hasil Amazon Comprehend Anda bersih dan siap untuk visualisasi.
Untuk pekerjaan deteksi entitas PII, file output adalah plaintext, bukan arsip terkompresi. Nama file output sama dengan file input, dengan .out ditambahkan di akhir. Anda tidak perlu langkah mengekstrak file output. Lewati untuk Memuat Data ke dalam file AWS Glue Data Catalog.
Topik
Prasyarat
Sebelum Anda mulai, selesaikanLangkah 3: Menjalankan pekerjaan analisis pada dokumen di Amazon S3.
Unduh Output
Amazon Comprehend menggunakan kompresi Gzip untuk mengompres file output dan menyimpannya sebagai arsip tar. Cara termudah untuk mengekstrak file output adalah dengan mengunduh output.tar.gz arsip secara lokal.
Pada langkah ini, Anda mengunduh arsip keluaran sentimen dan entitas.
Untuk menemukan file output untuk setiap pekerjaan, kembali ke pekerjaan analisis di konsol Amazon Comprehend. Pekerjaan analisis menyediakan lokasi S3 untuk output, di mana Anda dapat mengunduh file output.
Untuk mengunduh file output (konsol)
-
Di konsol Amazon Comprehend
, di panel navigasi, kembali ke pekerjaan Analisis. -
Pilih pekerjaan
reviews-sentiment-analysisanalisis sentimen Anda. -
Di bawah Keluaran, pilih tautan yang ditampilkan di sebelah Lokasi data keluaran. Ini mengarahkan Anda ke
output.tar.gzarsip di bucket S3 Anda. -
Di tab Ikhtisar, pilih Unduh.
-
Di komputer Anda, ganti nama arsip sebagai
sentiment-output.tar.gz. Karena semua file output memiliki nama yang sama, ini membantu Anda melacak sentimen dan file entitas. -
Ulangi langkah 1-4 untuk menemukan dan mengunduh output dari
reviews-entities-analysispekerjaan Anda. Di komputer Anda, ganti nama arsip sebagaientities-output.tar.gz.
Untuk menemukan file output untuk setiap pekerjaan, gunakan JobId dari pekerjaan analisis untuk menemukan lokasi S3 output. Kemudian, gunakan cp perintah untuk mengunduh file output ke komputer Anda.
Untuk mengunduh file output (AWS CLI)
-
Untuk membuat daftar detail tentang pekerjaan analisis sentimen Anda, jalankan perintah berikut. Ganti
sentiment-job-idJobIdyang Anda simpan.aws comprehend describe-sentiment-detection-job --job-idsentiment-job-idJika Anda kehilangan jejak Anda
JobId, Anda dapat menjalankan perintah berikut untuk membuat daftar semua pekerjaan sentimen Anda dan memfilter untuk pekerjaan Anda berdasarkan nama.aws comprehend list-sentiment-detection-jobs --filter JobName="reviews-sentiment-analysis" -
Di
OutputDataConfigobjek, temukanS3Urinilainya.S3UriNilainya harus mirip dengan format berikut:s3://amzn-s3-demo-bucket/.../output/output.tar.gz -
Untuk mengunduh arsip keluaran sentimen ke direktori lokal Anda, jalankan perintah berikut. Ganti jalur bucket S3 dengan yang
S3UriAnda salin di langkah sebelumnya. Gantipath/sentiment-output.tar.gzmenggantikan nama arsip asli untuk membantu Anda melacak sentimen dan file entitas.aws s3 cps3://amzn-s3-demo-bucket/.../output/output.tar.gzpath/sentiment-output.tar.gz -
Untuk membuat daftar detail tentang pekerjaan analisis entitas Anda, jalankan perintah berikut.
aws comprehend describe-entities-detection-job --job-identities-job-idJika Anda tidak tahu
JobId, jalankan perintah berikut untuk daftar semua pekerjaan entitas Anda dan filter untuk pekerjaan Anda berdasarkan nama.aws comprehend list-entities-detection-jobs --filter JobName="reviews-entities-analysis" -
Dari
OutputDataConfigobjek dalam deskripsi pekerjaan entitas Anda, salinS3Urinilainya. -
Untuk mengunduh arsip keluaran entitas ke direktori lokal Anda, jalankan perintah berikut. Ganti jalur bucket S3 dengan yang
S3UriAnda salin di langkah sebelumnya. Gantipath/entities-output.tar.gzmenggantikan nama arsip asli.aws s3 cps3://amzn-s3-demo-bucket/.../output/output.tar.gzpath/entities-output.tar.gz
Ekstrak file output
Sebelum Anda dapat mengakses hasil Amazon Comprehend, buka paket sentimen dan arsip entitas. Anda dapat menggunakan sistem file lokal atau terminal untuk membongkar arsip.
Jika Anda menggunakan macOS, klik dua kali arsip di sistem file GUI Anda untuk mengekstrak file keluaran dari arsip.
Jika Anda menggunakan Windows, Anda dapat menggunakan alat pihak ketiga seperti 7-Zip untuk mengekstrak file output dalam sistem file GUI Anda. Di Windows, Anda harus melakukan dua langkah untuk mengakses file output dalam arsip. Pertama dekompresi arsip, dan kemudian ekstrak arsip.
Ubah nama file sentimen sebagai sentiment-output dan file entitas entities-output untuk membedakan antara file output.
Jika Anda menggunakan Linux atau macOS, Anda dapat menggunakan terminal standar Anda. Jika Anda menggunakan Windows, Anda harus memiliki akses ke Unix-style lingkungan, seperti Cygwin, untuk menjalankan perintah tar.
Untuk mengekstrak file output sentimen dari arsip sentimen, jalankan perintah berikut di terminal lokal Anda.
tar -xvf sentiment-output.tar.gz --transform 's,^,sentiment-,'
Perhatikan bahwa --transform parameter menambahkan awalan sentiment- ke file output di dalam arsip, mengganti nama file sebagai. sentiment-output Hal ini memungkinkan Anda untuk membedakan antara sentimen dan entitas output file dan mencegah penimpaan.
Untuk mengekstrak file keluaran entitas dari arsip entitas, jalankan perintah berikut di terminal lokal Anda.
tar -xvf entities-output.tar.gz --transform 's,^,entities-,'
--transformParameter menambahkan awalan entities- ke nama file output.
Tip
Untuk menghemat biaya penyimpanan di Amazon S3, Anda dapat mengompres file lagi dengan Gzip sebelum mengunggahnya. Sangat penting untuk mendekompresi dan membongkar arsip asli karena tidak AWS Glue dapat secara otomatis membaca data dari arsip tar. Namun, AWS Glue dapat membaca dari file dalam format Gzip.
Unggah file yang diekstrak
Setelah mengekstrak file, unggah ke bucket Anda. Anda harus menyimpan sentimen dan entitas output file dalam folder terpisah AWS Glue agar dapat membaca data dengan benar. Di bucket Anda, buat folder untuk hasil sentimen yang diekstraksi dan folder kedua untuk hasil entitas yang diekstrak. Anda dapat membuat folder baik dengan konsol Amazon S3 atau. AWS CLI
Di bucket S3 Anda, buat satu folder untuk file hasil sentimen yang diekstraksi dan satu folder untuk file hasil entitas. Kemudian, unggah file hasil yang diekstrak ke folder masing-masing.
Untuk mengunggah file yang diekstrak ke Amazon S3 (konsol)
Buka konsol Amazon S3 di. https://console.aws.amazon.com/s3/
-
Di Bucket, pilih bucket Anda lalu pilih Buat folder.
-
Untuk nama folder baru, masukkan
sentiment-resultsdan pilih Simpan. Folder ini akan berisi file output sentimen yang diekstraksi. -
Di tab Ikhtisar bucket Anda, dari daftar isi bucket, pilih folder baru
sentiment-results. Pilih Unggah. -
Pilih Tambahkan file, pilih
sentiment-outputfile dari komputer lokal Anda, lalu pilih Berikutnya. -
Biarkan opsi untuk Kelola pengguna, Akses untuk lainnya Akun AWS, dan Kelola izin publik sebagai default. Pilih Berikutnya.
-
Untuk kelas Storage, pilih Standard. Biarkan opsi untuk Enkripsi, Metadata, dan Tag sebagai default. Pilih Berikutnya.
-
Tinjau opsi unggah lalu pilih Unggah.
-
Ulangi langkah 1-8 untuk membuat folder bernama
entities-results, dan unggahentities-outputfile ke sana.
Anda dapat membuat folder di bucket S3 Anda saat mengunggah file dengan perintah. cp
Untuk mengunggah file yang diekstrak ke Amazon AWS CLI S3 ()
-
Buat folder sentimen dan unggah file sentimen Anda ke sana dengan menjalankan perintah berikut. Ganti
path/aws s3 cppath/sentiment-output s3://amzn-s3-demo-bucket/sentiment-results/ -
Buat folder keluaran entitas dan unggah file entitas Anda ke sana dengan menjalankan perintah berikut. Ganti
path/aws s3 cppath/entities-output s3://amzn-s3-demo-bucket/entities-results/
Memuat data ke dalam AWS Glue Data Catalog
Untuk mendapatkan hasil ke dalam database, Anda dapat menggunakan AWS Glue crawler. AWS Glue Crawler memindai file dan menemukan skema data. Kemudian mengatur data dalam tabel dalam AWS Glue Data Catalog (database tanpa server). Anda dapat membuat crawler dengan AWS Glue konsol atau file. AWS CLI
Buat AWS Glue crawler yang memindai entities-results folder sentiment-results dan folder Anda secara terpisah. Peran IAM baru untuk AWS Glue
memberikan izin crawler untuk mengakses bucket S3 Anda. Anda membuat peran IAM ini saat menyiapkan crawler.
Untuk memuat data ke dalam AWS Glue Data Catalog (konsol)
-
Pastikan Anda berada di wilayah yang mendukung AWS Glue. Jika Anda berada di Wilayah lain, di bilah navigasi, pilih Wilayah yang didukung dari pemilih Wilayah. Untuk daftar Wilayah yang mendukung AWS Glue, lihat Tabel Wilayah
di Panduan Infrastruktur Global. Buka AWS Glue konsol di https://console.aws.amazon.com/glue/
. -
Di panel navigasi, pilih Crawler dan kemudian pilih Tambah crawler.
-
Untuk nama Crawler, masukkan
comprehend-analysis-crawlerlalu pilih Berikutnya. -
Untuk tipe sumber Crawler, pilih Penyimpanan data dan kemudian pilih Berikutnya.
-
Untuk Tambahkan penyimpanan data, lakukan hal berikut:
-
Untuk Pilih penyimpanan data, pilih S3.
-
Biarkan Koneksi kosong.
-
Untuk Merayapi data di, pilih Jalur yang ditentukan di akun saya.
-
Untuk jalur Sertakan, masukkan jalur S3 lengkap dari folder keluaran sentimen:.
s3://amzn-s3-demo-bucket/sentiment-results -
Pilih Berikutnya.
-
-
Untuk Tambahkan penyimpanan data lain, pilih Ya dan kemudian pilih Berikutnya. Ulangi Langkah 6, tetapi masukkan jalur S3 lengkap dari folder keluaran entitas:
s3://amzn-s3-demo-bucket/entities-results. -
Untuk Tambahkan penyimpanan data lain, pilih Tidak, lalu pilih Berikutnya.
-
Untuk Pilih peran IAM, lakukan hal berikut:
-
Pilih Buat peran IAM.
-
Untuk peran IAM, masukkan
glue-access-rolelalu pilih Berikutnya.
-
-
Untuk Buat jadwal untuk crawler ini, pilih Jalankan sesuai permintaan dan pilih Berikutnya.
-
Untuk Mengkonfigurasi output crawler, lakukan hal berikut:
-
Untuk Database, pilih Tambah database.
-
Untuk nama Database, masukkan
comprehend-results. Database ini akan menyimpan tabel keluaran Amazon Comprehend Anda. -
Biarkan opsi lain pada pengaturan default mereka dan pilih Berikutnya.
-
-
Tinjau informasi crawler lalu pilih Selesai.
-
Di konsol Glue, di Crawler, pilih
comprehend-analysis-crawlerdan pilih Run crawler. Diperlukan beberapa menit agar crawler selesai.
Buat peran IAM AWS Glue yang memberikan izin untuk mengakses bucket S3 Anda. Kemudian, buat database di AWS Glue Data Catalog. Terakhir, buat dan jalankan crawler yang memuat data Anda ke dalam tabel di database.
Untuk memuat data ke dalam AWS Glue Data Catalog (AWS CLI)
-
Untuk membuat peran IAM AWS Glue, lakukan hal berikut:
-
Simpan kebijakan kepercayaan berikut sebagai dokumen JSON yang dipanggil
glue-trust-policy.jsondi komputer Anda. -
Untuk membuat peran IAM, jalankan perintah berikut. Ganti
path/aws iam create-role --role-name glue-access-role --assume-role-policy-document file://path/glue-trust-policy.json -
Saat AWS CLI mencantumkan Nomor Sumber Daya Amazon (ARN) untuk peran baru, salin dan simpan ke editor teks.
-
Simpan kebijakan IAM berikut sebagai dokumen JSON yang dipanggil
glue-access-policy.jsondi komputer Anda. Kebijakan memberikan AWS Glue izin untuk meng-crawl folder hasil Anda. -
Untuk membuat kebijakan IAM, jalankan perintah berikut. Ganti
path/aws iam create-policy --policy-name glue-access-policy --policy-document file://path/glue-access-policy.json -
Saat AWS CLI mencantumkan ARN kebijakan akses, salin dan simpan ke editor teks.
-
Lampirkan kebijakan baru ke peran IAM dengan menjalankan perintah berikut. Ganti
policy-arnaws iam attach-role-policy --policy-arnpolicy-arn--role-name glue-access-role -
Lampirkan kebijakan AWS terkelola
AWSGlueServiceRoleke peran IAM Anda dengan menjalankan perintah berikut.aws iam attach-role-policy --policy-arn arn:aws:iam::aws:policy/service-role/AWSGlueServiceRole --role-name glue-access-role
-
-
Buat AWS Glue database dengan menjalankan perintah berikut.
aws glue create-database --database-input Name="comprehend-results" -
Buat AWS Glue crawler baru dengan menjalankan perintah berikut. Ganti
glue-iam-role-arnaws glue create-crawler --name comprehend-analysis-crawler --roleglue-iam-role-arn--targets S3Targets=[ {Path="s3://amzn-s3-demo-bucket/sentiment-results"}, {Path="s3://amzn-s3-demo-bucket/entities-results"}] --database-name comprehend-results -
Mulai crawler dengan menjalankan perintah berikut.
aws glue start-crawler --name comprehend-analysis-crawlerDiperlukan beberapa menit agar crawler selesai.
Siapkan data untuk analisis
Sekarang Anda memiliki database yang diisi dengan hasil Amazon Comprehend. Namun, hasilnya bersarang. Untuk melepaskannya, Anda menjalankan beberapa pernyataan SQL di. Amazon Athena Amazon Athena adalah layanan kueri interaktif yang memudahkan untuk menganalisis data di Amazon S3 menggunakan SQL standar. Athena tanpa server, jadi tidak ada infrastruktur untuk dikelola dan memiliki model harga bayar per kueri. Pada langkah ini, Anda membuat tabel baru data dibersihkan yang dapat Anda gunakan untuk analisis dan visualisasi. Anda menggunakan konsol Athena untuk menyiapkan data.
Untuk menyiapkan data
Buka konsol Athena di https://console.aws.amazon.com/athena/
. -
Di editor kueri, pilih Pengaturan, lalu pilih Kelola.
-
Untuk Lokasi hasil kueri, masukkan
s3://amzn-s3-demo-bucket/query-results/. Ini membuat folder baru yang disebutquery-resultsdi bucket Anda yang menyimpan output Amazon Athena kueri yang Anda jalankan. Pilih Simpan. -
Di editor kueri, pilih Editor.
-
Untuk Database, pilih AWS Glue database
comprehend-resultsyang Anda buat. -
Di bagian Tabel, Anda harus memiliki dua tabel yang disebut
sentiment_resultsdanentities_results. Pratinjau tabel untuk memastikan bahwa crawler memuat data. Dalam opsi setiap tabel (tiga titik di sebelah nama tabel), pilih tabel Pratinjau. Kueri singkat berjalan secara otomatis. Periksa panel Hasil untuk memastikan bahwa tabel berisi data.Tip
Jika tabel tidak memiliki data apa pun, coba periksa folder di bucket S3 Anda. Pastikan ada satu folder untuk hasil entitas dan satu folder untuk hasil sentimen. Kemudian, coba jalankan AWS Glue crawler baru.
-
Untuk membuka
sentiment_resultstabel, masukkan kueri berikut di editor Query dan pilih Run.CREATE TABLE sentiment_results_final AS SELECT file, line, sentiment, sentimentscore.mixed AS mixed, sentimentscore.negative AS negative, sentimentscore.neutral AS neutral, sentimentscore.positive AS positive FROM sentiment_results -
Untuk memulai unnesting tabel entitas, masukkan kueri berikut di editor Query dan pilih Run.
CREATE TABLE entities_results_1 AS SELECT file, line, nested FROM entities_results CROSS JOIN UNNEST(entities) as t(nested) -
Untuk menyelesaikan unnesting tabel entitas, masukkan kueri berikut di editor Query dan pilih Run query.
CREATE TABLE entities_results_final AS SELECT file, line, nested.beginoffset AS beginoffset, nested.endoffset AS endoffset, nested.score AS score, nested.text AS entity, nested.type AS category FROM entities_results_1
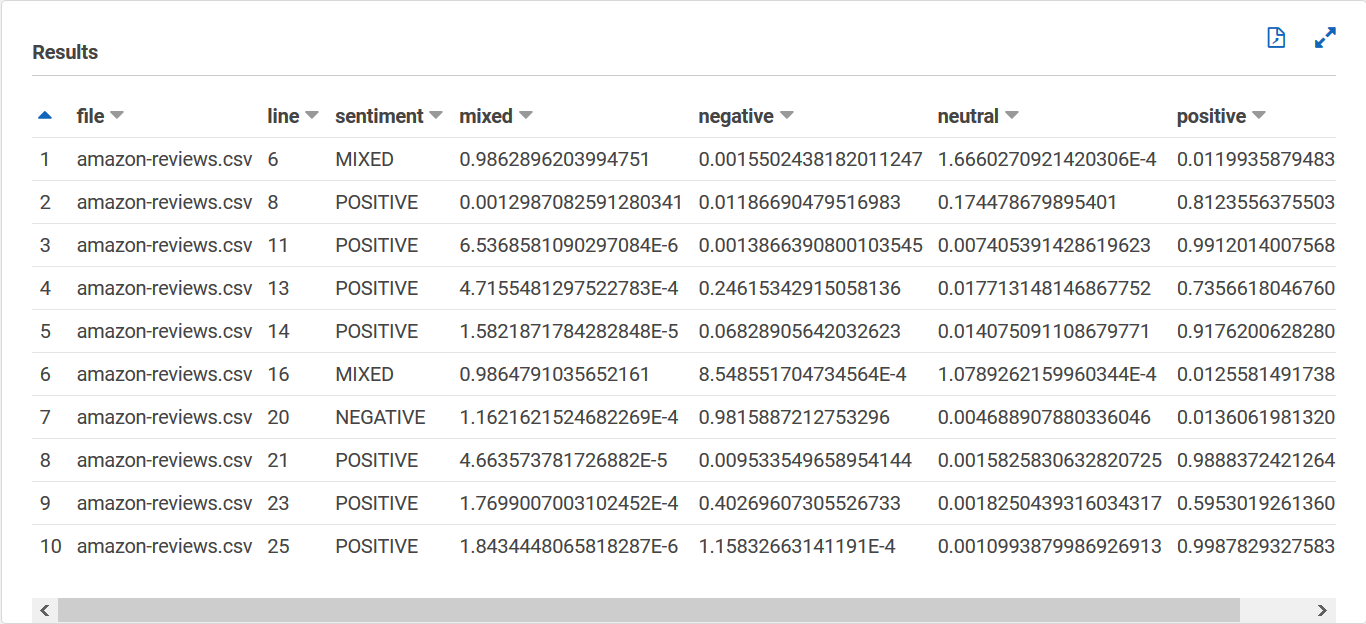
sentiment_results_finalTabel Anda akan terlihat seperti berikut ini, dengan kolom bernama file, baris, sentimen, campuran, negatif, netral, dan positif. Tabel harus memiliki satu nilai per sel. Kolom sentimen menggambarkan sentimen keseluruhan yang paling mungkin dari tinjauan tertentu. Kolom campuran, negatif, netral, dan positif memberikan skor untuk setiap jenis sentimen.
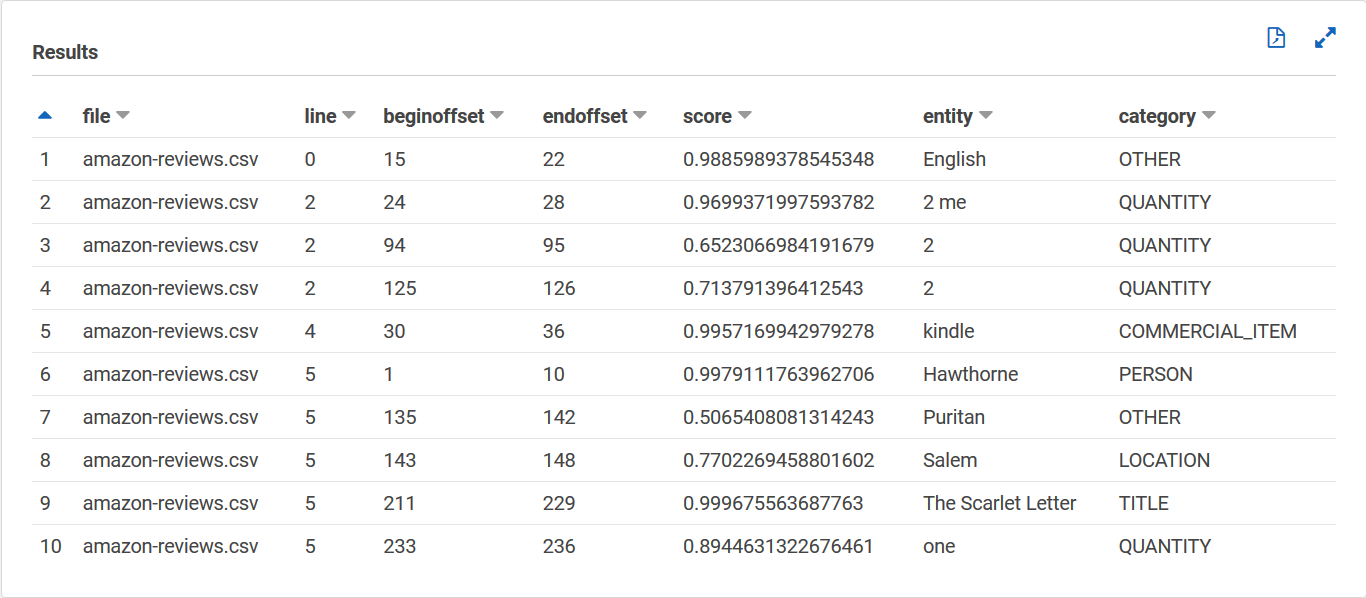
entities_results_finalTabel Anda akan terlihat seperti berikut ini, dengan kolom bernama file, baris, beginoffset, endoffset, skor, entitas, dan kategori. Tabel harus memiliki satu nilai per sel. Kolom skor menunjukkan kepercayaan Amazon Comprehend pada entitas yang dideteksi. Kategori menunjukkan jenis entitas apa yang Comprehend terdeteksi.
Sekarang setelah hasil Amazon Comprehend dimuat ke dalam tabel, Anda dapat memvisualisasikan dan mengekstrak wawasan yang berarti dari data.
