Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Pembelajaran penguatan di AWS DeepRacer
Dalam pembelajaran penguatan, agen, seperti DeepRacer kendaraan AWS fisik atau virtual, dengan tujuan untuk mencapai tujuan yang dimaksudkan berinteraksi dengan lingkungan untuk memaksimalkan hadiah total agen. Agen mengambil tindakan, dipandu oleh strategi yang disebut sebagai kebijakan, pada status lingkungan tertentu dan mencapai status baru. Ada penghargaan langsung yang terkait dengan tindakan apa pun. Penghargaan adalah ukuran keinginan tindakan. Penghargaan langsung ini dianggap dikembalikan oleh lingkungan.
Tujuan dari pembelajaran penguatan di AWS DeepRacer adalah untuk mempelajari kebijakan optimal di lingkungan tertentu. Belajar adalah proses berulang dari uji coba dan kesalahan. Agen mengambil tindakan awal acak untuk sampai pada status baru. Kemudian agen mengulangi langkah dari status baru ke berikutnya. Seiring waktu, agen menemukan tindakan yang mengarah pada imbalan jangka panjang maksimum. Interaksi agen dari status awal ke status terminal disebut episode.
Sketsa berikut menggambarkan proses pembelajaran ini:
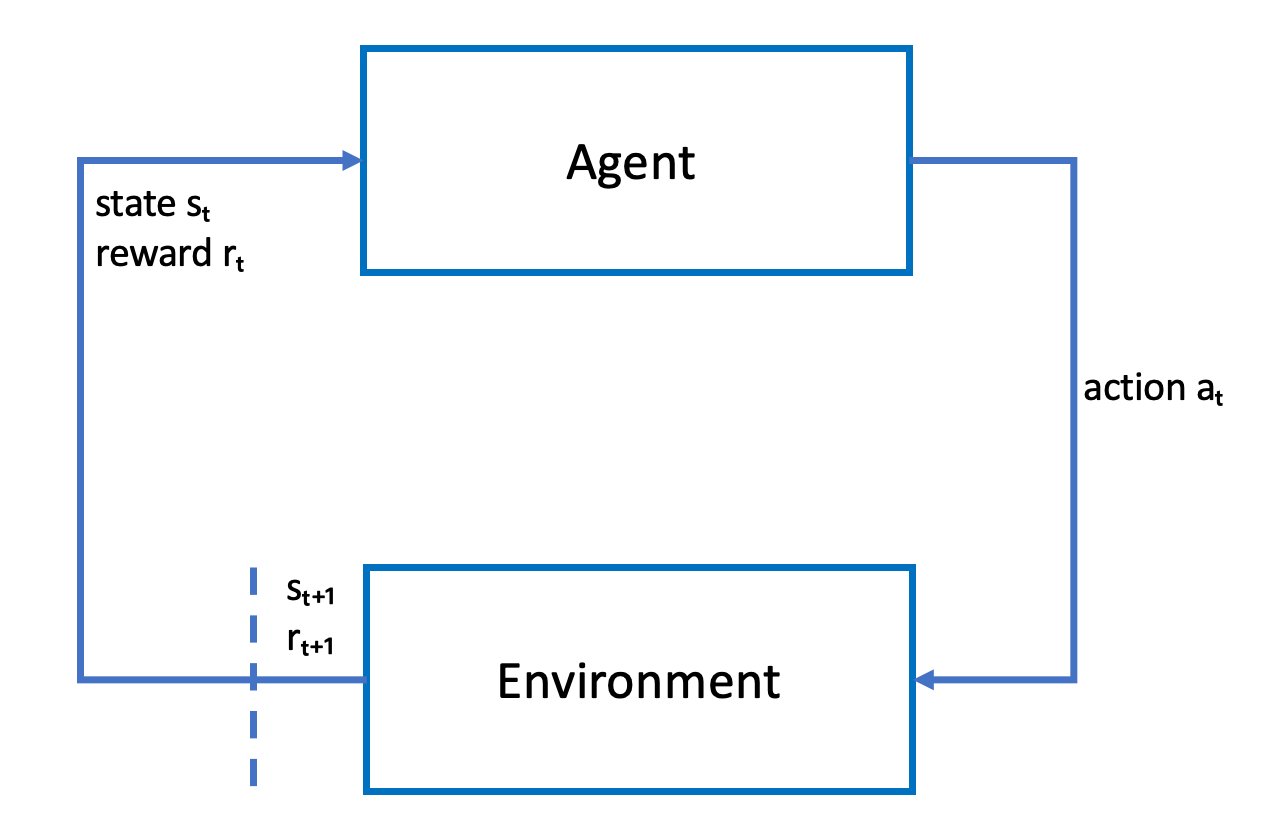
Agen mewujudkan jaringan neural yang mewakili fungsi untuk mendekati kebijakan agen. Gambar dari kamera depan kendaraan adalah status lingkungan dan tindakan agen ditentukan oleh kecepatan agen dan sudut kemudi.
Agen menerima penghargaan positif jika tetap di lintasan untuk menyelesaikan balapan dan penghargaan negatif untuk keluar lintasan. Sebuah episode dimulai dengan agen di suatu tempat di lintasan balap dan berakhir ketika agen keluar lintasan atau menyelesaikan satu putaran.
catatan
Sebenarnya, status lingkungan mengacu pada segala sesuatu yang relevan dengan masalah. Misalnya, posisi kendaraan di lintasan serta bentuk lintasan. Gambar yang diumpankan melalui kamera yang dipasang di bagian depan kendaraan tidak menangkap seluruh keadaan lingkungan. Untuk alasan ini, lingkungan dianggap sebagian diamati dan input ke agen disebut sebagai pengamatan daripada keadaan. Untuk kesederhanaan, kami menggunakan status dan observasi secara bergantian di seluruh dokumentasi ini.
Pelatihan agen di lingkungan simulasi memiliki keuntungan sebagai berikut:
-
Simulasi dapat memperkirakan seberapa banyak kemajuan yang telah dibuat agen dan mengidentifikasi kapan ia keluar lintasan untuk komputasi penghargaan.
-
Simulasi membebaskan pelatih dari tugas-tugas yang membosankan untuk mengatur ulang kendaraan setiap kali keluar lintasan, seperti yang dilakukan di lingkungan fisik.
-
Simulasi dapat mempercepat pelatihan.
-
Simulasi memberikan kontrol yang lebih baik terhadap kondisi lingkungan, misalnya memilih trek, latar belakang, dan kondisi kendaraan yang berbeda.
Alternatif untuk pembelajaran penguatan adalah pembelajaran yang diawasi, juga disebut sebagai pembelajaran imitasi. Di sini set data yang diketahui (dari tupel [gambar, tindakan]) yang dikumpulkan dari lingkungan tertentu digunakan untuk melatih agen. Model yang dilatih melalui pembelajaran imitasi dapat diterapkan untuk mengemudi sendiri. Model dan agen bekerja dengan baik hanya jika gambar dari kamera terlihat mirip dengan gambar dalam set data pelatihan. Untuk mengemudi yang tangguh, set data pelatihan harus komprehensif. Sebaliknya, pembelajaran penguatan tidak memerlukan upaya pelabelan yang ekstensif dan dapat dilatih sepenuhnya dalam simulasi. Karena pembelajaran penguatan dimulai dengan tindakan acak, agen mempelajari berbagai lingkungan dan kondisi lintasan. Hal ini membuat model yang terlatih tangguh.
