Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Praktik Terbaik untuk Keandalan
Bagian ini memberikan panduan tentang membuat beban kerja berjalan di EKS tangguh dan sangat tersedia
Cara menggunakan panduan ini
Panduan ini ditujukan untuk pengembang dan arsitek yang ingin mengembangkan dan mengoperasikan layanan yang sangat tersedia dan toleran terhadap kesalahan di EKS. Panduan ini diatur ke dalam area topik yang berbeda untuk konsumsi yang lebih mudah. Setiap topik dimulai dengan ikhtisar singkat, diikuti dengan daftar rekomendasi dan praktik terbaik untuk keandalan kluster EKS Anda.
Pengantar
Praktik terbaik keandalan untuk EKS telah dikelompokkan di bawah topik-topik berikut:
-
Aplikasi
-
Bidang Kontrol
-
Bidang Data
Apa yang membuat sistem dapat diandalkan? Jika suatu sistem dapat berfungsi secara konsisten dan memenuhi tuntutan terlepas dari perubahan lingkungannya selama periode waktu tertentu, itu dapat disebut andal. Untuk mencapai hal ini, sistem harus mendeteksi kegagalan, secara otomatis menyembuhkan dirinya sendiri, dan memiliki kemampuan untuk skala berdasarkan permintaan.
Pelanggan dapat menggunakan Kubernetes sebagai fondasi untuk mengoperasikan aplikasi dan layanan mission-critical dengan andal. Namun selain menggabungkan prinsip desain aplikasi berbasis kontainer, menjalankan beban kerja dengan andal juga membutuhkan infrastruktur yang andal. Di Kubernetes, infrastruktur terdiri dari bidang kontrol dan pesawat data.
EKS menyediakan pesawat kontrol Kubernetes tingkat produksi yang dirancang agar sangat tersedia dan toleran terhadap kesalahan.
Di EKS, AWS bertanggung jawab atas keandalan bidang kontrol Kubernetes. EKS menjalankan bidang kontrol Kubernetes di tiga zona ketersediaan di Wilayah AWS. Ini secara otomatis mengelola ketersediaan dan skalabilitas server API Kubernetes dan cluster etcd.
Tanggung jawab atas keandalan pesawat data dibagi antara Anda, pelanggan, dan AWS. EKS menawarkan empat opsi node pekerja untuk menerapkan bidang data Kubernetes.
Mode Otomatis EKS, yang merupakan opsi paling terkelola, menangani penyediaan, penskalaan, dan pembaruan bidang data bersama dengan menyediakan kemampuan Compute, Networking, dan Storage yang dikelola. AMI Mode Otomatis sering dirilis dan cluster diperbarui ke AMI terbaru secara otomatis untuk menerapkan perbaikan CVE dan patch keamanan. Anda memiliki kemampuan untuk mengontrol kapan ini terjadi dengan mengonfigurasi kontrol gangguan pada Mode Otomatis Anda. NodePools
Fargate menangani provisioning dan scaling data plane dengan menjalankan satu Pod per Node. Opsi ketiga, grup node terkelola, menangani penyediaan, dan pembaruan bidang data. Dan akhirnya, node yang dikelola sendiri adalah opsi yang paling tidak dikelola untuk bidang data. Semakin banyak pesawat AWS-managed data yang Anda gunakan, semakin sedikit tanggung jawab yang Anda miliki.
Grup node terkelola mengotomatiskan penyediaan dan manajemen siklus hidup node EC2. Anda dapat menggunakan EKS API (menggunakan konsol EKS, AWS API, AWS CLI,, TerraformCloudFormation, ataueksctl), untuk membuat, menskalakan, dan meningkatkan node terkelola. Node terkelola menjalankan instans EKS-optimized Amazon Linux 2 EC2 di akun Anda, dan Anda dapat menginstal paket perangkat lunak khusus dengan mengaktifkan akses SSH. Saat Anda menyediakan node terkelola, node tersebut berjalan sebagai bagian dari Grup EKS-managed Auto Scaling yang dapat menjangkau beberapa Availability Zone; Anda mengontrol ini melalui subnet yang Anda berikan saat membuat node terkelola. EKS juga secara otomatis menandai node yang dikelola sehingga dapat digunakan dengan Cluster Autoscaler.
Amazon EKS mengikuti model tanggung jawab bersama untuk CVE dan patch keamanan pada grup simpul terkelola. Karena node terkelola menjalankan EKS-optimized AMI Amazon, Amazon EKS bertanggung jawab untuk membuat versi tambalan dari AMI ini saat perbaikan bug. Namun, Anda bertanggung jawab untuk menerapkan versi AMI yang ditambal ini ke grup node terkelola Anda.
EKS juga mengelola pembaruan node meskipun Anda harus memulai proses pembaruan. Proses memperbarui node terkelola dijelaskan dalam dokumentasi EKS.
Jika Anda menjalankan node yang dikelola sendiri, Anda dapat menggunakan Amazon EKS-optimized Linux AMI untuk membuat node pekerja. Anda bertanggung jawab untuk menambal dan meningkatkan AMI dan node. Ini adalah praktik terbaik untuk menggunakaneksctl, CloudFormation, atau infrastruktur sebagai alat kode untuk menyediakan node yang dikelola sendiri karena ini akan memudahkan Anda untuk meningkatkan node yang dikelola sendiri. Pertimbangkan untuk bermigrasi ke node baru saat memperbarui node pekerja karena proses migrasi menodai grup node lama NoSchedule dan menguras node setelah tumpukan baru siap menerima beban kerja pod yang ada. Namun, Anda juga dapat melakukan peningkatan node yang dikelola sendiri di tempat.
Model Tanggung Jawab Bersama - Fargate
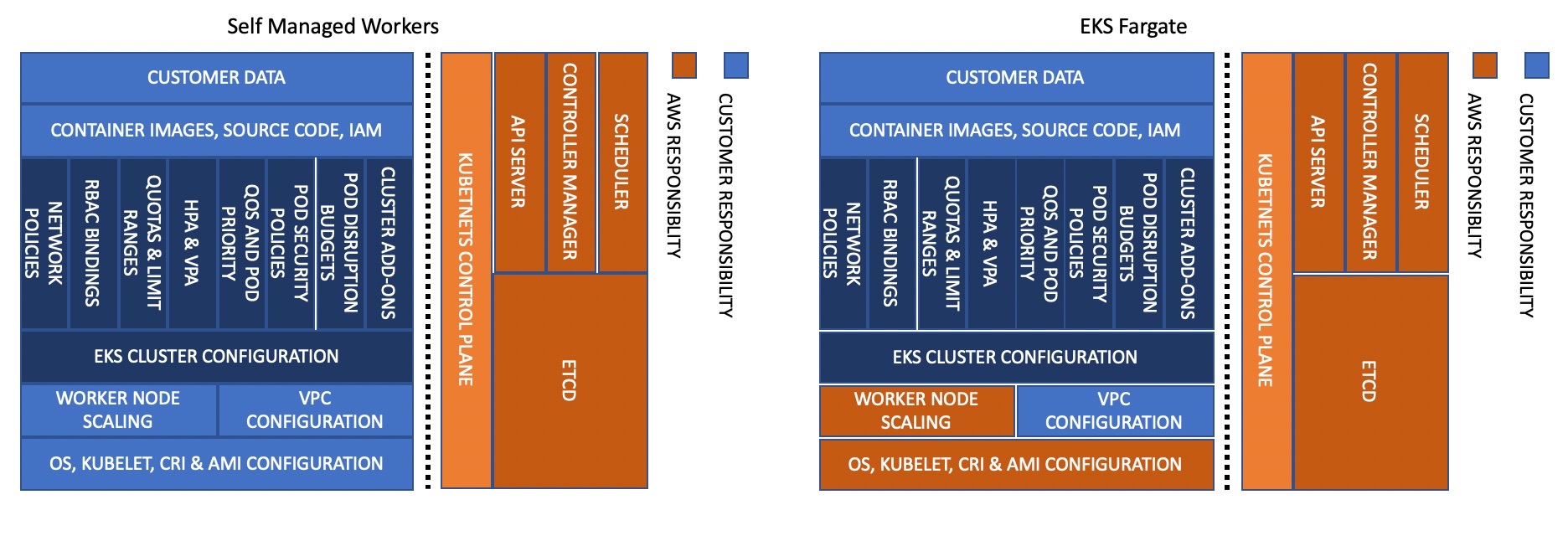
Model Tanggung Jawab Bersama - MNG
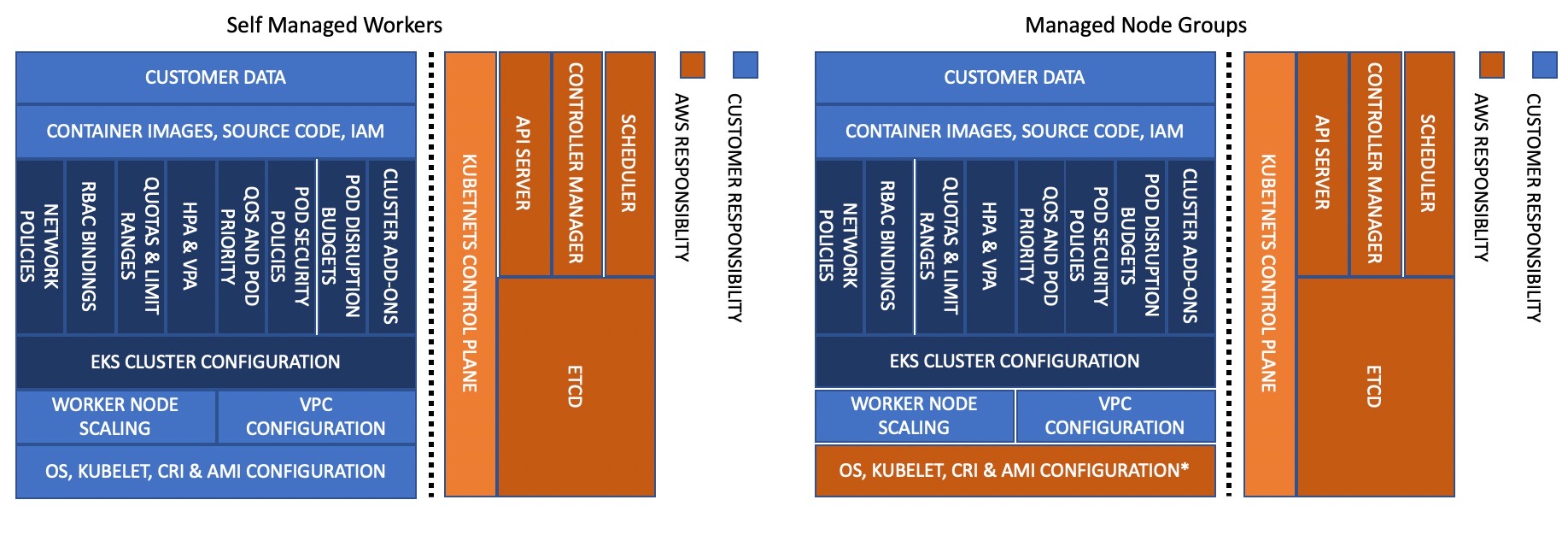
Panduan ini mencakup serangkaian rekomendasi yang dapat Anda gunakan untuk meningkatkan keandalan bidang data EKS Anda, komponen inti Kubernetes, dan aplikasi Anda.
Umpan Balik
Panduan ini dirilis GitHub untuk mengumpulkan umpan balik dan saran langsung dari EKS/Kubernetes komunitas yang lebih luas. Jika Anda memiliki praktik terbaik yang menurut Anda harus kami sertakan dalam panduan ini, harap ajukan masalah atau kirimkan PR di GitHub repositori. Kami bermaksud untuk memperbarui panduan secara berkala karena fitur baru ditambahkan ke layanan atau ketika praktik terbaik baru berkembang.
