Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Mengaktifkan peniruan pengguna untuk memantau aktivitas pengguna dan tugas Spark
EMRNotebook memungkinkan Anda mengonfigurasi peniruan identitas pengguna pada cluster Spark. Fitur ini membantu Anda melacak aktivitas tugas yang dimulai dari dalam editor notebook. Selain itu, EMR Notebook memiliki widget Jupyter Notebook bawaan untuk melihat detail pekerjaan Spark di samping output kueri di editor notebook. Widget ini tersedia secara default dan tidak memerlukan konfigurasi khusus. Namun, untuk melihat server riwayat, klien Anda harus dikonfigurasi untuk melihat antarmuka EMR web Amazon yang di-host di node utama.
catatan
EMRNotebook tersedia sebagai Ruang Kerja EMR Studio di konsol. Tombol Create Workspace di konsol memungkinkan Anda membuat notebook baru. Untuk mengakses atau membuat Ruang Kerja, pengguna EMR Notebook memerlukan izin IAM peran tambahan. Untuk informasi selengkapnya, lihat EMRNotebook Amazon adalah Amazon EMR Studio Workspaces di konsol dan konsol Amazon EMR.
Menyiapkan peniruan pengguna Spark
Secara default, tugas Spark yang dikirimkan pengguna menggunakan editor notebook tampaknya berasal dari identitas pengguna livy. Anda dapat mengonfigurasi peniruan identitas pengguna untuk klaster sehingga pekerjaan ini terkait dengan identitas pengguna yang menjalankan kode sebagai gantinya. HDFSdirektori pengguna pada node utama dibuat untuk setiap identitas pengguna yang menjalankan kode di notebook. Misalnya, jika pengguna NbUser1 menjalankan kode dari editor notebook, Anda dapat terhubung ke node utama dan melihat yang hadoop fs -ls /user menunjukkan direktori/user/user_NbUser1.
Anda mengaktifkan fitur ini dengan menetapkan properti di klasifikasi konfigurasi core-site dan livy-conf. Fitur ini tidak tersedia secara default ketika Anda memiliki Amazon EMR membuat cluster bersama dengan notebook. Untuk informasi selengkapnya tentang menggunakan klasifikasi konfigurasi untuk menyesuaikan aplikasi, lihat Mengonfigurasi aplikasi di Panduan EMRRilis Amazon.
Gunakan klasifikasi dan nilai konfigurasi berikut untuk mengaktifkan peniruan identitas pengguna untuk Notebook: EMR
[ { "Classification": "core-site", "Properties": { "hadoop.proxyuser.livy.groups": "*", "hadoop.proxyuser.livy.hosts": "*" } }, { "Classification": "livy-conf", "Properties": { "livy.impersonation.enabled": "true" } } ]
Menggunakan widget pemantauan tugas Spark
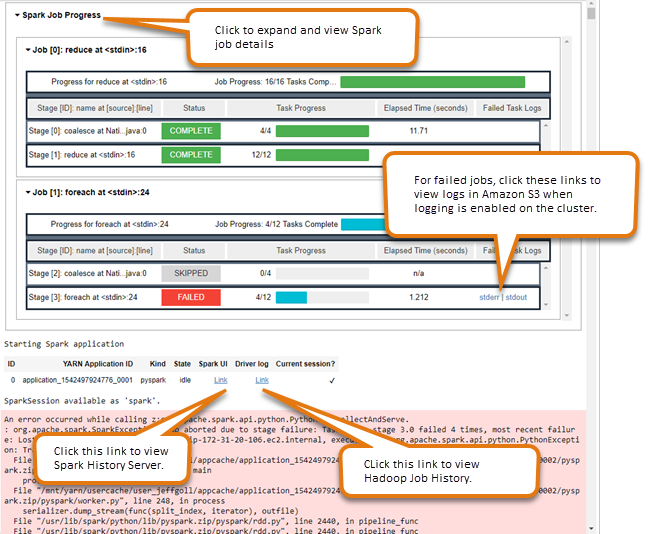
Saat Anda menjalankan kode di editor notebook yang menjalankan tugas Spark di EMR cluster, output menyertakan widget Jupyter Notebook untuk pemantauan pekerjaan Spark. Widget memberikan detail tugas dan tautan yang berguna ke halaman server riwayat Spark dan halaman riwayat tugas Hadoop, bersama dengan tautan yang nyaman untuk log tugas di Amazon S3 untuk tugas gagal.
Untuk melihat halaman server riwayat pada node utama cluster, Anda harus mengatur SSH klien dan proxy yang sesuai. Untuk informasi selengkapnya, lihat Lihat antarmuka web yang dihosting di kluster Amazon EMR. Untuk melihat log di Amazon S3, pencatatan klaster harus diaktifkan, yang merupakan default untuk klaster baru. Untuk informasi selengkapnya, lihat Melihat berkas log yang diarsipkan ke Amazon S3.
Berikut ini adalah contoh dari pemantauan tugas Spark.