Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Debug aplikasi dan pekerjaan dengan EMR Studio
Dengan Amazon EMR Studio, Anda dapat meluncurkan antarmuka aplikasi data untuk menganalisis aplikasi dan pekerjaan yang berjalan di browser.
Anda juga dapat meluncurkan antarmuka pengguna yang persisten dan di luar klaster untuk Amazon EMR yang berjalan pada klaster EC2 dari konsol Amazon EMR. Untuk informasi selengkapnya, lihat Lihat antarmuka pengguna aplikasi persisten di Amazon EMR.
Bergantung pada setelan peramban, Anda mungkin perlu mengaktifkan pop-up agar UI aplikasi terbuka.
Untuk informasi tentang mengonfigurasi dan menggunakan antarmuka aplikasi, lihat Server Timeline YARN, Pemantauan dan instrumentasi, atau Gambaran umum Tez UI.
Men-debug Amazon EMR yang berjalan pada pekerjaan Amazon EC2
- Workspace UI
-
Luncurkan UI pada klaster dari file notebook
Jika Anda menggunakan rilis Amazon EMR versi 5.33.0 dan yang lebih baru, Anda dapat meluncurkan antarmuka pengguna web Spark (Spark UI atau Spark History Server) dari notebook di Workspace Anda.
On-cluster UI bekerja dengan kernel PySpark, Spark, atau SparkR. Ukuran maksimum file dapat dilihat untuk log peristiwa atau log kontainer Spark adalah 10 MB. Jika file log melebihi 10 MB, sebaiknya Anda menggunakan Spark History Server yang persisten, bukannya Spark UI pada klaster untuk men-debug pekerjaan.
Agar EMR Studio dapat meluncurkan antarmuka pengguna aplikasi on-cluster dari Workspace, kluster harus dapat berkomunikasi dengan Amazon API Gateway. Anda harus mengonfigurasi kluster EMR untuk mengizinkan lalu lintas jaringan keluar ke Amazon API Gateway, dan memastikan bahwa Amazon API Gateway dapat dijangkau dari cluster.
Spark UI mengakses log kontainer dengan menyelesaikan nama host. Jika Anda menggunakan nama domain khusus, Anda harus memastikan bahwa nama host simpul klaster Anda dapat diselesaikan oleh Amazon DNS atau server DNS yang Anda tentukan. Untuk melakukannya, atur opsi Dynamic Host Configuration Protocol (DHCP) untuk Amazon Virtual Private Cloud (VPC) yang terkait dengan klaster Anda. Untuk informasi lebih lanjut tentang opsi DHCP, lihat Set opsi DHCP dalam Panduan Pengguna Amazon Virtual Private Cloud.
-
Di EMR Studio Anda, buka Workspace yang ingin Anda gunakan dan pastikan itu terlampir ke klaster Amazon EMR yang berjalan di EC2. Untuk petunjuk, lihat Lampirkan komputasi ke Ruang Kerja EMR Studio.
-
Buka file notebook dan gunakan kernel PySpark, Spark, atau SparkR. Untuk memilih kernel, pilih nama kernel dari kanan atas bilah alat notebook untuk membuka kotak dialog Pilih Kernel. Nama muncul sebagai Tidak ada Kernel! jika tidak ada kernel yang dipilih.
-
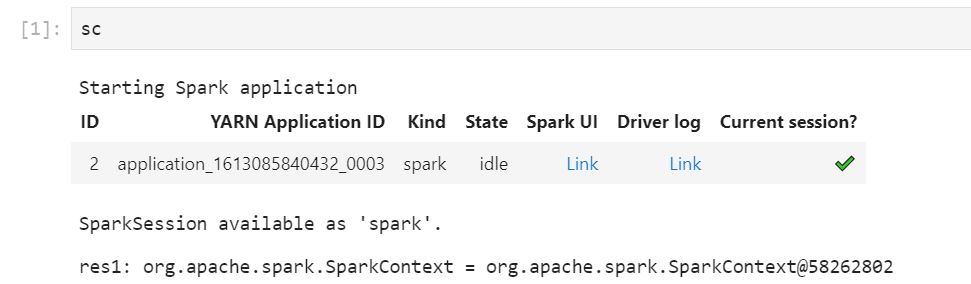
Jalankan kode notebook Anda. Berikut ini muncul sebagai output di notebook ketika Anda memulai konteks Spark. Mungkin diperlukan waktu beberapa detik untuk muncul. Jika Anda telah memulai konteks Spark, Anda dapat menjalankan %%info perintah untuk mengakses tautan ke UI Spark kapan saja.
Jika tautan Spark UI tidak berfungsi atau tidak muncul setelah beberapa detik, buat sel notebook baru dan jalankan perintah %%info untuk meregenerasi tautan.
-
Untuk meluncurkan Spark UI, pilih Tautan di bawah Spark UI. Jika aplikasi Spark Anda sedang berjalan, Spark UI terbuka di tab baru. Jika aplikasi telah selesai, Spark History Server akan membuka.
Setelah meluncurkan UI Spark, Anda dapat memodifikasi URL di browser untuk membuka YARN ResourceManager atau Yarn Timeline Server. Tambahkan salah satu jalur berikut setelah amazonaws.com.
| Web UI |
Jalur |
Contoh URL yang dimodifikasi |
| BENANG ResourceManager |
/rm |
https://j-examplebby5ij.emrappui-prod. eu-west-1.amazonaws.com /rm |
| Yarn Timeline Server |
/yts |
https://j-examplebby5ij.emrappui-prod. eu-west-1.amazonaws.com /yts |
| Spark History Server |
/shs |
https://j-examplebby5ij.emrappui-prod. eu-west-1.amazonaws.com /shs
|
- Studio UI
-
Luncurkan YARN Timeline Server, Spark History Server, atau Tez UI persisten dari EMR Studio UI
-
Di EMR Studio Anda, pilih Amazon EMR di EC2 di sisi kiri halaman untuk membuka Amazon EMR pada daftar cluster EC2.
-
Filter daftar klaster menurut nama, status, atau ID dengan memasukkan nilai di kotak pencarian. Anda juga dapat mencari berdasarkan rentang waktu pembuatan.
-
Pilih klaster kemudian pilih Luncurkan UI aplikasi untuk memilih antarmuka pengguna aplikasi. UI Aplikasi terbuka di tab peramban baru dan mungkin memerlukan beberapa waktu untuk memuat.
Debug EMR Studio berjalan di EMR Tanpa Server
Mirip dengan Amazon EMR yang berjalan di Amazon EC2, Anda dapat menggunakan antarmuka pengguna Workspace untuk menganalisis aplikasi EMR Tanpa Server Anda. Dari UI Workspace, saat Anda menggunakan Amazon EMR rilis 6.14.0 dan yang lebih tinggi, Anda dapat meluncurkan antarmuka pengguna web Spark (UI Spark atau Server Riwayat Spark) dari notebook di Workspace Anda. Untuk kenyamanan Anda, kami juga menyediakan tautan ke log driver untuk akses cepat log driver Spark.
Debug Amazon EMR pada pekerjaan EKS berjalan dengan Spark History Server
Saat Anda mengirimkan pekerjaan yang dijalankan ke EMR Amazon di klaster EKS, Anda dapat mengakses log untuk pekerjaan yang dijalankan menggunakan Server Riwayat Spark. Spark History Server menyediakan alat untuk memantau aplikasi Spark, seperti daftar tahapan dan tugas penjadwal, ringkasan ukuran RDD dan penggunaan memori, dan informasi lingkungan. Anda dapat meluncurkan Spark History Server untuk Amazon EMR pada pekerjaan EKS berjalan dengan cara berikut:
-
Saat mengirimkan pekerjaan yang dijalankan menggunakan EMR Studio dengan Amazon EMR di titik akhir terkelola EKS, Anda dapat meluncurkan Server Riwayat Spark dari file notebook di Workspace.
-
Saat Anda mengirimkan pekerjaan yang dijalankan menggunakan AWS CLI atau AWS SDK untuk Amazon EMR di EKS, Anda dapat meluncurkan Spark History Server dari EMR Studio UI.
Untuk informasi tentang cara menggunakan Spark History Server, lihat Pemantauan dan Instrumentasi dalam dokumentasi Apache Spark. Untuk informasi lebih lanjut tentang pekerjaan berjalan, lihat Konsep dan komponen dalam Panduan Pengembangan Amazon EMR pada EKS.
Untuk meluncurkan Spark History Server dari file notebook di EMR Studio Workspace
-
Buka Workspace yang terhubung ke Amazon EMR di klaster EKS.
-
Pilih dan buka file notebook Anda di Workspace.
-
Pilih Spark UI di bagian atas file notebook untuk membuka Server Riwayat Spark persisten di tab baru.
Untuk meluncurkan Spark History Server dari EMR Studio UI
Daftar Pekerjaan di EMR Studio UI hanya menampilkan tugas yang Anda kirimkan menggunakan AWS CLI atau AWS SDK untuk Amazon EMR di EKS.
-
Di EMR Studio Anda, pilih Amazon EMR di EKS di sisi kiri halaman.
-
Cari EMR Amazon di klaster virtual EKS yang Anda gunakan untuk mengirimkan pekerjaan Anda. Anda dapat memfilter daftar cluster berdasarkan status atau ID dengan memasukkan nilai di kotak pencarian.
-
Pilih cluster untuk membuka halaman detailnya. Halaman detail menampilkan informasi tentang cluster, seperti ID, namespace, dan status. Halaman ini juga menampilkan daftar semua pekerjaan yang dikirimkan ke klaster itu.
-
Dari halaman detail klaster, pilih pekerjaan berjalan untuk di-debug.
-
Di kanan atas daftar Pekerjaan, pilih Luncurkan Spark History Server untuk membuka antarmuka aplikasi di tab peramban baru.