Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Performa Amazon FSx for Lustre
Bab ini menyediakan topik kinerja Amazon FSx for Lustre, termasuk beberapa tips dan rekomendasi penting untuk memaksimalkan kinerja sistem file Anda.
Topik
Gambaran umum
Amazon FSx for Lustre, Lustre dibangun di atas, sistem file berkinerja tinggi yang populer, memberikan kinerja scale-out yang meningkat secara linier dengan ukuran sistem file. Lustreskala sistem file secara horizontal di beberapa server file dan disk. Penskalaan ini memberikan setiap klien akses langsung ke data yang disimpan pada setiap disk untuk menghapus banyaknya kemacetan yang ada dalam sistem file tradisional. Amazon FSx for Lustre dibangun Lustre di atas arsitektur yang dapat diskalakan untuk mendukung kinerja tingkat tinggi di sejumlah besar klien.
Cara kerja sistem file FSx for Lustre
Setiap sistem file FSx for Lustre terdiri dari server file yang berkomunikasi dengan klien, dan satu set disk yang dilampirkan ke setiap server file yang menyimpan data Anda. Setiap server file menggunakan cache dalam memori untuk meningkatkan performa untuk data yang diakses paling sering. Tergantung pada kelas penyimpanan, server file Anda dapat disediakan dengan cache baca SSD opsional. Ketika klien mengakses data yang disimpan di cache dalam memori atau cache SSD, server file tidak perlu membacanya dari disk, yang mana akan mengurangi latensi dan meningkatkan jumlah total throughput yang dapat Anda drive. Diagram berikut menggambarkan jalur operasi tulis, operasi baca yang disajikan dari disk, dan operasi baca yang disajikan dari cache dalam memori atau SSD.
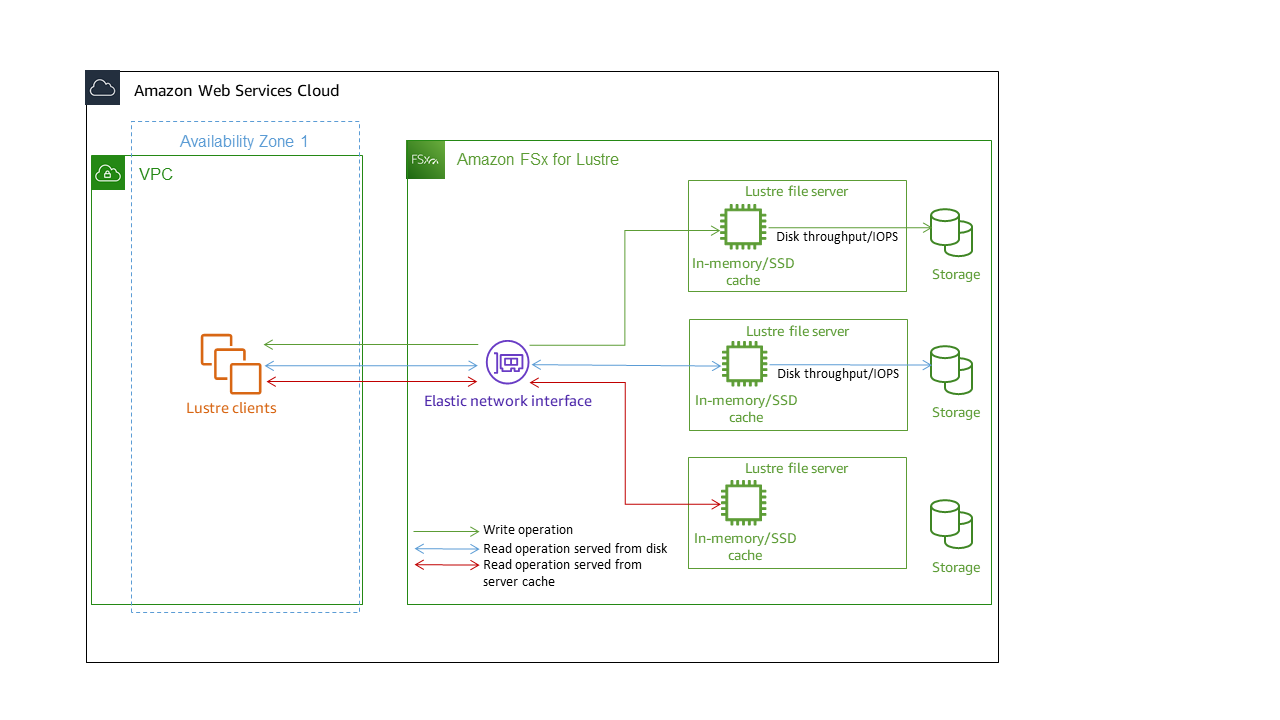
Ketika Anda membaca data yang disimpan di cache dalam-memori atau cache SSD pada server file, performa sistem file ditentukan oleh throughput jaringan. Ketika Anda menulis data ke sistem file Anda, atau ketika Anda membaca data yang tidak disimpan pada cache dalam memori, kinerja sistem file ditentukan oleh yang lebih rendah dari throughput jaringan dan throughput disk.
Untuk mempelajari lebih lanjut tentang throughput jaringan, throughput disk, dan karakteristik IOPS dari kelas penyimpanan SSD dan HDD, lihat dan. Karakteristik kinerja kelas penyimpanan SSD dan HDD Karakteristik kinerja kelas Intelligent-Tiering penyimpanan
Kinerja metadata sistem file
Sistem file metadata operasi IO per detik (IOPS) menentukan jumlah file dan direktori yang dapat Anda buat, daftar, baca, dan hapus per detik.
Sistem file 2 persisten memungkinkan Anda untuk menyediakan Metadata IOPS independen dari kapasitas penyimpanan dan memberikan peningkatan visibilitas ke dalam jumlah dan jenis metadata yang ditargetkan oleh instans klien IOPS di sistem file Anda. Dengan sistem file SSD, Metadata IOPS secara otomatis disediakan berdasarkan kapasitas penyimpanan yang Anda berikan. Mode otomatis tidak didukung pada sistem Intelligent-Tiering file.
Dengan sistem file FSx for Lustre Persistent 2, jumlah IOPS Metadata yang Anda sediakan dan jenis operasi metadata menentukan tingkat operasi metadata yang dapat didukung oleh sistem file Anda. Tingkat IOPS metadata yang Anda berikan menentukan jumlah IOPS yang disediakan untuk disk metadata sistem file Anda.
| Jenis operasi | Operasi yang dapat Anda kendarai per detik untuk setiap metadata yang disediakan IOPS |
|---|---|
|
Membuat File, Buka dan Tutup |
2 |
|
Hapus File |
1 |
|
Direktori Buat, Ganti Nama |
0.1 |
|
Direktori Hapus |
0.2 |
Untuk sistem file SSD, Anda dapat memilih untuk menyediakan metadata IOPS menggunakan mode Otomatis. Dalam mode Otomatis, Amazon FSx secara otomatis menyediakan IOPS metadata berdasarkan kapasitas penyimpanan sistem file Anda sesuai dengan tabel di bawah ini:
| Kapasitas penyimpanan sistem file | Termasuk metadata IOPS dalam mode Otomatis |
|---|---|
|
1200 GiB |
1500 |
|
2400 GiB |
3000 |
|
4800—9600 GiB |
6000 |
|
12000—45600 GiB |
12000 |
|
≥48000 GiB |
12000 IOPS per 24000 GiB |
Dalam User-provisioned mode, Anda dapat memilih untuk menentukan jumlah IOPS metadata yang akan disediakan. Nilai yang valid adalah sebagai berikut:
Untuk sistem file SSD, nilai yang valid adalah
150030006000,12000,,,, dan kelipatan12000hingga maksimum.192000Untuk sistem Intelligent-Tiering file, nilai yang valid adalah
6000dan12000.
Untuk informasi tentang cara mengonfigurasi IOPS Metadata, lihat. Mengelola kinerja metadata Perhatikan bahwa Anda membayar Metadata IOPS yang disediakan di atas nomor default Metadata IOPS untuk sistem file Anda.
Throughput ke instance klien individu
Jika Anda membuat sistem file dengan kapasitas throughput lebih dari 10 GBps, sebaiknya aktifkan Elastic Fabric Adapter (EFA) untuk mengoptimalkan throughput per instance klien. Untuk lebih mengoptimalkan throughput per instance klien, sistem EFA-enabled file juga mendukung GPUDirect Storage untuk instans GPU-based klien EFA-enabled NVIDIA dan ENA Express untuk instans klien ENA. Express-enabled
Throughput yang dapat Anda arahkan ke satu instance klien tergantung pada pilihan jenis sistem file dan antarmuka jaringan pada instance klien Anda.
| Tipe Sistem File | Antarmuka jaringan instance klien | Throughput maksimum per klien, Gbps |
|---|---|---|
|
Non EFA-enabled |
Setiap |
100 Gbps* |
|
EFA-enabled |
ENA |
100 Gbps* |
|
EFA-enabled |
ENA Ekspres |
100 Gbps |
|
EFA-enabled |
EFA |
700 Gbps |
|
EFA-enabled |
EFA dengan GDS |
1200 Gbps |
catatan
* Lalu lintas antara instance klien individu dan FSx individu untuk server penyimpanan objek Lustre dibatasi hingga 5 Gbps. Lihat Alamat IP untuk sistem file untuk jumlah server penyimpanan objek yang mendukung sistem file FSx for Lustre Anda.
Layout penyimpanan sistem file
Semua data file Lustre disimpan pada volume penyimpanan yang disebut target penyimpanan objek (OST). Semua metadata file (termasuk nama file, timestamp, izin, dan lainnya) disimpan di volume penyimpanan yang disebut target metadata (MDT). Sistem file Amazon FSx for Lustre terdiri dari satu atau lebih MDT dan beberapa OST. Amazon FSx for Lustre menyebarkan data file Anda ke seluruh OST yang membentuk sistem file Anda untuk menyeimbangkan kapasitas penyimpanan dengan throughput dan beban IOPS.
Untuk melihat penggunaan penyimpanan MDT dan OST yang membentuk sistem file Anda, jalankan perintah berikut dari client yang sistem file-nya sudah terpasang.
lfs df -hmount/path
Hasil akhir dari perintah ini adalah sebagai berikut.
contoh
UUID bytes Used Available Use% Mounted onmountname-MDT0000_UUID 68.7G 5.4M 68.7G 0% /fsx[MDT:0]mountname-OST0000_UUID 1.1T 4.5M 1.1T 0% /fsx[OST:0]mountname-OST0001_UUID 1.1T 4.5M 1.1T 0% /fsx[OST:1] filesystem_summary: 2.2T 9.0M 2.2T 0% /fsx
Sedang melakukan stripe data di sistem file Anda
Anda dapat mengoptimalkan performa throughput sistem file Anda dengan melakukan file striping. Amazon FSx for Lustre secara otomatis menyebarkan file-file ke seluruh OST untuk memastikan bahwa data dilayani dari semua server penyimpanan. Anda dapat menerapkan konsep yang sama di tingkat file dengan mengonfigurasi bagaimana file-file di-stripe di beberapa OST.
Striping artinya bahwa file-file dapat dibagi menjadi beberapa potongan yang kemudian disimpan di seluruh OST yang berbeda. Ketika sebuah file di-stripe di beberapa OST, pembacaan atau penulisan permintaan ke file tersebar di OST-OST tersebut, meningkatkan throughput agregat atau IOPS yang aplikasi Anda dapat melakukan drive melaluinya.
Berikut ini adalah layout default untuk sistem file Amazon FSx for Lustre.
Untuk sistem file yang dibuat sebelum 18 Desember 2020, tata letak default menentukan jumlah garis 1. Ini berarti bahwa kecuali sebuah layout yang berbeda ditentukan, setiap file yang dibuat di Amazon FSx for Lustre menggunakan alat-alat Linux standar disimpan di sebuah disk.
Untuk sistem file yang dibuat setelah 18 Desember 2020, tata letak default adalah tata letak file progresif di mana file di bawah ukuran 1GiB disimpan dalam satu garis, dan file yang lebih besar diberi jumlah garis 5.
Untuk sistem file yang dibuat setelah 25 Agustus 2023, tata letak default adalah tata letak file progresif 4 komponen yang dijelaskan di. Layout file progresif
Untuk semua sistem file terlepas dari tanggal pembuatannya, file yang diimpor dari Amazon S3 tidak menggunakan tata letak default, melainkan menggunakan tata letak dalam parameter sistem file.
ImportedFileChunkSizeS3-imported file yang lebih besar dariImportedFileChunkSizeakan disimpan di beberapa OST dengan jumlah garis.(FileSize / ImportedFileChunksize) + 1Nilai default dariImportedFileChunkSizeadalah 1GiB.
Anda dapat melihat konfigurasi layout dari sebuah file atau direktori menggunakan perintah lfs getstripe.
lfs getstripepath/to/filename
Perintah ini melaporkan jumlah stripe dari file, ukuran stripe, dan offset stripe. Jumlah stripe adalah seberapa banyak OST file yang di-stripe. Ukuran stripe adalah seberapa banyak data berkelanjutan yang disimpan dalam sebuah OST. Offset stripe adalah indeks OST pertama tempat file di-stripe.
Memodifikasi konfigurasi striping Anda
Parameter layout dari sebuah file diatur ketika file pertama kali dibuat. Gunakan perintah lfs setstripe untuk membuat sebuah file yang baru, kosong dengan layout yang telah ditentukan.
lfs setstripefilename--stripe-countnumber_of_OSTs
Perintah lfs setstripe mempengaruhi hanya layout dari sebuah file baru. Gunakan perintah tersebut untuk menentukan layout sebuah file sebelum Anda membuatnya. Anda juga dapat menentukan layout untuk sebuah direktori. Setelah ditetapkan pada sebuah direktori, layout diterapkan ke setiap file baru yang ditambahkan ke direktori tersebut, tetapi tidak ke file yang sudah ada. Setiap subdirektori baru yang Anda buat juga mewarisi layout baru, yang kemudian diterapkan ke setiap file atau direktori baru yang Anda buat dalam subdirektori tersebut.
Untuk memodifikasi layout dari file yang ada, gunakan perintah lfs migrate. Perintah ini menyalin file sebagaimana diperlukan untuk mendistribusikan isinya berdasarkan layout yang Anda tentukan di perintah. Misalnya, file-file yang ditambahkan atau ditingkatkan ukurannya tidak akan mengubah jumlah stripe, jadi Anda harus me-migrasi file-file untuk mengubah layout file. Atau, Anda dapat membuat file baru menggunakan perintah lfs setstripe untuk menentukan layout-nya, menyalin konten semula ke file yang baru, dan kemudian mengubah nama file yang baru untuk mengganti file semula.
Mungkin ada kasus-kasus di mana konfigurasi layout default tidak optimal untuk beban kerja Anda. Sebagai contoh, sistem file dengan puluhan OST dan sejumlah besar file berukuran multi-gigabyte bisa memiliki performa yang lebih tinggi dengan melakukan stripe file lebih dari nilai jumlah stripe default dari lima OST. Membuat file besar dengan jumlah strip rendah dapat menyebabkan kemacetan I/O kinerja dan juga dapat menyebabkan OST terisi. Dalam hal ini, Anda dapat membuat sebuah direktori dengan jumlah stripe yang lebih besar untuk file-file ini.
Mengatur layout yang ditetapkan stripe-nya untuk file-file besar (terutama file-file yang lebih besar dari ukuran gigabyte) adalah penting karena alasan-alasan berikut ini:
Tingkatkan throughput dengan mengizinkan beberapa OST dan server mereka yang ter-associate untuk berkontribusi IOPS, bandwidth jaringan, dan sumber daya CPU saat membaca dan menulis file besar.
Mengurangi kemungkinan subset kecil dari OST menjadi hot spot yang membatasi performa beban kerja secara keseluruhan.
Mencegah satu file tunggal besar mengisi OST, yang berpotensi menyebabkan error disk penuh.
Tidak ada konfigurasi layout optimal tunggal untuk semua kasus penggunaan. Untuk panduan rinci tentang tata letak file, lihat Mengelola Tata Letak File (Striping) dan Ruang Bebas
Layout yang sudah ditentukan stripe-nya adalah masalah bagi file-file besar, terutama dalam kasus penggunaan di mana file-file secara rutin memiliki ukuran ratusan megabyte atau lebih. Untuk alasan ini, layout default untuk sistem file baru menetapkan jumlah stripe sebanyak lima untuk file-file di atas ukuran 1GiB.
Jumlah Stripe adalah parameter layout yang harus Anda sesuaikan untuk sistem yang men-support file-file besar. Jumlah stripe menentukan jumlah volume OST yang akan menyimpan potongan file yang memiliki stripe. Misalnya, dengan jumlah garis 2 dan ukuran garis 1MiB, Lustre tulis potongan 1MiB alternatif dari file ke masing-masing dari dua OST.
Jumlah stripe yang efektif adalah lebih sedikit dari jumlah volume OST yang sebenarnya dan nilai jumlah stripe yang Anda tentukan. Anda dapat menggunakan nilai jumlah stripe sebanyak
-1untuk menunjukkan bahwa stripe harus ditempatkan di semua volume OST.Mengatur jumlah strip besar untuk file kecil adalah sub-optimal karena untuk operasi tertentu Lustre memerlukan jaringan pulang pergi ke setiap OST dalam tata letak, bahkan jika file terlalu kecil untuk mengkonsumsi ruang pada semua volume OST.
Anda dapat mengatur layout file progresif (PFL) yang mengizinkan layout sebuah file berubah-ubah sesuai ukuran. Konfigurasi PFL dapat menyederhanakan pengelolaan sebuah sistem file yang memiliki kombinasi file besar dan kecil tanpa Anda harus secara eksplisit mengatur konfigurasi untuk setiap file. Untuk informasi selengkapnya, lihat Layout file progresif.
Ukuran Stripe secara default adalah 1MiB. Menyetel garis offset mungkin berguna dalam keadaan khusus, tetapi secara umum yang terbaik adalah membiarkannya tidak ditentukan dan menggunakan default.
Layout file progresif
Anda dapat menentukan konfigurasi layout file progresif (PFL) untuk sebuah direktori untuk menentukan konfigurasi stripe yang berbeda-beda untuk file kecil dan besar sebelum mengisinya. Misalnya, Anda dapat mengatur PFL di direktori tingkat atas sebelum ada data yang dituliskan ke sistem file yang baru.
Untuk menentukan konfigurasi PFL, gunakan perintah lfs setstripe dengan opsi -E untuk menentukan komponen layout untuk file dengan ukuran yang berbeda-beda, seperti perintah berikut:
lfs setstripe -E 100M -c 1 -E 10G -c 8 -E 100G -c 16 -E -1 -c 32/mountname/directory
Perintah ini menetapkan empat komponen tata letak:
Komponen pertama (
-E 100M -c 1) menunjukkan nilai jumlah stripe sebanyak 1 untuk file-file dengan ukuran 100MiB.Komponen kedua (
-E 10G -c 8) menunjukkan nilai jumlah stripe sebanyak 8 untuk file-file dengan ukuran 10GiB.Komponen ketiga (
-E 100G -c 16) menunjukkan jumlah garis 16 untuk file berukuran hingga 100GiB.Komponen keempat (
-E -1 -c 32) menunjukkan jumlah garis 32 untuk file yang lebih besar dari 100GiB.
penting
Menambahkan data ke file yang dibuat dengan sebuah layout PFL, data akan mengisi semua komponen layout-nya. Misalnya, dengan perintah 4-komponen yang ditunjukkan di atas, jika Anda membuat file 1MiB dan kemudian menambahkan data ke ujungnya, tata letak file akan diperluas untuk memiliki jumlah garis -1, yang berarti semua OST dalam sistem. Hal ini tidak berarti data akan ditulis ke setiap OST, tetapi sebuah operasi seperti membaca panjang file akan mengirimkan permintaan secara paralel ke setiap OST, menambah beban jaringan yang signifikan ke sistem file.
Oleh karena itu, berhati-hatilah untuk membatasi jumlah stripe untuk panjang file berukuran kecil dan medium yang selanjutnya dapat diisi oleh data ke dalamnya. Karena file berkas log biasanya membesar dengan adanya catatan baru yang ditambahkan, Amazon FSx for Lustre menetapkan jumlah stripe default sebanyak 1 ke setiap file yang dibuat dalam mode tambah, terlepas dari konfigurasi stripe default yang ditentukan oleh direktori induknya.
Konfigurasi PFL default di Amazon FSx for Lustre sistem file yang dibuat setelah 25 Agustus 2023 diatur dengan perintah ini:
lfs setstripe -E 100M -c 1 -E 10G -c 8 -E 100G -c 16 -E -1 -c 32/mountname
Pelanggan dengan beban kerja yang memiliki akses sangat bersamaan pada file sedang dan besar cenderung mendapat manfaat dari tata letak dengan lebih banyak garis pada ukuran yang lebih kecil dan striping di semua OST untuk file terbesar, seperti yang ditunjukkan dalam tata letak contoh empat komponen.
Memantau performa dan penggunaan
Setiap menit, Amazon FSx for Lustre memancarkan metrik penggunaan untuk setiap disk (MDT dan OST) ke Amazon. CloudWatch
Untuk melihat detail penggunaan sistem file agregat, Anda dapat melihat statistik Jumlah dari setiap metrik. Sebagai contoh, Jumlah dari statistik DataReadBytes melaporkan total throughput baca yang terlihat oleh semua OST di dalam sebuah sistem file. Sama halnya, Jumlah dari statistik FreeDataStorageCapacity melaporkan jumlah kapasitas penyimpanan yang tersedia untuk data file di dalam sistem file.
Untuk informasi selengkapnya tentang pemantauan performa dari sistem file Anda, lihat Memantau sistem file Amazon FSx for Lustre.
