Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
ETLLowongan kerja streaming di AWS Glue
Anda dapat membuat streaming extract, transform, dan load (ETL) pekerjaan yang berjalan terus menerus, mengkonsumsi data dari sumber streaming seperti Amazon Kinesis Data Streams, Apache Kafka Amazon Managed Streaming for Apache Kafka , dan (Amazon). MSK Pekerjaan membersihkan dan mengubah data, lalu memuat hasilnya ke dalam danau data Amazon S3 JDBC atau penyimpanan data.
Selain itu, Anda dapat menghasilkan data untuk Amazon Kinesis Data Streams. Fitur ini hanya tersedia saat menulis AWS Glue skrip. Untuk informasi selengkapnya, lihat Koneksi Kinesis.
Secara default, AWS Glue memproses dan menulis data dalam jendela 100 detik. Hal ini memungkinkan data diproses secara efisien dan memungkinkan agregasi untuk dilakukan pada data yang tiba lebih lambat dari yang diharapkan. Anda dapat mengubah ukuran jendela ini untuk meningkatkan ketepatan waktu atau akurasi agregasi. AWS Glue pekerjaan streaming menggunakan pos pemeriksaan daripada bookmark pekerjaan untuk melacak data yang telah dibaca.
catatan
AWS Glue tagihan per jam untuk ETL pekerjaan streaming saat mereka berjalan.
Video ini membahas tantangan ETL biaya streaming, dan fitur penghematan biaya di. AWS Glue
Membuat ETL pekerjaan streaming melibatkan langkah-langkah berikut:
-
Untuk sumber streaming Apache Kafka, buat AWS Glue koneksi ke sumber Kafka atau MSK cluster Amazon.
-
Secara manual, buat tabel Katalog Data untuk sumber streaming.
-
Buat ETL pekerjaan untuk sumber data streaming. Tentukan properti tugas spesifik-streaming, dan sediakan skrip Anda sendiri atau, secara opsional, modifikasi skrip yang dihasilkan.
Untuk informasi selengkapnya, lihat Streaming ETL di AWS Glue.
Saat membuat ETL pekerjaan streaming untuk Amazon Kinesis Data Streams, Anda tidak perlu membuat AWS Glue koneksi. Namun, jika ada koneksi yang melekat pada AWS Glue ETLpekerjaan streaming yang memiliki Kinesis Data Streams sebagai sumber, maka diperlukan endpoint virtual private VPC cloud () ke Kinesis. Untuk informasi selengkapnya, lihat Membuat titik akhir antarmuka di Panduan VPC Pengguna Amazon. Saat menentukan pengaliran Amazon Kinesis Data Streams di akun lain, Anda harus menyiapkan peran dan kebijakan untuk memungkinkan akses lintas akun. Untuk informasi selengkapnya, lihat Contoh: Baca Dari Pengaliran Kinesis di Akun Berbeda.
AWS Glue ETLpekerjaan streaming dapat mendeteksi data terkompresi secara otomatis, mendekompresi data streaming secara transparan, melakukan transformasi biasa pada sumber input, dan memuat ke penyimpanan output.
AWS Glue mendukung dekompresi otomatis untuk jenis kompresi berikut yang diberikan format input:
| Jenis kompresi | Berkas Avro | Tanggal Avro | JSON | CSV | Grok |
|---|---|---|---|---|---|
| BZIP2 | Ya | Ya | Ya | Ya | Ya |
| GZIP | Tidak | Ya | Ya | Ya | Ya |
| SNAPPY | Ya (Snappy mentah) | Ya (berbingkai Snappy) | Ya (berbingkai Snappy) | Ya (berbingkai Snappy) | Ya (berbingkai Snappy) |
| XZ | Ya | Ya | Ya | Ya | Ya |
| ZSTD | Ya | Tidak | Tidak | Tidak | Tidak |
| DEFLATE | Ya | Ya | Ya | Ya | Ya |
Topik
Membuat AWS Glue koneksi untuk aliran data Apache Kafka
Untuk membaca dari aliran Apache Kafka, Anda harus membuat AWS Glue koneksi.
Untuk membuat AWS Glue koneksi untuk sumber Kafka (Konsol)
Buka AWS Glue konsol di https://console.aws.amazon.com/glue/
. -
Pada panel navigasi, di Katalog data, pilih Koneksi.
-
Pilih Tambahkan koneksi, dan pada halaman Siapkan properti koneksi Anda, masukkan nama koneksi.
catatan
Untuk informasi selengkapnya tentang menentukan properti koneksi, lihat properti AWS Glue koneksi. .
-
Untuk Connection type (Tipe koneksi), pilih Kafka.
-
Untuk server bootstrap Kafka URLs, masukkan host dan nomor port untuk broker bootstrap untuk MSK cluster Amazon atau cluster Apache Kafka Anda. Gunakan hanya titik akhir Transport Layer Security (TLS) untuk membuat koneksi awal ke cluster Kafka. Tidak mendukung titik akhir teks biasa.
Berikut ini adalah contoh daftar pasangan hostname dan nomor port untuk MSK cluster Amazon.
myserver1.kafka.us-east-1.amazonaws.com:9094,myserver2.kafka.us-east-1.amazonaws.com:9094, myserver3.kafka.us-east-1.amazonaws.com:9094Untuk informasi selengkapnya tentang mendapatkan informasi broker bootstrap, lihat Mendapatkan Broker Bootstrap untuk MSK Cluster Amazon di Panduan Pengembang Amazon Managed Streaming for Apache Kafka.
-
Jika Anda menginginkan koneksi aman ke sumber data Kafka, pilih Memerlukan SSL koneksi, dan untuk lokasi sertifikat CA pribadi Kafka, masukkan jalur Amazon S3 yang valid ke sertifikat kustom. SSL
Untuk SSL koneksi ke Kafka yang dikelola sendiri, sertifikat khusus adalah wajib. Ini opsional untuk AmazonMSK.
Untuk informasi selengkapnya tentang menentukan sebuah sertifikat khusus untuk Kafka, lihat AWS Glue SSLproperti koneksi.
-
Gunakan AWS Glue Studio atau AWS CLI untuk menentukan metode otentikasi klien Kafka. Untuk mengakses AWS Glue Studio pilih AWS Gluedari ETLmenu di panel navigasi kiri.
Untuk informasi selengkapnya tentang metode otentikasi klien Kafka, lihat. AWS Glue Properti koneksi Kafka untuk otentikasi klien
-
Secara opsional, masukkan deskripsi, dan kemudian pilih Selanjutnya.
-
Untuk MSK klaster Amazon, tentukan virtual private cloud (VPC), subnet, dan grup keamanan. VPCInformasi ini opsional untuk Kafka yang dikelola sendiri.
-
Pilih Selanjutnya untuk meninjau semua properti koneksi, dan kemudian pilih Selesai.
Untuk informasi lebih lanjut tentang AWS Glue koneksi, lihatMenghubungkan ke data.
AWS Glue Properti koneksi Kafka untuk otentikasi klien
- SASL/GSSAPI(Kerberos) otentikasi
-
Memilih metode otentikasi ini akan memungkinkan Anda untuk menentukan properti Kerberos.
- Kerberos Keytab
-
Pilih lokasi file tab tombol. Keytab menyimpan kunci jangka panjang untuk satu atau lebih prinsipal. Untuk informasi selengkapnya, lihat Dokumentasi MIT Kerberos: Keytab
. - Kerberos berkas krb5.conf
-
Pilih file krb5.conf. Ini berisi ranah default (jaringan logis, mirip dengan domain, yang mendefinisikan sekelompok sistem di bawah yang samaKDC) dan lokasi KDC server. Untuk informasi lebih lanjut, lihat Dokumentasi MIT Kerberos:
krb5.conf. - Kepala sekolah Kerberos dan nama layanan Kerberos
-
Masukkan kepala sekolah dan nama layanan Kerberos. Untuk informasi lebih lanjut, lihat Dokumentasi MIT Kerberos: Kepala sekolah Kerberos
. - SASL/SCRAM- SHA -512 otentikasi
-
Memilih metode otentikasi ini akan memungkinkan Anda untuk menentukan kredensyal otentikasi.
- AWS Secrets Manager
-
Cari token Anda di kotak Pencarian dengan mengetikkan nama atauARN.
- Nama pengguna dan kata sandi penyedia secara langsung
-
Cari token Anda di kotak Pencarian dengan mengetikkan nama atauARN.
- SSLotentikasi klien
-
Memilih metode otentikasi ini memungkinkan Anda untuk memilih lokasi keystore klien Kafka dengan menjelajahi Amazon S3. Secara opsional, Anda dapat memasukkan kata sandi keystore klien Kafka dan kata sandi kunci klien Kafka.
- IAMotentikasi
-
Metode otentikasi ini tidak memerlukan spesifikasi tambahan dan hanya berlaku jika sumber Streaming adalah MSK Kafka.
- SASL/PLAINotentikasi
-
Memilih metode otentikasi ini memungkinkan Anda menentukan kredensyal otentikasi.
Membuat tabel Katalog Data untuk sumber streaming
Tabel Katalog Data yang menentukan properti aliran data sumber, termasuk skema data dapat dibuat secara manual untuk sumber streaming. Tabel ini digunakan sebagai sumber data untuk ETL pekerjaan streaming.
Jika Anda tidak tahu skema data dalam aliran data sumber, maka Anda dapat membuat tabel tanpa skema. Kemudian ketika Anda membuat ETL pekerjaan streaming, Anda dapat mengaktifkan AWS Glue fungsi deteksi skema. AWS Glue menentukan skema dari data streaming.
Gunakan AWS Glue konsol
catatan
Anda tidak dapat menggunakan AWS Lake Formation konsol untuk membuat tabel; Anda harus menggunakan AWS Glue konsol.
Juga mempertimbangkan informasi berikut untuk sumber streaming dalam format Avro atau untuk data log yang dapat Anda terapkan pola Grok untuknya.
Sumber data Kinesis
Saat membuat tabel, atur ETL properti streaming berikut (konsol).
- Jenis Sumber
-
Kinesis
- Untuk sebuah sumber Kinesis pada akun yang sama:
-
- Wilayah
-
AWS Wilayah tempat layanan Amazon Kinesis Data Streams berada. Nama aliran Wilayah dan Kinesis bersama-sama diterjemahkan ke Aliran. ARN
Contoh: https://kinesis.us-east-1.amazonaws.com
- Nama pengaliran Kinesis
-
Nama pengaliran seperti yang dijelaskan dalam Membuat Pengaliran dalam Panduan Developer Amazon Kinesis Data Streams.
- Untuk sumber Kinesis di akun lain, lihat contoh ini untuk menyiapkan peran dan kebijakan untuk memungkinkan akses lintas akun. Konfigurasikan pengaturan ini:
-
- Streaming ARN
-
Aliran data Kinesis tempat konsumen terdaftar. ARN Untuk informasi selengkapnya, lihat Amazon Resource Names (ARNs) dan Ruang Nama AWS Layanan di bagian. Referensi Umum AWS
- Peran yang Diasumsikan ARN
-
Nama Sumber Daya Amazon (ARN) dari peran yang akan diasumsikan.
- Nama sesi (opsional)
-
Sebuah pengenal untuk sesi peran yang diambil.
Gunakan nama sesi peran untuk mengidentifikasi sebuah sesi secara unik ketika peran yang sama diambil oleh prinsipal utama yang berbeda atau untuk alasan yang berbeda. Dalam skenario lintas akun, nama sesi peran dapat dilihat, dan dapat dicatat oleh akun yang memiliki peran tersebut. Nama sesi peran juga digunakan dalam ARN prinsip peran yang diasumsikan. Ini berarti bahwa API permintaan lintas akun berikutnya yang menggunakan kredenal keamanan sementara akan mengekspos nama sesi peran ke akun eksternal di log mereka. AWS CloudTrail
Untuk mengatur ETL properti streaming untuk Amazon Kinesis Data Streams (AWS Glue APIatau AWS CLI)
-
Untuk mengatur ETL properti streaming untuk sumber Kinesis di akun yang sama, tentukan
streamNamedanendpointUrlparameter dalamStorageDescriptorstrukturCreateTableAPI operasi atau perintah.create_tableCLI"StorageDescriptor": { "Parameters": { "typeOfData": "kinesis", "streamName": "sample-stream", "endpointUrl": "https://kinesis.us-east-1.amazonaws.com" } ... }Atau, tentukan
streamARN."StorageDescriptor": { "Parameters": { "typeOfData": "kinesis", "streamARN": "arn:aws:kinesis:us-east-1:123456789:stream/sample-stream" } ... } -
Untuk mengatur ETL properti streaming untuk sumber Kinesis di akun lain, tentukan parameter
streamARN,awsSTSRoleARNdanawsSTSSessionName(opsional) dalamStorageDescriptorstruktur dalamCreateTableAPI operasi atau perintah.create_tableCLI"StorageDescriptor": { "Parameters": { "typeOfData": "kinesis", "streamARN": "arn:aws:kinesis:us-east-1:123456789:stream/sample-stream", "awsSTSRoleARN": "arn:aws:iam::123456789:role/sample-assume-role-arn", "awsSTSSessionName": "optional-session" } ... }
Sumber data Kafka
Saat membuat tabel, atur ETL properti streaming berikut (konsol).
- Jenis Sumber
-
Kafka
- Untuk sebuah sumber Kafka:
-
- Nama topik
-
Nama topik sebagaimana ditentukan dalam Kafka.
- Koneksi
-
Sesi AWS Glue koneksi yang mereferensikan sumber Kafka, seperti yang dijelaskan dalamMembuat AWS Glue koneksi untuk aliran data Apache Kafka.
AWS Glue Sumber tabel Schema Registry
Untuk menggunakan AWS Glue Schema Registry untuk pekerjaan streaming, ikuti petunjuk di Kasus penggunaan: AWS Glue Data Catalog untuk membuat atau memperbarui tabel Schema Registry.
Saat ini, AWS Glue Streaming hanya mendukung format Glue Schema Registry Avro dengan inferensi skema disetel ke. false
Catatan dan batasan untuk sumber streaming Avro
Catatan dan pembatasan berikut berlaku untuk sumber streaming dalam format Avro:
-
Ketika skema deteksi diaktifkan, skema Avro tersebut harus disertakan dalam muatan. Saat dimatikan, muatan hanya berisi data saja.
-
Beberapa tipe data Avro tidak didukung dalam bingkai dinamis. Anda tidak dapat menentukan tipe data ini saat mendefinisikan skema dengan halaman Tentukan skema dalam panduan buat tabel di AWS Glue konsol. Selama deteksi skema, jenis yang tidak didukung dalam skema Avro dikonversi ke jenis yang didukung sebagai berikut:
-
EnumType => StringType -
FixedType => BinaryType -
UnionType => StructType
-
-
Jika Anda menentukan skema tabel menggunakan halaman Menentukan skema di konsol, maka jenis elemen akar tersirat untuk skema adalah
record. Jika Anda ingin jenis elemen akar selainrecord, misalnyaarrayataumap, Anda tidak dapat menentukan skema menggunakan halaman Menentukan skema. Sebagai gantinya, Anda harus melewati halaman itu dan menentukan skema baik sebagai properti tabel atau di dalam ETL skrip.-
Untuk menentukan skema di properti tabel, selesaikan penuntun membuat tabel, edit detail tabel, dan tambahkan pasangan nilai-kunci baru pada Properti tabel. Gunakan kunci
avroSchema, dan masukkan JSON objek skema untuk nilai, seperti yang ditunjukkan pada gambar berikut.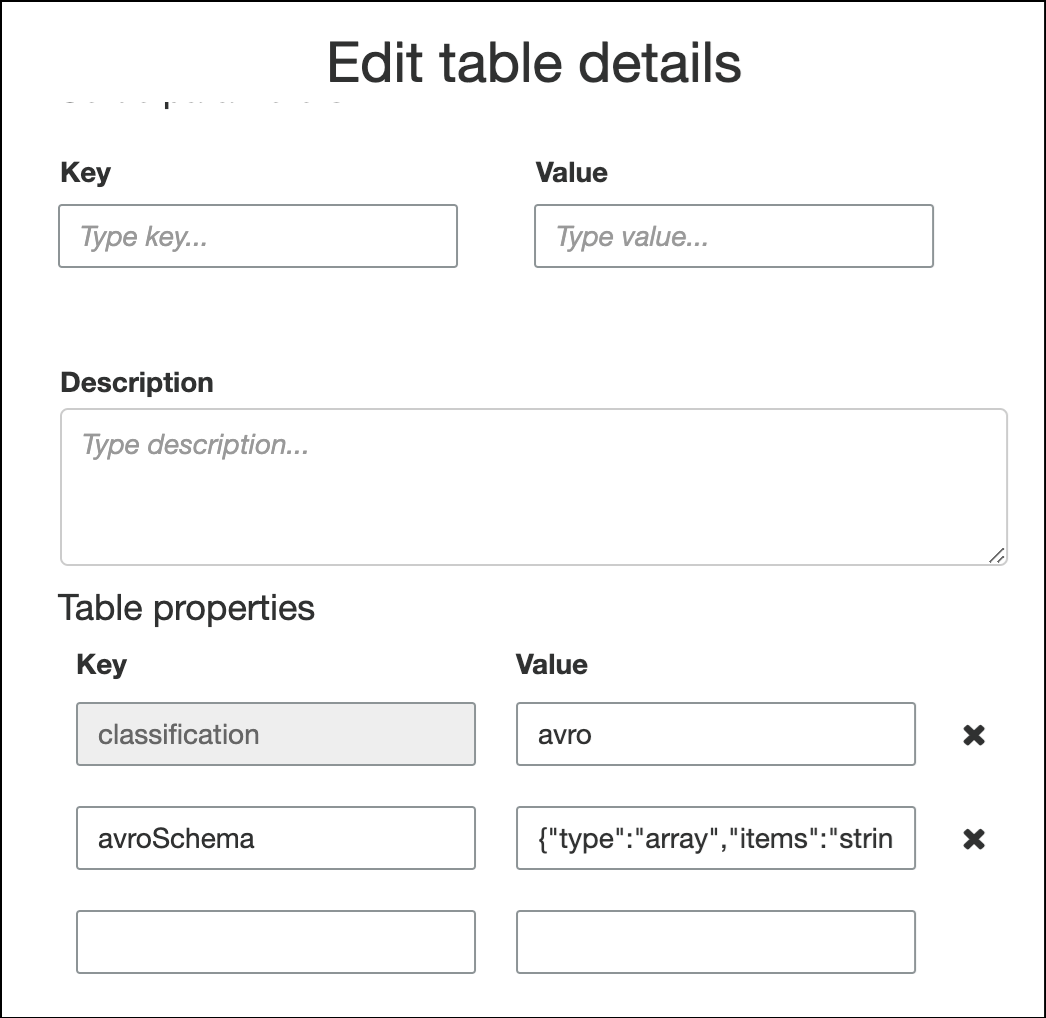
-
Untuk menentukan skema dalam ETL skrip, memodifikasi pernyataan
datasource0penugasan dan menambahkanavroSchemakunci untukadditional_optionsargumen, seperti yang ditunjukkan dalam contoh Python dan Scala berikut.
-
Menerapkan pola grok ke sumber streaming
Anda dapat membuat ETL pekerjaan streaming untuk sumber data log dan menggunakan pola Grok untuk mengonversi log menjadi data terstruktur. ETLPekerjaan kemudian memproses data sebagai sumber data terstruktur. Anda menentukan pola Grok untuk diterapkan saat Anda membuat tabel Katalog Data untuk sumber streaming.
Untuk informasi tentang pola Grok dan nilai-nilai string pola kustom, lihat Menulis pengklasifikasi kustom grok.
Untuk menambahkan pola grok ke tabel Katalog Data (konsol)
-
Gunakan penuntun membuat tabel, dan buatlah tabel dengan parameter yang ditentukan dalam Membuat tabel Katalog Data untuk sumber streaming. Tentukan format data sebagai Grok, isi Pola grok, dan secara opsional, Anda bisa memilih untuk menambahkan pola penyesuaian pada Pola kustom (opsional).
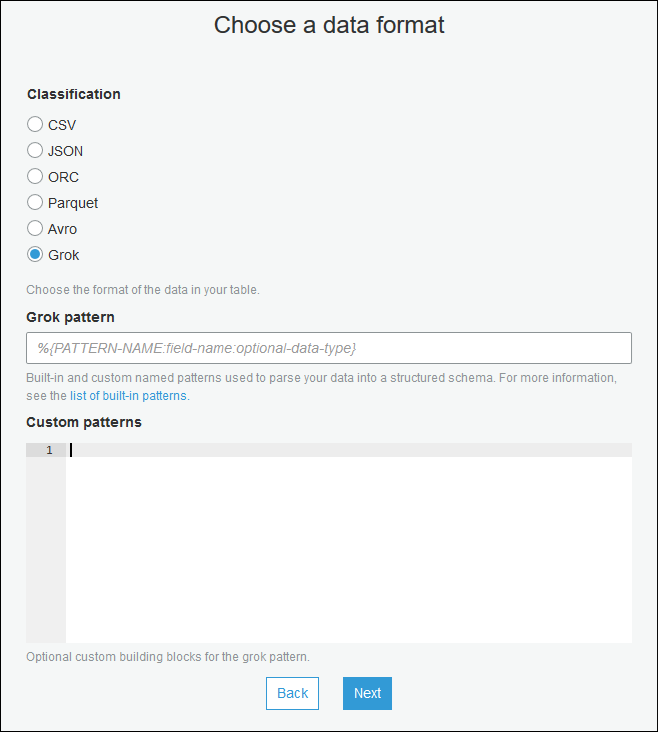
Tekan Enter setelah setiap pola kustom.
Untuk menambahkan pola grok ke tabel Katalog Data (AWS Glue APIatau AWS CLI)
-
Tambahkan
GrokPatternparameter dan opsionalCustomPatternsparameter keCreateTableAPI operasi ataucreate_tableCLI perintah."Parameters": { ... "grokPattern": "string", "grokCustomPatterns": "string", ... },Ekspresikan
grokCustomPatternssebagai string dan gunakan "\n" sebagai pemisah antara pola.Berikut ini adalah contoh cara menentukan parameter ini.
"parameters": { ... "grokPattern": "%{USERNAME:username} %{DIGIT:digit:int}", "grokCustomPatterns": "digit \d", ... }
Mendefinisikan properti pekerjaan untuk pekerjaan streaming ETL
Saat Anda menentukan ETL pekerjaan streaming di AWS Glue konsol, menyediakan properti khusus streaming berikut. Untuk deskripsi tentang properti tugas tambahan, lihat Mendefinisikan properti pekerjaan untuk pekerjaan Spark.
- Peran IAM
-
Tentukan peran AWS Identity and Access Management (IAM) yang digunakan untuk otorisasi sumber daya yang digunakan untuk menjalankan pekerjaan, mengakses sumber streaming, dan mengakses penyimpanan data target.
Untuk akses ke Amazon Kinesis Data Streams,
AmazonKinesisFullAccessAWS lampirkan kebijakan terkelola ke peran, atau lampirkan kebijakan serupa IAM yang mengizinkan akses yang lebih halus. Untuk kebijakan sampel, lihat Mengontrol Akses ke Sumber Daya Amazon Kinesis Data IAM Streams Menggunakan.Untuk informasi selengkapnya tentang izin untuk menjalankan pekerjaan di AWS Glue, lihat Identity and access management untuk AWS Glue.
- Tipe
-
Pilih Spark streaming.
- AWS Glue versi
-
Bagian AWS Glue versi menentukan versi Apache Spark, dan Python atau Scala, yang tersedia untuk pekerjaan itu. Pilih pilihan yang menentukan versi Python atau Scala yang tersedia untuk pekerjaan. AWS Glue Versi 2.0 dengan dukungan Python 3 adalah default untuk pekerjaan streamingETL.
- Periode pemeliharaan
-
Menentukan jendela di mana pekerjaan streaming dapat dimulai ulang. Lihat Jendela pemeliharaan untuk AWS Glue Streaming.
- Tugas habis waktu
-
Opsional, masukkan durasi dalam menit. Nilai defaultnya kosong.
Pekerjaan streaming harus memiliki nilai batas waktu kurang dari 7 hari atau 10080 menit.
Ketika nilai dibiarkan kosong, pekerjaan akan dimulai ulang setelah 7 hari, jika Anda belum menyiapkan jendela pemeliharaan. Jika Anda telah menyiapkan jendela pemeliharaan, pekerjaan akan dimulai kembali selama jendela pemeliharaan setelah 7 hari.
- Sumber data
-
Tentukan tabel yang Anda buat di Membuat tabel Katalog Data untuk sumber streaming.
- Target data
-
Lakukan salah satu hal berikut ini:
-
Pilih Buat tabel di target data Anda dan tentukan properti target data berikut.
- Penyimpanan data
-
Pilih Amazon S3 atau. JDBC
- format
-
Pilih format apa saja. Semua didukung untuk streaming.
-
Pilih Gunakan tabel di katalog data dan perbarui target data Anda, dan pilih tabel untuk penyimpanan JDBC data.
-
- Definisi skema output
-
Lakukan salah satu hal berikut ini:
-
Pilih Secara otomatis mendeteksi skema setiap rekaman untuk mengaktifkan deteksi skema. AWS Glue menentukan skema dari data streaming.
-
Pilih Tentukan skema output untuk semua catatan untuk menggunakan transformasi Terapkan Pemetaan untuk menentukan skema output.
-
- Skrip
-
Opsional, berikan skrip Anda sendiri atau modifikasi skrip yang dihasilkan untuk melakukan operasi yang didukung oleh mesin Apache Spark Structured Streaming. Untuk informasi tentang operasi yang tersedia, lihat Operasi pada streaming DataFrames /Datasets
.
ETLCatatan dan batasan streaming
Ingatlah catatan dan pembatasan berikut:
-
Dekompresi otomatis untuk AWS Glue ETLpekerjaan streaming hanya tersedia untuk jenis kompresi yang didukung. Perhatikan juga hal berikut:
Framed Snappy mengacu pada format pembingkaian
resmi untuk Snappy. Deflate didukung di Glue versi 3.0, bukan Glue versi 2.0.
-
Bila menggunakan deteksi skema, Anda tidak dapat melakukan penggabungan data streaming.
-
AWS Glue ETLpekerjaan streaming tidak mendukung tipe data Union untuk AWS Glue Registri Skema dengan format Avro.
-
ETLSkrip Anda dapat menggunakan AWS Gluetransformasi bawaan dan transformasi asli ke Apache Spark Structured Streaming. Untuk informasi selengkapnya, lihat Operasi pada streaming DataFrames /Datasets
di situs web Apache Spark atau. AWS Glue PySpark mengubah referensi -
AWS Glue ETLpekerjaan streaming menggunakan pos pemeriksaan untuk melacak data yang telah dibaca. Oleh karena itu, tugas yang dihentikan dan dimulai-ulang memilih tempat ia pergi di pengaliran. Jika Anda ingin memproses ulang data, maka Anda dapat menghapus folder pos pemeriksaan yang direferensikan dalam skrip.
-
Bookmark Tugas tidak didukung.
-
Untuk menggunakan fitur fan-out yang disempurnakan dari Kinesis Data Streams dalam pekerjaan Anda, konsultasikan. Menggunakan fan-out yang disempurnakan dalam pekerjaan streaming Kinesis
-
Jika Anda menggunakan tabel Katalog Data yang dibuat dari AWS Glue Schema Registry, ketika versi skema baru tersedia, untuk mencerminkan skema baru, Anda perlu melakukan hal berikut:
-
Hentikan pekerjaan yang terkait dengan tabel.
-
Perbarui skema untuk tabel Katalog Data.
-
Mulai ulang pekerjaan yang terkait dengan tabel.
-
