Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Tutorial: Membuat transformasi pembelajaran mesin dengan AWS Glue
Tutorial ini memandu Anda melakukan tindakan untuk membuat dan mengelola transformasi machine learning (ML) menggunakan AWS Glue. Sebelum menggunakan tutorial ini, Anda harus terbiasa dengan menggunakan konsol AWS Glue untuk menambahkan crawler dan tugas serta mengedit skrip. Anda juga harus terbiasa dengan mencari dan mengunduh file di konsol Amazon Simple Storage Service (Amazon S3).
Dalam contoh ini, Anda membuat sebuah transformasi FindMatches untuk menemukan catatan yang cocok, mengajari cara mengidentifikasi catatan yang cocok dan tidak cocok, dan menggunakannya dalam sebuah tugas AWS Glue. Tugas AWS Glue menulis file Amazon S3 baru dengan sebuah kolom tambahan bernama match_id.
Sumber data yang digunakan oleh tutorial ini adalah sebuah file bernama dblp_acm_records.csv. File ini adalah versi modifikasi dari publikasi akademis (DBLP dan ACM) yang tersedia dari Set data DBLP ACMdblp_acm_records.csvFile tersebut adalah file nilai yang dipisahkan koma (CSV) dalam UTF-8 format tanpa tanda urutan byte (BOM).
File kedua, dblp_acm_labels.csv, adalah contoh file pelabelan yang berisi catatan kecocokan dan catatan ketidakcocokan yang digunakan untuk mengajarkan transformasi sebagai bagian dari tutorial ini.
Topik
Langkah 1: Merayapi data sumber
Pertama, lakukan crawling pada file CSV Amazon S3 sumber untuk membuat sebuah tabel metadata yang sesuai di Katalog Data.
penting
Untuk mengarahkan crawler agar membuat tabel untuk file CSV saja, simpan data sumber CSV di folder Amazon S3 yang berbeda dari file lain.
Masuk ke AWS Management Console dan buka AWS Glue konsol di https://console.aws.amazon.com/glue/
. -
Di panel navigasi, pilih Crawler, Tambahkan crawler.
-
Ikuti penuntun untuk membuat dan menjalankan crawler bernama
demo-crawl-dblp-acmdengan keluaran ke basisdatademo-db-dblp-acm. Saat menjalankan penuntun, buat basis datademo-db-dblp-acmjika itu belum ada. Pilih jalur sertakan Amazon S3 ke data sampel di Wilayah saat ini AWS . Contohnya, untukus-east-1, Amazon S3 mencakup path ke file sumber yaknis3://ml-transforms-public-datasets-us-east-1/dblp-acm/records/dblp_acm_records.csv.Jika berhasil, crawler menciptakan tabel
dblp_acm_records_csvdengan kolom berikut: id, judul, penulis, tempat, tahun, dan sumber.
Langkah 2: Tambahkan transformasi pembelajaran mesin
Selanjutnya, tambahkan sebuah transformasi machine learning yang didasarkan pada skema tabel sumber data yang dibuat oleh crawler bernama demo-crawl-dblp-acm.
-
Di AWS Glue konsol, di panel navigasi di bawah Integrasi Data dan ETL, pilih Alat klasifikasi data > Pencocokan Rekam, lalu Tambahkan transformasi. Ikuti wizard untuk membuat
Find matchestransformasi dengan properti berikut.-
Untuk Nama transformasi, masukkan
demo-xform-dblp-acm. Ini adalah nama transformasi yang digunakan untuk menemukan kecocokan dalam data sumber. -
Untuk IAM role, pilih sebuah IAM role yang memiliki izin ke data sumber Amazon S3, file pelabelan, dan operasi API AWS Glue. Untuk informasi selengkapnya, lihat Membuat IAM role untuk AWS Glue dalam Panduan Developer AWS Glue .
-
Untuk Sumber data, pilih tabel bernama dblp_acm_records_csv dalam basis data demo-db-dblp-acm.
-
Untuk Kunci primer, pilih kolom kunci primer untuk tabel, id.
-
Dalam penuntun, pilih Selesai dan kembali ke daftar Transformasi ML.
Langkah 3: Ajarkan transformasi pembelajaran mesin Anda
Selanjutnya, Anda ajari transformasi machine learning Anda dengan menggunakan file pelabelan sampel dalam tutorial ini.
Anda tidak dapat menggunakan transformasi bahasa mesin dalam tugas extract, transform, and load (ETL) sampai statusnya Siap digunakan. Agar transformasi Anda siap, maka Anda harus mengajarinya cara mengidentifikasi catatan kecocokan dan ketidakcocokan dengan memberikan contoh catatan kecocokan dan ketidakcocokan. Untuk mengajarkan transformasi Anda, Anda dapat Buat sebuah file label, menambahkan label, dan kemudian Unggah file label. Dalam tutorial ini, Anda dapat menggunakan contoh file pelabelan bernama dblp_acm_labels.csv. Untuk informasi selengkapnya tentang proses pelabelan, lihat Pelabelan.
-
Di AWS Glue konsol, di panel navigasi, pilih Rekam Pencocokan.
-
Pilih transformasi
demo-xform-dblp-acm, dan kemudian pilih Tindakan, Ajarkan. Ikuti panduan untuk mengajar transformasiFind matchesAnda. Pada halaman properti transformasi, pilih Saya memiliki label. Pilih jalur Amazon S3 ke file pelabelan sampel di Wilayah saat ini. AWS Contohnya, untuk
us-east-1, unggah file pelabelan yang tersedia dari path Amazon S3s3://ml-transforms-public-datasets-us-east-1/dblp-acm/labels/dblp_acm_labels.csvdengan opsi menimpa label yang ada. File pelabelan harus ditempatkan di Amazon S3 dengan Wilayah yang sama dengan konsol AWS Glue.Ketika Anda mengunggah file pelabelan, sebuah tugas dimulai di AWS Glue untuk menambah atau menimpa label yang digunakan untuk mengajar transformasi cara memproses sumber data.
Di halaman terakhir penuntun, pilih Selesai, dan kembali ke daftar Transformasi ML.
Langkah 4: Perkirakan kualitas transformasi pembelajaran mesin Anda
Selanjutnya, Anda dapat memperkirakan kualitas transformasi machine learning Anda. Kualitasnya tergantung pada berapa banyak pelabelan yang telah Anda lakukan. Untuk informasi selengkapnya tentang cara memperkirakan kualitas, lihat Estimasi kualitas.
-
Di AWS Glue konsol, di panel navigasi di bawah Integrasi Data dan ETL, pilih Alat klasifikasi data > Pencocokan Rekam.
-
Pilih transformasi
demo-xform-dblp-acm, dan pilih tab Estimasi kualitas. Tab ini menampilkan perkiraan kualitas saat ini, jika tersedia, untuk transformasi tersebut. Pilih Estimasi kualitas untuk memulai sebuah tugas untuk memperkirakan kualitas transformasi. Keakuratan estimasi kualitas tersebut didasarkan pada pelabelan data sumber.
Arahkan ke tab Riwayat. Dalam panel ini, eksekusi tugas dicantumkan untuk transformasi, termasuk tugas Estimasi kualitas. Untuk detail lebih lanjut tentang eksekusi, pilih Log. Periksa apakah status eksekusi adalah Berhasil ketika selesai.
Langkah 5: Tambahkan dan jalankan pekerjaan dengan transformasi pembelajaran mesin Anda
Pada langkah ini, Anda menggunakan transformasi machine learning Anda untuk menambah dan menjalankan tugas di AWS Glue. Saat transformasi demo-xform-dblp-acm sudah Siap digunakan, Anda dapat menggunakannya dalam tugas ETL.
-
Pada konsol AWS Glue, di panel navigasi, pilih Tugas.
-
Pilih Tambahkan tugas, dan ikuti langkah-langkah yang ada di penuntun untuk membuat tugas ETL Spark dengan skrip yang sudah dihasilkan. Pilih nilai-nilai properti berikut untuk transformasi Anda:
-
Untuk Nama, pilih contoh tugas dalam tutorial ini, demo-etl-dblp-acm.
-
Untuk IAM role, pilih IAM role dengan izin ke data sumber Amazon S3, file pelabelan, dan operasi API AWS Glue. Untuk informasi selengkapnya, lihat Membuat IAM role untuk AWS Glue dalam Panduan Developer AWS Glue .
-
Untuk Bahasa ETL, pilih Scala. Ini adalah bahasa pemrograman dalam skrip ETL.
-
Untuk Nama file skrip, pilih demo-etl-dblp-acm. Ini adalah nama file dari skrip Scala (sama dengan nama tugas).
-
Untuk Sumber data, pilih dblp_acm_records_csv. Sumber data yang Anda pilih harus sesuai dengan skema sumber data transformasi machine learning.
-
Untuk Jenis transformasi, pilih Temukan catatan yang cocok untuk membuat sebuah tugas dengan menggunakan transformasi machine learning.
-
Bersihkan Hapus catatan duplikasi. Anda tidak ingin menghapus catatan duplikat karena catatan keluaran yang ditulis memiliki tambahan kolom
match_idyang ditambahkan. -
Untuk Transformasi, pilih demo-xform-dblp-acm, transformasi machine learning yang digunakan oleh tugas.
-
Untuk Buat tabel di target data Anda, pilih untuk membuat tabel dengan properti berikut:
-
Jenis penyimpanan data —
Amazon S3 -
Format —
CSV -
Jenis kompresi —
None -
Jalur target - Jalur Amazon S3 tempat output pekerjaan ditulis (di Wilayah konsol AWS saat ini)
-
-
-
Pilih Simpan tugas dan edit skrip untuk menampilkan halaman editor skrip.
-
Edit skrip untuk menambahkan pernyataan untuk menyebabkan output tugas untuk Path target untuk ditulis ke satu file partisi tunggal. Tambahkan pernyataan ini segera setelah pernyataan yang menjalankan transformasi
FindMatches. Pernyataan tersebut serupa dengan yang berikut ini.val single_partition = findmatches1.repartition(1)Anda harus mengubah pernyataan
.writeDynamicFrame(findmatches1)untuk menulis output sebagai.writeDynamicFrame(single_partion). -
Setelah Anda mengedit skrip, pilih Simpan. Skrip yang sudah dimodifikasi terlihat mirip dengan kode berikut, tapi disesuaikan untuk lingkungan Anda.
import com.amazonaws.services.glue.GlueContext import com.amazonaws.services.glue.errors.CallSite import com.amazonaws.services.glue.ml.FindMatches import com.amazonaws.services.glue.util.GlueArgParser import com.amazonaws.services.glue.util.Job import com.amazonaws.services.glue.util.JsonOptions import org.apache.spark.SparkContext import scala.collection.JavaConverters._ object GlueApp { def main(sysArgs: Array[String]) { val spark: SparkContext = new SparkContext() val glueContext: GlueContext = new GlueContext(spark) // @params: [JOB_NAME] val args = GlueArgParser.getResolvedOptions(sysArgs, Seq("JOB_NAME").toArray) Job.init(args("JOB_NAME"), glueContext, args.asJava) // @type: DataSource // @args: [database = "demo-db-dblp-acm", table_name = "dblp_acm_records_csv", transformation_ctx = "datasource0"] // @return: datasource0 // @inputs: [] val datasource0 = glueContext.getCatalogSource(database = "demo-db-dblp-acm", tableName = "dblp_acm_records_csv", redshiftTmpDir = "", transformationContext = "datasource0").getDynamicFrame() // @type: FindMatches // @args: [transformId = "tfm-123456789012", emitFusion = false, survivorComparisonField = "<primary_id>", transformation_ctx = "findmatches1"] // @return: findmatches1 // @inputs: [frame = datasource0] val findmatches1 = FindMatches.apply(frame = datasource0, transformId = "tfm-123456789012", transformationContext = "findmatches1", computeMatchConfidenceScores = true)// Repartition the previous DynamicFrame into a single partition. val single_partition = findmatches1.repartition(1)// @type: DataSink // @args: [connection_type = "s3", connection_options = {"path": "s3://aws-glue-ml-transforms-data/sal"}, format = "csv", transformation_ctx = "datasink2"] // @return: datasink2 // @inputs: [frame = findmatches1] val datasink2 = glueContext.getSinkWithFormat(connectionType = "s3", options = JsonOptions("""{"path": "s3://aws-glue-ml-transforms-data/sal"}"""), transformationContext = "datasink2", format = "csv").writeDynamicFrame(single_partition) Job.commit() } } Pilih Jalankan tugas untuk memulai eksekusi tugas. Periksa status tugas dalam daftar tugas. Setelah tugas selesai, di Transformasi ML, tab Riwayat, ada baris ID eksekusi baru yang ditambahkan dari jenis Tugas ETL.
Arahkan ke Tugas, tab Riwayat. Dalam panel ini, eksekusi tugas dicantumkan. Untuk detail lebih lanjut tentang eksekusi, pilih Log. Periksa apakah status eksekusi adalah Berhasil ketika selesai.
Langkah 6: Verifikasi data keluaran dari Amazon S3
Pada langkah ini, Anda memeriksa output dari eksekusi tugas di bucket Amazon S3 yang Anda pilih ketika Anda menambahkan tugas. Anda dapat mengunduh file output ke komputer lokal Anda dan memverifikasi bahwa catatan kecocokan telah diidentifikasi.
Buka konsol Amazon S3 di. https://console.aws.amazon.com/s3/
Unduh file output target dari tugas
demo-etl-dblp-acm. Buka file dalam aplikasi spreadsheet (Anda mungkin perlu menambahkan ekstensi file.csvpada file untuk membukanya dengan benar).Gambar berikut menunjukkan kutipan dari output pada Microsoft Excel.
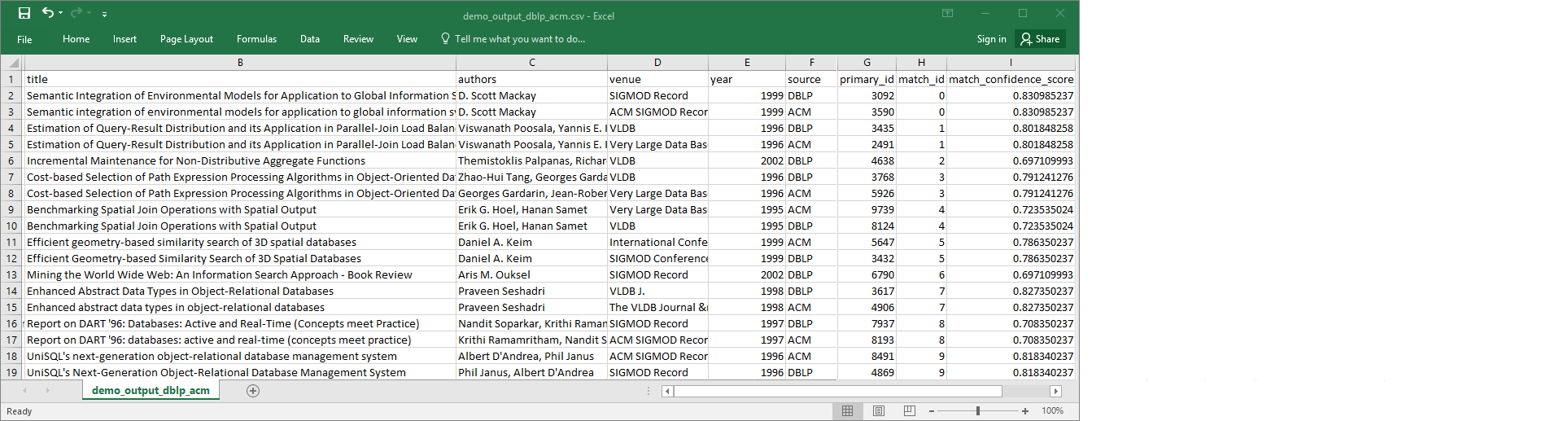
Sumber data dan file target keduanya memiliki 4.911 catatan. Namun, transformasi
Find matchesmenambahkan kolom lain bernamamatch_iduntuk mengidentifikasi catatan kecocokan dalam output. Baris denganmatch_idyang sama dianggap catatan yang cocok.match_confidence_scoreIni adalah angka antara 0 dan 1 yang memberikan perkiraan kualitas kecocokan yang ditemukan olehFind matches.-
Urutkan file output berdasarkan
match_iduntuk dengan mudah melihat catatan mana yang cocok. Bandingkan nilai di kolom lain untuk melihat apakah Anda setuju dengan hasil transformasiFind matches. Jika tidak, Anda dapat terus mengajarkan transformasi dengan menambahkan lebih banyak label lainnya.Anda juga dapat mengurutkan file berdasarkan kolom lain, seperti
title, untuk melihat apakah catatan dengan judul serupa memilikimatch_idyang sama.
