Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Pemantauan dengan AWS Glue Metrik observabilitas
catatan
AWS GlueMetrik observabilitas tersedia di AWS Glue versi 4.0 dan yang lebih baru.
Gunakan metrik AWS Glue Observability untuk menghasilkan wawasan tentang apa yang terjadi di dalam pekerjaan Apache Spark Anda AWS Glue untuk meningkatkan triaging dan analisis masalah. Metrik observabilitas divisualisasikan melalui Amazon CloudWatch dasbor dan dapat digunakan untuk membantu melakukan analisis akar penyebab kesalahan dan untuk mendiagnosis kemacetan kinerja. Anda dapat mengurangi waktu yang dihabiskan masalah debugging dalam skala besar sehingga Anda dapat fokus pada penyelesaian masalah lebih cepat dan lebih efektif.
AWS GlueObservabilitas menyediakan Amazon CloudWatch metrik yang dikategorikan dalam empat kelompok berikut:
-
Keandalan (yaitu, Kelas Kesalahan) — dengan mudah mengidentifikasi alasan kegagalan yang paling umum pada rentang waktu tertentu yang mungkin ingin Anda atasi.
-
Kinerja (yaitu, Skewness) - mengidentifikasi hambatan kinerja dan menerapkan teknik penyetelan. Misalnya, ketika Anda mengalami penurunan kinerja karena kemiringan pekerjaan, Anda mungkin ingin mengaktifkan Eksekusi Kueri Adaptif Spark dan menyempurnakan ambang gabungan miring.
-
Throughput (yaitu, per source/sink throughput) — memantau tren membaca dan menulis data. Anda juga dapat mengonfigurasi Amazon CloudWatch alarm untuk anomali.
-
Pemanfaatan Sumber Daya (yaitu, pekerja, memori dan pemanfaatan disk) — secara efisien menemukan pekerjaan dengan pemanfaatan kapasitas rendah. Anda mungkin ingin mengaktifkan AWS Glue auto-scaling untuk pekerjaan tersebut.
Memulai dengan AWS Glue Metrik observabilitas
catatan
Metrik baru diaktifkan secara default di AWS Glue Studio konsol.
Untuk mengonfigurasi metrik observabilitas di AWS Glue Studio:
-
Masuk ke AWS Glue konsol dan pilih pekerjaan ETL dari menu konsol.
-
Pilih pekerjaan dengan mengklik nama pekerjaan di bagian Pekerjaan Anda.
-
Pilih tab Detail tugas.
-
Gulir ke bawah dan pilih Advanced properties, lalu Job observability metrics.
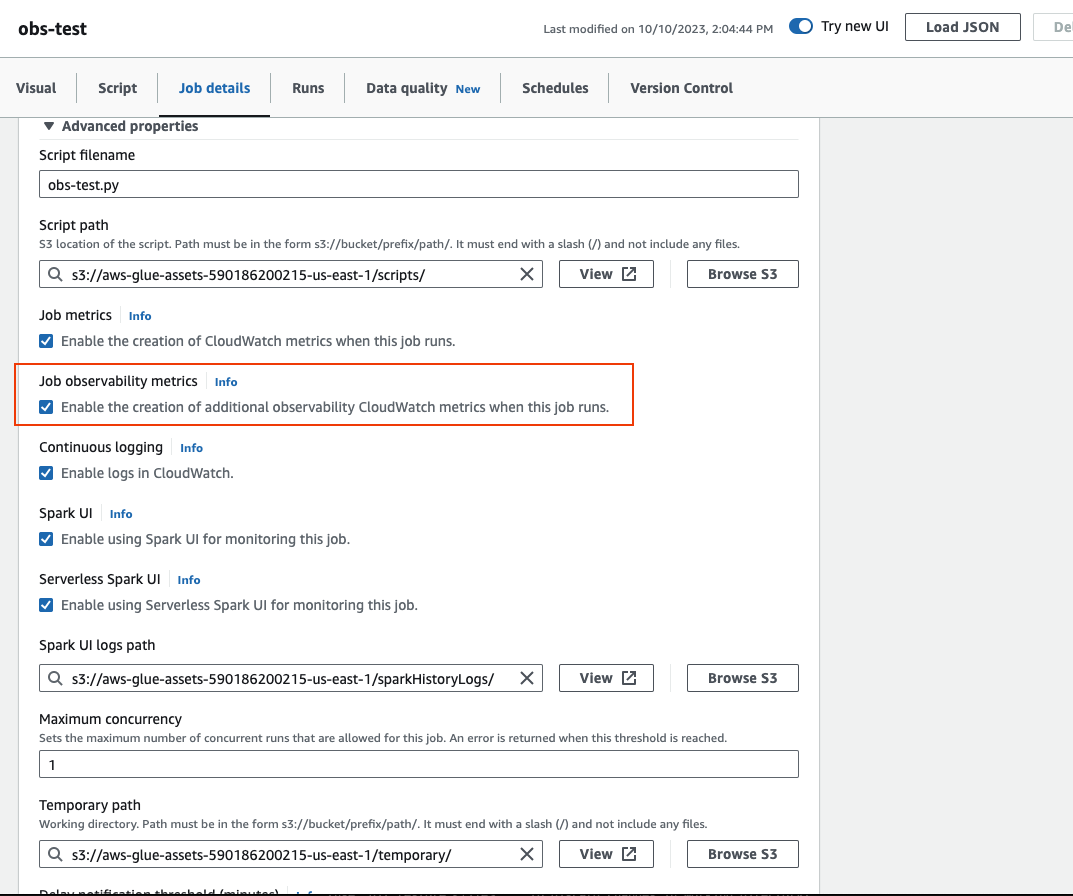
Untuk mengaktifkan AWS Glue Metrik observabilitas menggunakan AWS CLI:
-
Tambahkan ke
--default-argumentspeta kunci-nilai berikut dalam file JSON masukan:--enable-observability-metrics, true
Penggunaan AWS Glue observabilitas
Karena metrik AWS Glue observabilitas disediakan Amazon CloudWatch, Anda dapat menggunakan Amazon CloudWatch konsol, SDK AWS CLI, atau API untuk menanyakan titik data metrik observabilitas. Lihat Menggunakan Glue Observability untuk memantau pemanfaatan sumber daya guna mengurangi biaya
Penggunaan AWS Glue observabilitas di Amazon CloudWatch konsol
Untuk menanyakan dan memvisualisasikan metrik di Amazon CloudWatch konsol:
-
Buka Amazon CloudWatch konsol dan pilih Semua metrik.
-
Di bawah ruang nama khusus, pilih. AWS Glue
-
Pilih Metrik Observabilitas Pekerjaan, Metrik Observabilitas Per Sumber, atau Metrik Observabilitas Per Wastafel.
-
Cari nama metrik tertentu, nama pekerjaan, ID jalankan pekerjaan, dan pilih.
-
Di bawah tab Metrik grafik, konfigurasikan statistik pilihan Anda, periode, dan opsi lainnya.
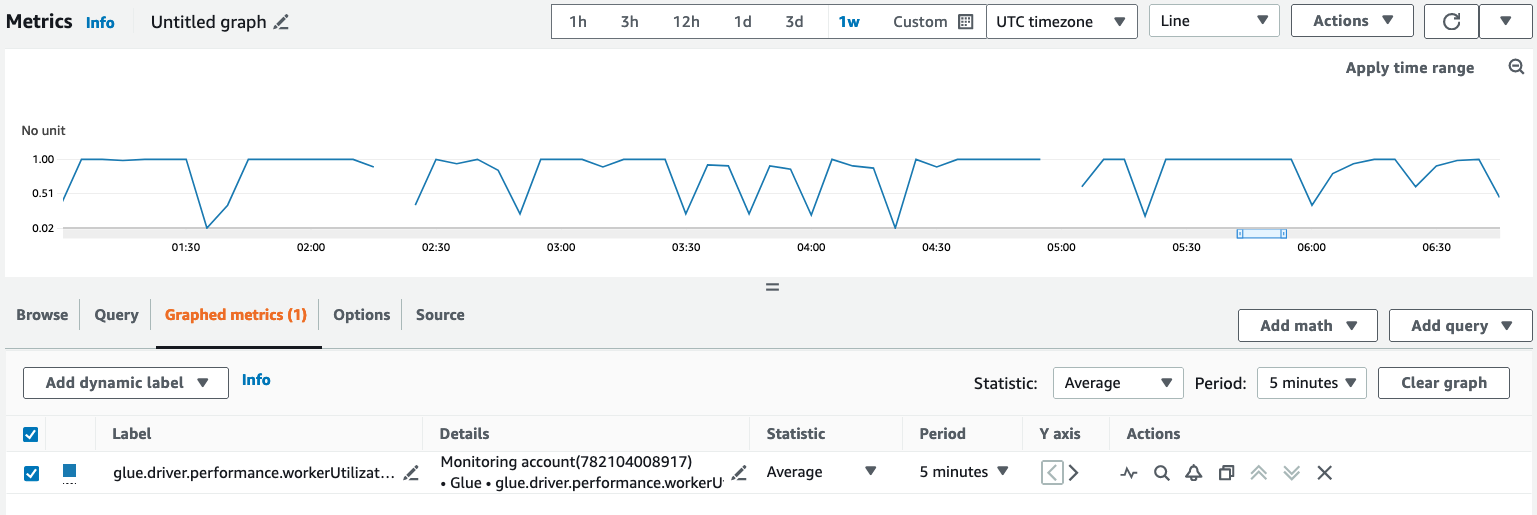
Untuk menanyakan metrik Observabilitas menggunakan AWS CLI:
-
Buat file JSON definisi metrik dan ganti
your-Glue-job-namedanyour-Glue-job-run-iddengan milik Anda.$ cat multiplequeries.json [ { "Id": "avgWorkerUtil_0", "MetricStat": { "Metric": { "Namespace": "Glue", "MetricName": "glue.driver.workerUtilization", "Dimensions": [ { "Name": "JobName", "Value": "<your-Glue-job-name-A>" }, { "Name": "JobRunId", "Value": "<your-Glue-job-run-id-A>" }, { "Name": "Type", "Value": "gauge" }, { "Name": "ObservabilityGroup", "Value": "resource_utilization" } ] }, "Period": 1800, "Stat": "Minimum", "Unit": "None" } }, { "Id": "avgWorkerUtil_1", "MetricStat": { "Metric": { "Namespace": "Glue", "MetricName": "glue.driver.workerUtilization", "Dimensions": [ { "Name": "JobName", "Value": "<your-Glue-job-name-B>" }, { "Name": "JobRunId", "Value": "<your-Glue-job-run-id-B>" }, { "Name": "Type", "Value": "gauge" }, { "Name": "ObservabilityGroup", "Value": "resource_utilization" } ] }, "Period": 1800, "Stat": "Minimum", "Unit": "None" } } ] -
Jalankan perintah
get-metric-data:$ aws cloudwatch get-metric-data --metric-data-queries file: //multiplequeries.json \ --start-time '2023-10-28T18: 20' \ --end-time '2023-10-28T19: 10' \ --region us-east-1 { "MetricDataResults": [ { "Id": "avgWorkerUtil_0", "Label": "<your-label-for-A>", "Timestamps": [ "2023-10-28T18:20:00+00:00" ], "Values": [ 0.06718750000000001 ], "StatusCode": "Complete" }, { "Id": "avgWorkerUtil_1", "Label": "<your-label-for-B>", "Timestamps": [ "2023-10-28T18:50:00+00:00" ], "Values": [ 0.5959183673469387 ], "StatusCode": "Complete" } ], "Messages": [] }
Metrik observabilitas
AWS GlueProfil observabilitas dan mengirimkan metrik berikut ke Amazon CloudWatch setiap 30 detik, dan beberapa metrik ini dapat terlihat di Halaman Pemantauan AWS Glue Studio Job Runs.
| Metrik | Deskripsi | Kategori |
|---|---|---|
| lem.driver.skewness.stage |
Kategori Metrik: job_performance Spark stage eksekusi Skewness: metrik ini merupakan indikator berapa lama waktu durasi tugas maksimum dalam tahap tertentu dibandingkan dengan durasi tugas median pada tahap ini. Ini menangkap kemiringan eksekusi, yang mungkin disebabkan oleh kemiringan data input atau oleh transformasi (misalnya, gabungan miring). Nilai metrik ini jatuh ke dalam kisaran [0, tak terhingga [, di mana 0 berarti rasio waktu eksekusi tugas maksimum terhadap median, di antara semua tugas dalam tahap kurang dari faktor kemiringan tahap tertentu. Faktor kemiringan tahap default adalah `5` dan dapat ditimpa melalui spark conf: spark.metrics.conf.driver.source.glue.job Performance.skewnessFactor Nilai kemiringan tahap 1 berarti rasio dua kali faktor kemiringan tahap. Nilai kemiringan panggung diperbarui setiap 30 detik untuk mencerminkan kemiringan saat ini. Nilai pada akhir tahap mencerminkan kemiringan tahap akhir. Metrik tingkat tahap ini digunakan untuk menghitung metrik tingkat pekerjaan. Dimensi yang valid: JobName (nama AWS Glue Job), JobRunId ( JobRun ID. atau ALL), Type (gauge), dan ObservabilityGroup (job_performance) Statistik yang Valid: Rata-rata, Maksimum, Minimum, Persentil Unit: Jumlah |
job_kinerja |
| lem.driver.skewness.job |
Kategori Metrik: job_performance Job skewness adalah kemiringan tertimbang maksimum dari semua tahapan. Kemiringan panggung (lem.driver.skewness.stage) ditimbang dengan durasi panggung. Ini untuk menghindari kasus sudut ketika tahap yang sangat miring sebenarnya berjalan untuk waktu yang sangat singkat relatif terhadap tahap lain (dan dengan demikian kemiringannya tidak signifikan untuk kinerja pekerjaan secara keseluruhan dan tidak sepadan dengan upaya untuk mencoba mengatasi kemiringannya). Metrik ini diperbarui setelah menyelesaikan setiap tahap, dan dengan demikian nilai terakhir mencerminkan kemiringan pekerjaan keseluruhan yang sebenarnya. Dimensi yang valid: JobName (nama AWS Glue Job), JobRunId ( JobRun ID. atau ALL), Type (gauge), dan ObservabilityGroup (job_performance) Statistik yang Valid: Rata-rata, Maksimum, Minimum, Persentil Unit: Jumlah |
job_kinerja |
| lem.berhasil.semua |
Kategori Metrik: kesalahan Jumlah total pekerjaan yang berhasil berjalan, untuk melengkapi gambaran kategori kegagalan Dimensi yang valid: JobName (nama AWS Glue Job), JobRunId ( JobRun ID. atau ALL), Type (count), dan ObservabilityGroup (error) Statistik yang Valid: SUM Unit: Jumlah |
kesalahan |
| lem.error.all |
Kategori Metrik: kesalahan Jumlah total kesalahan menjalankan pekerjaan, untuk melengkapi gambaran kategori kegagalan Dimensi yang valid: JobName (nama AWS Glue Job), JobRunId ( JobRun ID. atau ALL), Type (count), dan ObservabilityGroup (error) Statistik yang Valid: SUM Unit: Jumlah |
kesalahan |
| lem.error. [kategori kesalahan] |
Kategori Metrik: kesalahan Ini sebenarnya adalah satu set metrik, yang diperbarui hanya ketika pekerjaan berjalan gagal. Kategorisasi kesalahan membantu dengan triaging dan debugging. Ketika pekerjaan berjalan gagal, kesalahan yang menyebabkan kegagalan dikategorikan dan metrik kategori kesalahan yang sesuai disetel ke 1. Ini membantu untuk melakukan analisis kegagalan dari waktu ke waktu, serta atas semua analisis kesalahan pekerjaan untuk mengidentifikasi kategori kegagalan yang paling umum untuk mulai mengatasinya. AWS Gluememiliki 28 kategori kesalahan, termasuk kategori kesalahan OUT_OF_MEMORY (driver dan eksekutor), PERMISSION, SYNTAX dan THROTTLING. Kategori kesalahan juga mencakup kategori kesalahan KOMPILASI, PELUNCURAN, dan TIMEOUT. Dimensi yang valid: JobName (nama AWS Glue Job), JobRunId ( JobRun ID. atau ALL), Type (count), dan ObservabilityGroup (error) Statistik yang Valid: SUM Unit: Jumlah |
kesalahan |
| Glue.driver.workerUtilization |
Kategori Metrik: resource_utilization Persentase pekerja yang dialokasikan yang benar-benar digunakan. Jika tidak bagus, penskalaan otomatis dapat membantu. Dimensi yang valid: JobName (nama AWS Glue Job), JobRunId ( JobRun ID. atau ALL), Type (gauge), dan ObservabilityGroup (resource_utilization) Statistik yang Valid: Rata-rata, Maksimum, Minimum, Persentil Unit: Persentase |
resource_utilization |
| lem.driver.memory.heap. [tersedia | digunakan] |
Kategori Metrik: resource_utilization Memori heap driver yang tersedia/digunakan selama pekerjaan dijalankan. Ini membantu untuk memahami tren penggunaan memori, terutama dari waktu ke waktu, yang dapat membantu menghindari potensi kegagalan, selain men-debug kegagalan terkait memori. Dimensi yang valid: JobName (nama AWS Glue Job), JobRunId ( JobRun ID. atau ALL), Type (gauge), dan ObservabilityGroup (resource_utilization) Statistik yang Valid: Rata-rata Unit: Bita |
resource_utilization |
| lem.driver.memory.heap.used.percentage |
Kategori Metrik: resource_utilization Pengemudi menggunakan memori heap (%) selama pekerjaan dijalankan. Ini membantu untuk memahami tren penggunaan memori, terutama dari waktu ke waktu, yang dapat membantu menghindari potensi kegagalan, selain men-debug kegagalan terkait memori. Dimensi yang valid: JobName (nama AWS Glue Job), JobRunId ( JobRun ID. atau ALL), Type (gauge), dan ObservabilityGroup (resource_utilization) Statistik yang Valid: Rata-rata Unit: Persentase |
resource_utilization |
| lem.driver.memory.non-heap. [tersedia | digunakan] |
Kategori Metrik: resource_utilization Pengemudi yang tersedia/menggunakan memori non-heap selama pekerjaan dijalankan. Ini membantu untuk memahami tren penggunaan memori, terutama dari waktu ke waktu, yang dapat membantu menghindari potensi kegagalan, selain men-debug kegagalan terkait memori. Dimensi yang valid: JobName (nama AWS Glue Job), JobRunId ( JobRun ID. atau ALL), Type (gauge), dan ObservabilityGroup (resource_utilization) Statistik yang Valid: Rata-rata Unit: Bita |
resource_utilization |
| lem.driver.memory.non-heap.used.percentage |
Kategori Metrik: resource_utilization Pengemudi menggunakan memori non-heap (%) selama pekerjaan dijalankan. Ini membantu untuk memahami tren penggunaan memori, terutama dari waktu ke waktu, yang dapat membantu menghindari potensi kegagalan, selain men-debug kegagalan terkait memori. Dimensi yang valid: JobName (nama AWS Glue Job), JobRunId ( JobRun ID. atau ALL), Type (gauge), dan ObservabilityGroup (resource_utilization) Statistik yang Valid: Rata-rata Unit: Persentase |
resource_utilization |
| lem.driver.memory.total. [tersedia | digunakan] |
Kategori Metrik: resource_utilization Pengemudi tersedia/menggunakan memori total selama pekerjaan dijalankan. Ini membantu untuk memahami tren penggunaan memori, terutama dari waktu ke waktu, yang dapat membantu menghindari potensi kegagalan, selain men-debug kegagalan terkait memori. Dimensi yang valid: JobName (nama AWS Glue Job), JobRunId ( JobRun ID. atau ALL), Type (gauge), dan ObservabilityGroup (resource_utilization) Statistik yang Valid: Rata-rata Unit: Bita |
resource_utilization |
| lem.driver.memory.total.used.percentage |
Kategori Metrik: resource_utilization Pengemudi menggunakan (%) total memori selama menjalankan pekerjaan. Ini membantu untuk memahami tren penggunaan memori, terutama dari waktu ke waktu, yang dapat membantu menghindari potensi kegagalan, selain men-debug kegagalan terkait memori. Dimensi yang valid: JobName (nama AWS Glue Job), JobRunId ( JobRun ID. atau ALL), Type (gauge), dan ObservabilityGroup (resource_utilization) Statistik yang Valid: Rata-rata Unit: Persentase |
resource_utilization |
| lem. ALL.memory.heap. [tersedia | digunakan] |
Kategori Metrik: resource_utilization Memori tumpukan eksekutor. available/used SEMUA berarti semua pelaksana. Dimensi yang valid: JobName (nama AWS Glue Job), JobRunId ( JobRun ID. atau ALL), Type (gauge), dan ObservabilityGroup (resource_utilization) Statistik yang Valid: Rata-rata Unit: Bita |
resource_utilization |
| lem. ALL.memory.heap.used.percentage |
Kategori Metrik: resource_utilization Memori heap (%) yang digunakan para eksekutor. SEMUA berarti semua pelaksana. Dimensi yang valid: JobName (nama AWS Glue Job), JobRunId ( JobRun ID. atau ALL), Type (gauge), dan ObservabilityGroup (resource_utilization) Statistik yang Valid: Rata-rata Unit: Persentase |
resource_utilization |
| lem. ALL.memory.non-heap. [tersedia | digunakan] |
Kategori Metrik: resource_utilization Memori non-heap eksekutor available/used . SEMUA berarti semua pelaksana. Dimensi yang valid: JobName (nama AWS Glue Job), JobRunId ( JobRun ID. atau ALL), Type (gauge), dan ObservabilityGroup (resource_utilization) Statistik yang Valid: Rata-rata Unit: Bita |
resource_utilization |
| lem. ALL.memory.non-heap.used.percentage |
Kategori Metrik: resource_utilization Eksekutor menggunakan (%) memori non-heap. SEMUA berarti semua pelaksana. Dimensi yang valid: JobName (nama AWS Glue Job), JobRunId ( JobRun ID. atau ALL), Type (gauge), dan ObservabilityGroup (resource_utilization) Statistik yang Valid: Rata-rata Unit: Persentase |
resource_utilization |
| lem. ALL.memory.total. [tersedia | digunakan] |
Kategori Metrik: resource_utilization Memori total eksekutor. available/used SEMUA berarti semua pelaksana. Dimensi yang valid: JobName (nama AWS Glue Job), JobRunId ( JobRun ID. atau ALL), Type (gauge), dan ObservabilityGroup (resource_utilization) Statistik yang Valid: Rata-rata Unit: Bita |
resource_utilization |
| lem. ALL.memory.total.used.percentage |
Kategori Metrik: resource_utilization Eksekutor menggunakan (%) total memori. SEMUA berarti semua pelaksana. Dimensi yang valid: JobName (nama AWS Glue Job), JobRunId ( JobRun ID. atau ALL), Type (gauge), dan ObservabilityGroup (resource_utilization) Statistik yang Valid: Rata-rata Unit: Persentase |
resource_utilization |
| lem.driver.disk. [tersedia_GB | digunakan_GB] |
Kategori Metrik: resource_utilization Ruang available/used disk pengemudi selama pekerjaan dijalankan. Ini membantu untuk memahami tren penggunaan disk, terutama dari waktu ke waktu, yang dapat membantu menghindari potensi kegagalan, selain debugging tidak cukup kegagalan terkait ruang disk. Dimensi yang valid: JobName (nama AWS Glue Job), JobRunId ( JobRun ID. atau ALL), Type (gauge), dan ObservabilityGroup (resource_utilization) Statistik yang Valid: Rata-rata Satuan: Gigabytes |
resource_utilization |
| lem.driver.disk.used.percentage] |
Kategori Metrik: resource_utilization Ruang available/used disk pengemudi selama pekerjaan dijalankan. Ini membantu untuk memahami tren penggunaan disk, terutama dari waktu ke waktu, yang dapat membantu menghindari potensi kegagalan, selain debugging tidak cukup kegagalan terkait ruang disk. Dimensi yang valid: JobName (nama AWS Glue Job), JobRunId ( JobRun ID. atau ALL), Type (gauge), dan ObservabilityGroup (resource_utilization) Statistik yang Valid: Rata-rata Unit: Persentase |
resource_utilization |
| lem. ALL.disk. [tersedia_GB | digunakan_GB] |
Kategori Metrik: resource_utilization Ruang disk para eksekutor. available/used SEMUA berarti semua pelaksana. Dimensi yang valid: JobName (nama AWS Glue Job), JobRunId ( JobRun ID. atau ALL), Type (gauge), dan ObservabilityGroup (resource_utilization) Statistik yang Valid: Rata-rata Satuan: Gigabytes |
resource_utilization |
| lem. ALL.disk.used.percentage |
Kategori Metrik: resource_utilization Ruang disk eksekutor available/used /used (%). SEMUA berarti semua pelaksana. Dimensi yang valid: JobName (nama AWS Glue Job), JobRunId ( JobRun ID. atau ALL), Type (gauge), dan ObservabilityGroup (resource_utilization) Statistik yang Valid: Rata-rata Unit: Persentase |
resource_utilization |
| Lek.driver.bytesRead |
Kategori Metrik: throughput Jumlah byte yang dibaca per sumber input dalam pekerjaan ini dijalankan, serta untuk SEMUA sumber. Ini membantu memahami volume data dan perubahannya dari waktu ke waktu, yang membantu mengatasi masalah seperti kemiringan data. Dimensi yang valid: JobName (nama AWS Glue Job), JobRunId ( JobRun ID. atau ALL), Type (gauge), (resource_utilization), dan Source ObservabilityGroup (lokasi data sumber) Statistik yang Valid: Rata-rata Unit: Bita |
throughput |
| lem.driver. [RecordsRead | FilesRead] |
Kategori Metrik: throughput Jumlah records/files pembacaan per sumber input dalam pekerjaan ini dijalankan, serta untuk SEMUA sumber. Ini membantu memahami volume data dan perubahannya dari waktu ke waktu, yang membantu mengatasi masalah seperti kemiringan data. Dimensi yang valid: JobName (nama AWS Glue Job), JobRunId ( JobRun ID. atau ALL), Type (gauge), (resource_utilization), dan Source ObservabilityGroup (lokasi data sumber) Statistik yang Valid: Rata-rata Unit: Jumlah |
throughput |
| lem.driver.partitionsRead |
Kategori Metrik: throughput Jumlah partisi yang dibaca per sumber input Amazon S3 dalam pekerjaan ini dijalankan, serta untuk SEMUA sumber. Dimensi yang valid: JobName (nama AWS Glue Job), JobRunId ( JobRun ID. atau ALL), Type (gauge), (resource_utilization), dan Source ObservabilityGroup (lokasi data sumber) Statistik yang Valid: Rata-rata Unit: Jumlah |
throughput |
| Lek.driver.bytesWrittten |
Kategori Metrik: throughput Jumlah byte yang ditulis per output tenggelam dalam pekerjaan ini, serta untuk SEMUA sink. Ini membantu memahami volume data dan bagaimana perkembangannya dari waktu ke waktu, yang membantu mengatasi masalah seperti kemiringan pemrosesan. Dimensi yang valid: JobName (nama AWS Glue Job), JobRunId ( JobRun ID. atau ALL), Type (gauge), ObservabilityGroup (resource_utilization), dan Sink (lokasi data sink) Statistik yang Valid: Rata-rata Unit: Bita |
throughput |
| lem.driver. [RecordsWritten | FilesWritten] |
Kategori Metrik: throughput Jumlah records/files tertulis per output tenggelam dalam pekerjaan ini dijalankan, serta untuk SEMUA sink. Ini membantu memahami volume data dan bagaimana perkembangannya dari waktu ke waktu, yang membantu mengatasi masalah seperti kemiringan pemrosesan. Dimensi yang valid: JobName (nama AWS Glue Job), JobRunId ( JobRun ID. atau ALL), Type (gauge), ObservabilityGroup (resource_utilization), dan Sink (lokasi data sink) Statistik yang Valid: Rata-rata Unit: Jumlah |
throughput |
Kategori kesalahan
| Kategori kesalahan | Deskripsi |
|---|---|
| COMPILATION_ERROR | Kesalahan muncul selama kompilasi kode Scala. |
| CONNECTION_ERROR | Kesalahan muncul saat menghubungkan ke service/remote host/database layanan, dll. |
| DISK_NO_SPACE_ERROR |
Kesalahan muncul ketika tidak ada ruang yang tersisa di disk aktif driver/executor. |
| OUT_OF_MEMORY_ERROR | Kesalahan muncul ketika tidak ada ruang yang tersisa di memori aktif driver/executor. |
| IMPORT_ERROR | Kesalahan muncul saat dependensi impor. |
| INVALID_ARGUMENT_ERROR | Kesalahan muncul ketika argumen masukan invalid/illegal. |
| PERMISSION_ERROR | Kesalahan muncul ketika tidak memiliki izin untuk layanan, data, dll. |
| RESOURCE_NOT_FOUND_ERROR |
Kesalahan muncul ketika data, lokasi, dll tidak keluar. |
| QUERY_ERROR | Kesalahan muncul dari eksekusi kueri Spark SQL. |
| SYNTAX_ERROR | Kesalahan muncul ketika ada kesalahan sintaks dalam skrip. |
| THROTTLING_ERROR | Kesalahan muncul saat menekan batasan konkurensi layanan atau mengeksekusi batas kuota layanan. |
| DATA_LAKE_FRAMEWORK_ERROR | Kesalahan muncul dari kerangka data lake yang AWS Glue didukung asli seperti Hudi, Iceberg, dll. |
| UNSUPPORTED_OPERATION_ERROR | Kesalahan muncul saat melakukan operasi yang tidak didukung. |
| RESOURCES_ALREADY_EXISTS_ERROR | Kesalahan muncul ketika sumber daya yang akan dibuat atau ditambahkan sudah ada. |
| GLUE_INTERNAL_SERVICE_ERROR | Kesalahan muncul ketika ada masalah layanan AWS Glue internal. |
| GLUE_OPERATION_TIMEOUT_ERROR | Kesalahan muncul ketika AWS Glue operasi adalah batas waktu. |
| GLUE_VALIDATION_ERROR | Kesalahan muncul ketika nilai yang diperlukan tidak dapat divalidasi untuk AWS Glue pekerjaan. |
| GLUE_JOB_BOOKMARK_VERSION_MISMATCH_ERROR | Kesalahan muncul ketika pekerjaan yang sama menunjukkan bucket sumber yang sama dan menulis ke same/different tujuan secara bersamaan (konkurensi> 1) |
| LAUNCH_ERROR | Kesalahan muncul selama fase peluncuran AWS Glue pekerjaan. |
| DYNAMODB_ERROR | Kesalahan umum muncul dari Amazon DynamoDB layanan. |
| GLUE_ERROR | Kesalahan Generik muncul dari AWS Glue layanan. |
| LAKEFORMATION_ERROR | Kesalahan Generik muncul dari AWS Lake Formation layanan. |
| REDSHIFT_ERROR | Kesalahan Generik muncul dari Amazon Redshift layanan. |
| S3_KESALAHAN | Kesalahan Generik muncul dari layanan Amazon S3. |
| SYSTEM_EXIT_ERROR | Kesalahan keluar sistem generik. |
| TIMEOUT_ERROR | Kesalahan umum muncul ketika pekerjaan gagal karena waktu operasi habis. |
| UNCLASSIFIED_SPARK_ERROR | Kesalahan umum muncul dari Spark. |
| UNCLASSIFIED_ERROR | Kategori kesalahan default. |
Batasan
catatan
glueContextharus diinisialisasi untuk mempublikasikan metrik.
Di Dimensi Sumber, nilainya adalah jalur Amazon S3 atau nama tabel, tergantung pada jenis sumbernya. Selain itu, jika sumbernya adalah JDBC dan opsi kueri digunakan, string kueri diatur dalam dimensi sumber. Jika nilainya lebih panjang dari 500 karakter, itu dipangkas dalam 500 karakter.Berikut ini adalah batasan dalam nilai:
-
Non-ASCII Karakter akan dihapus.
<non-ASCII input>Jika nama sumber tidak mengandung karakter ASCII, itu dikonversi ke.
Keterbatasan dan pertimbangan untuk metrik throughput
-
DataFrame dan DataFrame-based DynamicFrame (misalnya JDBC, membaca dari parket di Amazon S3) didukung, namun, RDD-based DynamicFrame (misalnya membaca csv, json di Amazon S3, dll.) tidak didukung. Secara teknis, semua membaca dan menulis yang terlihat di Spark UI didukung.
-
recordsReadMetrik akan dipancarkan jika sumber data adalah tabel katalog dan formatnya adalah JSON, CSV, teks, atau Iceberg. -
glue.driver.throughput.recordsWritten,glue.driver.throughput.bytesWritten, danglue.driver.throughput.filesWrittenmetrik tidak tersedia dalam tabel JDBC dan Iceberg. -
Metrik mungkin tertunda. Jika pekerjaan selesai dalam waktu sekitar satu menit, mungkin tidak ada metrik throughput di Metrik. Amazon CloudWatch
