Setelah mempertimbangkan dengan cermat, kami memutuskan untuk menghentikan Amazon Kinesis Data Analytics SQL untuk aplikasi dalam dua langkah:
1. Mulai 15 Oktober 2025, Anda tidak akan dapat membuat Kinesis Data Analytics SQL baru untuk aplikasi.
2. Kami akan menghapus aplikasi Anda mulai 27 Januari 2026. Anda tidak akan dapat memulai atau mengoperasikan Amazon Kinesis Data Analytics Anda SQL untuk aplikasi. Support tidak akan lagi tersedia untuk Amazon Kinesis Data Analytics SQL sejak saat itu. Untuk informasi selengkapnya, lihat Amazon Kinesis Data Analytics SQL untuk penghentian Aplikasi.
Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Migrasi ke Layanan Terkelola untuk Contoh Apache Flink Studio
Setelah mempertimbangkan dengan cermat, kami telah membuat keputusan untuk menghentikan Amazon Kinesis Data Analytics SQL untuk aplikasi. Untuk membantu Anda merencanakan dan bermigrasi dari Amazon Kinesis Data Analytics SQL untuk aplikasi, kami akan menghentikan penawaran secara bertahap selama 15 bulan. Ada dua tanggal penting yang perlu diperhatikan, 15 Oktober 2025, dan 27 Januari 2026.
-
Mulai 15 Oktober 2025, Anda tidak akan dapat membuat Amazon Kinesis Data Analytics SQL baru untuk aplikasi.
-
Kami akan menghapus aplikasi Anda mulai 27 Januari 2026. Anda tidak akan dapat memulai atau mengoperasikan Amazon Kinesis Data Analytics SQL untuk aplikasi. Support tidak akan lagi tersedia untuk Amazon Kinesis Data Analytics SQL untuk aplikasi sejak saat itu. Untuk mempelajari selengkapnya, lihat Amazon Kinesis Data Analytics SQL untuk penghentian Aplikasi.
Kami menyarankan Anda menggunakan Amazon Managed Service untuk Apache Flink. Ini menggabungkan kemudahan penggunaan dengan kemampuan analitis tingkat lanjut, memungkinkan Anda membangun aplikasi pemrosesan aliran dalam hitungan menit.
Bagian ini menyediakan contoh kode dan arsitektur untuk membantu Anda memindahkan Amazon Kinesis Data Analytics SQL untuk beban kerja aplikasi ke Managed Service for Apache Flink.
Untuk informasi tambahan, lihat juga posting AWS blog ini: Migrasi dari Amazon Kinesis Data Analytics SQL untuk Aplikasi ke Managed Service untuk Apache
Untuk memigrasikan beban kerja Anda ke Managed Service for Apache Flink Studio atau Managed Service for Apache Flink, bagian ini menyediakan terjemahan kueri yang dapat Anda gunakan untuk kasus penggunaan umum.
Sebelum Anda menjelajahi contoh-contoh ini, kami sarankan Anda terlebih dahulu meninjau Menggunakan notebook Studio dengan Layanan Terkelola untuk Apache Flink.
Membuat ulang Kinesis Data Analytics SQL untuk kueri di Managed Service untuk Apache Flink Studio
Opsi berikut menyediakan terjemahan kueri aplikasi Kinesis Data Analytics SQL berbasis umum ke Managed Service for Apache Flink Studio.
Jika Anda ingin memindahkan beban kerja yang menggunakan Random Cut Forest dari Kinesis Analytics SQL ke Managed Service untuk Apache Flink, posting blog AWS ini
Lihat Converting- KDASQL -KDAStudio/
Dalam latihan berikut, Anda akan mengubah aliran data Anda untuk menggunakan Amazon Managed Service untuk Apache Flink Studio. Ini juga berarti beralih dari Amazon Kinesis Data Firehose ke Amazon Kinesis Data Streams.
Pertama kita berbagi tipikal KDA - SQL arsitektur, sebelum menunjukkan bagaimana Anda dapat mengganti ini menggunakan Amazon Managed Service untuk Apache Flink Studio dan Amazon Kinesis Data Streams. Atau Anda dapat meluncurkan AWS CloudFormation template di sini
Amazon Kinesis Data Analytics SQL - dan Amazon Kinesis Data Firehose
Berikut adalah alur arsitektur Amazon Kinesis Data SQL Analytics:
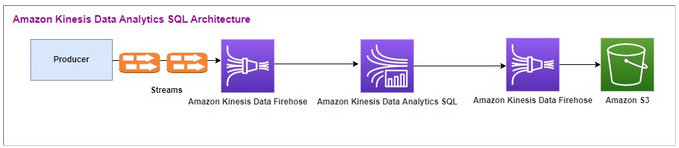
Kami pertama-tama memeriksa penyiapan Amazon Kinesis Data Analytics SQL - dan Amazon Kinesis Data Firehose lama. Kasus penggunaan adalah pasar perdagangan di mana data perdagangan, termasuk ticker saham dan harga, mengalir dari sumber eksternal ke sistem Amazon Kinesis. Amazon Kinesis Data Analytics SQL untuk menggunakan aliran input untuk mengeksekusi kueri Windowed seperti jendela Tumbling untuk menentukan volume perdagangan danmax,, average dan min harga perdagangan selama satu menit untuk setiap ticker saham.
Amazon Kinesis Data Analytics SQL - diatur untuk menelan data dari Amazon Kinesis Data Firehose. API Setelah diproses, Amazon Kinesis Data Analytics SQL - mengirimkan data yang diproses ke Amazon Kinesis Data Firehose lainnya, yang kemudian menyimpan output dalam bucket Amazon S3.
Dalam hal ini, Anda menggunakan Amazon Kinesis Data Generator. Amazon Kinesis Data Generator memungkinkan Anda mengirim data pengujian ke Amazon Kinesis Data Streams atau aliran pengiriman Amazon Kinesis Data Firehose. Untuk memulai, ikuti instruksi di sini
Setelah Anda menjalankan AWS CloudFormation template, bagian output akan memberikan url Amazon Kinesis Data Generator. Masuk ke portal menggunakan id pengguna Cognito dan kata sandi yang Anda atur di sini.
Berikut ini adalah contoh payload menggunakan Amazon Kinesis Data Generator. Generator data menargetkan input Amazon Kinesis Firehose Streams untuk mengalirkan data secara terus menerus. SDKKlien Amazon Kinesis dapat mengirim data dari produsen lain juga.
2023-02-17 09:28:07.763,"AAPL",5032023-02-17 09:28:07.763, "AMZN",3352023-02-17 09:28:07.763, "GOOGL",1852023-02-17 09:28:07.763, "AAPL",11162023-02-17 09:28:07.763, "GOOGL",1582
Berikut JSON ini digunakan untuk menghasilkan serangkaian waktu dan tanggal perdagangan acak, ticker saham, dan harga saham:
date.now(YYYY-MM-DD HH:mm:ss.SSS), "random.arrayElement(["AAPL","AMZN","MSFT","META","GOOGL"])", random.number(2000)
Setelah Anda memilih Kirim data, generator akan mulai mengirim data tiruan.
Sistem eksternal mengalirkan data ke Amazon Kinesis Data Firehose. Menggunakan Amazon Kinesis Data Analytics SQL untuk Aplikasi, Anda dapat menganalisis data streaming menggunakan SQL standar. Layanan ini memungkinkan Anda untuk membuat dan menjalankan SQL kode terhadap sumber streaming untuk melakukan analitik deret waktu, memberi umpan dasbor waktu nyata, dan membuat metrik waktu nyata. Amazon Kinesis Data Analytics SQL for Applications dapat membuat aliran tujuan SQL dari kueri pada aliran input dan mengirim aliran tujuan ke Amazon Kinesis Data Firehose lainnya. Tujuan Amazon Kinesis Data Firehose dapat mengirim data analitik ke Amazon S3 sebagai status akhir.
Amazon Kinesis Data Analytics SQL - kode lama didasarkan pada perpanjangan SQL Standar.
Anda menggunakan kueri berikut di Amazon Kinesis Data Analytics SQL -. Anda pertama kali membuat aliran tujuan untuk output kueri. Kemudian, Anda akan menggunakanPUMP, yang merupakan Objek Repositori Amazon Kinesis Data Analytics (ekstensi dari SQL Standar) yang menyediakan fungsionalitas kueri yang terus INSERT INTO stream SELECT ... FROM berjalan, sehingga memungkinkan hasil kueri untuk terus dimasukkan ke dalam aliran bernama.
CREATE OR REPLACE STREAM "DESTINATION_SQL_STREAM" (EVENT_TIME TIMESTAMP, INGEST_TIME TIMESTAMP, TICKER VARCHAR(16), VOLUME BIGINT, AVG_PRICE DOUBLE, MIN_PRICE DOUBLE, MAX_PRICE DOUBLE); CREATE OR REPLACE PUMP "STREAM_PUMP" AS INSERT INTO "DESTINATION_SQL_STREAM" SELECT STREAM STEP("SOURCE_SQL_STREAM_001"."tradeTimestamp" BY INTERVAL '60' SECOND) AS EVENT_TIME, STEP("SOURCE_SQL_STREAM_001".ROWTIME BY INTERVAL '60' SECOND) AS "STREAM_INGEST_TIME", "ticker", COUNT(*) AS VOLUME, AVG("tradePrice") AS AVG_PRICE, MIN("tradePrice") AS MIN_PRICE, MAX("tradePrice") AS MAX_PRICEFROM "SOURCE_SQL_STREAM_001" GROUP BY "ticker", STEP("SOURCE_SQL_STREAM_001".ROWTIME BY INTERVAL '60' SECOND), STEP("SOURCE_SQL_STREAM_001"."tradeTimestamp" BY INTERVAL '60' SECOND);
Yang sebelumnya SQL menggunakan dua jendela waktu — tradeTimestamp yang berasal dari muatan aliran masuk dan juga ROWTIME.tradeTimestamp disebut atau. Event Time client-side time Waktu ini sering kali berguna ketika digunakan dalam analitik karena merupakan waktu ketika peristiwa terjadi. Namun, banyak sumber peristiwa, seperti ponsel dan klien web, tidak memiliki jam yang dapat diandalkan, yang dapat menyebabkan waktu yang tidak akurat. Selain itu, masalah konektivitas dapat menyebabkan catatan yang muncul di aliran tidak dalam urutan yang sama dengan peristiwa yang terjadi.
Aliran dalam aplikasi juga menyertakan kolom khusus yang disebut. ROWTIME Kolom ini menyimpan stempel waktu ketika Amazon Kinesis Data Analytics memasukkan baris di aliran dalam aplikasi pertama. ROWTIME mencerminkan stempel waktu tempat Amazon Kinesis Data Analytics memasukkan catatan ke aliran dalam aplikasi pertama setelah membaca dari sumber streaming. Nilai ROWTIME ini selanjutnya dipertahankan di seluruh aplikasi Anda.
Ini SQL menentukan jumlah ticker sebagaivolume,, minmax, dan average harga selama interval 60 detik.
Menggunakan setiap waktu ini dalam kueri jendela yang berbasis waktu memiliki kelebihan dan kekurangan. Pilih satu atau lebih dari waktu-waktu ini, dan strategi untuk menangani kerugian yang relevan berdasarkan skenario kasus penggunaan Anda.
Strategi dua jendela menggunakan dua waktu berbasis, keduanya ROWTIME dan salah satu waktu lainnya seperti waktu acara.
-
Gunakan
ROWTIMEsebagai jendela pertama, yang mengontrol seberapa sering kueri memancarkan hasil, seperti yang ditunjukkan dalam contoh berikut. Ini tidak digunakan sebagai waktu logis. -
Gunakan salah satu waktu lain yang merupakan waktu logis yang ingin Anda kaitkan dengan analitik Anda. Waktu ini mewakili kapan peristiwa terjadi. Pada contoh berikut, tujuan analitik adalah mengelompokkan catatan dan dan kembali menghitung dengan ticker
Layanan Dikelola Amazon untuk Apache Flink Studio
Dalam arsitektur yang diperbarui, Anda mengganti Amazon Kinesis Data Firehose dengan Amazon Kinesis Data Streams. Amazon Kinesis Data Analytics SQL untuk Aplikasi digantikan oleh Amazon Managed Service untuk Apache Flink Studio. Kode Apache Flink dijalankan secara interaktif dalam Notebook Apache Zeppelin. Amazon Managed Service untuk Apache Flink Studio mengirimkan data perdagangan agregat ke bucket Amazon S3 untuk penyimpanan. Langkah-langkahnya ditunjukkan sebagai berikut:
Berikut adalah Amazon Managed Service untuk aliran arsitektur Apache Flink Studio:

Buat Aliran Data Kinesis
Untuk membuat aliran data menggunakan konsol
-
Di bilah navigasi, perluas pemilih Wilayah dan pilih Wilayah.
-
Pilih Create data stream (Buat aliran data).
-
Pada halaman Create Kinesis stream, masukkan nama untuk aliran data Anda dan terima mode kapasitas On-Demand default.
Dengan mode On-Demand, Anda kemudian dapat memilih Create Kinesis stream untuk membuat aliran data Anda.
Pada halaman Kinesis streams, Status streaming Anda adalah Membuat saat aliran sedang dibuat. Saat aliran siap digunakan, Status berubah menjadi Aktif.
-
Pilih nama streaming Anda. Halaman Detail Stream menampilkan ringkasan konfigurasi aliran Anda, bersama dengan informasi pemantauan.
-
Di Amazon Kinesis Data Generator, ubah aliran Stream/pengiriman ke Amazon Kinesis Data Streams baru: _ _. TRADE SOURCE STREAM
JSONdan Payload akan sama seperti yang Anda gunakan untuk Amazon Kinesis Data Analytics-. SQL Gunakan Amazon Kinesis Data Generator untuk menghasilkan beberapa contoh data muatan perdagangan dan menargetkan TRADE_ SOURCE _ STREAM Data Stream untuk latihan ini:
{{date.now(YYYY-MM-DD HH:mm:ss.SSS)}}, "{{random.arrayElement(["AAPL","AMZN","MSFT","META","GOOGL"])}}", {{random.number(2000)}} -
Saat AWS Management Console pergi ke Managed Service for Apache Flink dan kemudian pilih Create Application.
-
Di panel navigasi kiri, pilih buku catatan Studio lalu pilih Buat buku catatan studio.
-
Masukkan nama untuk notebook studio.
-
Di bawah database AWS Glue, sediakan AWS Glue database yang ada yang akan menentukan metadata untuk sumber dan tujuan Anda. Jika Anda tidak memiliki AWS Glue database, pilih Buat dan lakukan hal berikut:
-
Di konsol AWS Glue, pilih Databases di bawah katalog Data dari menu sebelah kiri.
-
Pilih Buat database
-
Di halaman Buat database, masukkan nama untuk database. Di bagian Lokasi - opsional, pilih Jelajahi Amazon S3 dan pilih bucket Amazon S3. Jika Anda belum memiliki bucket Amazon S3 yang sudah disiapkan, Anda dapat melewati langkah ini dan kembali lagi nanti.
-
(Opsional). Masukkan deskripsi untuk database.
-
Pilih Buat basis data.
-
-
Pilih Buat buku catatan
-
Setelah buku catatan Anda dibuat, pilih Jalankan.
-
Setelah notebook berhasil dimulai, luncurkan notebook Zeppelin dengan memilih Buka di Apache Zeppelin.
-
Pada halaman Notebook Zeppelin, pilih Buat catatan baru dan beri nama. MarketDataFeed
SQLKode Flink dijelaskan berikut, tetapi pertama-tama inilah tampilan layar notebook Zeppelin
Layanan Dikelola Amazon untuk Kode Apache Flink Studio
Amazon Managed Service untuk Apache Flink Studio menggunakan Notebook Zeppelin untuk menjalankan kode. Pemetaan dilakukan untuk contoh ini ke kode ssql berdasarkan Apache Flink 1.13. Kode di Notebook Zeppelin ditampilkan berikut, satu blok pada satu waktu.
Sebelum menjalankan kode apa pun di Notebook Zeppelin Anda, perintah konfigurasi Flink harus dijalankan. Jika Anda perlu mengubah pengaturan konfigurasi apa pun setelah menjalankan kode (ssql, Python, atau Scala), Anda harus berhenti dan memulai ulang notebook Anda. Dalam contoh ini, Anda harus mengatur checkpointing. Checkpointing diperlukan agar Anda dapat mengalirkan data ke file di Amazon S3. Ini memungkinkan streaming data ke Amazon S3 untuk dibuang ke file. Pernyataan berikut menetapkan interval ke 5000 milidetik.
%flink.conf execution.checkpointing.interval 5000
%flink.confmenunjukkan bahwa blok ini adalah pernyataan konfigurasi. Untuk informasi selengkapnya tentang konfigurasi Flink termasuk checkpointing, lihat Apache
Tabel input untuk sumber Amazon Kinesis Data Streams dibuat dengan kode ssql Flink berikut. Perhatikan bahwa TRADE_TIME bidang menyimpan tanggal/waktu yang dibuat oleh generator data.
%flink.ssql DROP TABLE IF EXISTS TRADE_SOURCE_STREAM; CREATE TABLE TRADE_SOURCE_STREAM (--`arrival_time` TIMESTAMP(3) METADATA FROM 'timestamp' VIRTUAL, TRADE_TIME TIMESTAMP(3), WATERMARK FOR TRADE_TIME as TRADE_TIME - INTERVAL '5' SECOND,TICKER STRING,PRICE DOUBLE, STATUS STRING)WITH ('connector' = 'kinesis','stream' = 'TRADE_SOURCE_STREAM', 'aws.region' = 'us-east-1','scan.stream.initpos' = 'LATEST','format' = 'csv');
Anda dapat melihat aliran masukan dengan pernyataan ini:
%flink.ssql(type=update)-- testing the source stream select * from TRADE_SOURCE_STREAM;
Sebelum mengirim data agregat ke Amazon S3, Anda dapat melihatnya langsung di Amazon Managed Service untuk Apache Flink Studio dengan kueri pilih jendela tumbling. Ini mengumpulkan data perdagangan dalam jendela waktu satu menit. Perhatikan bahwa pernyataan %flink.ssql harus memiliki penunjukan (type=update):
%flink.ssql(type=update) select TUMBLE_ROWTIME(TRADE_TIME, INTERVAL '1' MINUTE) as TRADE_WINDOW, TICKER, COUNT(*) as VOLUME, AVG(PRICE) as AVG_PRICE, MIN(PRICE) as MIN_PRICE, MAX(PRICE) as MAX_PRICE FROM TRADE_SOURCE_STREAMGROUP BY TUMBLE(TRADE_TIME, INTERVAL '1' MINUTE), TICKER;
Anda kemudian dapat membuat tabel untuk tujuan di Amazon S3. Anda harus menggunakan watermark. Tanda air adalah metrik kemajuan yang menunjukkan titik waktu ketika Anda yakin bahwa tidak ada lagi peristiwa yang tertunda yang akan tiba. Alasan tanda air adalah untuk memperhitungkan kedatangan yang terlambat. Interval ‘5’ Second ini memungkinkan perdagangan untuk memasuki Amazon Kinesis Data Stream terlambat 5 detik dan masih disertakan jika mereka memiliki stempel waktu di dalam jendela. Untuk informasi selengkapnya, lihat Menghasilkan Tanda Air
%flink.ssql(type=update) DROP TABLE IF EXISTS TRADE_DESTINATION_S3; CREATE TABLE TRADE_DESTINATION_S3 ( TRADE_WINDOW_START TIMESTAMP(3), WATERMARK FOR TRADE_WINDOW_START as TRADE_WINDOW_START - INTERVAL '5' SECOND, TICKER STRING, VOLUME BIGINT, AVG_PRICE DOUBLE, MIN_PRICE DOUBLE, MAX_PRICE DOUBLE) WITH ('connector' = 'filesystem','path' = 's3://trade-destination/','format' = 'csv');
Pernyataan ini menyisipkan data ke dalam. TRADE_DESTINATION_S3 TUMPLE_ROWTIMEadalah stempel waktu dari batas atas inklusif dari jendela yang jatuh.
%flink.ssql(type=update) insert into TRADE_DESTINATION_S3 select TUMBLE_ROWTIME(TRADE_TIME, INTERVAL '1' MINUTE), TICKER, COUNT(*) as VOLUME, AVG(PRICE) as AVG_PRICE, MIN(PRICE) as MIN_PRICE, MAX(PRICE) as MAX_PRICE FROM TRADE_SOURCE_STREAM GROUP BY TUMBLE(TRADE_TIME, INTERVAL '1' MINUTE), TICKER;
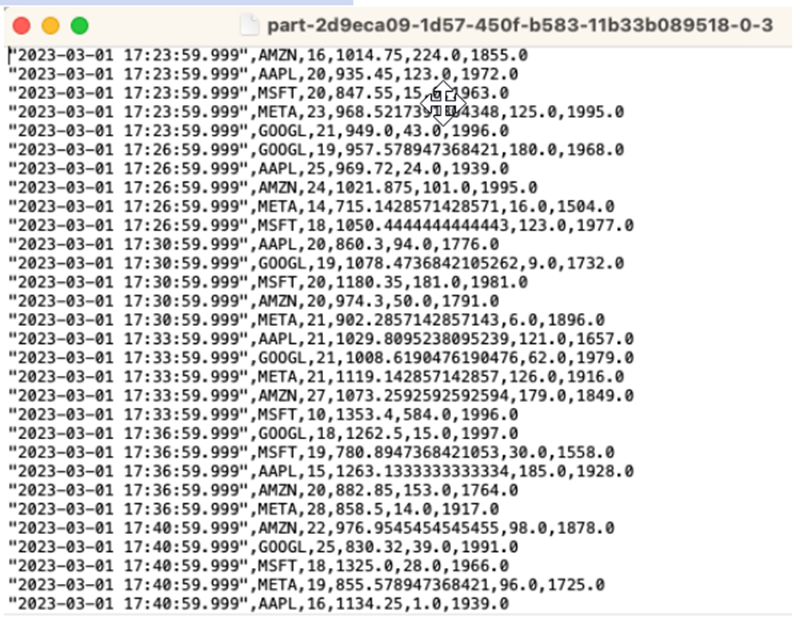
Biarkan pernyataan Anda berjalan selama 10 hingga 20 menit untuk mengumpulkan beberapa data di Amazon S3. Kemudian batalkan pernyataan Anda.
Ini menutup file di Amazon S3 sehingga dapat dilihat.
Berikut adalah apa isinya terlihat seperti:
Anda dapat menggunakan AWS CloudFormation template
AWS CloudFormation akan membuat sumber daya berikut di AWS akun Anda:
-
Amazon Kinesis Data Streams
-
Layanan Dikelola Amazon untuk Apache Flink Studio
-
AWS Glue basis data
-
Bucket Amazon S3
-
IAMperan dan kebijakan Amazon Managed Service untuk Apache Flink Studio untuk mengakses sumber daya yang sesuai
Impor notebook dan ubah nama bucket Amazon S3 dengan bucket Amazon S3 baru yang dibuat oleh. AWS CloudFormation

Lihat lebih banyak
Berikut adalah beberapa sumber daya tambahan yang dapat Anda gunakan untuk mempelajari lebih lanjut tentang penggunaan Layanan Terkelola untuk Apache Flink Studio:
Tujuan dari pola ini adalah untuk menunjukkan bagaimana memanfaatkan notebook Kinesis Data Analytics-Studio Zeppelin untuk memproses data UDFs dalam aliran Kinesis. Layanan Terkelola untuk Apache Flink Studio menggunakan Apache Flink untuk menyediakan kemampuan analitis tingkat lanjut, termasuk tepat sekali memproses semantik, jendela waktu acara, ekstensibilitas menggunakan fungsi yang ditentukan pengguna dan integrasi pelanggan, dukungan bahasa imperatif, status aplikasi yang tahan lama, penskalaan horizontal, dukungan untuk beberapa sumber data, integrasi yang dapat diperluas, dan banyak lagi. Hal ini penting untuk memastikan keakuratan, kelengkapan, konsistensi, dan keandalan pemrosesan aliran data dan tidak tersedia dengan Amazon Kinesis Data Analytics. SQL
Dalam aplikasi sampel ini, kami akan mendemonstrasikan cara memanfaatkan UDFs notebook KDA -Studio Zeppelin untuk memproses data dalam aliran Kinesis. Notebook studio untuk Kinesis Data Analytics memungkinkan Anda untuk secara interaktif melakukan kueri aliran data secara real time, dan dengan mudah membangun dan menjalankan aplikasi pemrosesan aliran menggunakan standarSQL, Python, dan Scala. Dengan beberapa klik AWS Management Console, Anda dapat meluncurkan notebook tanpa server untuk menanyakan aliran data dan mendapatkan hasil dalam hitungan detik. Untuk informasi selengkapnya, lihat Menggunakan notebook Studio dengan Kinesis Data Analytics untuk Apache Flink.
Fungsi Lambda yang digunakan untuk pemrosesan pra/pasca data di - aplikasi: KDA SQL
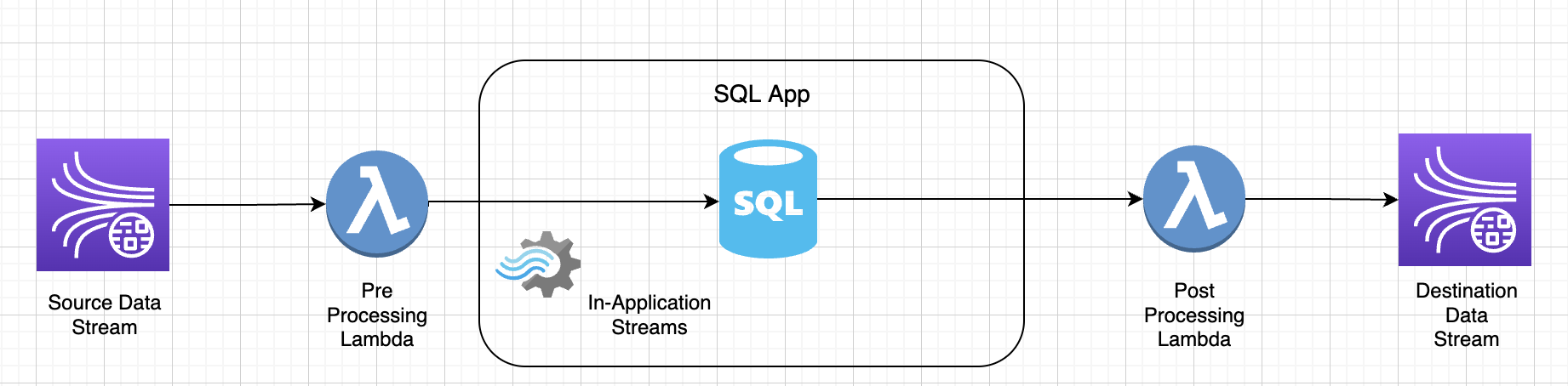
Fungsi yang ditentukan pengguna untuk pemrosesan data pra/pasca menggunakan notebook -Studio Zeppelin KDA
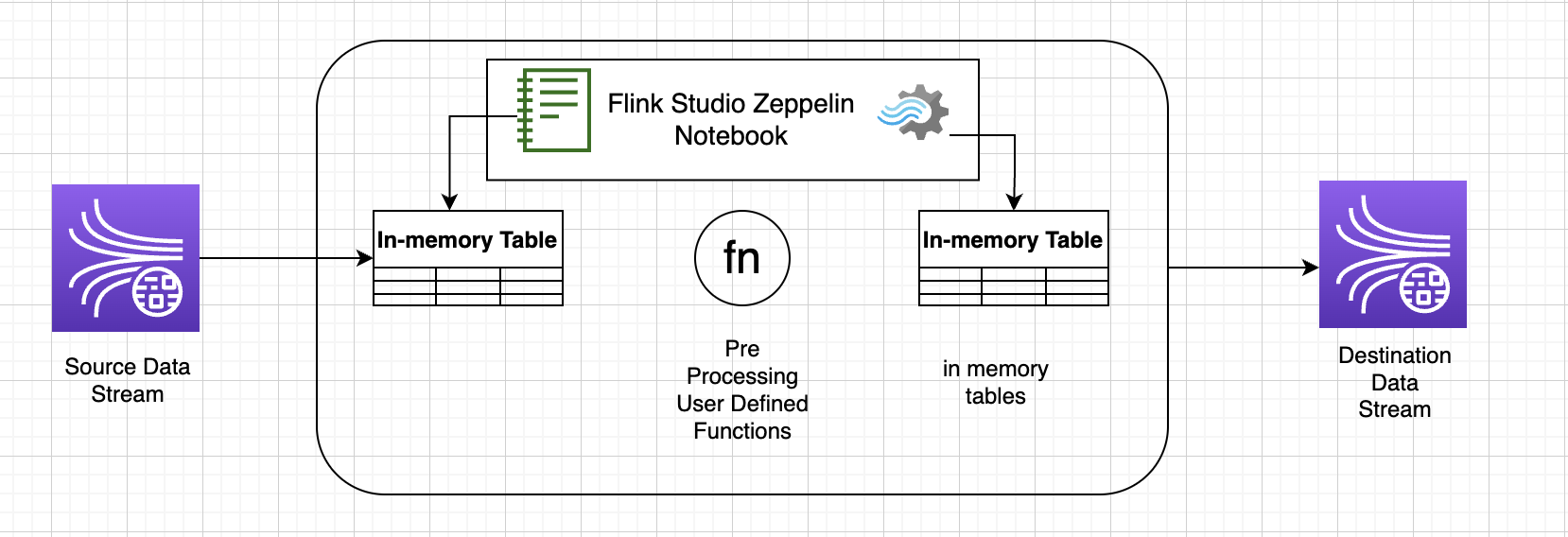
Fungsi yang ditentukan pengguna () UDFs
Untuk menggunakan kembali logika bisnis umum menjadi operator, akan berguna untuk mereferensikan fungsi yang ditentukan pengguna untuk mengubah aliran data Anda. Hal ini dapat dilakukan baik dalam Managed Service for Apache Flink Studio notebook, atau sebagai file jar aplikasi yang direferensikan secara eksternal. Memanfaatkan fungsi yang ditentukan pengguna dapat menyederhanakan transformasi atau pengayaan data yang mungkin Anda lakukan melalui streaming data.
Di notebook Anda, Anda akan mereferensikan jar aplikasi Java sederhana yang memiliki fungsi untuk menganonimkan nomor telepon pribadi. Anda juga dapat menulis Python atau Scala UDFs untuk digunakan dalam notebook. Kami memilih jar aplikasi Java untuk menyoroti fungsionalitas mengimpor jar aplikasi ke notebook Pyflink.
Pengaturan lingkungan
Untuk mengikuti panduan ini dan berinteraksi dengan data streaming Anda, Anda akan menggunakan AWS CloudFormation skrip untuk meluncurkan sumber daya berikut:
-
Sumber dan target Kinesis Data Streams
-
Database Glue
-
Peran IAM
-
Layanan Terkelola untuk Aplikasi Apache Flink Studio
-
Fungsi Lambda untuk memulai Managed Service untuk Apache Flink Studio Application
-
Peran Lambda untuk menjalankan fungsi Lambda sebelumnya
-
Sumber daya khusus untuk menjalankan fungsi Lambda
Unduh AWS CloudFormation template di sini
Buat AWS CloudFormation tumpukan
-
Pergi ke AWS Management Console dan pilih CloudFormationdi bawah daftar layanan.
-
Pada CloudFormationhalaman, pilih Stacks dan kemudian pilih Create Stack dengan sumber daya baru (standar).
-
Pada halaman Buat tumpukan, pilih Unggah File Template, lalu pilih
kda-flink-udf.ymlyang Anda unduh sebelumnya. Unggah file dan kemudian pilih Berikutnya. -
Beri nama template, seperti
kinesis-UDFagar mudah diingat, dan perbarui Parameter input seperti input-stream jika Anda menginginkan nama yang berbeda. Pilih Berikutnya. -
Pada halaman Configure stack options, tambahkan Tag jika Anda mau, lalu pilih Next.
-
Pada halaman Tinjauan, centang kotak yang memungkinkan pembuatan IAM sumber daya dan kemudian pilih Kirim.
AWS CloudFormation Tumpukan mungkin membutuhkan waktu 10 hingga 15 menit untuk diluncurkan tergantung pada Wilayah yang Anda luncurkan. Setelah Anda melihat CREATE_COMPLETE status untuk seluruh tumpukan, Anda siap untuk melanjutkan.
Bekerja dengan Layanan Terkelola untuk notebook Apache Flink Studio
Notebook studio untuk Kinesis Data Analytics memungkinkan Anda untuk secara interaktif melakukan kueri aliran data secara real time, dan dengan mudah membangun dan menjalankan aplikasi pemrosesan aliran menggunakan standarSQL, Python, dan Scala. Dengan beberapa klik AWS Management Console, Anda dapat meluncurkan notebook tanpa server untuk menanyakan aliran data dan mendapatkan hasil dalam hitungan detik.
Notebook adalah lingkungan pengembangan berbasis web. Dengan notebook, Anda mendapatkan pengalaman pengembangan interaktif sederhana yang dikombinasikan dengan kemampuan pemrosesan aliran data canggih yang disediakan oleh Apache Flink. Notebook studio menggunakan notebook yang didukung oleh Apache Zeppelin, dan menggunakan Apache Flink sebagai mesin pemrosesan aliran. Notebook studio menggabungkan teknologi ini dengan mulus untuk membuat analitik lanjutan pada aliran data dapat diakses oleh pengembang dari semua keahlian.
Apache Zeppelin memberi notebook Studio Anda dengan rangkaian alat analitik lengkap, termasuk yang berikut:
-
Visualisasi Data
-
Mengekspor data ke file
-
Mengontrol format output untuk analisis yang lebih mudah
Menggunakan notebook
-
Pergi ke AWS Management Console dan pilih Amazon Kinesis di bawah daftar layanan.
-
Di halaman navigasi sebelah kiri, pilih aplikasi Analytics, lalu pilih buku catatan Studio.
-
Verifikasi bahwa KinesisDataAnalyticsStudionotebook sedang berjalan.
-
Pilih notebook dan kemudian pilih Buka di Apache Zeppelin.
-
Unduh file Data Producer Zeppelin Notebook
yang akan Anda gunakan untuk membaca dan memuat data ke dalam Kinesis Stream. -
Impor
Data ProducerNotebook Zeppelin. Pastikan untuk memodifikasi inputSTREAM_NAMEdanREGIONdalam kode notebook. Nama aliran input dapat ditemukan di output AWS CloudFormation tumpukan. -
Jalankan notebook Data Producer dengan memilih tombol Jalankan paragraf ini untuk menyisipkan data sampel ke dalam input Kinesis Data Stream.
-
Saat data sampel dimuat, unduh MaskPhoneNumber-Interactive notebook
, yang akan membaca data input, menganonimkan nomor telepon dari aliran input dan menyimpan data anonim ke dalam aliran output. -
Impor notebook
MaskPhoneNumber-interactiveZeppelin. -
Jalankan setiap paragraf di buku catatan.
-
Dalam paragraf 1, Anda mengimpor Fungsi yang Ditetapkan Pengguna untuk menganonimkan nomor telepon.
%flink(parallelism=1) import com.mycompany.app.MaskPhoneNumber stenv.registerFunction("MaskPhoneNumber", new MaskPhoneNumber()) -
Pada paragraf berikutnya, Anda membuat tabel dalam memori untuk membaca data aliran input. Pastikan nama stream dan AWS Region sudah benar.
%flink.ssql(type=update) DROP TABLE IF EXISTS customer_reviews; CREATE TABLE customer_reviews ( customer_id VARCHAR, product VARCHAR, review VARCHAR, phone VARCHAR ) WITH ( 'connector' = 'kinesis', 'stream' = 'KinesisUDFSampleInputStream', 'aws.region' = 'us-east-1', 'scan.stream.initpos' = 'LATEST', 'format' = 'json'); -
Periksa apakah data dimuat ke dalam tabel dalam memori.
%flink.ssql(type=update) select * from customer_reviews -
Memanggil fungsi yang ditentukan pengguna untuk menganonimkan nomor telepon.
%flink.ssql(type=update) select customer_id, product, review, MaskPhoneNumber('mask_phone', phone) as phoneNumber from customer_reviews -
Sekarang setelah nomor telepon ditutup, buat tampilan dengan nomor bertopeng.
%flink.ssql(type=update) DROP VIEW IF EXISTS sentiments_view; CREATE VIEW sentiments_view AS select customer_id, product, review, MaskPhoneNumber('mask_phone', phone) as phoneNumber from customer_reviews -
Verifikasi datanya.
%flink.ssql(type=update) select * from sentiments_view -
Buat tabel dalam memori untuk Output Kinesis Stream. Pastikan nama stream dan AWS Region sudah benar.
%flink.ssql(type=update) DROP TABLE IF EXISTS customer_reviews_stream_table; CREATE TABLE customer_reviews_stream_table ( customer_id VARCHAR, product VARCHAR, review VARCHAR, phoneNumber varchar ) WITH ( 'connector' = 'kinesis', 'stream' = 'KinesisUDFSampleOutputStream', 'aws.region' = 'us-east-1', 'scan.stream.initpos' = 'TRIM_HORIZON', 'format' = 'json'); -
Masukkan catatan yang diperbarui di Aliran Kinesis target.
%flink.ssql(type=update) INSERT INTO customer_reviews_stream_table SELECT customer_id, product, review, phoneNumber FROM sentiments_view -
Lihat dan verifikasi data dari Aliran Kinesis target.
%flink.ssql(type=update) select * from customer_reviews_stream_table
-
Mempromosikan notebook sebagai aplikasi
Sekarang setelah Anda menguji kode notebook Anda secara interaktif, Anda akan menyebarkan kode sebagai aplikasi streaming dengan status tahan lama. Anda harus terlebih dahulu memodifikasi konfigurasi Aplikasi untuk menentukan lokasi kode Anda di Amazon S3.
-
Pada AWS Management Console, pilih buku catatan Anda dan di Deploy sebagai konfigurasi aplikasi - opsional, pilih Edit.
-
Di bawah Tujuan untuk kode di Amazon S3, pilih bucket Amazon S3 yang dibuat oleh skrip.AWS CloudFormation
Prosesnya mungkin memakan waktu beberapa menit. -
Anda tidak akan dapat mempromosikan catatan apa adanya. Jika Anda mencoba, Anda akan mengalami kesalahan karena
Selectpernyataan tidak didukung. Untuk mencegah masalah ini, unduh Notebook MaskPhoneNumber-Streaming Zeppelin. -
Impor
MaskPhoneNumber-streamingNotebook Zeppelin. -
Buka catatan dan pilih Tindakan untuk KinesisDataAnalyticsStudio.
-
Pilih Build MaskPhoneNumber -Streaming dan ekspor ke S3. Pastikan untuk mengganti nama Nama Aplikasi dan tidak menyertakan karakter khusus.
-
Pilih Bangun dan Ekspor. Ini akan memakan waktu beberapa menit untuk mengatur Aplikasi Streaming.
-
Setelah build selesai, pilih Deploy using AWS console.
-
Di halaman berikutnya, tinjau pengaturan dan pastikan untuk memilih IAM peran yang benar. Selanjutnya, pilih Buat aplikasi streaming.
-
Setelah beberapa menit, Anda akan melihat pesan bahwa aplikasi streaming berhasil dibuat.
Untuk informasi selengkapnya tentang penerapan aplikasi dengan status dan batas tahan lama, lihat Menerapkan sebagai aplikasi dengan status tahan lama.
Pembersihan
Secara opsional, Anda sekarang dapat menghapus tumpukan. AWS CloudFormation Ini akan menghapus semua layanan yang Anda atur sebelumnya.
