Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Membuat tabel Apache Iceberg
AWS Lake Formation mendukung pembuatan tabel Apache Iceberg yang menggunakan format data Apache Parquet di AWS Glue Data Catalog dengan data yang berada di Amazon S3. Tabel dalam Katalog Data adalah definisi metadata yang mewakili data dalam penyimpanan data. Secara default, Lake Formation membuat tabel Iceberg v2. Untuk perbedaan antara tabel v1 dan v2, lihat Format perubahan versi dalam dokumentasi Apache Iceberg.
Apache Iceberg adalah format tabel terbuka untuk dataset analitik yang sangat besar. Iceberg memungkinkan perubahan mudah pada skema Anda, juga dikenal sebagai evolusi skema, yang berarti bahwa pengguna dapat menambahkan, mengganti nama, atau menghapus kolom dari tabel data tanpa mengganggu data yang mendasarinya. Iceberg juga menyediakan dukungan untuk pembuatan versi data, yang memungkinkan pengguna untuk melacak perubahan data dari waktu ke waktu. Ini memungkinkan fitur perjalanan waktu, yang memungkinkan pengguna untuk mengakses dan menanyakan versi historis data dan menganalisis perubahan data antara pembaruan dan penghapusan.
Anda dapat menggunakan konsol Lake Formation atau CreateTable operasi di AWS Glue API untuk membuat tabel Gunung Es di Katalog Data. Untuk informasi selengkapnya, lihat CreateTable tindakan (Python: create_table).
Saat Anda membuat tabel Gunung Es di Katalog Data, Anda harus menentukan format tabel dan jalur file metadata di Amazon S3 agar dapat melakukan pembacaan dan penulisan.
Anda dapat menggunakan Lake Formation untuk mengamankan tabel Gunung Es menggunakan izin kontrol akses berbutir halus saat Anda mendaftarkan lokasi data Amazon S3. AWS Lake Formation Untuk data sumber di Amazon S3 dan metadata yang tidak terdaftar di Lake Formation, akses ditentukan oleh kebijakan IAM izin untuk Amazon S3 dan tindakan. AWS Glue Untuk informasi selengkapnya, lihat Mengelola izin Lake Formation.
Data Catalog tidak mendukung pembuatan partisi dan menambahkan properti tabel Iceberg.
Prasyarat
Untuk membuat tabel Gunung Es di Katalog Data, dan mengatur izin akses data Lake Formation, Anda harus melengkapi persyaratan berikut:
-
Izin diperlukan untuk membuat tabel Gunung Es tanpa data yang terdaftar di Lake Formation.
Selain izin yang diperlukan untuk membuat tabel di Katalog Data, pembuat tabel memerlukan izin berikut:
s3:PutObjectpada sumber daya arn:aws:s3::: {} bucketName
-
s3:GetObjectpada sumber daya arn:aws:s3::: {} bucketName
-
s3:DeleteObjectpada sumber daya arn:aws:s3::: {} bucketName
-
Izin yang diperlukan untuk membuat tabel Gunung Es dengan data yang terdaftar di Lake Formation:
Untuk menggunakan Lake Formation untuk mengelola dan mengamankan data di danau data Anda, daftarkan lokasi Amazon S3 Anda yang memiliki data untuk tabel dengan Lake Formation. Ini agar Lake Formation dapat memberikan kredensi ke layanan AWS analitis seperti Athena, Redshift Spectrum, dan Amazon untuk mengakses data. EMR Untuk informasi selengkapnya tentang mendaftarkan lokasi Amazon S3, lihat. Menambahkan lokasi Amazon S3 ke danau data Anda
Kepala sekolah yang membaca dan menulis data dasar yang terdaftar di Lake Formation memerlukan izin berikut:
-
lakeformation:GetDataAccess
-
DATA_LOCATION_ACCESS
Kepala sekolah yang memiliki izin lokasi data di lokasi juga memiliki izin lokasi di semua lokasi anak.
Untuk informasi selengkapnya tentang izin lokasi data, lihatKontrol akses data yang mendasari.
Untuk mengaktifkan pemadatan, layanan harus mengambil IAM peran yang memiliki izin untuk memperbarui tabel di Katalog Data. Untuk detailnya, lihat Prasyarat pengoptimalan tabel.
Membuat tabel Iceberg
Anda dapat membuat tabel Iceberg v1 dan v2 menggunakan konsol Lake Formation atau AWS Command Line Interface seperti yang didokumentasikan di halaman ini. Anda juga dapat membuat tabel Iceberg menggunakan AWS Glue konsol atau. Perayap AWS Glue Untuk informasi selengkapnya, lihat Katalog Data dan Crawler di Panduan AWS Glue Pengembang.
Untuk membuat tabel Iceberg
- Console
-
Masuk ke AWS Management Console, dan buka konsol Lake Formation di https://console.aws.amazon.com/lakeformation/.
Di bawah Katalog Data, pilih Tabel, dan gunakan tombol Buat tabel untuk menentukan atribut berikut:
-
Nama tabel: Masukkan nama untuk tabel. Jika Anda menggunakan Athena untuk mengakses tabel, gunakan tips penamaan ini di Panduan Pengguna Amazon Athena.
-
Database: Pilih database yang ada atau buat yang baru.
-
Deskripsi:Deskripsi tabel. Anda dapat menulis deskripsi untuk membantu Anda memahami isi tabel tersebut.
-
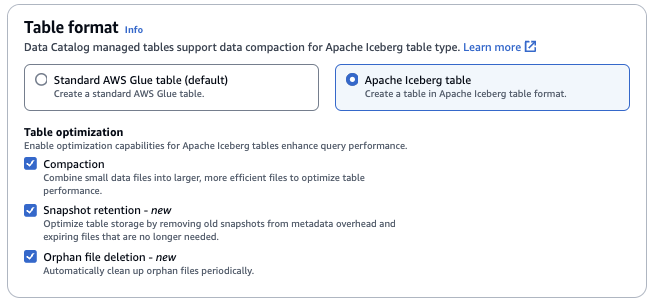
Format tabel: Untuk format Tabel, pilih Apache Iceberg.
Optimalisasi tabel
-
Pemadatan — File data digabungkan dan ditulis ulang menghapus data usang dan mengkonsolidasikan data yang terfragmentasi menjadi file yang lebih besar dan lebih efisien.
Retensi snapshot — Snapshot adalah versi stempel waktu dari tabel Iceberg. Konfigurasi retensi snapshot memungkinkan pelanggan untuk menerapkan berapa lama untuk menyimpan snapshot dan berapa banyak snapshot yang akan disimpan. Mengonfigurasi pengoptimal retensi snapshot dapat membantu mengelola overhead penyimpanan dengan menghapus snapshot yang lebih lama dan tidak perlu serta file yang mendasarinya yang terkait.
Penghapusan file yatim piatu — File yatim piatu adalah file yang tidak lagi direferensikan oleh metadata tabel Iceberg. File-file ini dapat terakumulasi dari waktu ke waktu, terutama setelah operasi seperti penghapusan tabel atau pekerjaan yang gagalETL. Mengaktifkan penghapusan file yatim memungkinkan AWS Glue untuk secara berkala mengidentifikasi dan menghapus file-file yang tidak perlu ini, membebaskan penyimpanan.
Untuk informasi selengkapnya, lihat Mengoptimalkan tabel Gunung Es.
-
IAMrole: Untuk menjalankan pemadatan, layanan mengasumsikan IAM peran atas nama Anda. Anda dapat memilih IAM peran menggunakan drop-down. Pastikan peran memiliki izin yang diperlukan untuk mengaktifkan pemadatan.
Untuk mempelajari lebih lanjut tentang izin yang diperlukan, lihat Prasyarat pengoptimalan tabel.
-
Lokasi: Tentukan jalur ke folder di Amazon S3 yang menyimpan tabel metadata. Iceberg membutuhkan file metadata dan lokasi di Katalog Data untuk dapat melakukan pembacaan dan penulisan.
-
Skema: Pilih Tambahkan kolom untuk menambahkan kolom dan tipe data kolom. Anda memiliki opsi untuk membuat tabel kosong dan memperbarui skema nanti. Katalog Data mendukung tipe data Hive. Untuk informasi selengkapnya, lihat Tipe data sarang.
Iceberg memungkinkan Anda untuk mengembangkan skema dan partisi setelah Anda membuat tabel. Anda dapat menggunakan kueri Athena untuk memperbarui skema tabel dan kueri Spark untuk memperbarui partisi.
- AWS CLI
-
aws glue create-table \
--database-name iceberg-db \
--region us-west-2 \
--open-table-format-input '{
"IcebergInput": {
"MetadataOperation": "CREATE",
"Version": "2"
}
}' \
--table-input '{"Name":"test-iceberg-input-demo",
"TableType": "EXTERNAL_TABLE",
"StorageDescriptor":{
"Columns":[
{"Name":"col1", "Type":"int"},
{"Name":"col2", "Type":"int"},
{"Name":"col3", "Type":"string"}
],
"Location":"s3://DOC_EXAMPLE_BUCKET_ICEBERG/"
}
}'