Kami tidak lagi memperbarui layanan Amazon Machine Learning atau menerima pengguna baru untuk itu. Dokumentasi ini tersedia untuk pengguna yang sudah ada, tetapi kami tidak lagi memperbaruinya. Untuk informasi selengkapnya, lihatApa itu Amazon Machine Learning.
Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Wawasan Model
Menafsirkan Prediksi
Output dari model ML-regresi adalah nilai numerik untuk prediksi model target. Misalnya, jika Anda memprediksi harga perumahan, prediksi model bisa menjadi nilai seperti 254.013.
catatan
Kisaran prediksi dapat berbeda dari kisaran target dalam data pelatihan. Misalnya, katakanlah Anda memprediksi harga perumahan, dan target dalam data pelatihan memiliki nilai dalam kisaran 0 hingga 450.000. Target yang diprediksi tidak perlu berada dalam kisaran yang sama, dan mungkin mengambil nilai positif (lebih besar dari 450.000) atau nilai negatif (kurang dari nol). Penting untuk merencanakan cara mengatasi nilai prediksi yang berada di luar rentang yang dapat diterima untuk aplikasi Anda.
Mengukur Akurasi Model
Untuk tugas regresi, Amazon MLE menggunakan metrik root mean square error (RMSE) standar industri. Ini adalah ukuran jarak antara target numerik yang diprediksi dan jawaban numerik aktual (ground truth). Semakin kecil nilai RMSE, semakin baik akurasi prediktif model. Sebuah model dengan prediksi yang benar sempurna akan memiliki RMSE 0. Contoh berikut menunjukkan data evaluasi yang berisi catatan N:

RMSE Dasar
Amazon XML menyediakan metrik dasar untuk model regresi. Ini adalah RMSE untuk model regresi hipotetis yang akan selalu memprediksi rata-rata target sebagai jawabannya. Misalnya, jika Anda memprediksi usia pembeli rumah dan usia rata-rata untuk pengamatan dalam data pelatihan Anda adalah 35, model dasar akan selalu memprediksi jawabannya sebagai 35. Anda akan membandingkan model ML-mu dengan baseline ini untuk memvalidasi jika model MLmu lebih baik daripada model ML-mu yang memprediksi jawaban konstan ini.
Menggunakan Visualisasi Kinerja
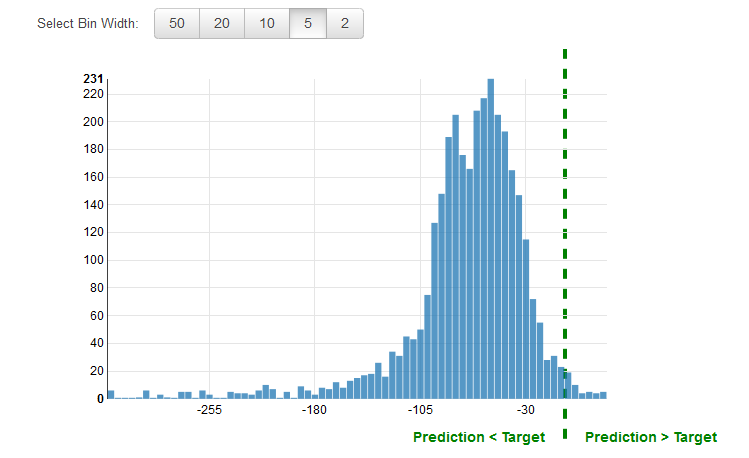
Ini adalah praktik umum untuk meninjau ulangresiduuntuk masalah regresi. Sisa untuk pengamatan dalam data evaluasi adalah perbedaan antara target sebenarnya dan target yang diprediksi. Residu mewakili bagian dari target bahwa model tidak dapat memprediksi. Sisa positif menunjukkan bahwa model meremehkan target (target sebenarnya lebih besar dari target yang diprediksi). Residual negatif menunjukkan overestimation (target sebenarnya lebih kecil dari target yang diprediksi). Histogram residu pada data evaluasi ketika didistribusikan dalam bentuk lonceng dan berpusat pada nol menunjukkan bahwa model membuat kesalahan secara acak dan tidak secara sistematis atas atau di bawah memprediksi kisaran tertentu nilai target. Jika residu tidak membentuk bentuk lonceng berpusat nol, ada beberapa struktur dalam kesalahan prediksi model. Menambahkan lebih banyak variabel ke model mungkin membantu model menangkap pola yang tidak ditangkap oleh model saat ini. Ilustrasi berikut menunjukkan residu yang tidak berpusat di sekitar nol.