Kami tidak lagi memperbarui layanan Amazon Machine Learning atau menerima pengguna baru untuk itu. Dokumentasi ini tersedia untuk pengguna yang sudah ada, tetapi kami tidak lagi memperbaruinya. Untuk informasi selengkapnya, lihat Apa itu Amazon Machine Learning.
Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Memisahkan Data Anda
Tujuan mendasar dari model ML adalah untuk membuat prediksi yang akurat tentang instance data future di luar yang digunakan untuk melatih model. Sebelum menggunakan model ML untuk membuat prediksi, kita perlu mengevaluasi kinerja prediktif model. Untuk memperkirakan kualitas prediksi model ML dengan data yang belum dilihatnya, kami dapat memesan, atau membagi, sebagian data yang sudah kami ketahui jawabannya sebagai proxy untuk data future dan mengevaluasi seberapa baik model ML memprediksi jawaban yang benar untuk data tersebut. Anda membagi sumber data menjadi beberapa bagian untuk sumber data pelatihan dan sebagian untuk sumber data evaluasi.
Amazon ML menyediakan tiga opsi untuk membagi data Anda:
-
Pre-split data - Anda dapat membagi data menjadi dua lokasi input data, sebelum mengunggahnya ke Amazon Simple Storage Service (Amazon S3) dan membuat dua sumber data terpisah dengannya.
-
Amazon ML sequential split - Anda dapat memberi tahu Amazon ML untuk membagi data Anda secara berurutan saat membuat sumber data pelatihan dan evaluasi.
-
Amazon ML random split - Anda dapat memberi tahu Amazon ML untuk membagi data Anda menggunakan metode acak unggulan saat membuat sumber data pelatihan dan evaluasi.
Pre-splitting Data Anda
Jika Anda ingin kontrol eksplisit atas data dalam sumber data pelatihan dan evaluasi, pisahkan data Anda menjadi lokasi data terpisah, dan buat sumber data terpisah untuk lokasi input dan evaluasi.
Memisahkan Data Anda Secara Berurutan
Cara sederhana untuk membagi data input Anda untuk pelatihan dan evaluasi adalah dengan memilih subset data yang tidak tumpang tindih sambil mempertahankan urutan catatan data. Pendekatan ini berguna jika Anda ingin mengevaluasi model ML Anda pada data untuk tanggal tertentu atau dalam rentang waktu tertentu. Misalnya, katakan bahwa Anda memiliki data keterlibatan pelanggan selama lima bulan terakhir, dan Anda ingin menggunakan data historis ini untuk memprediksi keterlibatan pelanggan di bulan berikutnya. Menggunakan awal rentang untuk pelatihan, dan data dari akhir rentang untuk evaluasi dapat menghasilkan perkiraan kualitas model yang lebih akurat daripada menggunakan data catatan yang diambil dari seluruh rentang data.
Gambar berikut menunjukkan contoh kapan Anda harus menggunakan strategi pemisahan berurutan versus kapan Anda harus menggunakan strategi acak.
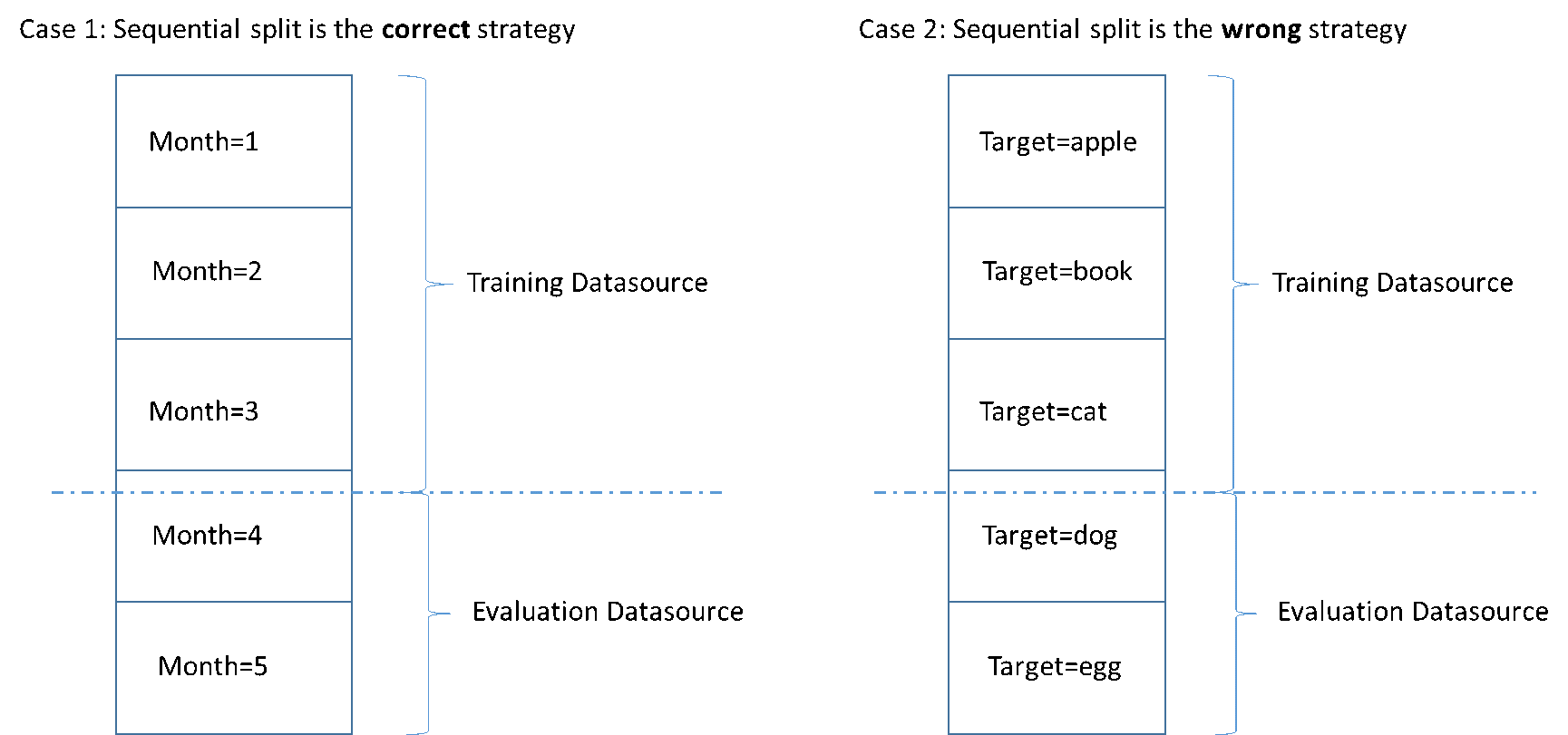
Saat membuat sumber data, Anda dapat memilih untuk membagi sumber data Anda secara berurutan, dan Amazon ML menggunakan 70 persen pertama data Anda untuk pelatihan dan 30 persen data lainnya untuk evaluasi. Ini adalah pendekatan default saat Anda menggunakan konsol Amazon Amazon untuk membagi data Anda.
Memisahkan Data Anda Secara Acak
Memisahkan data input secara acak ke dalam sumber data pelatihan dan evaluasi memastikan bahwa distribusi data serupa dalam sumber data pelatihan dan evaluasi. Pilih opsi ini ketika Anda tidak perlu mempertahankan urutan data input Anda.
Amazon ML menggunakan metode pembuatan nomor pseudo-acak unggulan untuk membagi data Anda. Benih sebagian didasarkan pada nilai string input dan sebagian pada konten data itu sendiri. Secara default, konsol Amazon Amazon menggunakan lokasi S3 dari data input sebagai string. Pengguna API dapat menyediakan string khusus. Ini berarti bahwa dengan bucket dan data S3 yang sama, Amazon MLmembagi data dengan cara yang sama setiap saat. Untuk mengubah cara Amazon MLmemisahkan data, Anda dapat menggunakanCreateDatasourceFromS3,CreateDatasourceFromRedshift, atau CreateDatasourceFromRDS API dan memberikan nilai untuk string benih. Saat menggunakan API ini untuk membuat sumber data terpisah untuk pelatihan dan evaluasi, penting untuk menggunakan nilai string benih yang sama untuk sumber data dan tanda pelengkap untuk satu sumber data, untuk memastikan bahwa tidak ada tumpang tindih antara data pelatihan dan evaluasi.
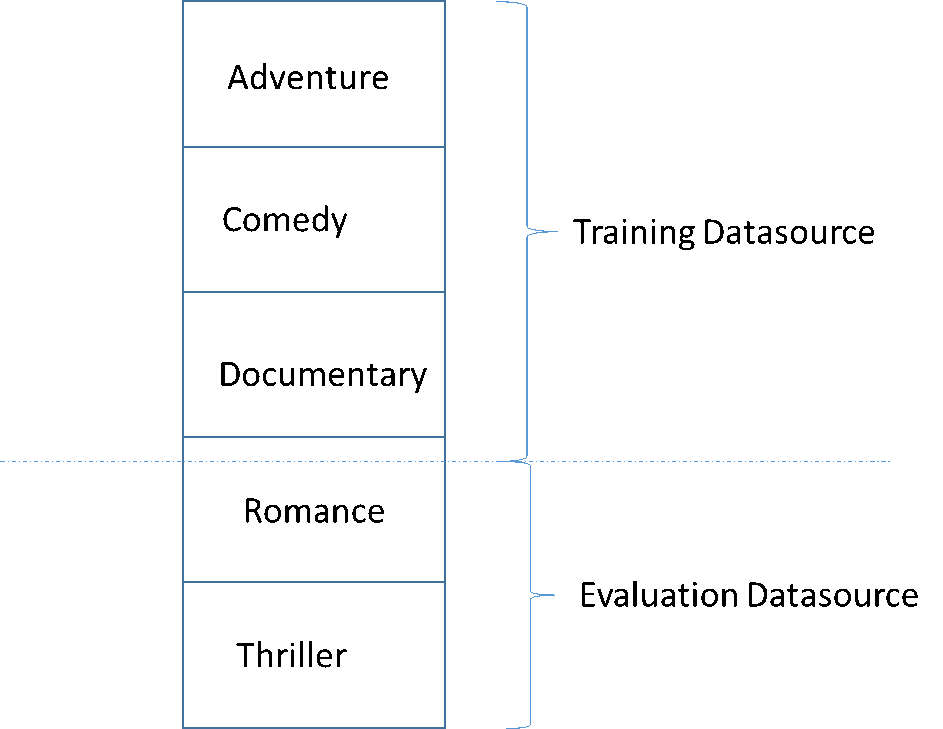
Perangkap umum dalam mengembangkan model ML berkualitas tinggi adalah mengevaluasi model ML pada data yang tidak mirip dengan data yang digunakan untuk pelatihan. Misalnya, Anda menggunakan ML untuk memprediksi genre film, dan data pelatihan Anda berisi film dari genre Petualangan, Komedi, dan Dokumenter. Namun, data evaluasi Anda hanya berisi data dari genre Romance dan Thriller. Dalam hal ini, model ML tidak mempelajari informasi apa pun tentang genre Romance dan Thriller, dan evaluasi tidak mengevaluasi seberapa baik model tersebut mempelajari pola untuk genre Petualangan, Komedi, dan Dokumenter. Akibatnya, informasi genre tidak berguna, dan kualitas prediksi model ML untuk semua genre terganggu. Model dan evaluasi terlalu berbeda (memiliki statistik deskriptif yang sangat berbeda) untuk berguna. Ini dapat terjadi ketika data input diurutkan berdasarkan salah satu kolom dalam kumpulan data, dan kemudian dibagi secara berurutan.
Jika sumber data pelatihan dan evaluasi Anda memiliki distribusi data yang berbeda, Anda akan melihat peringatan evaluasi dalam evaluasi model Anda. Untuk informasi selengkapnya tentang peringatan evaluasi, lihatPeringatan Evaluasi.
Anda tidak perlu menggunakan pemisahan acak di Amazon ML jika Anda telah mengacak data input Anda, misalnya, dengan mengacak data input Anda secara acak di Amazon S3, atau dengan menggunakan fungsi kueri Amazon Redshift SQL atau random() fungsi kueri MySQL SQL saat membuat sumber data. rand() Dalam kasus ini, Anda dapat mengandalkan opsi pemisahan sekuensial untuk membuat sumber data pelatihan dan evaluasi dengan distribusi serupa.
