Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Membuat gambar algoritme
SageMaker Algoritma Amazon mengharuskan pembeli membawa data mereka sendiri untuk dilatih sebelum membuat prediksi. Sebagai AWS Marketplace penjual, Anda dapat menggunakannya SageMaker untuk membuat algoritma dan model pembelajaran mesin (ML) yang dapat digunakan pembeli Anda. AWS Bagian berikut Anda cara membuat gambar algoritma untuk AWS Marketplace. Ini termasuk membuat image pelatihan Docker untuk melatih algoritme Anda dan gambar inferensi yang berisi logika inferensi Anda. Baik gambar pelatihan dan inferensi diperlukan saat menerbitkan produk algoritme.
Gambaran Umum
Algoritma mencakup komponen-komponen berikut:
-
Gambar pelatihan yang disimpan di Amazon ECR
-
Gambar inferensi yang disimpan di Amazon Elastic Container Registry (AmazonECR)
catatan
Untuk produk algoritme, wadah pelatihan menghasilkan artefak model yang dimuat ke dalam wadah inferensi pada penerapan model.
Diagram berikut menunjukkan alur kerja untuk menerbitkan dan menggunakan produk algoritma.
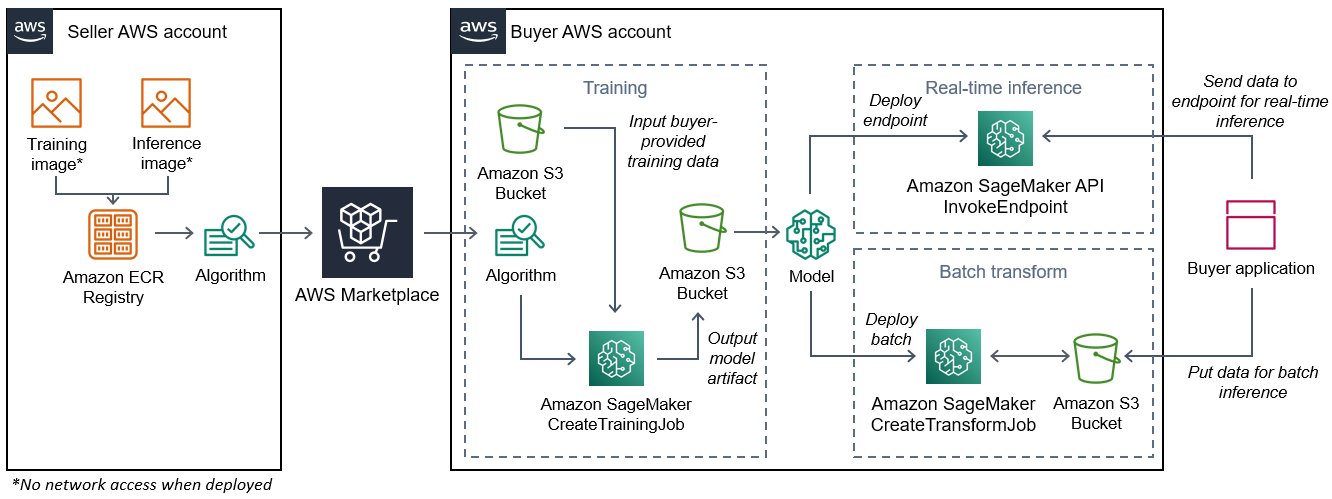
Alur kerja untuk membuat SageMaker algoritme AWS Marketplace mencakup langkah-langkah berikut:
-
Penjual membuat gambar pelatihan dan gambar inferensi (tidak ada akses jaringan saat digunakan) dan mengunggahnya ke Amazon Registry. ECR
-
Penjual kemudian membuat sumber daya algoritme di Amazon SageMaker dan menerbitkan produk ML-nya. AWS Marketplace
-
Pembeli berlangganan produk ML.
-
Pembeli membuat pekerjaan pelatihan dengan dataset yang kompatibel dan nilai hyperparameter yang sesuai. SageMaker menjalankan gambar pelatihan dan memuat data pelatihan dan hiperparameter ke dalam wadah pelatihan. Ketika pekerjaan pelatihan selesai, artefak model yang terletak di
/opt/ml/model/dikompresi dan disalin ke ember Amazon S3 pembeli. -
Pembeli membuat paket model dengan artefak model dari pelatihan yang disimpan di Amazon S3 dan menyebarkan model.
-
SageMaker menjalankan gambar inferensi, mengekstrak artefak model terkompresi, dan memuat file ke dalam jalur direktori kontainer inferensi
/opt/ml/model/di mana ia dikonsumsi oleh kode yang melayani inferensi. -
Baik model diterapkan sebagai titik akhir atau pekerjaan transformasi batch, SageMaker meneruskan data untuk inferensi atas nama pembeli ke wadah melalui HTTP titik akhir penampung dan mengembalikan hasil prediksi.
catatan
Untuk informasi lebih lanjut, lihat Model Kereta.
Membuat gambar pelatihan untuk algoritme
Bagian ini memberikan panduan untuk mengemas kode pelatihan Anda ke dalam gambar pelatihan. Gambar pelatihan diperlukan untuk membuat produk algoritme.
Gambar pelatihan adalah gambar Docker yang berisi algoritme pelatihan Anda. Kontainer mematuhi struktur file tertentu untuk memungkinkan SageMaker untuk menyalin data ke dan dari wadah Anda.
Baik gambar pelatihan dan inferensi diperlukan saat menerbitkan produk algoritme. Setelah membuat gambar pelatihan Anda, Anda harus membuat gambar inferensi. Kedua gambar dapat digabungkan menjadi satu gambar atau tetap sebagai gambar terpisah. Apakah akan menggabungkan gambar atau memisahkannya terserah Anda. Biasanya, inferensi lebih sederhana daripada pelatihan, dan Anda mungkin ingin gambar terpisah untuk membantu kinerja inferensi.
catatan
Berikut ini hanya satu contoh kode pengemasan untuk gambar pelatihan. Untuk informasi selengkapnya, lihat Menggunakan algoritme dan model Anda sendiri dengan AWS Marketplace dan AWS Marketplace
SageMaker contoh
Langkah-langkah
Langkah 1: Membuat gambar kontainer
Agar image pelatihan kompatibel dengan Amazon SageMaker, image tersebut harus mematuhi struktur file tertentu agar memungkinkan SageMaker penyalinan data pelatihan dan input konfigurasi ke jalur tertentu di container Anda. Saat pelatihan selesai, artefak model yang dihasilkan disimpan di jalur direktori tertentu di wadah tempat SageMaker salinannya berasal.
Berikut ini menggunakan Docker CLI diinstal dalam lingkungan pengembangan pada distribusi Ubuntu Linux.
Siapkan program Anda untuk membaca input konfigurasi
Jika program pelatihan Anda memerlukan input konfigurasi yang disediakan pembeli, berikut ini adalah di mana program tersebut disalin ke dalam container Anda saat dijalankan. Jika diperlukan, program Anda harus membaca dari jalur file tertentu.
-
/opt/ml/input/configadalah direktori yang berisi informasi yang mengontrol bagaimana program Anda berjalan.-
hyperparameters.jsonadalah kamus JSON yang diformat dari nama dan nilai hyperparameter. Nilainya adalah string, jadi Anda mungkin perlu mengonversinya. -
resourceConfig.jsonadalah file JSON berformat yang menjelaskan tata letak jaringan yang digunakan untuk pelatihan terdistribusi. Jika gambar pelatihan Anda tidak mendukung pelatihan terdistribusi, Anda dapat mengabaikan file ini.
-
catatan
Untuk informasi selengkapnya tentang input konfigurasi, lihat Cara Amazon SageMaker Menyediakan Informasi Pelatihan.
Siapkan program Anda untuk membaca input data
Data pelatihan dapat diteruskan ke wadah dalam salah satu dari dua mode berikut. Program pelatihan Anda yang berjalan di wadah mencerna data pelatihan di salah satu dari dua mode tersebut.
Modus berkas
-
/opt/ml/input/data/<channel_name>/berisi data input untuk saluran itu. Saluran dibuat berdasarkan panggilan keCreateTrainingJoboperasi, tetapi umumnya penting bahwa saluran cocok dengan apa yang diharapkan algoritme. File untuk setiap saluran disalin dari AmazonS3 ke direktori ini, mempertahankan struktur pohon yang ditunjukkan oleh struktur kunci Amazon S3.
Modus pipa
-
/opt/ml/input/data/<channel_name>_<epoch_number>adalah pipa untuk zaman tertentu. Epoch dimulai dari nol dan meningkat satu setiap kali Anda membacanya. Tidak ada batasan jumlah epoch yang dapat Anda jalankan, tetapi Anda harus menutup setiap pipa sebelum membaca epoch berikutnya.
Siapkan program Anda untuk menulis output pelatihan
Output dari pelatihan ditulis ke direktori kontainer berikut:
-
/opt/ml/model/adalah direktori tempat Anda menulis model atau artefak model yang dihasilkan oleh algoritme pelatihan Anda. Model Anda dapat dalam format apa pun yang Anda inginkan. Ini bisa berupa satu file atau seluruh pohon direktori. SageMaker mengemas file apa pun dalam direktori ini ke dalam file terkompresi (.tar.gz). File ini tersedia di lokasi Amazon S3 yang dikembalikan oleh operasi.DescribeTrainingJobAPI -
/opt/ml/output/adalah direktori tempat algoritme dapat menulisfailurefile yang menjelaskan mengapa pekerjaan gagal. Isi file ini dikembalikan diFailureReasonbidangDescribeTrainingJobhasil. Untuk pekerjaan yang berhasil, tidak ada alasan untuk menulis file ini karena diabaikan.
Buat skrip untuk container run
Buat skrip train shell yang SageMaker berjalan saat menjalankan image kontainer Docker. Ketika pelatihan selesai dan artefak model ditulis ke direktori masing-masing, keluar dari skrip.
./train
#!/bin/bash # Run your training program here # # # #
Buat Dockerfile
Buat Dockerfile dalam konteks build Anda. Contoh ini menggunakan Ubuntu 18.04 sebagai gambar dasar, tetapi Anda dapat mulai dari gambar dasar apa pun yang berfungsi untuk kerangka kerja Anda.
./Dockerfile
FROM ubuntu:18.04 # Add training dependencies and programs # # # # # # Add a script that SageMaker will run # Set run permissions # Prepend program directory to $PATH COPY /train /opt/program/train RUN chmod 755 /opt/program/train ENV PATH=/opt/program:${PATH}
DockerfileMenambahkan train skrip yang dibuat sebelumnya ke gambar. Direktori skrip ditambahkan ke PATH sehingga dapat berjalan ketika wadah berjalan.
Pada contoh sebelumnya, tidak ada logika pelatihan yang sebenarnya. Untuk gambar pelatihan Anda yang sebenarnya, tambahkan dependensi pelatihan keDockerfile, dan tambahkan logika untuk membaca input pelatihan untuk melatih dan menghasilkan artefak model.
Gambar pelatihan Anda harus berisi semua dependensi yang diperlukan karena tidak akan memiliki akses internet.
Untuk informasi selengkapnya, lihat Menggunakan algoritme dan model Anda sendiri dengan AWS Marketplace dan AWS Marketplace
SageMaker contoh
Langkah 2: Membangun dan menguji gambar secara lokal
Dalam konteks build, file berikut sekarang ada:
-
./Dockerfile -
./train -
Ketergantungan dan logika pelatihan Anda
Selanjutnya Anda dapat membangun, menjalankan, dan menguji image container ini.
Bangun citra
Jalankan perintah Docker dalam konteks build untuk membangun dan menandai gambar. Contoh ini menggunakan tagmy-training-image.
sudo docker build --tag my-training-image ./
Setelah menjalankan perintah Docker ini untuk membangun gambar, Anda akan melihat output saat Docker membangun gambar berdasarkan setiap baris di baris Anda. Dockerfile Setelah selesai, Anda akan melihat sesuatu yang mirip dengan yang berikut ini.
Successfully built abcdef123456
Successfully tagged my-training-image:latestJalankan secara lokal
Setelah itu selesai, uji gambar secara lokal seperti yang ditunjukkan pada contoh berikut.
sudo docker run \ --rm \ --volume '<path_to_input>:/opt/ml/input:ro' \ --volume '<path_to_model>:/opt/ml/model' \ --volume '<path_to_output>:/opt/ml/output' \ --name my-training-container \ my-training-image \ train
Berikut ini adalah detail perintah:
-
--rm- Secara otomatis menghapus wadah setelah berhenti. -
--volume '<path_to_input>:/opt/ml/input:ro'— Jadikan direktori input pengujian tersedia untuk wadah sebagai hanya-baca. -
--volume '<path_to_model>:/opt/ml/model'— Bind mount path di mana artefak model disimpan pada mesin host saat tes pelatihan selesai. -
--volume '<path_to_output>:/opt/ml/output'— Bind mount path di mana alasan kegagalan dalamfailurefile ditulis pada mesin host. -
--name my-training-container— Beri nama wadah yang sedang berjalan ini. -
my-training-image— Jalankan gambar yang dibangun. -
train— Jalankan skrip yang sama SageMaker berjalan saat menjalankan wadah.
Setelah menjalankan perintah ini, Docker membuat wadah dari gambar pelatihan yang Anda buat dan menjalankannya. Wadah menjalankan train skrip, yang memulai program pelatihan Anda.
Setelah program pelatihan Anda selesai dan wadah keluar, periksa apakah artefak model keluaran sudah benar. Selain itu, periksa keluaran log untuk mengonfirmasi bahwa mereka tidak menghasilkan log yang tidak Anda inginkan, sambil memastikan informasi yang cukup diberikan tentang pekerjaan pelatihan.
Ini melengkapi pengemasan kode pelatihan Anda untuk produk algoritme. Karena produk algoritme juga menyertakan gambar inferensi, lanjutkan ke bagian berikutnya, Membuat gambar inferensi untuk algoritme.
Membuat gambar inferensi untuk algoritme
Bagian ini memberikan panduan untuk mengemas kode inferensi Anda ke dalam gambar inferensi untuk produk algoritme Anda.
Gambar inferensi adalah gambar Docker yang berisi logika inferensi Anda. Container saat runtime mengekspos HTTP titik akhir untuk memungkinkan untuk meneruskan data SageMaker ke dan dari container Anda.
Baik gambar pelatihan dan inferensi diperlukan saat menerbitkan produk algoritme. Jika Anda belum melakukannya, lihat bagian sebelumnya tentangMembuat gambar pelatihan untuk algoritme. Kedua gambar dapat digabungkan menjadi satu gambar atau tetap sebagai gambar terpisah. Apakah akan menggabungkan gambar atau memisahkannya terserah Anda. Biasanya, inferensi lebih sederhana daripada pelatihan, dan Anda mungkin ingin gambar terpisah untuk membantu kinerja inferensi.
catatan
Berikut ini hanya satu contoh kode kemasan untuk gambar inferensi. Untuk informasi selengkapnya, lihat Menggunakan algoritme dan model Anda sendiri dengan AWS Marketplace dan AWS Marketplace
SageMaker contoh
Contoh berikut menggunakan layanan web, Flask
Langkah-langkah
Langkah 1: Membuat gambar inferensi
Agar gambar inferensi kompatibel SageMaker, gambar Docker harus mengekspos HTTP titik akhir. Saat kontainer Anda berjalan, SageMaker meneruskan input untuk inferensi yang diberikan oleh pembeli ke titik akhir kontainer HTTP Anda. Hasil inferensi dikembalikan ke dalam tubuh HTTP respons.
Berikut ini menggunakan Docker CLI diinstal dalam lingkungan pengembangan pada distribusi Ubuntu Linux.
Buat skrip server web
Contoh ini menggunakan server Python yang disebut Flask
catatan
Labu
Buat skrip server web Flask yang melayani dua HTTP titik akhir pada TCP port 8080 yang menggunakan. SageMaker Berikut ini adalah dua titik akhir yang diharapkan:
-
/ping— SageMaker membuat HTTP GET permintaan ke titik akhir ini untuk memeriksa apakah wadah Anda sudah siap. Saat penampung Anda siap, kontainer akan merespons HTTP GET permintaan di titik akhir ini dengan kode respons HTTP 200. -
/invocations— SageMaker membuat HTTP POST permintaan ke titik akhir ini untuk inferensi. Data input untuk inferensi dikirim dalam badan permintaan. Jenis konten yang ditentukan pengguna diteruskan di header. HTTP Tubuh respons adalah output inferensi.
./web_app_serve.py
# Import modules import json import re from flask import Flask from flask import request app = Flask(__name__) # Create a path for health checks @app.route("/ping") def endpoint_ping(): return "" # Create a path for inference @app.route("/invocations", methods=["POST"]) def endpoint_invocations(): # Read the input input_str = request.get_data().decode("utf8") # Add your inference code here. # # # # # # Add your inference code here. # Return a response with a prediction response = {"prediction":"a","text":input_str} return json.dumps(response)
Pada contoh sebelumnya, tidak ada logika inferensi yang sebenarnya. Untuk gambar inferensi Anda yang sebenarnya, tambahkan logika inferensi ke dalam aplikasi web sehingga memproses input dan mengembalikan prediksi.
Gambar inferensi Anda harus berisi semua dependensi yang diperlukan karena tidak akan memiliki akses internet.
Buat skrip untuk container run
Buat skrip bernama serve yang SageMaker berjalan saat menjalankan image kontainer Docker. Dalam skrip ini, mulai server HTTP web.
./serve
#!/bin/bash # Run flask server on port 8080 for SageMaker flask run --host 0.0.0.0 --port 8080
Buat Dockerfile
Buat Dockerfile dalam konteks build Anda. Contoh ini menggunakan Ubuntu 18.04, tetapi Anda dapat memulai dari gambar dasar apa pun yang berfungsi untuk kerangka kerja Anda.
./Dockerfile
FROM ubuntu:18.04 # Specify encoding ENV LC_ALL=C.UTF-8 ENV LANG=C.UTF-8 # Install python-pip RUN apt-get update \ && apt-get install -y python3.6 python3-pip \ && ln -s /usr/bin/python3.6 /usr/bin/python \ && ln -s /usr/bin/pip3 /usr/bin/pip; # Install flask server RUN pip install -U Flask; # Add a web server script to the image # Set an environment to tell flask the script to run COPY /web_app_serve.py /web_app_serve.py ENV FLASK_APP=/web_app_serve.py # Add a script that Amazon SageMaker will run # Set run permissions # Prepend program directory to $PATH COPY /serve /opt/program/serve RUN chmod 755 /opt/program/serve ENV PATH=/opt/program:${PATH}
DockerfileMenambahkan dua skrip yang dibuat sebelumnya ke gambar. Direktori serve skrip ditambahkan ke PATH sehingga dapat berjalan ketika wadah berjalan.
Mempersiapkan program Anda untuk memuat artefak model secara dinamis
Untuk produk algoritme, pembeli menggunakan kumpulan data mereka sendiri dengan gambar pelatihan Anda untuk menghasilkan artefak model yang unik. Saat proses pelatihan selesai, wadah pelatihan Anda mengeluarkan artefak model ke direktori kontainer.
/opt/ml/model/ SageMaker mengompres konten dalam direktori itu menjadi file.tar.gz dan menyimpannya di pembeli di Amazon S3. Akun AWS
Saat model diterapkan, SageMaker jalankan gambar inferensi Anda, ekstrak artefak model dari file.tar.gz yang disimpan di akun pembeli di Amazon S3, dan memuatnya ke wadah inferensi di direktori. /opt/ml/model/ Saat runtime, kode kontainer inferensi Anda menggunakan data model.
catatan
Untuk melindungi kekayaan intelektual apa pun yang mungkin terkandung dalam file artefak model, Anda dapat memilih untuk mengenkripsi file sebelum mengeluarkannya. Untuk informasi selengkapnya, lihat Keamanan dan kekayaan intelektual dengan Amazon SageMaker.
Langkah 2: Membangun dan menguji gambar secara lokal
Dalam konteks build, file berikut sekarang ada:
-
./Dockerfile -
./web_app_serve.py -
./serve
Selanjutnya Anda dapat membangun, menjalankan, dan menguji image container ini.
Bangun citra
Jalankan perintah Docker untuk membangun dan menandai gambar. Contoh ini menggunakan tagmy-inference-image.
sudo docker build --tag my-inference-image ./
Setelah menjalankan perintah Docker ini untuk membangun gambar, Anda akan melihat output saat Docker membangun gambar berdasarkan setiap baris di baris Anda. Dockerfile Setelah selesai, Anda akan melihat sesuatu yang mirip dengan yang berikut ini.
Successfully built abcdef123456
Successfully tagged my-inference-image:latestJalankan secara lokal
Setelah build selesai, Anda dapat menguji gambar secara lokal.
sudo docker run \ --rm \ --publish 8080:8080/tcp \ --volume '<path_to_model>:/opt/ml/model:ro' \ --detach \ --name my-inference-container \ my-inference-image \ serve
Berikut ini adalah detail perintah:
-
--rm- Secara otomatis menghapus wadah setelah berhenti. -
--publish 8080:8080/tcp— Ekspos port 8080 untuk mensimulasikan port SageMaker mengirim HTTP permintaan ke. -
--volume '<path_to_model>:/opt/ml/model:ro'— Bind mount path ke tempat artefak model uji disimpan di mesin host sebagai read-only untuk membuatnya tersedia untuk kode inferensi Anda dalam wadah. -
--detach— Jalankan wadah di latar belakang. -
--name my-inference-container— Beri nama wadah yang sedang berjalan ini. -
my-inference-image— Jalankan gambar yang dibangun. -
serve— Jalankan skrip yang sama SageMaker berjalan saat menjalankan wadah.
Setelah menjalankan perintah ini, Docker membuat wadah dari gambar inferensi dan menjalankannya di latar belakang. Wadah menjalankan serve skrip, yang memulai server web Anda untuk tujuan pengujian.
Uji titik HTTP akhir ping
Saat SageMaker menjalankan penampung Anda, penampung secara berkala melakukan ping ke titik akhir. Ketika titik akhir mengembalikan HTTP respons dengan kode status 200, itu memberi sinyal SageMaker bahwa wadah siap untuk inferensi.
Jalankan perintah berikut untuk menguji titik akhir dan sertakan header respons.
curl --include http://127.0.0.1:8080/ping
Contoh output ditunjukkan pada contoh berikut.
HTTP/1.0 200 OK
Content-Type: text/html; charset=utf-8
Content-Length: 0
Server: MyServer/0.16.0 Python/3.6.8
Date: Mon, 21 Oct 2019 06:58:54 GMTUji titik akhir inferensi HTTP
Ketika wadah menunjukkan siap dengan mengembalikan kode status 200, SageMaker meneruskan data inferensi ke /invocations HTTP titik akhir melalui permintaan. POST
Jalankan perintah berikut untuk menguji titik akhir inferensi.
curl \ --request POST \ --data "hello world" \ http://127.0.0.1:8080/invocations
Contoh output ditunjukkan pada contoh berikut..
{"prediction": "a", "text": "hello world"}Dengan dua HTTP titik akhir ini berfungsi, gambar inferensi sekarang kompatibel dengan. SageMaker
catatan
Model produk algoritme Anda dapat digunakan dalam dua cara: waktu nyata dan batch. Untuk kedua penerapan, SageMaker gunakan HTTP titik akhir yang sama saat menjalankan container Docker.
Untuk menghentikan kontainer, jalankan perintah berikut.
sudo docker container stop my-inference-container
Setelah gambar pelatihan dan inferensi Anda untuk produk algoritme Anda siap dan diuji, lanjutkan keMengunggah gambar Anda ke Amazon Elastic Container Registry.
