Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Kasus penggunaan
Berikut ini adalah kasus penggunaan pencarian vektor.
Retrieval Augmented Generation (RAG)
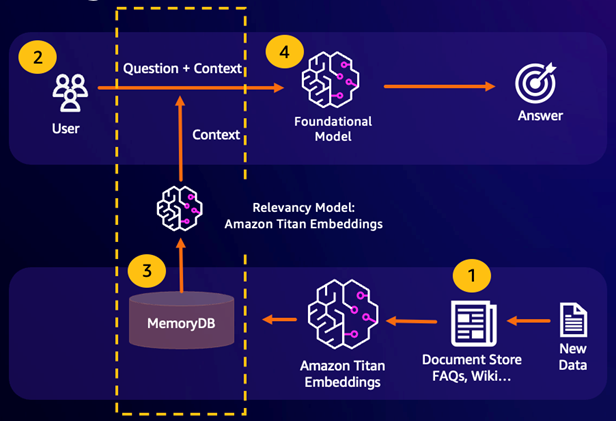
Retrieval Augmented Generation (RAG) memanfaatkan pencarian vektor untuk mengambil bagian yang relevan dari kumpulan data yang besar untuk menambah model bahasa besar (LLM). Secara khusus, encoder menyematkan konteks input dan kueri penelusuran ke dalam vektor, kemudian menggunakan perkiraan pencarian tetangga terdekat untuk menemukan bagian yang serupa secara semantik. Bagian yang diambil ini digabungkan dengan konteks asli untuk memberikan informasi tambahan yang relevan ke LLM untuk mengembalikan respons yang lebih akurat kepada pengguna.
Cache Semantik Tahan Lama
Semantic Caching adalah proses untuk mengurangi biaya komputasi dengan menyimpan hasil sebelumnya dari FM. Dengan menggunakan kembali hasil sebelumnya dari kesimpulan sebelumnya alih-alih mengkomputernya kembali, caching semantik mengurangi jumlah perhitungan yang diperlukan selama inferensi melalui. FMs MemoryDB memungkinkan caching semantik yang tahan lama, yang menghindari hilangnya data dari kesimpulan masa lalu Anda. Ini memungkinkan aplikasi AI generatif Anda merespons dalam milidetik satu digit dengan jawaban dari pertanyaan serupa semantik sebelumnya, sekaligus mengurangi biaya dengan menghindari kesimpulan LLM yang tidak perlu.
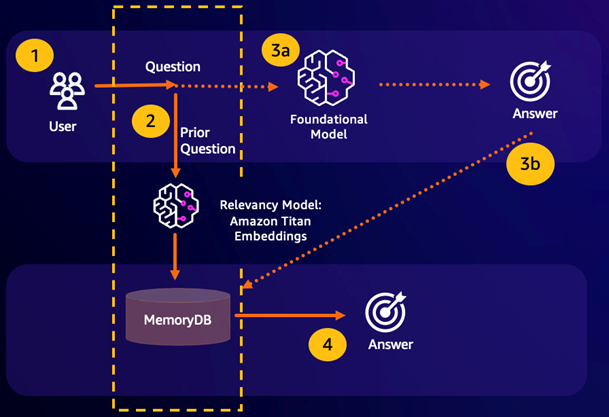
Pencarian semantik — Jika kueri pelanggan semantik serupa berdasarkan skor kesamaan yang ditentukan dengan pertanyaan sebelumnya, memori buffer FM (MemoryDB) akan mengembalikan jawaban ke pertanyaan sebelumnya di langkah 4 dan tidak akan memanggil FM melalui langkah 3. Ini akan menghindari latensi model pondasi (FM) dan biaya yang dikeluarkan, memberikan pengalaman yang lebih cepat bagi pelanggan.
Kehilangan pencarian semantik — Jika kueri pelanggan tidak semantik serupa berdasarkan skor kesamaan yang ditentukan dengan kueri sebelumnya, pelanggan akan menghubungi FM untuk memberikan respons kepada pelanggan pada langkah 3a. Respon yang dihasilkan dari FM kemudian akan disimpan sebagai vektor ke dalam MemoryDB untuk kueri future (langkah 3b) untuk meminimalkan biaya FM pada pertanyaan semantik serupa. Dalam alur ini, langkah 4 tidak akan dipanggil karena tidak ada pertanyaan semantik serupa untuk kueri asli.
Deteksi penipuan
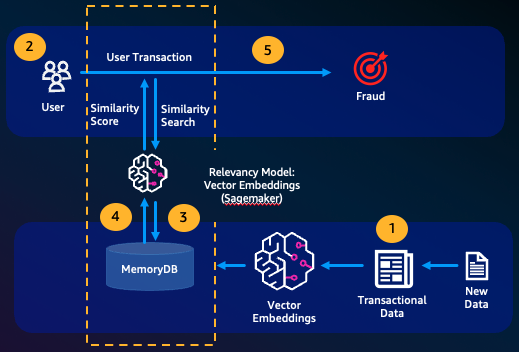
Deteksi penipuan, suatu bentuk deteksi anomali, mewakili transaksi yang valid sebagai vektor sambil membandingkan representasi vektor dari transaksi baru bersih. Penipuan terdeteksi ketika transaksi baru bersih ini memiliki kesamaan rendah dengan vektor yang mewakili data transaksional yang valid. Hal ini memungkinkan penipuan dideteksi dengan memodelkan perilaku normal, daripada mencoba memprediksi setiap kemungkinan kejadian penipuan. MemoryDB memungkinkan organisasi untuk melakukan ini dalam periode throughput tinggi, dengan positif palsu minimal dan latensi milidetik satu digit.
Kasus penggunaan lainnya
Mesin rekomendasi dapat menemukan pengguna produk atau konten serupa dengan mewakili item sebagai vektor. Vektor dibuat dengan menganalisis atribut dan pola. Berdasarkan pola dan atribut pengguna, item baru yang tidak terlihat dapat direkomendasikan kepada pengguna dengan menemukan vektor paling mirip yang telah dinilai secara positif selaras dengan pengguna.
Mesin pencari dokumen mewakili dokumen teks sebagai vektor angka yang padat, menangkap makna semantik. Pada waktu pencarian, mesin mengubah permintaan pencarian ke vektor dan menemukan dokumen dengan vektor yang paling mirip dengan kueri menggunakan perkiraan pencarian tetangga terdekat. Pendekatan kesamaan vektor ini memungkinkan pencocokan dokumen berdasarkan makna daripada hanya mencocokkan kata kunci.
