Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
catatan
Amazon Neptunus mengirimkan metrik CloudWatch hanya ketika mereka memiliki nilai bukan nol.
Untuk semua metrik Neptune lainnya, granularitas agregasi adalah 5 menit.
Metrik Neptunus CloudWatch
Tabel berikut mencantumkan CloudWatch metrik yang didukung Neptunus.
catatan
Semua metrik kumulatif diatur ulang ke nol setiap kali server restart, baik untuk pemeliharaan, reboot, atau pemulihan dari crash.
| Metrik | Deskripsi |
|---|---|
|
Jumlah total penyimpanan cadangan, dalam byte, digunakan untuk mendukung jendela penyimpanan cadangan klaster DB Neptune. Termasuk dalam total yang dilaporkan oleh metrik |
|
Persentase permintaan yang dilayani oleh cache buffer. Metrik ini dapat berguna dalam mendiagnosis permintaan latensi, karena cache terlewat menginduksi latensi yang signifikan. Jika rasio hit cache di bawah 99,9, pertimbangkan untuk meningkatkan tipe instans untuk meng-cache lebih banyak data dalam memori. |
|
Untuk replika baca, jumlah lag saat mereplikasi pembaruan dari instans primer, dalam milidetik. |
|
Jumlah maksimum lag antara instans primer dan setiap instans DB Neptune dalam klaster DB, dalam milidetik. |
|
Jumlah minimum lag antara instans primer dan setiap instans DB Neptune dalam klaster DB, dalam milidetik. |
|
Jumlah kredit CPU yang diakumulasikan oleh satu instans, yang dilaporkan pada interval 5 menit. Anda dapat menggunakan metrik ini untuk menentukan berapa lama instans DB dapat melakukan burst melampaui tingkat performa dasarnya pada tingkat tertentu. |
|
Jumlah CPU yang digunakan selama periode tertentu, yang dilaporkan pada interval 5 menit. Metrik ini mengukur jumlah waktu selama fisik CPUs telah digunakan untuk memproses instruksi oleh virtual yang CPUs dialokasikan ke instans DB. |
|
Jumlah kredit surplus yang telah digunakan oleh sebuah instans tak terbatas ketika nilai |
|
Jumlah kredit surplus yang dibelanjakan yang tidak dibayar oleh kredit CPU yang diperoleh, dan dikenakan biaya tambahan. |
|
Persentase penggunaan CPU. |
|
Jumlah waktu, dalam detik, instans telah berjalan. |
|
Jumlah memori akses acak yang tersedia, dalam byte. |
|
Jumlah byte data redo log yang ditransfer dari primer Wilayah AWS ke sekunder Wilayah AWS dalam database global Neptunus. |
|
Jumlah operasi tulis I/O direplikasi dari primer Wilayah AWS dalam database global ke volume cluster di sekunder. Wilayah AWS Perhitungan penagihan untuk setiap cluster DB dalam database global Neptunus menggunakan metrik untuk memperhitungkan penulisan |
|
Jumlah milidetik yang cluster sekunder berada di belakang cluster utama untuk transaksi pengguna dan transaksi sistem. |
|
Jumlah kesalahan sisi klien per detik di traversal Gremlin. |
|
Jumlah kesalahan sisi server per detik dalam traversal Gremlin. |
|
Jumlah permintaan per detik untuk mesin Gremlin. |
|
Jumlah WebSocket koneksi terbuka ke Neptunus. |
|
Jumlah kesalahan sisi klien per detik dari permintaan loader. |
|
Jumlah permintaan loader per detik. |
|
Jumlah kesalahan sisi server loader per detik. |
|
Jumlah permintaan yang menunggu di eksekusi yang tertunda antrean input. Neptune mulai melakukan throttling permintaan ketika mereka melebihi kapasitas antrean maksimum. |
|
Hanya berlaku untuk instans DB Tanpa Server Neptunus atau cluster DB. Pada tingkat instans, melaporkan persentase yang dihitung sebagai jumlah unit kapasitas Neptunus NCUs () yang saat ini digunakan oleh instance yang dimaksud, dibagi dengan pengaturan kapasitas NCU maksimum untuk cluster. NCU, atau unit kapasitas Neptunus, terdiri dari 2 GiB (gibibyte) memori (RAM), bersama dengan kapasitas prosesor virtual terkait (vCPU) dan jaringan. Pada tingkat cluster, |
|
Jumlah throughput jaringan yang diterima dari dan dikirim ke klien oleh setiap instans di klaster DB Neptune, dalam byte per detik. Throughput ini tidak termasuk lalu lintas jaringan antara instance di cluster DB dan volume cluster. |
|
Jumlah throughput jaringan keluar yang ditransmisikan ke klien oleh setiap instance di cluster DB Neptunus, dalam byte per detik. Throughput ini tidak termasuk lalu lintas jaringan antara instance di cluster DB dan volume cluster. |
NumIndexDeletesPerSec |
Jumlah penghapusan dari indeks individu. Penghapusan dari setiap indeks dihitung secara individual. Ini termasuk penghapusan yang mungkin dibatalkan jika kueri menemukan kesalahan. |
NumIndexInsertsPerSec |
Jumlah sisipan ke indeks individu. Sisipan untuk setiap indeks dihitung secara terpisah. Ini termasuk sisipan yang mungkin dibatalkan jika kueri menemukan kesalahan. |
NumIndexReadsPerSec |
Jumlah pernyataan yang dipindai dari indeks apa pun. Setiap pola akses dimulai dengan pencarian pada indeks dan membaca semua pernyataan yang cocok. Peningkatan metrik ini dapat menyebabkan peningkatan latensi kueri atau pemanfaatan CPU. |
|
Jumlah kesalahan OpenCypher klien per detik. |
|
Jumlah OpenCypher permintaan per detik. |
|
Jumlah kesalahan OpenCypher server per detik. |
|
Jumlah permintaan antri per detik. |
|
Jumlah hasil cache hasil Gremlin. |
|
Jumlah cache hasil Gremlin meleset. |
|
Jumlah transaksi yang berhasil dilakukan per detik. |
|
Jumlah transaksi yang dibuka pada server per detik. |
|
Untuk query tulis, jumlah transaksi per detik digulung kembali di server karena kesalahan. Untuk kueri hanya-baca, metrik ini sama dengan jumlah transaksi hanya-baca yang diselesaikan per detik. |
NumUndoPagesPurged |
Metrik ini menunjukkan jumlah batch yang dibersihkan. Metrik ini adalah indikator kemajuan dalam pembersihan. Nilainya 0 untuk instance pembaca, dan metrik hanya berlaku untuk instance penulis. |
|
Jumlah permintaan per detik (baik HTTPS dan Bolt) ke mesin OpenCypher. |
|
Jumlah koneksi Bolt terbuka ke Neptunus. |
|
Total perkiraan ukuran (dalam byte) dari semua item yang di-cache di cache hasil Gremlin. |
|
Jumlah item dalam cache hasil Gremlin. |
|
Stempel waktu item tertua yang di-cache di cache hasil Gremlin. |
|
Stempel waktu item terbaru yang di-cache di cache hasil Gremlin. |
|
Sebagai metrik tingkat instance, Pada tingkat cluster, |
|
Jumlah total penyimpanan cadangan yang digunakan oleh semua snapshot untuk klaster Aurora DB Neptune di luar jendela penyimpanan cadangan, dalam byte. Termasuk dalam total yang dilaporkan oleh metrik |
|
Jumlah kesalahan sisi klien per detik dalam kueri SPARQL. |
|
Jumlah permintaan per detik untuk mesin SPARQL. |
|
Jumlah kesalahan server SPARQL per detik. |
|
Jumlah total pernyataan yang dipindai untuk statistik DFE sejak server dimulai. Setiap kali perhitungan statistik dipicu, angka ini meningkat, tetapi ketika tidak ada perhitungan yang terjadi, itu tetap statis. Akibatnya, jika Anda membuat grafik dari waktu ke waktu, Anda dapat mengetahui kapan perhitungan terjadi dan kapan tidak: 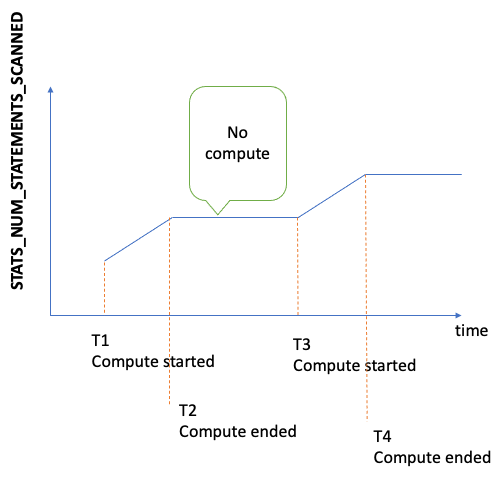
Dengan melihat kemiringan grafik pada periode di mana metrik meningkat, Anda juga dapat mengetahui seberapa cepat perhitungan berjalan. Jika tidak ada metrik seperti itu, itu berarti fitur statistik dinonaktifkan di cluster DB Anda, atau versi mesin yang Anda jalankan tidak memiliki fitur statistik. Jika nilai metrik nol, itu berarti tidak ada perhitungan statistik yang terjadi. |
|
Jumlah throughput jaringan yang diterima dari subsistem penyimpanan oleh setiap instance di cluster DB Neptunus. |
StorageNetworkThroughput |
Jumlah throughput jaringan yang diterima dari dan dikirim ke subsistem penyimpanan oleh setiap instance di cluster DB Neptunus. |
|
Jumlah throughput jaringan yang dikirim ke subsistem penyimpanan oleh setiap instance di cluster DB Neptunus. |
|
Jumlah ruang swap yang digunakan. |
|
Jumlah IOPS untuk membaca dan menulis pada penyimpanan lokal yang dilampirkan ke instans DB Neptunus. Metrik ini merepresentasikan hitungan dan diukur sekali per detik. |
|
Jumlah data yang ditransfer ke dan dari penyimpanan lokal yang terkait dengan instans DB Neptunus. Metrik ini merepresentasikan byte dan diukur sekali per detik. |
|
Jumlah total penyimpanan cadangan yang akan ditagihkan untuk klaster DB Neptune tertentu, dalam byte. Termasuk penyimpanan backup yang diukur oleh metrik |
|
Jumlah total permintaan per detik ke server dari semua sumber. |
|
Jumlah total per detik permintaan yang mengalami kesalahan karena masalah sisi klien. |
|
Jumlah total per detik permintaan yang mengalami kesalahan pada server karena kegagalan internal. |
|
Hitungan batalkan log dalam daftar log undo. Undo log berisi catatan transaksi berkomitmen yang kedaluwarsa ketika semua transaksi aktif lebih baru daripada waktu komit. Catatan yang kedaluwarsa dibersihkan secara berkala. Catatan untuk operasi penghapusan dapat memakan waktu lebih lama untuk dibersihkan daripada catatan untuk jenis transaksi lainnya. Pembersihan dilakukan secara eksklusif oleh instance penulis cluster DB, sehingga tingkat pembersihan tergantung pada jenis instance penulis. Jika tinggi dan berkembang di cluster DB Anda, tingkatkan instance penulis untuk meningkatkan tingkat pembersihan. Juga, jika Anda meningkatkan ke versi mesin |
|
Jumlah total penyimpanan yang dialokasikan untuk klaster DB Neptune Anda, dalam byte. Ini adalah jumlah penyimpanan yang ditagih untuk Anda. Ini adalah jumlah maksimum penyimpanan yang dialokasikan untuk klaster DB Anda pada setiap titik keberadaannya, bukan jumlah yang sedang Anda gunakan (lihat Penagihan penyimpanan Neptunus). |
|
Jumlah total operasi baca I/O yang ditagih dari volume cluster, melaporkan interval 5 menit. Operasi baca bertagihan dihitung pada tingkat volume klaster, GA dari semua instans dalam klaster DB Neptune, kemudian dilaporkan pada interval 5 menit. |
VolumeWriteIOPs |
Jumlah total operasi I/O disk tulis ke volume cluster, dilaporkan pada interval 5 menit. |
CloudWatch Metrik yang Sekarang Tidak Digunakan Lagi di Neptunus
Penggunaan metrik Neptune ini sekarang telah usang. Mereka masih didukung, tetapi dapat dihilangkan di masa depan karena metrik baru dan lebih baik tersedia.
Metrik |
Deskripsi |
|---|---|
|
Jumlah respons HTTP 1xx untuk titik akhir Gremlin per detik. Kami menyarankan agar Anda menggunakan metrik gabungan |
|
Jumlah respons HTTP 2xx untuk titik akhir Gremlin per detik. Kami menyarankan agar Anda menggunakan metrik gabungan |
|
Jumlah kesalahan HTTP 4xx untuk titik akhir Gremlin per detik. Kami menyarankan agar Anda menggunakan metrik gabungan |
|
Jumlah kesalahan HTTP 5xx untuk titik akhir Gremlin per detik. Kami menyarankan agar Anda menggunakan metrik gabungan |
|
Jumlah kesalahan dalam traversal Gremlin. |
|
Jumlah permintaan untuk mesin Gremlin. |
|
Jumlah WebSocket koneksi yang berhasil ke titik akhir Gremlin per detik. |
|
Jumlah kesalahan WebSocket klien pada titik akhir Gremlin per detik. |
|
Jumlah kesalahan WebSocket server pada titik akhir Gremlin per detik. |
|
Jumlah WebSocket koneksi potensial yang tersedia saat ini. |
|
Jumlah respons HTTP 100 untuk titik akhir per detik. Kami menyarankan agar Anda menggunakan metrik gabungan |
|
Jumlah respons HTTP 101 untuk titik akhir per detik. Kami menyarankan agar Anda menggunakan metrik gabungan |
|
Jumlah respons HTTP 1xx untuk titik akhir per detik. |
|
Jumlah respons HTTP 200 untuk titik akhir per detik. Kami menyarankan agar Anda menggunakan metrik gabungan |
|
Jumlah respons HTTP 2xx untuk titik akhir per detik. |
|
Jumlah kesalahan HTTP 400 untuk titik akhir per detik. Kami menyarankan agar Anda menggunakan metrik gabungan |
|
Jumlah kesalahan HTTP 403 untuk titik akhir per detik. Kami menyarankan agar Anda menggunakan metrik gabungan |
|
Jumlah kesalahan HTTP 405 untuk titik akhir per detik. Kami menyarankan agar Anda menggunakan metrik gabungan |
|
Jumlah kesalahan HTTP 413 untuk titik akhir per detik. Kami menyarankan agar Anda menggunakan metrik gabungan |
|
Jumlah kesalahan HTTP 429 untuk titik akhir per detik. Kami menyarankan agar Anda menggunakan metrik gabungan |
|
Jumlah kesalahan HTTP 4xx untuk titik akhir per detik. |
|
Jumlah kesalahan HTTP 500 untuk titik akhir per detik. Kami menyarankan agar Anda menggunakan metrik gabungan |
|
Jumlah kesalahan HTTP 501 untuk titik akhir per detik. Kami menyarankan agar Anda menggunakan metrik gabungan |
|
Jumlah kesalahan HTTP 5xx untuk titik akhir per detik. |
|
Jumlah kesalahan dari permintaan Loader. |
|
Jumlah Permintaan Loader. |
|
Jumlah respons HTTP 1xx untuk titik akhir SPARQL per detik. Kami menyarankan agar Anda menggunakan metrik gabungan |
|
Jumlah respons HTTP 2xx untuk titik akhir SPARQL per detik. Kami menyarankan agar Anda menggunakan metrik gabungan |
|
Jumlah kesalahan HTTP 4xx untuk titik akhir SPARQL per detik. Kami menyarankan agar Anda menggunakan metrik gabungan |
|
Jumlah kesalahan HTTP 5xx untuk titik akhir SPARQL per detik. Kami menyarankan agar Anda menggunakan metrik gabungan |
|
Jumlah kesalahan dalam kueri SPARQL. |
|
Jumlah permintaan ke mesin SPARQL. |
|
Jumlah kesalahan dari titik akhir status. |
|
Jumlah permintaan ke titik akhir status. |
