Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Apa itu Amazon Tanpa OpenSearch Server?
Amazon OpenSearch Serverless adalah opsi on-demand, tanpa server untuk OpenSearch Amazon Service yang menghilangkan kompleksitas operasional penyediaan, konfigurasi, dan penyetelan cluster. OpenSearch Ini ideal untuk organisasi yang memilih untuk tidak mengelola sendiri cluster mereka atau tidak memiliki sumber daya dan keahlian khusus untuk mengoperasikan penyebaran skala besar. Dengan OpenSearch Tanpa Server, Anda dapat mencari dan menganalisis volume data yang besar tanpa mengelola infrastruktur yang mendasarinya.
Koleksi OpenSearch tanpa server adalah sekelompok OpenSearch indeks yang bekerja sama untuk mendukung beban kerja atau kasus penggunaan tertentu. Koleksi menyederhanakan operasi dibandingkan dengan OpenSearch cluster yang dikelola sendiri, yang memerlukan penyediaan manual.
Koleksi menggunakan penyimpanan berkapasitas tinggi, terdistribusi, dan sangat tersedia yang sama dengan domain OpenSearch Layanan yang disediakan, tetapi selanjutnya mengurangi kompleksitas dengan menghilangkan konfigurasi dan penyetelan manual. Data dalam koleksi dienkripsi dalam perjalanan. OpenSearch Serverless juga mendukung OpenSearch Dasbor, menyediakan antarmuka untuk analisis data.
OpenSearch Serverless kompatibel dengan open source. OpenSearch Saat versi baru dirilis, OpenSearch Tanpa Server secara otomatis meningkatkan koleksi untuk menggabungkan fitur baru, perbaikan bug, dan peningkatan kinerja.
OpenSearch Serverless mendukung operasi API ingest dan query yang sama dengan suite OpenSearch open source, sehingga Anda dapat terus menggunakan klien dan aplikasi yang ada. Klien Anda harus kompatibel dengan OpenSearch 3.x agar dapat bekerja dengan Tanpa OpenSearch Server. Untuk informasi selengkapnya, lihat Menyerap data ke dalam koleksi Amazon Tanpa OpenSearch Server.
Topik
Kasus penggunaan untuk Tanpa OpenSearch Server
OpenSearch Tanpa server mendukung dua kasus penggunaan utama:
-
Analisis log - Segmen analisis log berfokus pada analisis volume besar data deret waktu semi-terstruktur yang dihasilkan mesin untuk wawasan operasional dan perilaku pengguna.
-
Full-text pencarian - Segmen pencarian teks lengkap mendukung aplikasi di jaringan internal Anda (sistem manajemen konten, dokumen hukum) dan aplikasi yang menghadap ke internet, seperti pencarian konten situs web e-commerce.
Saat Anda membuat koleksi, Anda memilih salah satu kasus penggunaan ini. Untuk informasi selengkapnya, lihat Memilih jenis koleksi.
Cara kerjanya
OpenSearch Cluster tradisional memiliki satu set instance yang melakukan operasi pengindeksan dan pencarian, dan penyimpanan indeks digabungkan erat dengan kapasitas komputasi. Sebaliknya, OpenSearch Tanpa Server menggunakan arsitektur cloud-native yang memisahkan komponen pengindeksan (ingest) dari komponen penelusuran (kueri), dengan Amazon S3 sebagai penyimpanan data utama untuk indeks.
Arsitektur terpisah ini memungkinkan Anda menskalakan fungsi pencarian dan pengindeksan secara independen satu sama lain, dan secara independen dari data yang diindeks di S3. Arsitektur juga menyediakan isolasi untuk operasi ingest dan query sehingga mereka dapat berjalan secara bersamaan tanpa pertentangan sumber daya.
Saat Anda menulis data ke koleksi, OpenSearch Tanpa Server mendistribusikannya ke unit komputasi pengindeksan. Unit komputasi pengindeksan menyerap data yang masuk dan memindahkan indeks ke S3. Saat Anda melakukan penelusuran pada data pengumpulan, Rutekan OpenSearch Tanpa Server meminta ke unit komputasi penelusuran yang menyimpan data yang sedang ditanyakan. Unit komputasi pencarian mengunduh data yang diindeks langsung dari S3 (jika belum di-cache secara lokal), menjalankan operasi pencarian, dan melakukan agregasi.
Gambar berikut mengilustrasikan arsitektur terpisah ini:
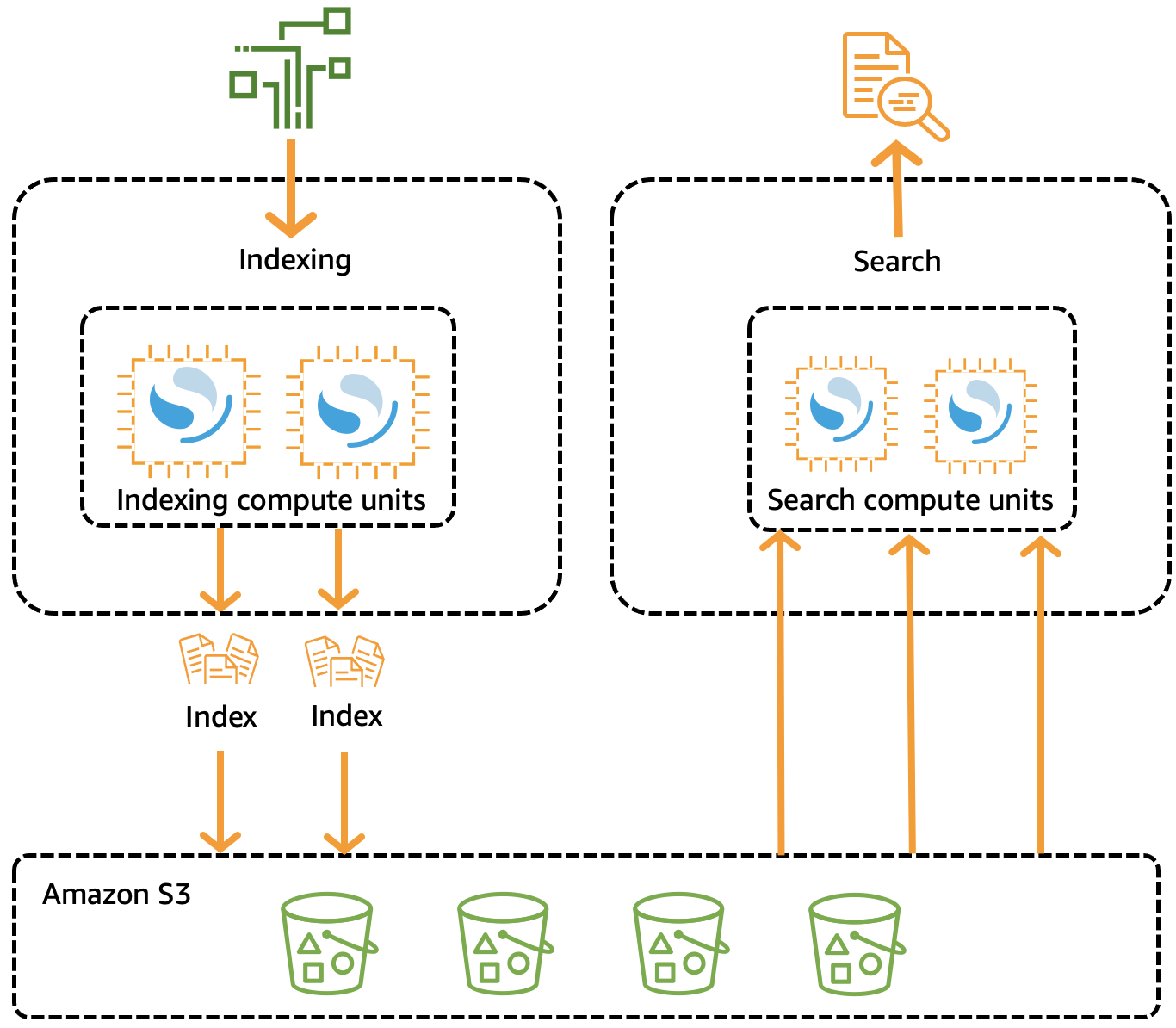
OpenSearch Kapasitas komputasi tanpa server untuk konsumsi data, pencarian, dan kueri diukur dalam OpenSearch Compute Units (OCU). Setiap OCU adalah kombinasi dari 6 GiB memori dan CPU virtual yang sesuai (vCPU), serta transfer data ke Amazon S3.
OpenSearch Serverless menyediakan OCU secara terpisah untuk pencarian dan pengindeksan. OpenSearch Tanpa server hanya menambahkan OCU tambahan untuk pencarian dan konsumsi sesuai kebutuhan untuk mendukung koleksi, sesuai dengan batas kapasitas yang Anda tentukan. Kapasitas turun kembali saat penggunaan komputasi Anda berkurang.
Untuk informasi tentang cara Anda ditagih untuk OCU ini, lihat harga OpenSearch Layanan Amazon
Memilih jenis koleksi
OpenSearch Serverless mendukung tiga jenis koleksi utama:
Time series — Segmen analisis log yang menganalisis volume besar data semi-terstruktur yang dihasilkan mesin secara real-time, memberikan wawasan tentang operasi, keamanan, perilaku pengguna, dan kinerja bisnis.
catatan
Koleksi time series hanya tersedia untuk koleksi Classic. NextGenkoleksi saat ini hanya mendukung jenis pencarian Pencarian dan Vektor.
Pencarian — Full-text pencarian yang memungkinkan aplikasi dalam jaringan internal, seperti sistem manajemen konten dan repositori dokumen hukum, serta aplikasi yang menghadap ke internet seperti pencarian situs e-commerce dan penemuan konten.
Pencarian vektor — Pencarian semantik pada penyematan vektor menyederhanakan manajemen data vektor dan memungkinkan pengalaman pencarian yang ditambah pembelajaran mesin (ML). Ini mendukung aplikasi AI generatif seperti chatbots, asisten pribadi, dan deteksi penipuan.
Anda memilih jenis koleksi saat pertama kali membuat koleksi:
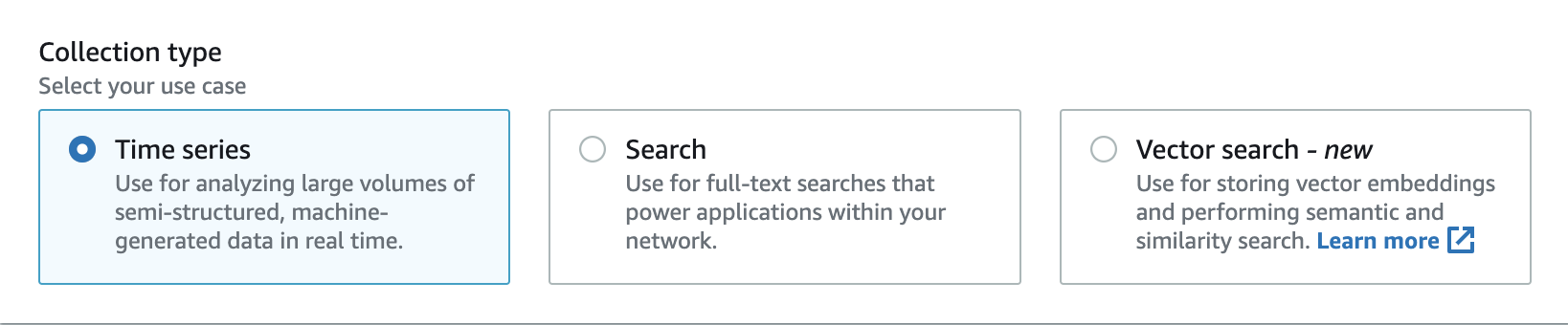
Jenis koleksi yang Anda pilih bergantung pada jenis data yang Anda rencanakan untuk dicerna ke dalam koleksi, dan bagaimana Anda berencana untuk menanyakannya. Anda tidak dapat mengubah jenis koleksi setelah Anda membuatnya.
Jenis koleksi memiliki perbedaan penting berikut:
-
Untuk koleksi pencarian dan pencarian vektor, semua data disimpan dalam penyimpanan panas untuk memastikan waktu respons kueri yang cepat. Koleksi deret waktu menggunakan kombinasi penyimpanan panas dan hangat, di mana data terbaru disimpan dalam penyimpanan panas untuk mengoptimalkan waktu respons kueri untuk data yang lebih sering diakses.
-
Untuk koleksi deret waktu, Anda tidak dapat mengindeks berdasarkan ID dokumen kustom atau memperbarui dengan permintaan upsert. Operasi ini dicadangkan untuk kasus penggunaan pencarian. Anda dapat memperbarui dengan ID dokumen sebagai gantinya. Untuk informasi selengkapnya, lihat Operasi dan izin OpenSearch API yang didukung.
-
Untuk koleksi penelusuran dan deret waktu, Anda tidak dapat menggunakan indeks tipe K-nN.
Didukung Wilayah AWS
OpenSearch Tanpa server tersedia dalam subset OpenSearch Layanan Wilayah AWS yang tersedia di. Untuk daftar Wilayah yang didukung, lihat titik akhir dan kuota OpenSearch Layanan Amazon di. Referensi Umum AWS
Batasan
OpenSearch Tanpa server memiliki batasan sebagai berikut:
-
Beberapa operasi OpenSearch API tidak didukung. Lihat Operasi dan izin OpenSearch API yang didukung.
-
Beberapa OpenSearch plugin tidak didukung. Lihat OpenSearch Plugin yang didukung.
-
Saat ini tidak ada cara untuk secara otomatis memigrasikan data Anda dari domain OpenSearch Layanan terkelola ke koleksi tanpa server. Anda harus mengindeks ulang data Anda dari domain ke koleksi.
-
Cross-account akses ke koleksi tidak didukung. Anda tidak dapat menyertakan koleksi dari akun lain dalam enkripsi atau kebijakan akses data Anda.
-
OpenSearch Plugin khusus tidak didukung.
-
Snapshot otomatis didukung untuk koleksi Tanpa OpenSearch Server. Snapshot manual tidak didukung. Untuk informasi selengkapnya, lihat Mencadangkan koleksi menggunakan snapshot.
-
Cross-Region pencarian dan replikasi tidak didukung.
-
Ada batasan jumlah sumber daya tanpa server yang dapat Anda miliki dalam satu akun dan Wilayah. Lihat OpenSearch Kuota tanpa server.
-
Interval penyegaran untuk indeks dalam penelusuran dan koleksi deret waktu kira-kira 10 detik.
-
Jumlah pecahan, jumlah interval, dan interval penyegaran tidak dapat dimodifikasi dan ditangani oleh Tanpa Server. OpenSearch Strategi sharding didasarkan pada jenis koleksi dan lalu lintas. Misalnya, pengumpulan deret waktu menskalakan pecahan primer berdasarkan kemacetan lalu lintas tulis.
