Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Pemecahan Masalah Tumpukan AWS OpsWorks
penting
AWS OpsWorks Stacks Layanan ini mencapai akhir masa pakai pada 26 Mei 2024 dan telah dinonaktifkan untuk pelanggan baru dan yang sudah ada. Kami sangat menyarankan pelanggan untuk memindahkan beban kerja mereka ke solusi lain sesegera mungkin. Jika Anda memiliki pertanyaan tentang migrasi, hubungi AWS Support Tim di AWS re:Post
Bagian ini berisi beberapa masalah AWS OpsWorks Stacks yang umum ditemui dan solusinya.
Topik
- Tidak Dapat Mengelola Instance
- Setelah Chef Run, Instance Tidak Akan Boot
- Contoh Lapisan Semua Gagal Pemeriksaan Kesehatan Elastic Load Balancing
- Tidak Dapat Berkomunikasi dengan Load Balancer Elastic Load Balancing
- Instance Lokal yang Diimpor Gagal Menyelesaikan Pengaturan Volume Setelah Mulai Ulang
- Volume EBS Tidak Terpasang Kembali Setelah Reboot
- Tidak Dapat Menghapus AWS OpsWorks Grup Keamanan Stacks
- Tidak Sengaja Menghapus Grup Keamanan AWS OpsWorks Stacks
- Chef Log Berakhir Tiba-tiba
- Cookbook Tidak Diperbarui
- Instance Terjebak di Status Booting
- Instans Secara Tak Terduga Mulai Ulang
- opsworks-agentProses Berjalan pada Instance
- Perintah execute_recipes yang tidak terduga
Tidak Dapat Mengelola Instance
Masalah: Anda tidak lagi dapat mengelola instance yang telah dikelola di masa lalu. Dalam beberapa kasus, log dapat menunjukkan kesalahan yang mirip dengan berikut ini.
Aws::CharlieInstanceService::Errors::UnrecognizedClientException - The security token included in the request is invalid.
Penyebab: Ini dapat terjadi jika sumber daya AWS OpsWorks di luar tempat instance bergantung telah diedit atau dihapus. Berikut ini adalah contoh perubahan sumber daya yang dapat memutus komunikasi dengan sebuah instance.
-
Pengguna IAM atau peran yang terkait dengan instance telah dihapus secara tidak sengaja, di luar AWS OpsWorks Stacks. Hal ini menyebabkan kegagalan komunikasi antara AWS OpsWorks agen yang diinstal pada instance, dan layanan AWS OpsWorks Stacks. Pengguna yang terkait dengan instance diperlukan sepanjang umur instance.
-
Mengedit konfigurasi volume atau penyimpanan saat instance offline dapat membuat instance tidak dapat dikelola.
-
Menambahkan instans EC2 ke ELB secara manual. AWS OpsWorks mengonfigurasi ulang penyeimbang beban Elastic Load Balancing yang ditetapkan setiap kali instance masuk atau keluar dari status online. AWS OpsWorks hanya menganggap contoh yang diketahuinya akan menjadi anggota yang valid; contoh yang ditambahkan di luar AWS OpsWorks, atau oleh beberapa proses lain, dihapus. Setiap contoh lainnya dihapus.
Solusi: Jangan hapus pengguna IAM atau peran yang menjadi sandaran instans Anda. Jika memungkinkan, edit konfigurasi volume atau penyimpanan hanya saat instance dependen sedang berjalan. Gunakan AWS OpsWorks untuk mengelola load balancer atau keanggotaan EIP instance. AWS OpsWorks Saat Anda mendaftarkan instance, untuk membantu mencegah masalah dalam mengelola instance terdaftar jika pengguna terhapus secara tidak sengaja, tambahkan --use-instance-profile parameter ke register perintah Anda untuk menggunakan profil instans bawaan instans sebagai gantinya.
Setelah Chef Run, Instance Tidak Akan Boot
Masalah: Pada Chef 11.10 atau tumpukan yang lebih lama yang dikonfigurasi untuk menggunakan buku masak khusus, setelah Chef menjalankan yang menggunakan buku masak komunitas, instance tidak akan boot. Pesan log dapat menyatakan bahwa resep gagal dikompilasi (“Kesalahan Kompilasi Resep”), atau tidak dapat dimuat karena tidak dapat menemukan ketergantungan.
Penyebab: Penyebab yang paling mungkin adalah buku masak kustom atau komunitas tidak mendukung versi Chef yang digunakan tumpukan Anda. Beberapa buku masak komunitas populer, seperti apt danbuild-essential, telah mengetahui masalah kompatibilitas dengan Chef 11.10.
Solusi: Pada AWS OpsWorks tumpukan Tumpukan yang mengaktifkan pengaturan Gunakan buku masak Chef kustom, buku masak khusus atau komunitas harus selalu mendukung versi Chef yang digunakan tumpukan Anda. Sematkan buku masak komunitas ke versi (yaitu, atur nomor versi buku masak ke versi tertentu) yang kompatibel dengan versi Chef yang dikonfigurasi dalam pengaturan tumpukan Anda. Untuk menemukan versi buku masak komunitas yang didukung, lihat changelog untuk buku masak yang gagal dikompilasi, dan gunakan hanya versi terbaru dari buku masak yang akan didukung oleh tumpukan Anda. Untuk menyematkan versi buku masak, tentukan nomor versi yang tepat di Berksfile repositori buku masak kustom Anda. Misalnya, cookbook 'build-essential', '= 3.2.0'.
Contoh Lapisan Semua Gagal Pemeriksaan Kesehatan Elastic Load Balancing
Masalah: Anda melampirkan penyeimbang beban Elastic Load Balancing ke lapisan server aplikasi, tetapi semua instance gagal dalam pemeriksaan kesehatan.
Penyebab: Saat membuat penyeimbang beban Elastic Load Balancing, Anda harus menentukan jalur ping yang dipanggil penyeimbang beban untuk menentukan apakah instans tersebut sehat. Pastikan untuk menentukan jalur ping yang sesuai untuk aplikasi Anda; nilai defaultnya adalah /index.html. Jika aplikasi Anda tidak termasukindex.html, Anda harus menentukan jalur yang sesuai atau pemeriksaan kesehatan akan gagal. Misalnya, aplikasi SimplePhpApp yang digunakan Memulai dengan Chef 11 Linux Stacks tidak menggunakan index.html; jalur ping yang sesuai untuk server tersebut adalah /.
Solusi: Edit jalur ping penyeimbang beban. Untuk informasi selengkapnya, lihat Elastic Load Balancing
Tidak Dapat Berkomunikasi dengan Load Balancer Elastic Load Balancing
Masalah: Anda membuat penyeimbang beban Elastic Load Balancing dan melampirkannya ke lapisan server aplikasi, tetapi ketika Anda mengklik nama DNS atau alamat IP penyeimbang beban untuk menjalankan aplikasi, Anda mendapatkan kesalahan berikut: “Server jarak jauh tidak merespons”.
Penyebab: Jika tumpukan Anda berjalan di VPC default, saat Anda membuat penyeimbang beban Elastic Load Balancing di wilayah tersebut, Anda harus menentukan grup keamanan. Grup keamanan harus memiliki aturan masuk yang memungkinkan lalu lintas masuk dari alamat IP Anda. Jika Anda menentukan grup keamanan VPC default, aturan masuk default tidak menerima lalu lintas masuk apa pun.
Solusi: Edit aturan masuk grup keamanan untuk menerima lalu lintas masuk dari alamat IP yang sesuai.
-
Klik Grup Keamanan di panel navigasi konsol Amazon EC2
. -
Pilih grup keamanan load balancer.
-
Klik Edit pada tab Inbound.
-
Tambahkan aturan masuk dengan Sumber disetel ke CIDR yang sesuai.
Misalnya, menentukan Anywhere menetapkan CIDR ke 0.0.0.0/0, yang mengarahkan penyeimbang beban untuk menerima lalu lintas masuk dari alamat IP apa pun.
Instance Lokal yang Diimpor Gagal Menyelesaikan Pengaturan Volume Setelah Mulai Ulang
Masalah: Anda memulai ulang instans EC2 yang telah Anda impor ke AWS OpsWorks Stacks, dan tampilan konsol AWS OpsWorks Stacks gagal sebagai status instans. Ini dapat terjadi pada contoh Chef 11 atau Chef 12.
Penyebab:AWS OpsWorks Tumpukan mungkin tidak dapat melampirkan volume ke instans Anda selama proses penyiapan. Salah satu kemungkinan penyebabnya adalah AWS OpsWorks
Stacks menimpa konfigurasi volume Anda pada instance Anda saat Anda menjalankan perintah. setup
Solusi: Buka halaman Detail untuk instance, dan periksa konfigurasi volume Anda di area Volume. Perhatikan bahwa Anda dapat mengubah konfigurasi volume hanya jika instans Anda berada dalam status berhenti. Pastikan bahwa setiap volume memiliki titik pemasangan dan nama yang ditentukan. Konfirmasikan bahwa Anda memberikan titik pemasangan yang benar dalam konfigurasi di AWS OpsWorks Stacks sebelum memulai ulang instance.
Volume EBS Tidak Terpasang Kembali Setelah Reboot
Masalah: Anda menggunakan konsol Amazon EC2 untuk melampirkan volume Amazon EBS ke instans tetapi ketika Anda me-reboot instans, volume tidak lagi terpasang.
Penyebab: AWS OpsWorks Tumpukan hanya dapat memasang kembali volume Amazon EBS yang disadarinya, yang terbatas pada hal-hal berikut:
-
Volume yang dibuat oleh AWS OpsWorks Stacks.
-
Volume dari akun Anda yang telah Anda daftarkan secara eksplisit dengan tumpukan menggunakan halaman Resources.
Solusi: Kelola volume Amazon EBS Anda hanya dengan menggunakan konsol AWS OpsWorks Stacks, API, atau CLI. Jika Anda ingin menggunakan salah satu volume Amazon EBS akun Anda dengan tumpukan, gunakan halaman Sumber Daya tumpukan untuk mendaftarkan volume dan melampirkannya ke sebuah instance. Untuk informasi selengkapnya, lihat Manajemen Sumber Daya.
Tidak Dapat Menghapus AWS OpsWorks Grup Keamanan Stacks
Masalah: Setelah Anda menghapus tumpukan, ada sejumlah grup keamanan AWS OpsWorks Stacks yang tertinggal yang tidak dapat dihapus.
Penyebab: Grup keamanan harus dihapus dalam urutan tertentu.
Solusi: Pertama, pastikan tidak ada instance yang menggunakan grup keamanan. Kemudian, hapus salah satu grup keamanan berikut, jika ada, dengan urutan sebagai berikut:
-
AWS- OpsWorks -Server Kosong
-
AWS- OpsWorks -Monitoring-Master-Server
-
AWS- OpsWorks -DB-Master-Server
-
AWS- OpsWorks -Memcached-Server
-
AWS- OpsWorks -Server Khusus
-
AWS- OpsWorks -NodeJS-App-Server
-
AWS- OpsWorks -PHP-APP-Server
-
AWS- OpsWorks -Rails-App-Server
-
AWS- OpsWorks -Server Web
-
AWS- OpsWorks -Server Default
-
AWS- OpsWorks -LB-Server
Tidak Sengaja Menghapus Grup Keamanan AWS OpsWorks Stacks
Masalah: Anda menghapus salah satu grup keamanan AWS OpsWorks Stacks dan perlu membuatnya kembali.
Penyebab: Grup keamanan ini biasanya dihapus secara tidak sengaja.
Solusi: Grup yang dibuat ulang harus duplikat persis dari aslinya, termasuk kapitalisasi yang sama untuk nama grup. Alih-alih membuat ulang grup secara manual, pendekatan yang lebih disukai adalah meminta AWS OpsWorks Stacks melakukan tugas untuk Anda. Cukup buat tumpukan baru di wilayah AWS yang sama—dan VPC, jika AWS OpsWorks ada—dan Stacks akan secara otomatis membuat ulang semua grup keamanan bawaan, termasuk yang Anda hapus. Anda kemudian dapat menghapus tumpukan jika Anda tidak memiliki penggunaan lebih lanjut untuk itu; grup keamanan akan tetap ada.
Chef Log Berakhir Tiba-tiba
Masalah: Log Chef berakhir secara tiba-tiba; akhir log tidak menunjukkan keberhasilan menjalankan atau menampilkan pengecualian dan jejak tumpukan.
Penyebab: Perilaku ini biasanya disebabkan oleh memori yang tidak memadai.
Solusi: Buat instance yang lebih besar dan gunakan run_command perintah CLI agen untuk menjalankan resep lagi. Untuk informasi selengkapnya, lihat Mengeksekusi Resep.
Cookbook Tidak Diperbarui
Masalah: Anda memperbarui buku masak Anda tetapi instance tumpukan masih menjalankan resep lama.
Penyebab: AWS OpsWorks Tumpukan menyimpan buku masak di setiap instance, dan menjalankan resep dari cache, bukan repositori. Saat Anda memulai instance baru, AWS OpsWorks Stacks mengunduh buku masak Anda dari repositori ke cache instance. Namun, jika Anda kemudian memodifikasi buku masak khusus Anda, AWS OpsWorks Stacks tidak secara otomatis memperbarui cache instans online.
Solusi: Jalankan perintah tumpukan Update Cookbooks untuk secara eksplisit mengarahkan AWS OpsWorks Stacks untuk memperbarui cache buku masak instans online Anda.
Instance Terjebak di Status Booting
Masalah: Ketika Anda me-restart sebuah instance, atau auto healing restart secara otomatis, operasi startup berhenti pada booting status.
Penyebab: Salah satu kemungkinan penyebab masalah ini adalah konfigurasi VPC, termasuk VPC default. Instans harus selalu dapat berkomunikasi dengan layanan AWS OpsWorks Stacks, Amazon S3, dan paket, buku masak, dan repositori aplikasi. Jika, misalnya, Anda menghapus gateway default dari VPC default, instance kehilangan koneksinya ke layanan Stacks. AWS OpsWorks Karena AWS OpsWorks Stacks tidak dapat lagi berkomunikasi dengan agen instance, ia memperlakukan instance sebagai gagal dan menyembuhkannya secara otomatis. Namun, tanpa koneksi, AWS OpsWorks Stacks tidak dapat menginstal agen instance pada instance yang disembuhkan. Tanpa agen, AWS OpsWorks Stacks tidak dapat menjalankan resep Pengaturan pada instance, sehingga operasi startup tidak dapat berkembang melampaui status “booting”.
Solusi: Ubah konfigurasi VPC Anda sehingga instance memiliki konektivitas yang diperlukan.
Instans Secara Tak Terduga Mulai Ulang
Masalah: Instance yang berhenti tiba-tiba dimulai ulang.
Penyebab 1: Jika Anda telah mengaktifkan penyembuhan otomatis untuk instans Anda, AWS OpsWorks Stacks secara berkala melakukan pemeriksaan kesehatan pada instans Amazon EC2 terkait, dan memulai ulang instans yang tidak sehat. Jika Anda menghentikan atau menghentikan instans yang AWS OpsWorks dikelola Stacks dengan menggunakan konsol Amazon EC2, API, atau CLI, Stacks tidak akan diberi tahu. AWS OpsWorks Sebaliknya, ia akan menganggap instance yang dihentikan sebagai tidak sehat dan secara otomatis memulai ulang.
Solusi: Kelola instans Anda hanya dengan menggunakan konsol AWS OpsWorks Stacks, API, atau CLI. Jika Anda menggunakan AWS OpsWorks Stacks untuk menghentikan atau menghapus instance, itu tidak akan dimulai ulang. Untuk informasi selengkapnya, lihat Memulai, Menghentikan, dan Memulai Ulang Instans 24/7 Secara Manual dan Menghapus Instans AWS OpsWorks Stacks.
Penyebab 2: Contoh dapat gagal karena berbagai alasan. Jika Anda mengaktifkan penyembuhan otomatis, AWS OpsWorks Stacks secara otomatis memulai ulang instans yang gagal.
Solusi: Ini adalah operasi normal; tidak perlu melakukan apa pun kecuali Anda tidak ingin AWS OpsWorks Stacks memulai ulang instance yang gagal. Dalam hal ini, Anda harus menonaktifkan penyembuhan otomatis.
opsworks-agentProses Berjalan pada Instance
Masalah: Beberapa opsworks-agent proses berjalan pada instance Anda. Sebagai contoh:
aws 24543 0.0 1.3 172360 53332 ? S Feb24 0:29 opsworks-agent: master 24543 aws 24545 0.1 2.0 208932 79224 ? S Feb24 22:02 opsworks-agent: keep_alive of master 24543 aws 24557 0.0 2.0 209012 79412 ? S Feb24 8:04 opsworks-agent: statistics of master 24543 aws 24559 0.0 2.2 216604 86992 ? S Feb24 4:14 opsworks-agent: process_command of master 24
Penyebab: Ini adalah proses yang sah yang diperlukan untuk operasi normal agen. Mereka melakukan tugas-tugas seperti menangani penerapan dan mengirim pesan keep-alive kembali ke layanan.
Solusi: Ini adalah perilaku normal. Jangan hentikan proses ini; melakukannya akan membahayakan operasi agen.
Perintah execute_recipes yang tidak terduga
Masalah: Bagian Log pada halaman detail instance menyertakan execute_recipes perintah yang tidak terduga. execute_recipesPerintah tak terduga juga dapat muncul di halaman Stack dan Deployments.
Penyebab: Masalah ini sering disebabkan oleh perubahan izin. Saat Anda mengubah izin SSH atau sudo pengguna atau grup, AWS OpsWorks Stacks berjalan execute_recipes untuk memperbarui instance tumpukan dan juga memicu peristiwa Konfigurasi. Sumber execute_recipes perintah lainnya adalah AWS OpsWorks
Stacks memperbarui agen instance.
Solusi: Ini adalah operasi normal; tidak perlu melakukan apa pun.
Untuk melihat tindakan apa yang dilakukan execute_recipes perintah, buka halaman Deployments dan klik stempel waktu perintah. Ini membuka halaman detail perintah, yang mencantumkan resep utama yang dijalankan. Misalnya, halaman detail berikut adalah untuk execute_recipes perintah yang dijalankan ssh_users untuk memperbarui izin SSH.
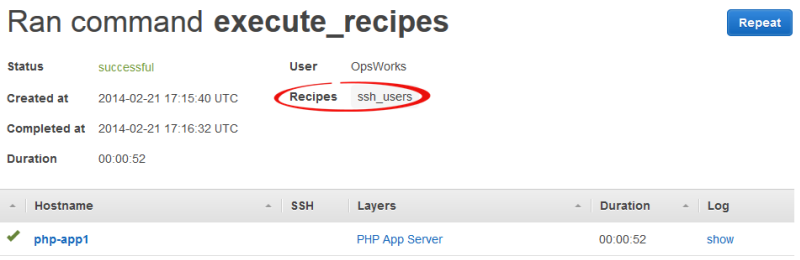
Untuk melihat semua detail, klik tampilkan di kolom Log perintah untuk menampilkan log Chef terkait. Cari log untukRun List. AWS OpsWorks Resep pemeliharaan tumpukan akan berada di bawahOpsWorks Custom Run List. Misalnya, berikut ini adalah daftar run untuk execute_recipes perintah yang ditunjukkan pada tangkapan layar sebelumnya, dan menunjukkan setiap resep yang terkait dengan perintah.
[2014-02-21T17:16:30+00:00] INFO: OpsWorks Custom Run List: ["opsworks_stack_state_sync", "ssh_users", "test_suite", "opsworks_cleanup"]
