Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
AWS ParallelClusterproses
Bagian ini hanya berlaku untuk klaster HPC yang digunakan dengan salah satu penjadwal pekerjaan tradisional yang didukung (SGE,, atau). Slurm Torque Ketika digunakan dengan penjadwal ini, AWS ParallelCluster mengelola penyediaan dan penghapusan node komputasi dengan berinteraksi dengan grup Auto Scaling dan penjadwal pekerjaan yang mendasarinya.
Untuk klaster HPC yang didasarkan padaAWS Batch, AWS ParallelCluster bergantung pada kemampuan yang disediakan oleh AWS Batch untuk manajemen node komputasi.
catatan
Dimulai dengan versi 2.11.5, AWS ParallelCluster tidak mendukung penggunaan SGE atau Torque penjadwal. Anda dapat terus menggunakannya dalam versi hingga dan termasuk 2.11.4, tetapi mereka tidak memenuhi syarat untuk pembaruan di masa mendatang atau dukungan pemecahan masalah dari tim AWS Layanan dan AWS Dukungan.
SGE and Torque integration processes
catatan
Bagian ini hanya berlaku untuk AWS ParallelCluster versi hingga dan termasuk versi 2.11.4. Dimulai dengan versi 2.11.5, AWS ParallelCluster tidak mendukung penggunaan SGE dan Torque penjadwal, Amazon SNS, dan Amazon SQS.
Ikhtisar umum
Siklus hidup klaster dimulai setelah dibuat oleh pengguna. Biasanya, cluster dibuat dari Command Line Interface (CLI). Setelah dibuat, klaster ada sampai dihapus. AWS ParallelClusterdaemon berjalan pada node cluster, terutama untuk mengelola elastisitas cluster HPC. Diagram berikut menunjukkan alur kerja pengguna dan siklus hidup cluster. Bagian yang mengikuti menggambarkan AWS ParallelCluster daemon yang digunakan untuk mengelola klaster.
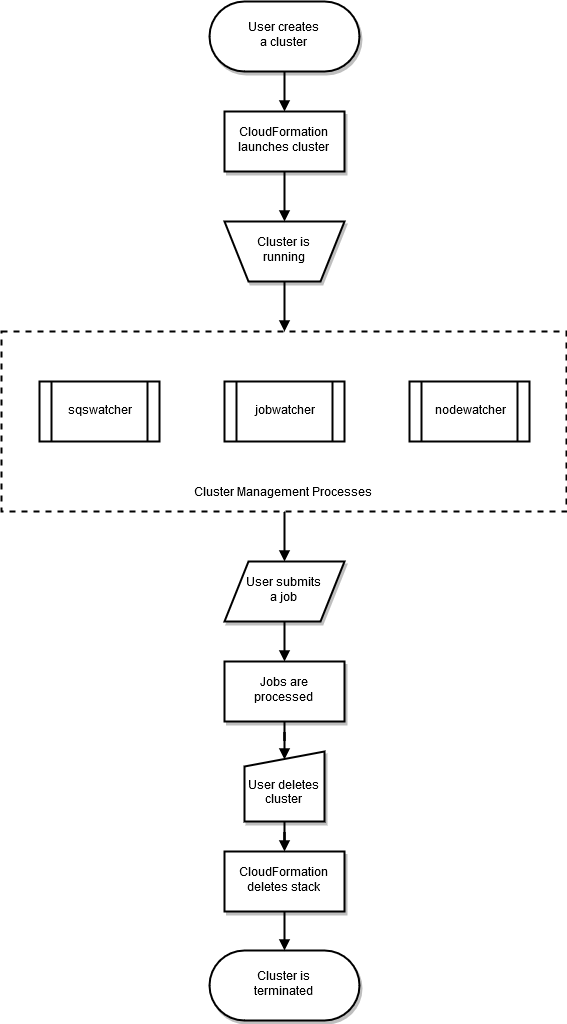
Dengan SGE dan Torque penjadwal, AWS ParallelCluster penggunaan, nodewatcherjobwatcher, dan sqswatcher proses.
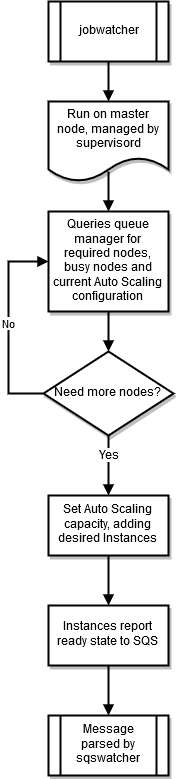
jobwatcher
Ketika cluster berjalan, proses yang dimiliki oleh pengguna root memonitor scheduler dikonfigurasi (SGEatauTorque). Setiap menit itu mengevaluasi antrian untuk memutuskan kapan untuk meningkatkan skala.
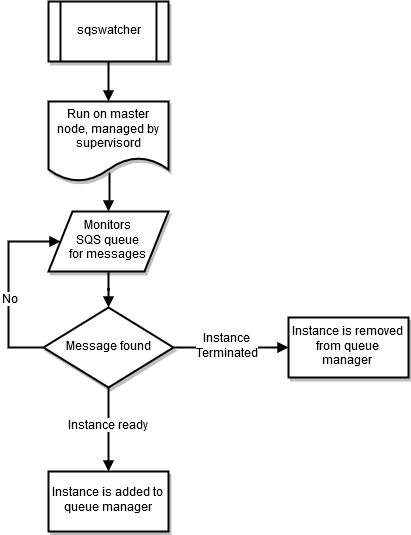
sqswatcher
sqswatcherProses memantau pesan Amazon SQS yang dikirim oleh Auto Scaling untuk memberi tahu Anda tentang perubahan status dalam klaster. Ketika instans online, instans mengirimkan pesan “siap instans” ke Amazon SQS. Pesan ini diambil olehsqs_watcher, berjalan pada node kepala. Pesan ini digunakan untuk memberi tahu pengelola antrian saat instans baru online atau dihentikan, sehingga dapat ditambahkan atau dihapus dari antrean.
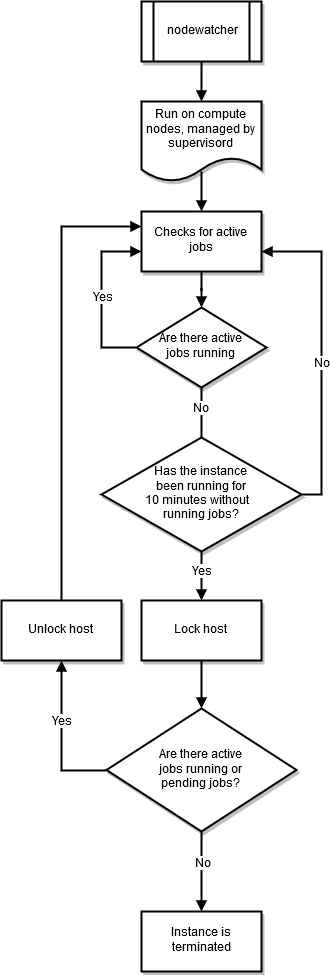
nodewatcher
nodewatcherProses berjalan pada setiap node dalam armada komputasi. Setelah scaledown_idletime periode, seperti yang didefinisikan oleh pengguna, instance dihentikan.
Slurm integration processes
Dengan Slurm penjadwal, AWS ParallelCluster penggunaan clustermgtd dan computemgt proses.
clustermgtd
Cluster yang berjalan dalam mode heterogen (ditunjukkan dengan menentukan queue_settings nilai) memiliki proses daemon manajemen cluster (clustermgtd) yang berjalan pada node kepala. Tugas-tugas ini dilakukan oleh daemon manajemen cluster.
-
Pembersihan partisi tidak aktif
-
Manajemen kapasitas statis: pastikan kapasitas statis selalu naik dan sehat
-
Sinkronkan penjadwal dengan Amazon EC2.
-
Pembersihan contoh yatim piatu
-
Memulihkan status node penjadwal pada penghentian Amazon EC2 yang terjadi di luar alur kerja penangguhan
-
Manajemen instans Amazon EC2 yang tidak sehat (gagal dalam pemeriksaan kesehatan Amazon EC2)
-
Manajemen acara pemeliharaan terjadwal
-
Manajemen node Penjadwal Tidak Sehat (gagal pemeriksaan kesehatan Scheduler)
computemgtd
Cluster yang berjalan dalam mode heterogen (ditunjukkan dengan menentukan queue_settings nilai) memiliki proses daemon manajemen komputasi (computemgtd) yang berjalan pada masing-masing node komputasi. Setiap lima (5) menit, daemon manajemen komputasi menegaskan bahwa simpul kepala dapat dicapai dan sehat. Jika lima (5) menit berlalu selama node kepala tidak dapat dicapai atau tidak sehat, node komputasi dimatikan.
