Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Optimalkan fungsi yang ditentukan pengguna
Fungsi yang ditentukan pengguna (UDFs) dan PySpark sering menurunkan RDD.map kinerja secara signifikan. Ini karena overhead yang diperlukan untuk secara akurat mewakili kode Python Anda dalam implementasi Scala yang mendasari Spark.
Diagram berikut menunjukkan arsitektur PySpark pekerjaan. Saat Anda menggunakan PySpark, driver Spark menggunakan pustaka Py4j untuk memanggil metode Java dari Python. Saat memanggil Spark SQL atau fungsi DataFrame bawaan, ada sedikit perbedaan kinerja antara Python dan Scala karena fungsi berjalan pada setiap pelaksana menggunakan rencana eksekusi yang JVM dioptimalkan.
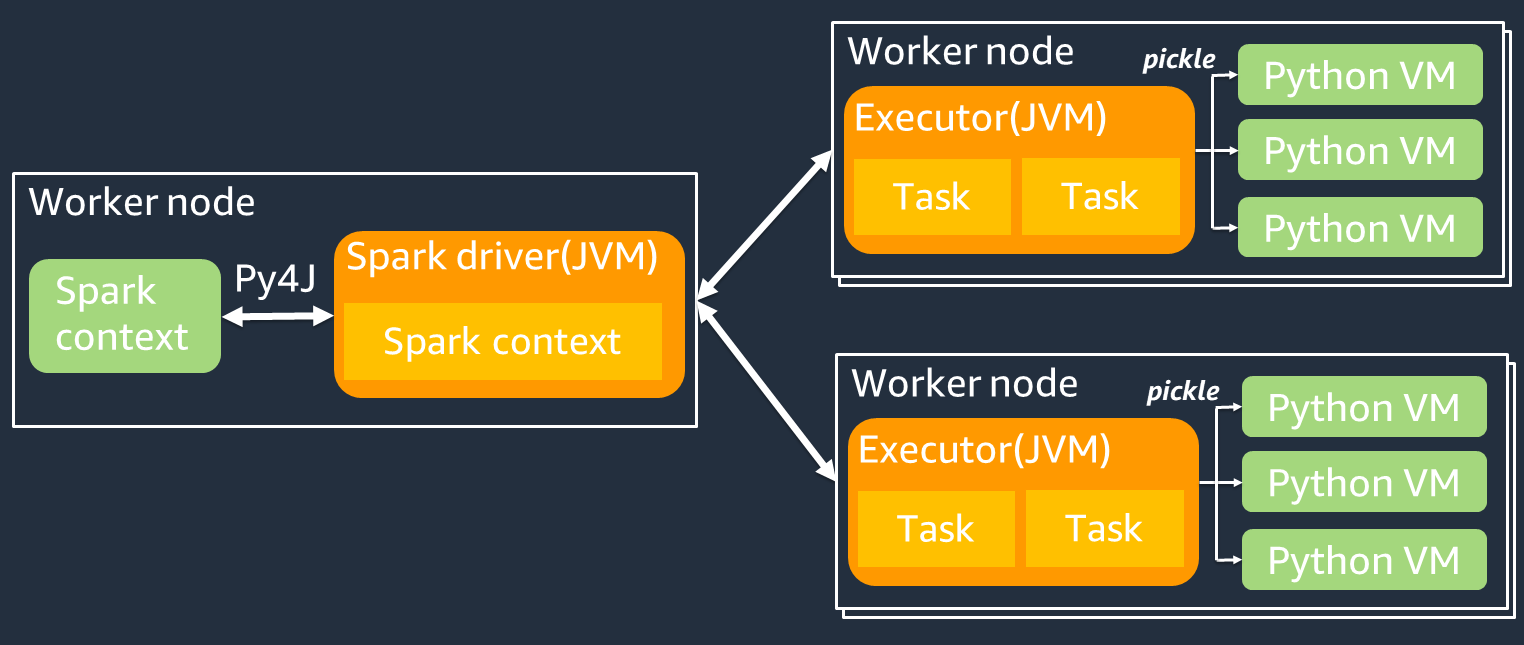
Jika Anda menggunakan logika Python Anda sendiri, seperti menggunakanmap/ mapPartitions/ udf, tugas akan berjalan di lingkungan runtime Python. Mengelola dua lingkungan menciptakan biaya overhead. Selain itu, data Anda dalam memori harus diubah untuk digunakan oleh fungsi bawaan lingkungan JVM runtime. Pickle adalah format serialisasi yang digunakan secara default untuk pertukaran antara runtime dan JVM Python. Namun, biaya serialisasi dan biaya deserialisasi ini sangat tinggi, sehingga UDFs ditulis dalam Java atau Scala lebih cepat daripada Python. UDFs
Untuk menghindari overhead serialisasi dan deserialisasi PySpark, pertimbangkan hal berikut:
-
Gunakan fungsi Spark bawaan - Pertimbangkan untuk mengganti SQL fungsi Anda sendiri UDF atau peta dengan Spark SQL atau fungsi DataFrame bawaan. Saat menjalankan Spark SQL atau fungsi DataFrame bawaan, ada sedikit perbedaan kinerja antara Python dan Scala karena tugas ditangani pada masing-masing pelaksana. JVM
-
Implementasikan UDFs di Scala atau Java - Pertimbangkan untuk menggunakan UDF yang ditulis dalam Java atau Scala, karena mereka berjalan di. JVM
-
Gunakan Apache Arrow berbasis UDFs untuk beban kerja vektor — Pertimbangkan untuk menggunakan berbasis Arrow. UDFs Fitur ini juga dikenal sebagai Vectorized UDF (Pandas). UDF Apache Arrow
adalah format data dalam memori bahasa agnostik yang AWS Glue dapat digunakan untuk mentransfer data secara efisien antara dan proses Python. JVM Ini saat ini paling bermanfaat bagi pengguna Python yang bekerja dengan Panda atau data. NumPy Panah adalah format kolumnar (vektor). Penggunaannya tidak otomatis dan mungkin memerlukan beberapa perubahan kecil pada konfigurasi atau kode untuk memanfaatkan sepenuhnya dan memastikan kompatibilitas. Untuk detail dan keterbatasan lebih lanjut, lihat Apache Arrow di PySpark
. Contoh berikut membandingkan inkremental dasar UDF dalam Python standar, sebagai VektorUDF, dan di Spark. SQL
Python Standar UDF
Contoh waktu adalah 3,20 (detik).
Contoh kode
# DataSet df = spark.range(10000000).selectExpr("id AS a","id AS b") # UDF Example def plus(a,b): return a+b spark.udf.register("plus",plus) df.selectExpr("count(plus(a,b))").collect()
Rencana eksekusi
== Physical Plan == AdaptiveSparkPlan isFinalPlan=false +- HashAggregate(keys=[], functions=[count(pythonUDF0#124)]) +- Exchange SinglePartition, ENSURE_REQUIREMENTS, [id=#580] +- HashAggregate(keys=[], functions=[partial_count(pythonUDF0#124)]) +- Project [pythonUDF0#124] +- BatchEvalPython [plus(a#116L, b#117L)], [pythonUDF0#124] +- Project [id#114L AS a#116L, id#114L AS b#117L] +- Range (0, 10000000, step=1, splits=16)
Divektorkan UDF
Contoh waktu adalah 0,59 (detik).
Vektor UDF 5 kali lebih cepat dari contoh sebelumnya. UDF MemeriksaPhysical Plan, Anda dapat melihatArrowEvalPython, yang menunjukkan aplikasi ini di-vektor oleh Apache Arrow. Untuk mengaktifkan VectorizedUDF, Anda harus menentukan spark.sql.execution.arrow.pyspark.enabled = true dalam kode Anda.
Contoh kode
# Vectorized UDF from pyspark.sql.types import LongType from pyspark.sql.functions import count, pandas_udf # Enable Apache Arrow Support spark.conf.set("spark.sql.execution.arrow.pyspark.enabled", "true") # DataSet df = spark.range(10000000).selectExpr("id AS a","id AS b") # Annotate pandas_udf to use Vectorized UDF @pandas_udf(LongType()) def pandas_plus(a,b): return a+b spark.udf.register("pandas_plus",pandas_plus) df.selectExpr("count(pandas_plus(a,b))").collect()
Rencana eksekusi
== Physical Plan == AdaptiveSparkPlan isFinalPlan=false +- HashAggregate(keys=[], functions=[count(pythonUDF0#1082L)], output=[count(pandas_plus(a, b))#1080L]) +- Exchange SinglePartition, ENSURE_REQUIREMENTS, [id=#5985] +- HashAggregate(keys=[], functions=[partial_count(pythonUDF0#1082L)], output=[count#1084L]) +- Project [pythonUDF0#1082L] +- ArrowEvalPython [pandas_plus(a#1074L, b#1075L)], [pythonUDF0#1082L], 200 +- Project [id#1072L AS a#1074L, id#1072L AS b#1075L] +- Range (0, 10000000, step=1, splits=16)
Percikan SQL
Contoh waktu adalah 0,087 (detik).
Spark jauh SQL lebih cepat daripada VectorizedUDF, karena tugas dijalankan pada setiap eksekutor tanpa JVM runtime Python. Jika Anda dapat mengganti fungsi Anda UDF dengan fungsi bawaan, kami sarankan untuk melakukannya.
Contoh kode
df.createOrReplaceTempView("test") spark.sql("select count(a+b) from test").collect()
Menggunakan panda untuk data besar
Jika Anda sudah terbiasa dengan panda
