Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Kapasitas klaster skala
Jika pekerjaan Anda memakan terlalu banyak waktu, tetapi pelaksana menghabiskan sumber daya yang cukup dan Spark membuat sejumlah besar tugas relatif terhadap inti yang tersedia, pertimbangkan untuk menskalakan kapasitas cluster. Untuk menilai apakah ini sesuai, gunakan metrik berikut.
CloudWatch metrik
-
Periksa Pemanfaatan CPUBeban dan Memori untuk menentukan apakah pelaksana mengkonsumsi sumber daya yang cukup.
-
Periksa berapa lama pekerjaan telah berjalan untuk menilai apakah waktu pemrosesan terlalu lama untuk memenuhi tujuan kinerja Anda.
Dalam contoh berikut, empat pelaksana berjalan pada CPU beban lebih dari 97 persen, tetapi pemrosesan belum selesai setelah sekitar tiga jam.

catatan
Jika CPU beban rendah, Anda mungkin tidak akan mendapat manfaat dari penskalaan kapasitas cluster.
Spark UI
Pada tab Job atau tab Stage, Anda dapat melihat jumlah tugas untuk setiap pekerjaan atau tahap. Dalam contoh berikut, Spark telah membuat 58100 tugas.

Pada tab Executor, Anda dapat melihat jumlah total pelaksana dan tugas. Pada tangkapan layar berikut, setiap pelaksana Spark memiliki empat inti dan dapat melakukan empat tugas secara bersamaan.
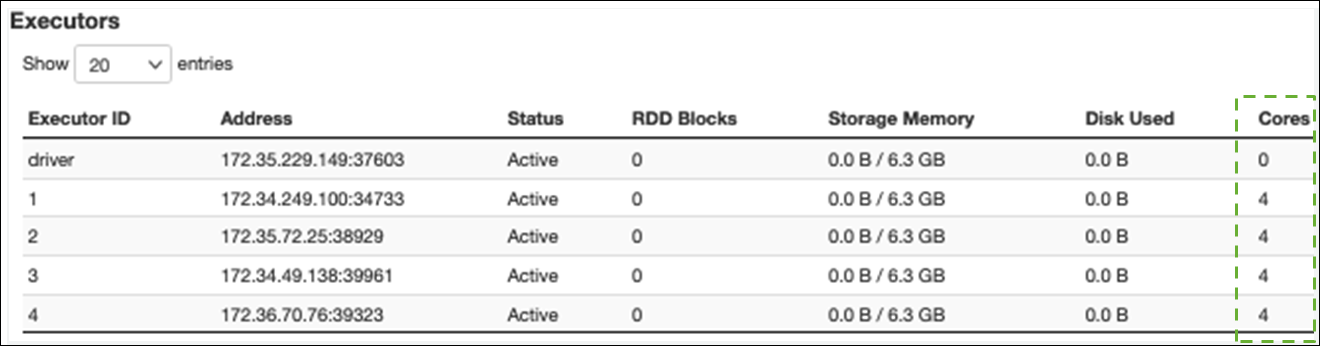
Dalam contoh ini, jumlah tugas Spark (jauh 58100) lebih besar daripada 16 tugas yang dapat diproses oleh pelaksana secara bersamaan (4 pelaksana × 4 core).
Jika Anda mengamati gejala-gejala ini, pertimbangkan untuk menskalakan cluster. Anda dapat menskalakan kapasitas cluster dengan menggunakan opsi berikut:
-
Aktifkan AWS Glue Auto Scaling — Auto Scaling tersedia untuk mengekstrak, mengubah, dan memuat ETL () dan pekerjaan streaming AWS Glue Anda AWS Glue di versi 3.0 atau yang lebih baru. AWS Glue secara otomatis menambahkan dan menghapus pekerja dari cluster tergantung pada jumlah partisi pada setiap tahap atau tingkat di mana microbatch dihasilkan pada pekerjaan yang dijalankan.
Jika Anda mengamati situasi di mana jumlah pekerja tidak bertambah meskipun Auto Scaling diaktifkan, pertimbangkan untuk menambahkan pekerja secara manual. Namun, perhatikan bahwa penskalaan secara manual untuk satu tahap dapat menyebabkan banyak pekerja menganggur selama tahap selanjutnya, dengan biaya lebih untuk nol perolehan kinerja.
Setelah mengaktifkan Auto Scaling, Anda dapat melihat jumlah pelaksana dalam metrik pelaksana. CloudWatch Gunakan metrik berikut untuk memantau permintaan pelaksana dalam aplikasi Spark:
-
glue.driver.ExecutorAllocationManager.executors.numberAllExecutors -
glue.driver.ExecutorAllocationManager.executors.numberMaxNeededExecutors
Untuk informasi selengkapnya tentang metrik, lihat Memantau AWS Glue menggunakan CloudWatch metrik Amazon.
-
-
Skalakan: Tingkatkan jumlah AWS Glue pekerja - Anda dapat meningkatkan jumlah AWS Glue pekerja secara manual. Tambahkan pekerja hanya sampai Anda mengamati pekerja yang menganggur. Pada saat itu, menambahkan lebih banyak pekerja akan meningkatkan biaya tanpa meningkatkan hasil. Untuk informasi selengkapnya, lihat Parallelize task.
-
Tingkatkan: Gunakan tipe pekerja yang lebih besar — Anda dapat secara manual mengubah jenis instans AWS Glue pekerja Anda untuk menggunakan pekerja dengan lebih banyak inti, memori, dan penyimpanan. Jenis pekerja yang lebih besar memungkinkan Anda untuk menskalakan secara vertikal dan menjalankan pekerjaan integrasi data intensif, seperti transformasi data intensif memori, agregasi miring, dan pemeriksaan deteksi entitas yang melibatkan petabyte data.
Peningkatan skala juga membantu dalam kasus di mana driver Spark membutuhkan kapasitas yang lebih besar — misalnya, karena rencana permintaan pekerjaan cukup besar. Untuk informasi selengkapnya tentang jenis dan kinerja pekerja, lihat postingan AWS Big Data Blog Scale your AWS Glue for Apache Spark jobs dengan tipe pekerja baru yang lebih besar G.4X dan G.8X
. Menggunakan pekerja yang lebih besar juga dapat mengurangi jumlah total pekerja yang dibutuhkan, yang meningkatkan kinerja dengan mengurangi shuffle dalam operasi intensif seperti bergabung.
