Amazon Redshift tidak akan lagi mendukung pembuatan UDF Python baru mulai Patch 198. UDF Python yang ada akan terus berfungsi hingga 30 Juni 2026. Untuk informasi lebih lanjut, lihat posting blog
Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Tutorial: Memuat data dari Amazon S3
Dalam tutorial ini, Anda berjalan melalui proses memuat data ke dalam tabel database Amazon Redshift Anda dari file data dalam bucket Amazon S3 dari awal hingga akhir.
Dalam tutorial ini, Anda akan melakukan hal-hal berikut:
-
Unduh file data yang menggunakan nilai dipisahkan koma (CSV), dibatasi karakter, dan format lebar tetap.
-
Buat bucket Amazon S3 lalu unggah file data ke bucket.
-
Luncurkan cluster Amazon Redshift dan buat tabel database.
-
Gunakan perintah COPY untuk memuat tabel dari file data di Amazon S3.
-
Memecahkan masalah kesalahan pemuatan dan memodifikasi perintah COPY Anda untuk memperbaiki kesalahan.
Prasyarat
Anda membutuhkan prasyarat berikut:
-
AWS Akun untuk meluncurkan cluster Amazon Redshift dan membuat ember di Amazon S3.
-
AWS Kredensi Anda (peran IAM) untuk memuat data pengujian dari Amazon S3. Jika Anda membutuhkan peran IAM baru, buka Membuat peran IAM.
-
Klien SQL seperti editor kueri konsol Amazon Redshift.
Tutorial ini dirancang sedemikian rupa sehingga dapat diambil dengan sendirinya. Selain tutorial ini, kami sarankan untuk menyelesaikan tutorial berikut untuk mendapatkan pemahaman yang lebih lengkap tentang cara merancang dan menggunakan database Amazon Redshift:
-
Panduan Memulai Amazon Redshift memandu Anda melalui proses pembuatan klaster Amazon Redshift dan memuat data sampel.
Ikhtisar
Anda dapat menambahkan data ke tabel Amazon Redshift baik dengan menggunakan perintah INSERT atau dengan menggunakan perintah COPY. Pada skala dan kecepatan gudang data Amazon Redshift, perintah COPY berkali-kali lebih cepat dan lebih efisien daripada perintah INSERT.
Perintah COPY menggunakan arsitektur Amazon Redshift massively parallel processing (MPP) untuk membaca dan memuat data secara paralel dari berbagai sumber data. Anda dapat memuat dari file data di Amazon S3, Amazon EMR, atau host jarak jauh apa pun yang dapat diakses melalui koneksi Secure Shell (SSH). Atau Anda dapat memuat langsung dari tabel Amazon DynamoDB.
Dalam tutorial ini, Anda menggunakan perintah COPY untuk memuat data dari Amazon S3. Banyak prinsip yang disajikan di sini berlaku untuk pemuatan dari sumber data lain juga.
Untuk mempelajari lebih lanjut tentang menggunakan perintah COPY, lihat sumber daya ini:
Langkah 1: Buat cluster
Jika Anda sudah memiliki cluster yang ingin Anda gunakan, Anda dapat melewati langkah ini.
Untuk latihan dalam tutorial ini, gunakan cluster empat simpul.
Untuk membuat klaster DB
-
Masuk ke AWS Management Console dan buka konsol Amazon Redshift di. https://console.aws.amazon.com/redshiftv2/
Menggunakan menu navigasi, pilih dasbor Cluster yang disediakan.
penting
Pastikan Anda memiliki izin yang diperlukan untuk melakukan operasi cluster. Untuk informasi tentang pemberian izin yang diperlukan, lihat Mengotorisasi Amazon Redshift untuk mengakses layanan. AWS
-
Di kanan atas, pilih AWS Wilayah tempat Anda ingin membuat cluster. Untuk keperluan tutorial ini, pilih US West (Oregon).
-
Pada menu navigasi, pilih Clusters, lalu pilih Create cluster. Halaman Create cluster muncul.
-
Pada halaman Create cluster masukkan parameter untuk cluster Anda. Pilih nilai Anda sendiri untuk parameter, kecuali ubah nilai berikut:
Pilih
dc2.largeuntuk jenis node.Pilih
4untuk Jumlah node.Di bagian izin Cluster, pilih peran IAM dari peran IAM yang Tersedia. Peran ini harus menjadi salah satu yang Anda buat sebelumnya dan yang memiliki akses ke Amazon S3. Kemudian pilih peran IAM Associate untuk menambahkannya ke daftar peran IAM Terkait untuk cluster.
-
Pilih Buat klaster.
Ikuti langkah-langkah Panduan Memulai Amazon Redshift untuk menyambung ke klaster Anda dari klien SQL dan menguji koneksi. Anda tidak perlu menyelesaikan langkah-langkah Memulai yang tersisa untuk membuat tabel, mengunggah data, dan mencoba contoh kueri.
Langkah 2: Unduh file data
Pada langkah ini, Anda mengunduh satu set file data sampel ke komputer Anda. Pada langkah berikutnya, Anda mengunggah file ke bucket Amazon S3.
Untuk mengunduh file data
-
Unduh file zip: LoadingDataSampleFiles.zip.
-
Ekstrak file ke folder di komputer Anda.
-
Verifikasi bahwa folder Anda berisi file-file berikut.
customer-fw-manifest customer-fw.tbl-000 customer-fw.tbl-000.bak customer-fw.tbl-001 customer-fw.tbl-002 customer-fw.tbl-003 customer-fw.tbl-004 customer-fw.tbl-005 customer-fw.tbl-006 customer-fw.tbl-007 customer-fw.tbl.log dwdate-tab.tbl-000 dwdate-tab.tbl-001 dwdate-tab.tbl-002 dwdate-tab.tbl-003 dwdate-tab.tbl-004 dwdate-tab.tbl-005 dwdate-tab.tbl-006 dwdate-tab.tbl-007 part-csv.tbl-000 part-csv.tbl-001 part-csv.tbl-002 part-csv.tbl-003 part-csv.tbl-004 part-csv.tbl-005 part-csv.tbl-006 part-csv.tbl-007
Langkah 3: Unggah file ke bucket Amazon S3
Pada langkah ini, Anda membuat bucket Amazon S3 dan mengunggah file data ke bucket.
Untuk mengunggah file ke bucket Amazon S3
-
Buat ember di Amazon S3.
Untuk informasi selengkapnya tentang membuat bucket, lihat Membuat bucket di Panduan Pengguna Layanan Penyimpanan Sederhana Amazon.
-
Masuk ke AWS Management Console dan buka konsol Amazon S3 di. https://console.aws.amazon.com/s3/
-
Pilih Buat bucket.
-
Pilih sebuah Wilayah AWS.
Buat bucket di Region yang sama dengan cluster Anda. Jika cluster Anda berada di Wilayah AS Barat (Oregon), pilih Wilayah AS Barat (Oregon) (us-west-2).
-
Di kotak Nama Bucket pada kotak dialog Buat ember, masukkan nama bucket.
Nama bucket yang Anda pilih harus unik di antara semua nama bucket yang ada di Amazon S3. Salah satu cara untuk membantu memastikan keunikan adalah dengan mengawali nama bucket Anda dengan nama organisasi Anda. Nama bucket harus mematuhi aturan tertentu. Untuk informasi selengkapnya, buka Pembatasan dan batasan Bucket di Panduan Pengguna Layanan Penyimpanan Sederhana Amazon.
-
Pilih default yang disarankan untuk opsi lainnya.
-
Pilih Buat bucket.
Saat Amazon S3 berhasil membuat bucket Anda, konsol akan menampilkan bucket kosong Anda di panel Bucket.
-
-
Buat folder.
-
Pilih nama ember baru.
-
Pilih tombol Buat Folder.
-
Beri nama folder baru
load.catatan
Ember yang Anda buat tidak ada di kotak pasir. Dalam latihan ini, Anda menambahkan objek ke ember sungguhan. Anda dikenakan jumlah nominal untuk waktu Anda menyimpan benda-benda di ember. Untuk informasi lebih lanjut tentang harga Amazon S3, buka halaman harga Amazon S3
.
-
-
Unggah file data ke bucket Amazon S3 baru.
-
Pilih nama folder data.
-
Di wizard Unggah, pilih Tambahkan file.
Ikuti petunjuk konsol Amazon S3 untuk mengunggah semua file yang Anda unduh dan ekstrak,
-
Pilih Unggah.
-
Kredensial Pengguna
Perintah Amazon Redshift COPY harus memiliki akses untuk membaca objek file di bucket Amazon S3. Jika Anda menggunakan kredensi pengguna yang sama untuk membuat bucket Amazon S3 dan menjalankan perintah Amazon Redshift COPY, perintah COPY memiliki semua izin yang diperlukan. Jika Anda ingin menggunakan kredensil pengguna yang berbeda, Anda dapat memberikan akses dengan menggunakan kontrol akses Amazon S3. Perintah Amazon Redshift COPY memerlukan setidaknya ListBucket dan GetObject izin untuk mengakses objek file di bucket Amazon S3. Untuk informasi selengkapnya tentang mengontrol akses ke sumber daya Amazon S3, buka Mengelola izin akses ke sumber daya Amazon S3 Anda.
Langkah 4: Buat tabel sampel
Untuk tutorial ini, Anda menggunakan satu set tabel berdasarkan skema Star Schema Benchmark (SSB). Diagram berikut menunjukkan model data SSB.
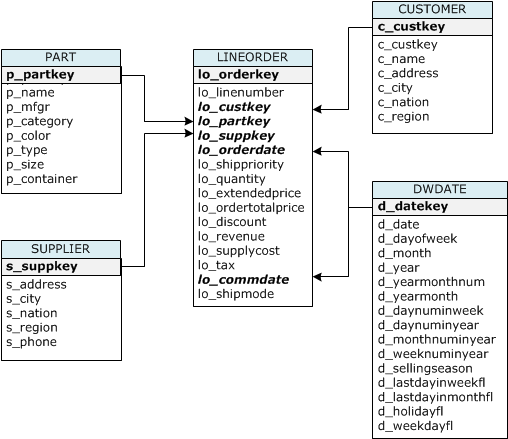
Tabel SSB mungkin sudah ada di database saat ini. Jika demikian, jatuhkan tabel untuk menghapusnya dari database sebelum Anda membuatnya menggunakan perintah CREATE TABLE di langkah berikutnya. Tabel yang digunakan dalam tutorial ini mungkin memiliki atribut yang berbeda dari tabel yang ada.
Untuk membuat tabel sampel
-
Untuk menjatuhkan tabel SSB, jalankan perintah berikut di klien SQL Anda.
drop table part cascade; drop table supplier; drop table customer; drop table dwdate; drop table lineorder; -
Jalankan perintah CREATE TABLE berikut di klien SQL Anda.
CREATE TABLE part ( p_partkey INTEGER NOT NULL, p_name VARCHAR(22) NOT NULL, p_mfgr VARCHAR(6), p_category VARCHAR(7) NOT NULL, p_brand1 VARCHAR(9) NOT NULL, p_color VARCHAR(11) NOT NULL, p_type VARCHAR(25) NOT NULL, p_size INTEGER NOT NULL, p_container VARCHAR(10) NOT NULL ); CREATE TABLE supplier ( s_suppkey INTEGER NOT NULL, s_name VARCHAR(25) NOT NULL, s_address VARCHAR(25) NOT NULL, s_city VARCHAR(10) NOT NULL, s_nation VARCHAR(15) NOT NULL, s_region VARCHAR(12) NOT NULL, s_phone VARCHAR(15) NOT NULL ); CREATE TABLE customer ( c_custkey INTEGER NOT NULL, c_name VARCHAR(25) NOT NULL, c_address VARCHAR(25) NOT NULL, c_city VARCHAR(10) NOT NULL, c_nation VARCHAR(15) NOT NULL, c_region VARCHAR(12) NOT NULL, c_phone VARCHAR(15) NOT NULL, c_mktsegment VARCHAR(10) NOT NULL ); CREATE TABLE dwdate ( d_datekey INTEGER NOT NULL, d_date VARCHAR(19) NOT NULL, d_dayofweek VARCHAR(10) NOT NULL, d_month VARCHAR(10) NOT NULL, d_year INTEGER NOT NULL, d_yearmonthnum INTEGER NOT NULL, d_yearmonth VARCHAR(8) NOT NULL, d_daynuminweek INTEGER NOT NULL, d_daynuminmonth INTEGER NOT NULL, d_daynuminyear INTEGER NOT NULL, d_monthnuminyear INTEGER NOT NULL, d_weeknuminyear INTEGER NOT NULL, d_sellingseason VARCHAR(13) NOT NULL, d_lastdayinweekfl VARCHAR(1) NOT NULL, d_lastdayinmonthfl VARCHAR(1) NOT NULL, d_holidayfl VARCHAR(1) NOT NULL, d_weekdayfl VARCHAR(1) NOT NULL ); CREATE TABLE lineorder ( lo_orderkey INTEGER NOT NULL, lo_linenumber INTEGER NOT NULL, lo_custkey INTEGER NOT NULL, lo_partkey INTEGER NOT NULL, lo_suppkey INTEGER NOT NULL, lo_orderdate INTEGER NOT NULL, lo_orderpriority VARCHAR(15) NOT NULL, lo_shippriority VARCHAR(1) NOT NULL, lo_quantity INTEGER NOT NULL, lo_extendedprice INTEGER NOT NULL, lo_ordertotalprice INTEGER NOT NULL, lo_discount INTEGER NOT NULL, lo_revenue INTEGER NOT NULL, lo_supplycost INTEGER NOT NULL, lo_tax INTEGER NOT NULL, lo_commitdate INTEGER NOT NULL, lo_shipmode VARCHAR(10) NOT NULL );
Langkah 5: Jalankan perintah COPY
Anda menjalankan perintah COPY untuk memuat setiap tabel dalam skema SSB. Contoh perintah COPY menunjukkan pemuatan dari format file yang berbeda, menggunakan beberapa opsi perintah COPY, dan pemecahan masalah kesalahan pemuatan.
COPY sintaks perintah
Sintaks MENYONTEK perintah dasar adalah sebagai berikut.
COPY table_name [ column_list ] FROM data_source CREDENTIALS access_credentials [options]
Untuk menjalankan perintah COPY, Anda memberikan nilai-nilai berikut.
Nama tabel
Tabel target untuk perintah COPY. Tabel harus sudah ada dalam basis data. Tabel bisa bersifat sementara atau persisten. Perintah COPY menambahkan data input baru ke setiap baris yang ada dalam tabel.
Daftar kolom
Secara default, COPY memuat bidang dari data sumber ke kolom tabel secara berurutan. Anda dapat secara opsional menentukan daftar kolom, yaitu daftar nama kolom yang dipisahkan koma, untuk memetakan bidang data ke kolom tertentu. Anda tidak menggunakan daftar kolom dalam tutorial ini. Untuk informasi selengkapnya, lihat Column List di referensi perintah COPY.
Sumber data
Anda dapat menggunakan perintah COPY untuk memuat data dari bucket Amazon S3, cluster EMR Amazon, host jarak jauh menggunakan koneksi SSH, atau tabel Amazon DynamoDB. Untuk tutorial ini, Anda memuat dari file data di bucket Amazon S3. Saat memuat dari Amazon S3, Anda harus memberikan nama bucket dan lokasi file data. Untuk melakukan ini, berikan jalur objek untuk file data atau lokasi file manifes yang secara eksplisit mencantumkan setiap file data dan lokasinya.
-
Awalan kunci
Objek yang disimpan di Amazon S3 diidentifikasi secara unik oleh kunci objek, yang mencakup nama bucket, nama folder, jika ada, dan nama objek. Sebuah key prefix mengacu pada satu set objek dengan awalan yang sama. Object path adalah key prefix yang digunakan perintah COPY untuk memuat semua objek yang berbagi key prefix. Misalnya, key prefix
custdata.txtdapat merujuk ke satu file atau ke satu set file, termasuk,custdata.txt.001custdata.txt.002, dan sebagainya. -
File manifes
Dalam beberapa kasus, Anda mungkin perlu memuat file dengan awalan yang berbeda, misalnya dari beberapa bucket atau folder. Di tempat lain, Anda mungkin perlu mengecualikan file yang berbagi awalan. Dalam kasus ini, Anda dapat menggunakan file manifes. File manifes secara eksplisit mencantumkan setiap file pemuatan dan kunci objek uniknya. Anda menggunakan file manifes untuk memuat tabel PART nanti dalam tutorial ini.
Kredensial
Untuk mengakses AWS sumber daya yang berisi data yang akan dimuat, Anda harus memberikan kredensi AWS akses bagi pengguna dengan hak istimewa yang memadai. Kredensi ini mencakup peran IAM Amazon Resource Name (ARN). Untuk memuat data dari Amazon S3, kredensi harus menyertakan dan izin. ListBucket GetObject Kredensi tambahan diperlukan jika data Anda dienkripsi. Untuk informasi selengkapnya, lihat Parameter otorisasi di referensi perintah COPY. Untuk informasi selengkapnya tentang mengelola akses, buka Mengelola izin akses ke sumber daya Amazon S3 Anda.
Pilihan
Anda dapat menentukan sejumlah parameter dengan perintah COPY untuk menentukan format file, mengelola format data, mengelola kesalahan, dan mengontrol fitur lainnya. Dalam tutorial ini, Anda menggunakan opsi dan fitur perintah COPY berikut:
-
Awalan kunci
Untuk informasi tentang cara memuat dari beberapa file dengan menentukan key prefix, lihat. Muat tabel PART menggunakan NULL AS
-
Format CSV
Untuk informasi tentang cara memuat data dalam format CSV, lihatMuat tabel PART menggunakan NULL AS.
-
NULL SEBAGAI
Untuk informasi tentang cara memuat PART menggunakan opsi NULL AS, lihatMuat tabel PART menggunakan NULL AS.
-
Character-delimited format
Untuk informasi tentang cara menggunakan opsi DELIMITER, lihat. Opsi DELIMITER dan REGION
-
DAERAH
Untuk informasi tentang cara menggunakan opsi REGION, lihatOpsi DELIMITER dan REGION.
-
Fixed-format lebar
Untuk informasi tentang cara memuat tabel PELANGGAN dari data dengan lebar tetap, lihat. Muat tabel PELANGGAN menggunakan MANIFEST
-
MAXERROR
Untuk informasi tentang cara menggunakan opsi MAXERROR, lihatMuat tabel PELANGGAN menggunakan MANIFEST.
-
TERIMA INVCHARS
Untuk informasi tentang cara menggunakan opsi ACCEPTINVCHARS, lihat. Muat tabel PELANGGAN menggunakan MANIFEST
-
NYATA
Untuk informasi tentang cara menggunakan opsi MANIFEST, lihatMuat tabel PELANGGAN menggunakan MANIFEST.
-
FORMAT TANGGAL
Untuk informasi tentang cara menggunakan opsi DATEFORMAT, lihat. Muat tabel DWDATE menggunakan DATEFORMAT
-
GZIP, LZOP dan BZIP2
Untuk informasi tentang cara mengompres file Anda, lihatMuat beberapa file data.
-
KOMPUPDATE
Untuk informasi tentang cara menggunakan opsi COMPUPDATE, lihat. Muat beberapa file data
-
Beberapa file
Untuk informasi tentang cara memuat banyak file, lihatMuat beberapa file data.
Memuat tabel SSB
Anda menggunakan perintah COPY berikut untuk memuat setiap tabel dalam skema SSB. Perintah untuk setiap tabel menunjukkan opsi COPY dan teknik pemecahan masalah yang berbeda.
Untuk memuat tabel SSB, ikuti langkah-langkah ini:
Ganti nama bucket dan AWS credentials
Perintah COPY dalam tutorial ini disajikan dalam format berikut.
copy table from 's3://<your-bucket-name>/load/key_prefix' credentials 'aws_iam_role=arn:aws:iam::<aws-account-id>:role/<role-name>' options;
Untuk setiap perintah COPY, lakukan hal berikut:
-
Ganti
<your-bucket-name>dengan nama bucket di wilayah yang sama dengan cluster Anda.Langkah ini mengasumsikan bucket dan cluster berada di wilayah yang sama. Atau, Anda dapat menentukan wilayah menggunakan REGION opsi dengan perintah COPY.
-
Ganti
<aws-account-id>dan<role-name>dengan peran Anda sendiri Akun AWS dan IAM. Segmen string kredensial yang diapit tanda kutip tunggal tidak boleh berisi spasi atau jeda baris. Perhatikan bahwa ARN mungkin sedikit berbeda dalam format dari sampel. Yang terbaik adalah menyalin ARN untuk peran dari konsol IAM, untuk memastikan bahwa itu akurat, ketika Anda menjalankan perintah COPY.
Muat tabel PART menggunakan NULL AS
Pada langkah ini, Anda menggunakan opsi CSV dan NULL AS untuk memuat tabel PART.
Perintah COPY dapat memuat data dari beberapa file secara paralel, yang jauh lebih cepat daripada memuat dari satu file. Untuk mendemonstrasikan prinsip ini, data untuk setiap tabel dalam tutorial ini dibagi menjadi delapan file, meskipun file-filenya sangat kecil. Pada langkah selanjutnya, Anda membandingkan perbedaan waktu antara memuat dari satu file dan memuat dari beberapa file. Untuk informasi selengkapnya, lihat Memuat file data.
Awalan kunci
Anda dapat memuat dari beberapa file dengan menentukan key prefix untuk kumpulan file, atau dengan secara eksplisit mencantumkan file dalam file manifes. Pada langkah ini, Anda menggunakan key prefix. Pada langkah selanjutnya, Anda menggunakan file manifes. Prefix key 's3://amzn-s3-demo-bucket/load/part-csv.tbl' memuat kumpulan file berikut dalam folder. load
part-csv.tbl-000 part-csv.tbl-001 part-csv.tbl-002 part-csv.tbl-003 part-csv.tbl-004 part-csv.tbl-005 part-csv.tbl-006 part-csv.tbl-007
Format CSV
CSV, yang merupakan singkatan dari nilai dipisahkan koma, adalah format umum yang digunakan untuk mengimpor dan mengekspor data spreadsheet. CSV lebih fleksibel daripada format yang dibatasi koma karena memungkinkan Anda untuk memasukkan string yang dikutip dalam bidang. Karakter tanda kutip default untuk COPY dari format CSV adalah tanda kutip ganda ("), tetapi Anda dapat menentukan karakter tanda kutip lain dengan menggunakan opsi QUOTE AS. Saat Anda menggunakan karakter tanda kutip di dalam bidang, lepaskan karakter dengan karakter tanda kutip tambahan.
Kutipan berikut dari file CSV-formatted data untuk tabel PART menunjukkan string terlampir dalam tanda kutip ganda (). "LARGE ANODIZED
BRASS" Ini juga menunjukkan string tertutup dalam dua tanda kutip ganda dalam string yang dikutip (). "MEDIUM ""BURNISHED"" TIN"
15,dark sky,MFGR#3,MFGR#47,MFGR#3438,indigo,"LARGE ANODIZED BRASS",45,LG CASE 22,floral beige,MFGR#4,MFGR#44,MFGR#4421,medium,"PROMO, POLISHED BRASS",19,LG DRUM 23,bisque slate,MFGR#4,MFGR#41,MFGR#4137,firebrick,"MEDIUM ""BURNISHED"" TIN",42,JUMBO JAR
Data untuk tabel PART berisi karakter yang menyebabkan COPY gagal. Dalam latihan ini, Anda memecahkan masalah kesalahan dan memperbaikinya.
Untuk memuat data yang dalam format CSV, tambahkan csv ke perintah COPY Anda. Jalankan perintah berikut untuk memuat tabel PART.
copy part from 's3://<your-bucket-name>/load/part-csv.tbl' credentials 'aws_iam_role=arn:aws:iam::<aws-account-id>:role/<role-name>' csv;
Anda mungkin mendapatkan pesan kesalahan yang mirip dengan berikut ini.
An error occurred when executing the SQL command: copy part from 's3://amzn-s3-demo-bucket/load/part-csv.tbl' credentials' ... ERROR: Load into table 'part' failed. Check 'stl_load_errors' system table for details. [SQL State=XX000] Execution time: 1.46s 1 statement(s) failed. 1 statement(s) failed.
Untuk mendapatkan informasi lebih lanjut tentang kesalahan, kueri tabel STL_LOAD_ERRORS. Kueri berikut menggunakan fungsi SUBSTRING untuk mempersingkat kolom agar mudah dibaca dan menggunakan LIMIT 10 untuk mengurangi jumlah baris yang dikembalikan. Anda dapat menyesuaikan nilai substring(filename,22,25) untuk memungkinkan panjang nama bucket Anda.
select query, substring(filename,22,25) as filename,line_number as line, substring(colname,0,12) as column, type, position as pos, substring(raw_line,0,30) as line_text, substring(raw_field_value,0,15) as field_text, substring(err_reason,0,45) as reason from stl_load_errors order by query desc limit 10;
query | filename | line | column | type | pos | --------+-------------------------+-----------+------------+------------+-----+---- 333765 | part-csv.tbl-000 | 1 | | | 0 | line_text | field_text | reason ------------------+------------+---------------------------------------------- 15,NUL next, | | Missing newline: Unexpected character 0x2c f
NULL SEBAGAI
File part-csv.tbl data menggunakan karakter terminator NUL (\x000atau\x0) untuk menunjukkan nilai NULL.
catatan
Meskipun ejaan yang sangat mirip, NUL dan NULL tidak sama. NUL adalah UTF-8 karakter dengan codepoint x000 yang sering digunakan untuk menunjukkan akhir catatan (EOR). NULL adalah nilai SQL yang mewakili tidak adanya data.
Secara default, COPY memperlakukan karakter terminator NUL sebagai karakter EOR dan mengakhiri rekaman, yang sering menghasilkan hasil yang tidak terduga atau kesalahan. Tidak ada metode standar tunggal untuk menunjukkan NULL dalam data teks. Dengan demikian, opsi perintah NULL AS COPY memungkinkan Anda menentukan karakter mana yang akan diganti dengan NULL saat memuat tabel. Dalam contoh ini, Anda ingin COPY memperlakukan karakter terminator NUL sebagai nilai NULL.
catatan
Kolom tabel yang menerima nilai NULL harus dikonfigurasi sebagai nullable. Artinya, itu tidak boleh menyertakan kendala NOT NULL dalam spesifikasi CREATE TABLE.
Untuk memuat BAGIAN menggunakan opsi NULL AS, jalankan perintah COPY berikut.
copy part from 's3://<your-bucket-name>/load/part-csv.tbl' credentials 'aws_iam_role=arn:aws:iam::<aws-account-id>:role/<role-name>' csv null as '\000';
Untuk memverifikasi bahwa COPY memuat nilai NULL, jalankan perintah berikut untuk memilih hanya baris yang berisi NULL.
select p_partkey, p_name, p_mfgr, p_category from part where p_mfgr is null;
p_partkey | p_name | p_mfgr | p_category -----------+----------+--------+------------ 15 | NUL next | | MFGR#47 81 | NUL next | | MFGR#23 133 | NUL next | | MFGR#44 (2 rows)
Opsi DELIMITER dan REGION
Opsi DELIMITER dan REGION penting untuk memahami cara memuat data.
Character-delimited format
Bidang dalam file yang dibatasi karakter dipisahkan oleh karakter tertentu, seperti karakter pipa (|), koma (,) atau tab (\ t). Character-delimited file dapat menggunakan karakter ASCII tunggal, termasuk salah satu karakter ASCII yang tidak dicetak, sebagai pembatas. Anda menentukan karakter pembatas dengan menggunakan opsi DELIMITER. Pembatas default adalah karakter pipa (|).
Kutipan berikut dari data untuk tabel SUPPLIER menggunakan format yang dibatasi pipa.
1|1|257368|465569|41365|19950218|2-HIGH|0|17|2608718|9783671|4|2504369|92072|2|19950331|TRUCK 1|2|257368|201928|8146|19950218|2-HIGH|0|36|6587676|9783671|9|5994785|109794|6|19950416|MAIL
DAERAH
Jika memungkinkan, Anda harus menemukan data pemuatan Anda di AWS wilayah yang sama dengan cluster Amazon Redshift Anda. Jika data dan cluster Anda berada di wilayah yang sama, Anda mengurangi latensi dan menghindari biaya transfer data lintas wilayah. Untuk informasi selengkapnya, lihat Praktik terbaik Amazon Redshift untuk memuat data.
Jika Anda harus memuat data dari AWS wilayah yang berbeda, gunakan opsi REGION untuk menentukan AWS wilayah di mana data beban berada. Jika Anda menentukan wilayah, semua data pemuatan, termasuk file manifes, harus berada di wilayah bernama. Untuk informasi selengkapnya, lihat REGION.
Misalnya, jika klaster Anda berada di Wilayah AS Timur (Virginia N.), dan bucket Amazon S3 Anda terletak di Wilayah AS Barat (Oregon), perintah COPY berikut menunjukkan cara memuat tabel SUPPLIER dari data yang dibatasi pipa.
copy supplier from 's3://amzn-s3-demo-bucket/ssb/supplier.tbl' credentials 'aws_iam_role=arn:aws:iam::<aws-account-id>:role/<role-name>' delimiter '|' gzip region 'us-west-2';
Muat tabel PELANGGAN menggunakan MANIFEST
Pada langkah ini, Anda menggunakan opsi FIXEDWIDTH, MAXERROR, ACCEPTINVCHARS, dan MANIFEST untuk memuat tabel PELANGGAN.
Data sampel untuk latihan ini berisi karakter yang menyebabkan kesalahan saat COPY mencoba memuatnya. Anda menggunakan opsi MAXERRORS dan tabel sistem STL_LOAD_ERRORS untuk memecahkan masalah kesalahan pemuatan dan kemudian menggunakan opsi ACCEPTINVCHARS dan MANIFEST untuk menghilangkan kesalahan.
Fixed-Width Format
Fixed-width format mendefinisikan setiap bidang sebagai jumlah karakter yang tetap, daripada memisahkan bidang dengan pembatas. Kutipan berikut dari data untuk tabel PELANGGAN menggunakan format lebar tetap.
1 Customer#000000001 IVhzIApeRb MOROCCO 0MOROCCO AFRICA 25-705 2 Customer#000000002 XSTf4,NCwDVaWNe6tE JORDAN 6JORDAN MIDDLE EAST 23-453 3 Customer#000000003 MG9kdTD ARGENTINA5ARGENTINAAMERICA 11-783
Urutan label/width pasangan harus sesuai dengan urutan kolom tabel dengan tepat. Untuk informasi selengkapnya, lihat FIXEDWIDTH.
String spesifikasi lebar tetap untuk data tabel PELANGGAN adalah sebagai berikut.
fixedwidth 'c_custkey:10, c_name:25, c_address:25, c_city:10, c_nation:15, c_region :12, c_phone:15,c_mktsegment:10'
Untuk memuat tabel CUSTOMER dari data fixed-width, jalankan perintah berikut.
copy customer from 's3://<your-bucket-name>/load/customer-fw.tbl' credentials 'aws_iam_role=arn:aws:iam::<aws-account-id>:role/<role-name>' fixedwidth 'c_custkey:10, c_name:25, c_address:25, c_city:10, c_nation:15, c_region :12, c_phone:15,c_mktsegment:10';
Anda harus mendapatkan pesan kesalahan, mirip dengan yang berikut ini.
An error occurred when executing the SQL command: copy customer from 's3://amzn-s3-demo-bucket/load/customer-fw.tbl' credentials'... ERROR: Load into table 'customer' failed. Check 'stl_load_errors' system table for details. [SQL State=XX000] Execution time: 2.95s 1 statement(s) failed.
MAXERROR
Secara default, pertama kali COPY menemukan kesalahan, perintah gagal dan mengembalikan pesan kesalahan. Untuk menghemat waktu selama pengujian, Anda dapat menggunakan opsi MAXERROR untuk menginstruksikan COPY untuk melewati sejumlah kesalahan tertentu sebelum gagal. Karena kami mengharapkan kesalahan saat pertama kali kami menguji pemuatan data tabel PELANGGAN, tambahkan maxerror 10 ke perintah COPY.
Untuk menguji menggunakan opsi FIXEDWIDTH dan MAXERROR, jalankan perintah berikut.
copy customer from 's3://<your-bucket-name>/load/customer-fw.tbl' credentials 'aws_iam_role=arn:aws:iam::<aws-account-id>:role/<role-name>' fixedwidth 'c_custkey:10, c_name:25, c_address:25, c_city:10, c_nation:15, c_region :12, c_phone:15,c_mktsegment:10' maxerror 10;
Kali ini, alih-alih pesan kesalahan, Anda mendapatkan pesan peringatan yang mirip dengan yang berikut ini.
Warnings: Load into table 'customer' completed, 112497 record(s) loaded successfully. Load into table 'customer' completed, 7 record(s) could not be loaded. Check 'stl_load_errors' system table for details.
Peringatan menunjukkan bahwa COPY mengalami tujuh kesalahan. Untuk memeriksa kesalahan, kueri tabel STL_LOAD_ERRORS, seperti yang ditunjukkan pada contoh berikut.
select query, substring(filename,22,25) as filename,line_number as line, substring(colname,0,12) as column, type, position as pos, substring(raw_line,0,30) as line_text, substring(raw_field_value,0,15) as field_text, substring(err_reason,0,45) as error_reason from stl_load_errors order by query desc, filename limit 7;
Hasil kueri STL_LOAD_ERRORS akan terlihat mirip dengan yang berikut ini.
query | filename | line | column | type | pos | line_text | field_text | error_reason --------+---------------------------+------+-----------+------------+-----+-------------------------------+------------+---------------------------------------------- 334489 | customer-fw.tbl.log | 2 | c_custkey | int4 | -1 | customer-fw.tbl | customer-f | Invalid digit, Value 'c', Pos 0, Type: Integ 334489 | customer-fw.tbl.log | 6 | c_custkey | int4 | -1 | Complete | Complete | Invalid digit, Value 'C', Pos 0, Type: Integ 334489 | customer-fw.tbl.log | 3 | c_custkey | int4 | -1 | #Total rows | #Total row | Invalid digit, Value '#', Pos 0, Type: Integ 334489 | customer-fw.tbl.log | 5 | c_custkey | int4 | -1 | #Status | #Status | Invalid digit, Value '#', Pos 0, Type: Integ 334489 | customer-fw.tbl.log | 1 | c_custkey | int4 | -1 | #Load file | #Load file | Invalid digit, Value '#', Pos 0, Type: Integ 334489 | customer-fw.tbl000 | 1 | c_address | varchar | 34 | 1 Customer#000000001 | .Mayag.ezR | String contains invalid or unsupported UTF8 334489 | customer-fw.tbl000 | 1 | c_address | varchar | 34 | 1 Customer#000000001 | .Mayag.ezR | String contains invalid or unsupported UTF8 (7 rows)
Dengan memeriksa hasilnya, Anda dapat melihat bahwa ada dua pesan di error_reasons kolom:
-
Invalid digit, Value '#', Pos 0, Type: IntegKesalahan ini disebabkan oleh
customer-fw.tbl.logfile. Masalahnya adalah itu adalah file log, bukan file data, dan tidak boleh dimuat. Anda dapat menggunakan file manifes untuk menghindari memuat file yang salah. -
String contains invalid or unsupported UTF8Tipe data VARCHAR mendukung UTF-8 karakter multibyte hingga tiga byte. Jika data pemuatan berisi karakter yang tidak didukung atau tidak valid, Anda dapat menggunakan opsi ACCEPTINVCHARS untuk mengganti setiap karakter yang tidak valid dengan karakter alternatif tertentu.
Masalah lain dengan beban lebih sulit dideteksi — beban menghasilkan hasil yang tidak terduga. Untuk menyelidiki masalah ini, jalankan perintah berikut untuk query tabel CUSTOMER.
select c_custkey, c_name, c_address from customer order by c_custkey limit 10;
c_custkey | c_name | c_address -----------+---------------------------+--------------------------- 2 | Customer#000000002 | XSTf4,NCwDVaWNe6tE 2 | Customer#000000002 | XSTf4,NCwDVaWNe6tE 3 | Customer#000000003 | MG9kdTD 3 | Customer#000000003 | MG9kdTD 4 | Customer#000000004 | XxVSJsL 4 | Customer#000000004 | XxVSJsL 5 | Customer#000000005 | KvpyuHCplrB84WgAi 5 | Customer#000000005 | KvpyuHCplrB84WgAi 6 | Customer#000000006 | sKZz0CsnMD7mp4Xd0YrBvx 6 | Customer#000000006 | sKZz0CsnMD7mp4Xd0YrBvx (10 rows)
Baris harus unik, tetapi ada duplikat.
Cara lain untuk memeriksa hasil yang tidak terduga adalah dengan memverifikasi jumlah baris yang dimuat. Dalam kasus kami, 100000 baris seharusnya dimuat, tetapi pesan pemuatan melaporkan memuat 112497 catatan. Baris tambahan dimuat karena COPY memuat file asing,. customer-fw.tbl0000.bak
Dalam latihan ini, Anda menggunakan file manifes untuk menghindari memuat file yang salah.
TERIMA INVCHARS
Secara default, ketika COPY menemukan karakter yang tidak didukung oleh tipe data kolom, ia melewatkan baris dan mengembalikan kesalahan. Untuk informasi tentang UTF-8 karakter yang tidak valid, lihat. Kesalahan pemuatan karakter multibyte
Anda dapat menggunakan opsi MAXERRORS untuk mengabaikan kesalahan dan melanjutkan pemuatan, lalu kueri STL_LOAD_ERRORS untuk menemukan karakter yang tidak valid, dan kemudian memperbaiki file data. Namun, MAXERRORS paling baik digunakan untuk memecahkan masalah beban dan umumnya tidak boleh digunakan dalam lingkungan produksi.
Opsi ACCEPTINVCHARS biasanya merupakan pilihan yang lebih baik untuk mengelola karakter yang tidak valid. ACCEPTINVCHARS menginstruksikan COPY untuk mengganti setiap karakter yang tidak valid dengan karakter valid yang ditentukan dan melanjutkan operasi pemuatan. Anda dapat menentukan karakter ASCII yang valid, kecuali NULL, sebagai karakter pengganti. Karakter pengganti default adalah tanda tanya (? ). COPY menggantikan karakter multibyte dengan string pengganti dengan panjang yang sama. Misalnya, karakter 4-byte akan diganti dengan'????'.
COPY mengembalikan jumlah baris yang berisi karakter yang tidak valid UTF-8 . Ini juga menambahkan entri ke tabel sistem STL_REPLACEMENTS untuk setiap baris yang terpengaruh, hingga maksimum 100 baris per irisan node. UTF-8 Karakter tambahan yang tidak valid juga diganti, tetapi peristiwa pengganti tersebut tidak direkam.
ACCEPTINVCHARS hanya berlaku untuk kolom VARCHAR.
Untuk langkah ini, Anda menambahkan ACCEPTINVCHARS dengan karakter pengganti. '^'
NYATA
Saat Anda MENYALIN dari Amazon S3 menggunakan key prefix, ada risiko Anda mungkin memuat tabel yang tidak diinginkan. Misalnya, 's3://amzn-s3-demo-bucket/load/ folder berisi delapan file data yang berbagi key prefixcustomer-fw.tbl:customer-fw.tbl0000,customer-fw.tbl0001, dan seterusnya. Namun, folder yang sama juga berisi file customer-fw.tbl.log asing dan. customer-fw.tbl-0001.bak
Untuk memastikan bahwa Anda memuat semua file yang benar, dan hanya file yang benar, gunakan file manifes. Manifes adalah file teks dalam format JSON yang secara eksplisit mencantumkan kunci objek unik untuk setiap file sumber yang akan dimuat. Objek file dapat berada di folder yang berbeda atau ember yang berbeda, tetapi mereka harus berada di wilayah yang sama. Untuk informasi selengkapnya, lihat MANIFEST.
Berikut ini menunjukkan customer-fw-manifest teks.
{ "entries": [ {"url":"s3://<your-bucket-name>/load/customer-fw.tbl-000"}, {"url":"s3://<your-bucket-name>/load/customer-fw.tbl-001"}, {"url":"s3://<your-bucket-name>/load/customer-fw.tbl-002"}, {"url":"s3://<your-bucket-name>/load/customer-fw.tbl-003"}, {"url":"s3://<your-bucket-name>/load/customer-fw.tbl-004"}, {"url":"s3://<your-bucket-name>/load/customer-fw.tbl-005"}, {"url":"s3://<your-bucket-name>/load/customer-fw.tbl-006"}, {"url":"s3://<your-bucket-name>/load/customer-fw.tbl-007"} ] }
Untuk memuat data untuk tabel CUSTOMER menggunakan file manifes
-
Buka file
customer-fw-manifestdi editor teks. -
Ganti
<your-bucket-name>dengan nama bucket Anda. -
Simpan file tersebut.
-
Unggah file ke folder muat di bucket Anda.
-
Jalankan perintah COPY berikut.
copy customer from 's3://<your-bucket-name>/load/customer-fw-manifest' credentials 'aws_iam_role=arn:aws:iam::<aws-account-id>:role/<role-name>' fixedwidth 'c_custkey:10, c_name:25, c_address:25, c_city:10, c_nation:15, c_region :12, c_phone:15,c_mktsegment:10' maxerror 10 acceptinvchars as '^' manifest;
Muat tabel DWDATE menggunakan DATEFORMAT
Pada langkah ini, Anda menggunakan opsi DELIMITER dan DATEFORMAT untuk memuat tabel DWDATE.
Saat memuat kolom DATE dan TIMESTAMP, COPY mengharapkan format default, yaitu YYYY-MM-DD untuk tanggal dan YYYY-MM-DD HH:MI:SS stempel waktu. Jika data beban tidak menggunakan format default, Anda dapat menggunakan DATEFORMAT dan TIMEFORMAT untuk menentukan format.
Kutipan berikut menunjukkan format tanggal dalam tabel DWDATE. Perhatikan bahwa format tanggal di kolom dua tidak konsisten.
19920104 1992-01-04 Sunday January 1992 199201 Jan1992 1 4 4 1... 19920112 January 12, 1992 Monday January 1992 199201 Jan1992 2 12 12 1... 19920120 January 20, 1992 Tuesday January 1992 199201 Jan1992 3 20 20 1...
FORMAT TANGGAL
Anda hanya dapat menentukan satu format tanggal. Jika data pemuatan berisi format yang tidak konsisten, mungkin dalam kolom yang berbeda, atau jika format tidak diketahui pada waktu muat, Anda menggunakan DATEFORMAT dengan argumen. 'auto' Kapan 'auto' ditentukan, COPY mengenali format tanggal atau waktu yang valid dan mengubahnya menjadi format default. 'auto'Opsi ini mengenali beberapa format yang tidak didukung saat menggunakan string DATEFORMAT dan TIMEFORMAT. Untuk informasi selengkapnya, lihat Menggunakan pengenalan otomatis dengan DATEFORMAT dan TIMEFORMAT.
Untuk memuat tabel DWDATE, jalankan perintah COPY berikut.
copy dwdate from 's3://<your-bucket-name>/load/dwdate-tab.tbl' credentials 'aws_iam_role=arn:aws:iam::<aws-account-id>:role/<role-name>' delimiter '\t' dateformat 'auto';
Muat beberapa file data
Anda dapat menggunakan opsi GZIP dan COMPUPDATE untuk memuat tabel.
Anda dapat memuat tabel dari satu file data atau beberapa file. Lakukan ini untuk membandingkan waktu muat untuk kedua metode.
GZIP, LZOP dan BZIP2
Anda dapat mengompres file Anda menggunakan format kompresi gzip, lzop, atau bzip2. Saat memuat dari file terkompresi, COPY membuka kompres file selama proses pemuatan. Mengompresi file Anda menghemat ruang penyimpanan dan mempersingkat waktu upload.
KOMPUPDATE
Ketika COPY memuat tabel kosong tanpa pengkodean kompresi, ia menganalisis data beban untuk menentukan pengkodean yang optimal. Kemudian mengubah tabel untuk menggunakan pengkodean tersebut sebelum memulai beban. Proses analisis ini membutuhkan waktu, tetapi terjadi, paling banyak, sekali per tabel. Untuk menghemat waktu, Anda dapat melewati langkah ini dengan mematikan COMPUPDATE. Untuk mengaktifkan evaluasi waktu COPY yang akurat, Anda menonaktifkan COMPUPDATE untuk langkah ini.
Beberapa File
Perintah COPY dapat memuat data dengan sangat efisien ketika memuat dari beberapa file secara paralel, bukan dari satu file. Anda dapat membagi data Anda menjadi file sehingga jumlah file adalah kelipatan dari jumlah irisan di cluster Anda. Jika ya, Amazon Redshift membagi beban kerja dan mendistribusikan data secara merata di antara irisan. Jumlah irisan per node tergantung pada ukuran node cluster. Untuk informasi selengkapnya tentang jumlah irisan yang dimiliki setiap ukuran node, lihat Tentang cluster dan node di Panduan Manajemen Pergeseran Merah Amazon.
Misalnya, node komputasi di cluster Anda dalam tutorial ini dapat memiliki dua irisan masing-masing, sehingga cluster empat simpul memiliki delapan irisan. Pada langkah sebelumnya, data pemuatan terkandung dalam delapan file, meskipun file-file tersebut sangat kecil. Anda dapat membandingkan perbedaan waktu antara memuat dari satu file besar dan memuat dari beberapa file.
Bahkan file yang berisi 15 juta catatan dan menempati sekitar 1,2 GB sangat kecil dalam skala Amazon Redshift. Tetapi mereka cukup untuk menunjukkan keuntungan kinerja pemuatan dari banyak file.
Gambar berikut menunjukkan file data untuk LINEORDER.
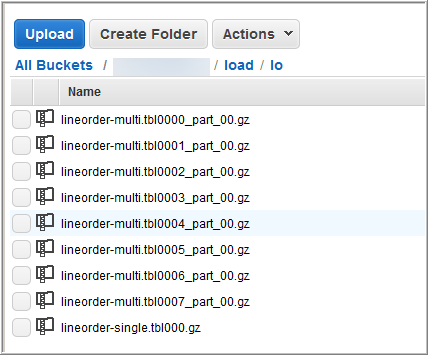
Untuk mengevaluasi kinerja COPY dengan banyak file
-
Dalam uji lab, perintah berikut dijalankan ke COPY dari satu file. Perintah ini menunjukkan ember fiktif.
copy lineorder from 's3://amzn-s3-demo-bucket/load/lo/lineorder-single.tbl' credentials 'aws_iam_role=arn:aws:iam::<aws-account-id>:role/<role-name>' gzip compupdate off region 'us-east-1'; -
Hasilnya adalah sebagai berikut. Perhatikan waktu eksekusi.
Warnings: Load into table 'lineorder' completed, 14996734 record(s) loaded successfully. 0 row(s) affected. copy executed successfully Execution time: 51.56s -
Kemudian perintah berikut untuk COPY dari beberapa file dijalankan.
copy lineorder from 's3://amzn-s3-demo-bucket/load/lo/lineorder-multi.tbl' credentials 'aws_iam_role=arn:aws:iam::<aws-account-id>:role/<role-name>' gzip compupdate off region 'us-east-1'; -
Hasilnya adalah sebagai berikut. Perhatikan waktu eksekusi.
Warnings: Load into table 'lineorder' completed, 14996734 record(s) loaded successfully. 0 row(s) affected. copy executed successfully Execution time: 17.7s -
Bandingkan waktu eksekusi.
Dalam percobaan kami, waktu untuk memuat 15 juta catatan menurun dari 51,56 detik menjadi 17,7 detik, pengurangan 65,7 persen.
Hasil ini didasarkan pada penggunaan cluster empat simpul. Jika cluster Anda memiliki lebih banyak node, penghematan waktu dikalikan. Untuk cluster Amazon Redshift yang khas, dengan puluhan hingga ratusan node, perbedaannya bahkan lebih dramatis. Jika Anda memiliki cluster node tunggal, ada sedikit perbedaan antara waktu eksekusi.
Langkah 6: Vakum dan analisis database
Setiap kali Anda menambahkan, menghapus, atau memodifikasi sejumlah besar baris, Anda harus menjalankan perintah VACUUM dan kemudian perintah ANALYZE. Vakum memulihkan ruang dari baris yang dihapus dan mengembalikan urutan pengurutan. Perintah ANALYZE memperbarui metadata statistik, yang memungkinkan pengoptimal kueri menghasilkan rencana kueri yang lebih akurat. Untuk informasi selengkapnya, lihat Tabel penyedot debu.
Jika Anda memuat data dalam urutan kunci sortir, ruang hampa cepat. Dalam tutorial ini, Anda menambahkan sejumlah besar baris, tetapi Anda menambahkannya ke tabel kosong. Karena itu, tidak perlu menggunakan, dan Anda tidak menghapus baris apa pun. COPY secara otomatis memperbarui statistik setelah memuat tabel kosong, sehingga statistik Anda harus mutakhir. Namun, sebagai masalah tata graha yang baik, Anda menyelesaikan tutorial ini dengan menyedot debu dan menganalisis database Anda.
Untuk menyedot debu dan menganalisis database, jalankan perintah berikut.
vacuum; analyze;
Langkah 7: Bersihkan sumber daya Anda
Cluster Anda terus bertambah biaya selama itu berjalan. Ketika Anda telah menyelesaikan tutorial ini, Anda harus mengembalikan lingkungan Anda ke keadaan sebelumnya dengan mengikuti langkah-langkah di Langkah 5: Cabut akses dan hapus cluster sampel Anda di Panduan Memulai Amazon Redshift.
Jika Anda ingin menyimpan cluster, tetapi memulihkan penyimpanan yang digunakan oleh tabel SSB, jalankan perintah berikut.
drop table part; drop table supplier; drop table customer; drop table dwdate; drop table lineorder;
Selanjutnya
Ringkasan
Dalam tutorial ini, Anda mengunggah file data ke Amazon S3 dan kemudian menggunakan perintah COPY untuk memuat data dari file ke tabel Amazon Redshift.
Anda memuat data menggunakan format berikut:
-
Character-delimited
-
CSV
-
Fixed-width
Anda menggunakan tabel sistem STL_LOAD_ERRORS untuk memecahkan masalah kesalahan pemuatan, lalu menggunakan opsi REGION, MANIFEST, MAXERROR, ACCEPTINVCHARS, DATEFORMAT, dan NULL AS untuk mengatasi kesalahan.
Anda menerapkan praktik terbaik berikut untuk memuat data:
Untuk informasi selengkapnya tentang praktik terbaik Amazon Redshift, lihat tautan berikut:
