Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Meminimalkan waktu vakum
Amazon Redshift secara otomatis mengurutkan data dan berjalan VACUUM DELETE di latar belakang. Ini mengurangi kebutuhan untuk menjalankan perintah. VACUUM Menyedot debu berpotensi memakan waktu. Bergantung pada sifat data Anda, kami merekomendasikan praktik berikut untuk meminimalkan waktu vakum.
Topik
Putuskan apakah akan mengindeks ulang
Anda sering dapat meningkatkan kinerja kueri secara signifikan dengan menggunakan gaya pengurutan interleaved, tetapi seiring waktu kinerja mungkin menurun jika distribusi nilai dalam kolom kunci sortir berubah.
Saat Anda pertama kali memuat tabel interleaved kosong menggunakan COPY atau CREATE TABLE AS, Amazon Redshift secara otomatis membuat indeks interleaved. Jika Anda awalnya memuat tabel interleaved menggunakanINSERT, Anda harus menjalankan VACUUM REINDEX setelahnya untuk menginisialisasi indeks interleaved.
Seiring waktu, saat Anda menambahkan baris dengan nilai kunci sortir baru, kinerja mungkin menurun jika distribusi nilai dalam kolom kunci sortir berubah. Jika baris baru Anda terutama berada dalam kisaran nilai kunci pengurutan yang ada, Anda tidak perlu mengindeks ulang. Jalankan VACUUM SORT ONLY atau VACUUM FULL untuk mengembalikan urutan pengurutan.
Mesin kueri dapat menggunakan urutan pengurutan untuk secara efisien memilih blok data mana yang perlu dipindai untuk memproses kueri. Untuk pengurutan interleaved, Amazon Redshift menganalisis nilai kolom kunci sortir untuk menentukan urutan pengurutan yang optimal. Jika distribusi nilai kunci berubah, atau miring, saat baris ditambahkan, strategi pengurutan tidak akan lagi optimal, dan manfaat kinerja penyortiran akan menurun. Untuk menganalisis ulang distribusi kunci sortir, Anda dapat menjalankan file. VACUUM REINDEX Operasi reindex memakan waktu, jadi untuk memutuskan apakah sebuah tabel akan mendapat manfaat dari reindex, kueri tampilan. SVV_INTERLEAVED_COLUMNS
Misalnya, kueri berikut menunjukkan detail untuk tabel yang menggunakan kunci pengurutan interleaved.
select tbl as tbl_id, stv_tbl_perm.name as table_name, col, interleaved_skew, last_reindex from svv_interleaved_columns, stv_tbl_perm where svv_interleaved_columns.tbl = stv_tbl_perm.id and interleaved_skew is not null;tbl_id | table_name | col | interleaved_skew | last_reindex --------+------------+-----+------------------+-------------------- 100048 | customer | 0 | 3.65 | 2015-04-22 22:05:45 100068 | lineorder | 1 | 2.65 | 2015-04-22 22:05:45 100072 | part | 0 | 1.65 | 2015-04-22 22:05:45 100077 | supplier | 1 | 1.00 | 2015-04-22 22:05:45 (4 rows)
Nilai untuk interleaved_skew adalah rasio yang menunjukkan jumlah kemiringan. Nilai 1 berarti tidak ada kemiringan. Jika kemiringan lebih besar dari 1,4, a biasanya VACUUM REINDEX akan meningkatkan kinerja kecuali kemiringan melekat pada set yang mendasarinya.
Anda dapat menggunakan nilai tanggal last_reindex untuk menentukan berapa lama sejak reindex terakhir.
Kurangi ukuran wilayah yang tidak disortir
Wilayah yang tidak disortir tumbuh ketika Anda memuat sejumlah besar data baru ke dalam tabel yang sudah berisi data atau ketika Anda tidak mengosongkan tabel sebagai bagian dari operasi pemeliharaan rutin Anda. Untuk menghindari operasi vakum yang berjalan lama, gunakan praktik berikut:
-
Jalankan operasi vakum pada jadwal reguler.
Jika Anda memuat tabel Anda secara bertahap (seperti pembaruan harian yang mewakili persentase kecil dari jumlah total baris dalam tabel), berjalan VACUUM secara teratur akan membantu memastikan bahwa operasi vakum individu berjalan dengan cepat.
-
Jalankan beban terbesar terlebih dahulu.
Jika Anda perlu memuat tabel baru dengan beberapa COPY operasi, jalankan beban terbesar terlebih dahulu. Saat Anda menjalankan pemuatan awal ke tabel baru atau terpotong, semua data dimuat langsung ke wilayah yang diurutkan, jadi tidak diperlukan vakum.
-
Memotong tabel alih-alih menghapus semua baris.
Menghapus baris dari tabel tidak merebut kembali ruang yang ditempati baris sampai Anda melakukan operasi vakum; Namun, memotong tabel mengosongkan tabel dan merebut kembali ruang disk, sehingga tidak diperlukan ruang hampa. Atau, jatuhkan tabel dan buat kembali.
-
Memotong atau menjatuhkan tabel uji.
Jika Anda memuat sejumlah kecil baris ke dalam tabel untuk tujuan pengujian, jangan hapus baris setelah selesai. Sebagai gantinya, potong tabel dan muat ulang baris tersebut sebagai bagian dari operasi beban produksi berikutnya.
-
Lakukan salinan yang dalam.
Jika tabel yang menggunakan tabel kunci sortir majemuk memiliki wilayah besar yang tidak disortir, salinan dalam jauh lebih cepat daripada ruang hampa. Salinan mendalam membuat ulang dan mengisi ulang tabel dengan menggunakan sisipan massal, yang secara otomatis mengurutkan ulang tabel. Jika sebuah tabel memiliki wilayah besar yang tidak disortir, salinan dalam jauh lebih cepat daripada ruang hampa. Trade off adalah bahwa Anda tidak dapat membuat pembaruan bersamaan selama operasi penyalinan mendalam, yang dapat Anda lakukan selama vakum. Untuk informasi selengkapnya, lihat Praktik terbaik Amazon Redshift untuk mendesain kueri.
Kurangi volume baris yang digabungkan
Jika operasi vakum perlu menggabungkan baris baru ke dalam wilayah yang diurutkan tabel, waktu yang diperlukan untuk ruang hampa akan meningkat seiring dengan bertambahnya tabel. Anda dapat meningkatkan kinerja vakum dengan mengurangi jumlah baris yang harus digabungkan.
Sebelum ruang hampa, tabel terdiri dari wilayah yang diurutkan di kepala tabel, diikuti oleh wilayah yang tidak disortir, yang tumbuh setiap kali baris ditambahkan atau diperbarui. Ketika satu set baris ditambahkan oleh COPY operasi, kumpulan baris baru diurutkan pada kunci sortir karena ditambahkan ke wilayah yang tidak disortir di akhir tabel. Baris baru diurutkan dalam set mereka sendiri, tetapi tidak dalam wilayah yang tidak disortir.
Diagram berikut mengilustrasikan wilayah yang tidak disortir setelah dua COPY operasi berturut-turut, di mana kunci sortir adalah. CUSTID Untuk mempermudah, contoh ini menunjukkan kunci sortir majemuk, tetapi prinsip yang sama berlaku untuk kunci sortir yang disisipkan, kecuali bahwa dampak wilayah yang tidak disortir lebih besar untuk tabel yang disisipkan.
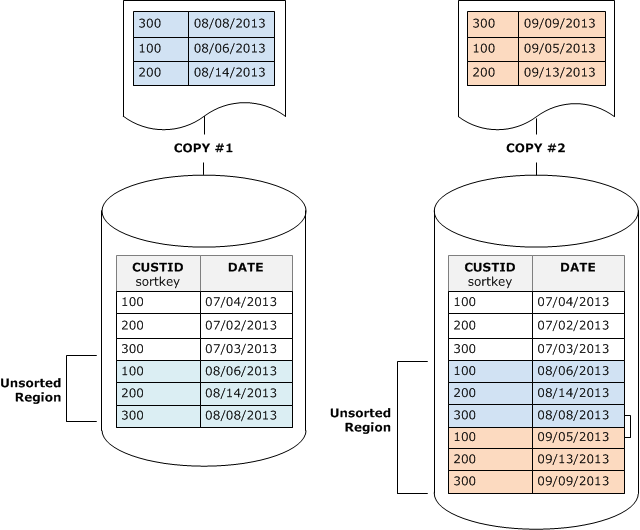
Vakum mengembalikan urutan pengurutan tabel dalam dua tahap:
-
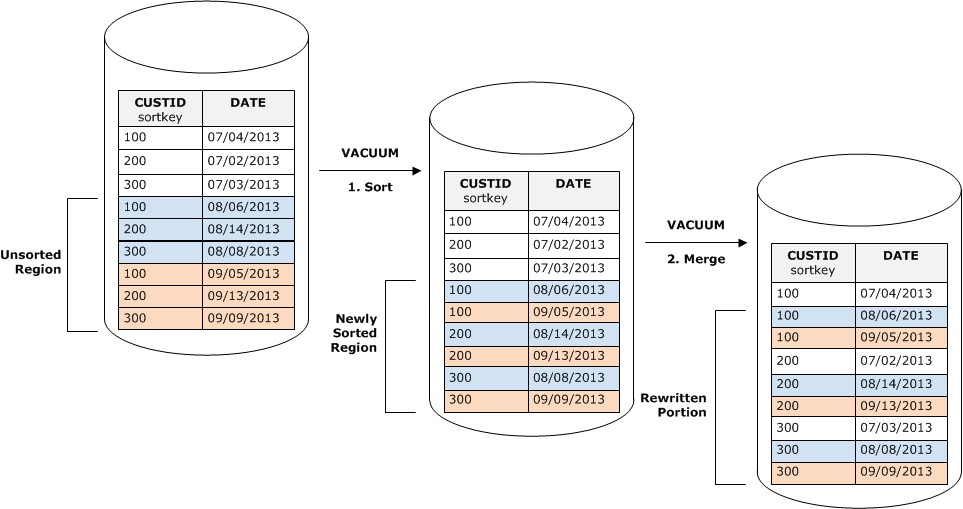
Urutkan wilayah yang tidak disortir menjadi wilayah yang baru diurutkan.
Tahap pertama relatif murah, karena hanya wilayah yang tidak disortir yang ditulis ulang. Jika rentang nilai kunci sortir dari wilayah yang baru diurutkan lebih tinggi dari rentang yang ada, hanya baris baru yang perlu ditulis ulang, dan ruang hampa selesai. Misalnya, jika wilayah yang diurutkan berisi nilai ID 1 hingga 500 dan operasi penyalinan berikutnya menambahkan nilai kunci lebih besar dari 500, maka hanya wilayah yang tidak disortir yang perlu ditulis ulang.
-
Gabungkan wilayah yang baru diurutkan dengan wilayah yang telah diurutkan sebelumnya.
Jika kunci di wilayah yang baru diurutkan tumpang tindih dengan kunci di wilayah yang diurutkan, maka VACUUM perlu menggabungkan baris. Mulai dari awal wilayah yang baru diurutkan (pada kunci pengurutan terendah), ruang hampa menulis baris gabungan dari wilayah yang diurutkan sebelumnya dan wilayah yang baru diurutkan ke dalam kumpulan blok baru.
Sejauh mana rentang kunci sortir baru tumpang tindih dengan kunci pengurutan yang ada menentukan sejauh mana wilayah yang diurutkan sebelumnya perlu ditulis ulang. Jika kunci yang tidak disortir tersebar di seluruh rentang pengurutan yang ada, ruang hampa mungkin perlu menulis ulang bagian tabel yang ada.
Diagram berikut menunjukkan bagaimana vakum akan mengurutkan dan menggabungkan baris yang ditambahkan ke tabel di mana CUSTID adalah kunci sortir. Karena setiap operasi penyalinan menambahkan satu set baris baru dengan nilai kunci yang tumpang tindih dengan kunci yang ada, hampir seluruh tabel perlu ditulis ulang. Diagram menunjukkan pengurutan tunggal dan penggabungan, tetapi dalam praktiknya, ruang hampa besar terdiri dari serangkaian langkah pengurutan dan penggabungan tambahan.
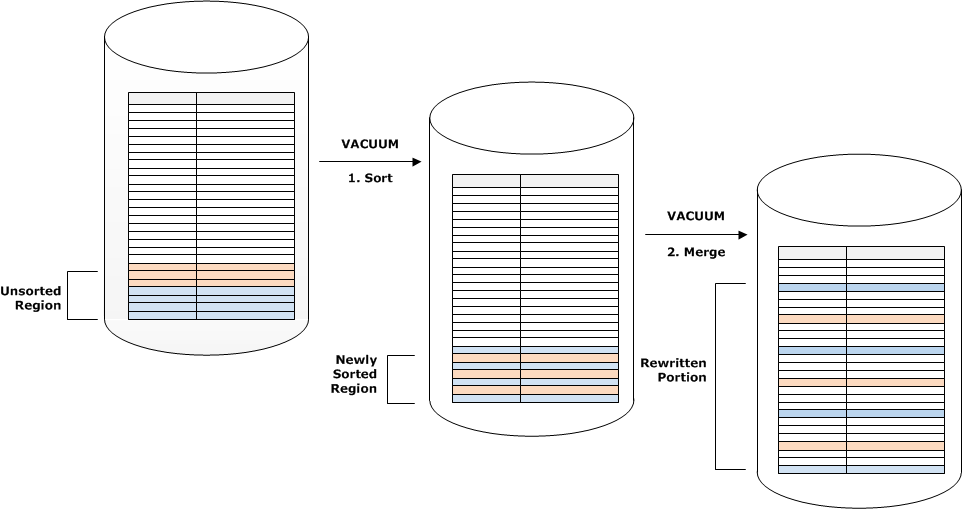
Jika rentang kunci sortir dalam satu set baris baru tumpang tindih dengan kisaran kunci yang ada, biaya tahap penggabungan terus tumbuh sebanding dengan ukuran tabel saat tabel tumbuh sementara biaya tahap pengurutan tetap sebanding dengan ukuran wilayah yang tidak disortir. Dalam kasus seperti itu, biaya tahap penggabungan membayangi biaya tahap pengurutan, seperti yang ditunjukkan diagram berikut.
Untuk menentukan proporsi tabel yang digabungkan ulang, kueri SVV _ VACUUM _ SUMMARY setelah operasi vakum selesai. Kueri berikut menunjukkan efek dari enam vakum berturut-turut yang CUSTSALES tumbuh lebih besar dari waktu ke waktu.
select * from svv_vacuum_summary where table_name = 'custsales';table_name | xid | sort_ | merge_ | elapsed_ | row_ | sortedrow_ | block_ | max_merge_ | | partitions | increments | time | delta | delta | delta | partitions -----------+------+------------+------------+------------+-------+------------+---------+--------------- custsales | 7072 | 3 | 2 | 143918314 | 0 | 88297472 | 1524 | 47 custsales | 7122 | 3 | 3 | 164157882 | 0 | 88297472 | 772 | 47 custsales | 7212 | 3 | 4 | 187433171 | 0 | 88297472 | 767 | 47 custsales | 7289 | 3 | 4 | 255482945 | 0 | 88297472 | 770 | 47 custsales | 7420 | 3 | 5 | 316583833 | 0 | 88297472 | 769 | 47 custsales | 9007 | 3 | 6 | 306685472 | 0 | 88297472 | 772 | 47 (6 rows)
Kolom merge_increments memberikan indikasi jumlah data yang digabungkan untuk setiap operasi vakum. Jika jumlah kenaikan penggabungan selama vakum berturut-turut meningkat sebanding dengan pertumbuhan ukuran tabel, ini menunjukkan bahwa setiap operasi vakum menggabungkan kembali peningkatan jumlah baris dalam tabel karena daerah yang ada dan yang baru diurutkan tumpang tindih.
Muat data Anda dalam urutan kunci sortir
Jika Anda memuat data Anda dalam urutan kunci sortir menggunakan COPY perintah, Anda dapat mengurangi atau bahkan menghapus kebutuhan untuk menyedot debu.
COPYsecara otomatis menambahkan baris baru ke wilayah tabel yang diurutkan ketika semua hal berikut benar:
-
Tabel menggunakan kunci sortir majemuk dengan hanya satu kolom sortir.
-
Kolom sortir adalah NOTNULL.
-
Tabel 100 persen diurutkan atau kosong.
-
Semua baris baru lebih tinggi dalam urutan pengurutan daripada baris yang ada, termasuk baris yang ditandai untuk dihapus. Dalam hal ini, Amazon Redshift menggunakan delapan byte pertama dari kunci sortir untuk menentukan urutan pengurutan.
Misalnya, Anda memiliki tabel yang mencatat peristiwa pelanggan menggunakan ID pelanggan dan waktu. Jika Anda mengurutkan ID pelanggan, kemungkinan rentang kunci pengurutan baris baru yang ditambahkan oleh beban tambahan akan tumpang tindih dengan rentang yang ada, seperti yang ditunjukkan pada contoh sebelumnya, yang mengarah ke operasi vakum yang mahal.
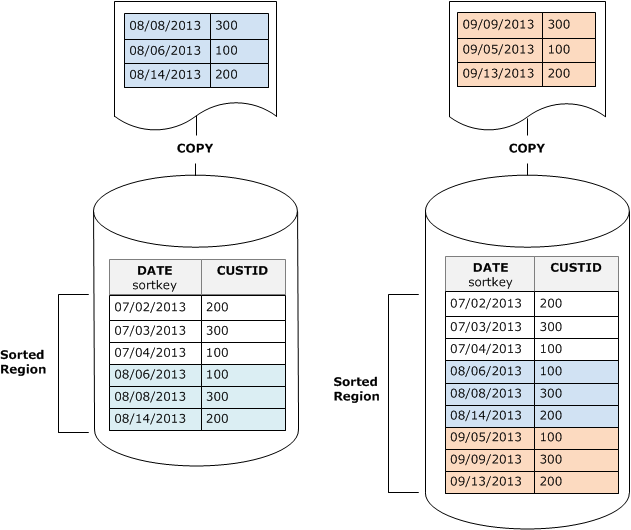
Jika Anda mengatur kunci pengurutan ke kolom stempel waktu, baris baru Anda akan ditambahkan dalam urutan pengurutan di akhir tabel, seperti yang ditunjukkan diagram berikut, mengurangi atau bahkan menghilangkan kebutuhan untuk menyedot debu.
Gunakan tabel deret waktu untuk mengurangi data yang tersimpan
Jika Anda memelihara data untuk periode waktu bergulir, gunakan serangkaian tabel, seperti yang diilustrasikan diagram berikut.
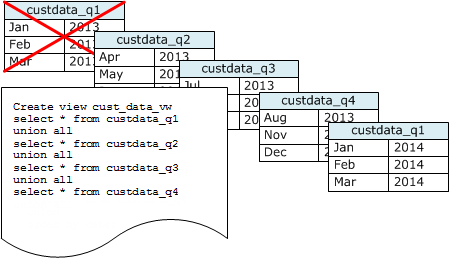
Buat tabel baru setiap kali Anda menambahkan satu set data, lalu hapus tabel tertua dalam seri. Anda mendapatkan manfaat ganda:
-
Anda menghindari biaya tambahan untuk menghapus baris, karena DROP TABLE operasi jauh lebih efisien daripada massaDELETE.
-
Jika tabel diurutkan berdasarkan stempel waktu, tidak diperlukan vakum. Jika setiap tabel berisi data selama satu bulan, ruang hampa paling banyak harus menulis ulang data selama satu bulan, bahkan jika tabel tidak diurutkan berdasarkan stempel waktu.
Anda dapat membuat UNION ALL tampilan untuk digunakan dengan melaporkan kueri yang menyembunyikan fakta bahwa data disimpan dalam beberapa tabel. Jika kueri memfilter pada kunci pengurutan, perencana kueri dapat secara efisien melewati semua tabel yang tidak digunakan. A UNION ALL bisa kurang efisien untuk jenis kueri lainnya, jadi Anda harus mengevaluasi kinerja kueri dalam konteks semua kueri yang menggunakan tabel.
