Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Bekerja dengan editor kueri v2
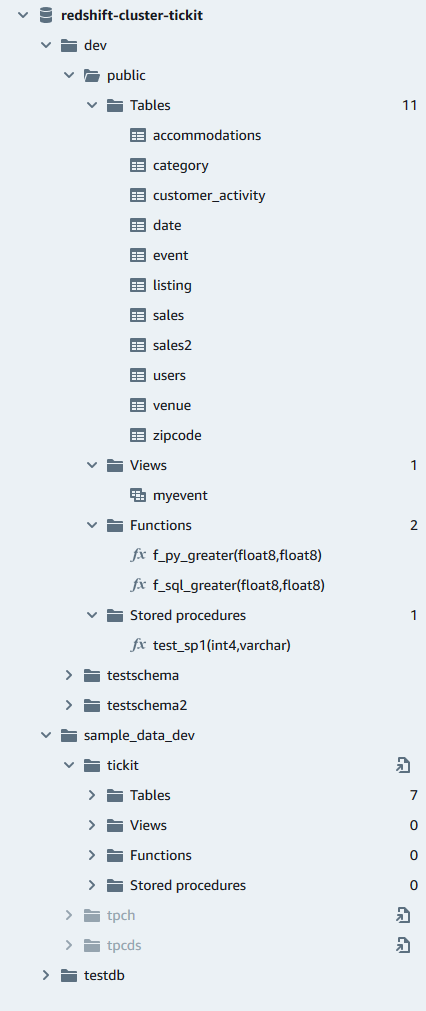
Editor kueri v2 terutama digunakan untuk mengedit dan menjalankan kueri, memvisualisasikan hasil, dan berbagi pekerjaan Anda dengan tim Anda. Dengan query editor v2, Anda dapat membuat database, skema, tabel, dan fungsi yang ditentukan pengguna (UDF). Dalam panel tampilan pohon, untuk setiap database Anda, Anda dapat melihat skema. Untuk setiap skema, Anda dapat melihat tabel, tampilan, UDF, dan prosedur tersimpan.
Topik
Membuka editor kueri v2
Untuk membuka editor kueri v2
Dari menu navigator, pilih Editor, lalu Query editor V2. Editor kueri v2 terbuka di tab browser baru.
Halaman editor kueri memiliki menu navigator tempat Anda memilih tampilan sebagai berikut:
- Penyunting
Anda mengelola dan menanyakan data Anda diatur sebagai tabel dan terkandung dalam database. Basis data dapat berisi data yang disimpan atau berisi referensi ke data yang disimpan di tempat lain, seperti Amazon S3. Anda terhubung ke database yang terdapat dalam kluster atau grup kerja tanpa server.
Saat bekerja di tampilan Editor, Anda memiliki kontrol berikut:
Bidang Cluster atau Workgroup menampilkan nama yang saat ini Anda sambungkan. Bidang Database menampilkan database dalam cluster atau workgroup. Tindakan yang Anda lakukan dalam tampilan Database default untuk bertindak pada database yang telah Anda pilih.
Tampilan hierarkis tampilan pohon dari cluster atau kelompok kerja, database, dan skema Anda. Di bawah skema, Anda dapat bekerja dengan tabel, tampilan, fungsi, dan prosedur tersimpan. Setiap objek dalam tampilan pohon mendukung menu konteks untuk melakukan tindakan terkait, seperti Refresh atau Drop, untuk objek.
Tindakan
 Buat untuk membuat database, skema, tabel, dan fungsi.
Buat untuk membuat database, skema, tabel, dan fungsi.Tindakan
 Muat data untuk memuat data dari Amazon S3 atau dari file lokal ke database Anda.
Muat data untuk memuat data dari Amazon S3 atau dari file lokal ke database Anda.Ikon
 Simpan untuk menyimpan kueri Anda.
Simpan untuk menyimpan kueri Anda. Ikon
 Pintasan untuk menampilkan pintasan keyboard untuk editor.
Pintasan untuk menampilkan pintasan keyboard untuk editor. Ikon
 Lainnya untuk menampilkan lebih banyak tindakan di editor. Seperti:
Lainnya untuk menampilkan lebih banyak tindakan di editor. Seperti: Bagikan dengan tim saya untuk membagikan kueri atau buku catatan dengan tim Anda. Untuk informasi selengkapnya, lihat Berkolaborasi dan berbagi sebagai sebuah tim.
Pintasan untuk menampilkan pintasan keyboard untuk editor.
Riwayat tab untuk menampilkan riwayat tab tab di editor.
Segarkan pelengkapan otomatis untuk menyegarkan saran yang ditampilkan saat membuat SQL.
Area
 Editor tempat Anda dapat memasukkan dan menjalankan kueri Anda.
Editor tempat Anda dapat memasukkan dan menjalankan kueri Anda. Setelah Anda menjalankan kueri, tab Hasil muncul dengan hasil. Di sinilah Anda dapat mengaktifkan Bagan untuk memvisualisasikan hasil Anda. Anda juga dapat mengekspor hasil Anda.
Area
Notebook tempat Anda dapat menambahkan bagian untuk masuk dan menjalankan SQL atau menambahkan Markdown. Setelah Anda menjalankan kueri, tab Hasil muncul dengan hasil. Di sinilah Anda dapat Mengekspor hasil Anda.
- Pertanyaan

Kueri berisi perintah SQL untuk mengelola dan menanyakan data Anda dalam database. Saat Anda menggunakan editor kueri v2 untuk memuat data sampel, itu juga membuat dan menyimpan kueri sampel untuk Anda.
Ketika Anda memilih kueri yang disimpan, Anda dapat membuka, mengganti nama, dan menghapusnya menggunakan menu konteks (klik kanan). Anda dapat melihat atribut seperti ARN Kueri dari kueri yang disimpan dengan memilih Detail kueri. Anda juga dapat melihat riwayat versinya, mengedit tag yang dilampirkan ke kueri, dan membagikannya dengan tim Anda.
- Notebook

Notebook SQL berisi sel SQL dan Markdown. Gunakan buku catatan untuk mengatur, membubuhi keterangan, dan berbagi beberapa perintah SQL dalam satu dokumen.
Ketika Anda memilih buku catatan yang disimpan, Anda dapat membuka, mengganti nama, menggandakan, dan menghapusnya menggunakan menu konteks (klik kanan). Anda dapat melihat atribut seperti ARN Notebook buku catatan yang disimpan dengan memilih detail Notebook. Anda juga dapat melihat riwayat versinya, mengedit tag yang dilampirkan ke buku catatan, mengekspornya, dan membagikannya dengan tim Anda. Untuk informasi selengkapnya, lihat Menulis dan menjalankan notebook.
- Grafik

Bagan adalah representasi visual dari data Anda. Editor kueri v2 menyediakan alat untuk membuat banyak jenis bagan dan menyimpannya.
Saat Anda memilih bagan yang disimpan, Anda dapat membuka, mengganti nama, dan menghapusnya menggunakan menu konteks (klik kanan). Anda dapat melihat atribut seperti Bagan ARN dari bagan yang disimpan dengan memilih Detail bagan. Anda juga dapat mengedit tag yang dilampirkan pada bagan dan mengekspornya. Untuk informasi selengkapnya, lihat Memvisualisasikan hasil kueri.
- Sejarah

Riwayat kueri adalah daftar kueri yang Anda jalankan menggunakan editor kueri Amazon Redshift v2. Kueri ini berjalan sebagai kueri individual atau sebagai bagian dari notebook SQL. Untuk informasi selengkapnya, lihat Melihat kueri dan riwayat tab.
- Pertanyaan terjadwal

Kueri terjadwal adalah kueri yang diatur untuk memulai pada waktu tertentu.
Semua tampilan editor kueri v2 memiliki ikon berikut:
Ikon mode
 Visual untuk beralih antara mode terang dan mode gelap.
Visual untuk beralih antara mode terang dan mode gelap.Ikon
 Pengaturan untuk menampilkan menu layar pengaturan yang berbeda.
Pengaturan untuk menampilkan menu layar pengaturan yang berbeda.Ikon preferensi
 Editor untuk mengedit preferensi Anda saat Anda menggunakan editor kueri v2. Di sini Anda dapat Mengedit pengaturan ruang kerja untuk mengubah ukuran font, ukuran tab, dan pengaturan tampilan lainnya. Anda juga dapat mengaktifkan (atau menonaktifkan) Pelengkapan Otomatis untuk menampilkan saran saat Anda memasukkan SQL Anda.
Editor untuk mengedit preferensi Anda saat Anda menggunakan editor kueri v2. Di sini Anda dapat Mengedit pengaturan ruang kerja untuk mengubah ukuran font, ukuran tab, dan pengaturan tampilan lainnya. Anda juga dapat mengaktifkan (atau menonaktifkan) Pelengkapan Otomatis untuk menampilkan saran saat Anda memasukkan SQL Anda.Ikon
 Connections untuk melihat koneksi yang digunakan oleh tab editor Anda.
Connections untuk melihat koneksi yang digunakan oleh tab editor Anda.Koneksi digunakan untuk mengambil data dari database. Koneksi dibuat untuk database tertentu. Dengan koneksi terisolasi, hasil perintah SQL yang mengubah database, seperti membuat tabel sementara, dalam satu tab editor, tidak terlihat di tab editor lain. Saat Anda membuka tab editor di editor kueri v2, defaultnya adalah koneksi terisolasi. Saat Anda membuat koneksi bersama, yaitu mematikan sakelar sesi terisolasi, maka hasil koneksi bersama lainnya ke database yang sama akan terlihat satu sama lain. Namun, tab editor yang menggunakan koneksi bersama ke database tidak berjalan secara paralel. Pertanyaan yang menggunakan koneksi yang sama harus menunggu hingga koneksi tersedia. Koneksi ke satu database tidak dapat dibagikan dengan database lain, dan dengan demikian hasil SQL tidak terlihat di seluruh koneksi database yang berbeda.
Jumlah koneksi yang dapat diaktifkan oleh pengguna di akun dikendalikan oleh administrator editor kueri v2.
Ikon Pengaturan
 akun yang digunakan oleh administrator untuk mengubah pengaturan tertentu dari semua pengguna di akun. Untuk informasi selengkapnya, lihat Mengubah pengaturan akun.
akun yang digunakan oleh administrator untuk mengubah pengaturan tertentu dari semua pengguna di akun. Untuk informasi selengkapnya, lihat Mengubah pengaturan akun.
Menghubungkan ke database Amazon Redshift
Untuk menyambung ke database, pilih nama cluster atau workgroup di panel tampilan pohon. Jika diminta, masukkan parameter koneksi.
Ketika Anda terhubung ke cluster atau workgroup dan database-nya, Anda biasanya memberikan nama Database. Anda juga menyediakan parameter yang diperlukan untuk salah satu metode otentikasi berikut:
- Pusat Identitas IAM
-
Dengan metode ini, sambungkan ke gudang data Amazon Redshift Anda dengan kredensi masuk tunggal Anda dari penyedia identitas (iDP) Anda. Cluster atau workgroup Anda harus diaktifkan untuk IAM Identity Center di konsol Amazon Redshift. Untuk bantuan menyiapkan koneksi ke Pusat Identitas IAM, lihatHubungkan Redshift dengan IAM Identity Center untuk memberi pengguna pengalaman masuk tunggal.
- Pengguna federasi
-
Dengan metode ini, tag utama peran IAM atau pengguna Anda harus memberikan detail koneksi. Anda mengonfigurasi tag ini di AWS Identity and Access Management atau penyedia identitas Anda (iDP). Editor kueri v2 bergantung pada tag berikut.
RedshiftDbUserTag ini mendefinisikan pengguna database yang digunakan oleh query editor v2. Tag ini diperlukan.RedshiftDbGroups— Tag ini mendefinisikan grup database yang bergabung saat menghubungkan ke editor kueri v2. Tag ini opsional dan nilainya harus berupa daftar yang dipisahkan titik dua seperti.group1:group2:group3Nilai kosong diabaikan, yaitu,group1::::group2ditafsirkan sebagaigroup1:group2.
Tag ini diteruskan ke
redshift:GetClusterCredentialsAPI untuk mendapatkan kredensil untuk klaster Anda. Untuk informasi selengkapnya, lihat Menyiapkan tag utama untuk menghubungkan cluster atau workgroup dari editor kueri v2. - Kredensi sementara menggunakan nama pengguna database
-
Opsi ini hanya tersedia saat menghubungkan ke cluster. Dengan metode ini, query editor v2, memberikan nama pengguna untuk database. Editor kueri v2 menghasilkan kata sandi sementara untuk terhubung ke database sebagai nama pengguna database Anda. Seorang pengguna yang menggunakan metode ini untuk terhubung harus diizinkan izin IAM untuk
redshift:GetClusterCredentials. Untuk mencegah pengguna menggunakan metode ini, ubah pengguna atau peran IAM mereka untuk menolak izin ini. - Kredensi sementara menggunakan identitas IAM Anda
-
Opsi ini hanya tersedia saat menghubungkan ke cluster. Dengan metode ini, editor kueri v2 memetakan nama pengguna ke identitas IAM Anda dan menghasilkan kata sandi sementara untuk terhubung ke database sebagai identitas IAM Anda. Seorang pengguna yang menggunakan metode ini untuk terhubung harus diizinkan izin IAM untuk
redshift:GetClusterCredentialsWithIAM. Untuk mencegah pengguna menggunakan metode ini, ubah pengguna atau peran IAM mereka untuk menolak izin ini. - Nama pengguna dan kata sandi basis data
-
Dengan metode ini, berikan juga nama Pengguna dan Kata Sandi untuk database yang Anda sambungkan. Editor kueri v2 membuat rahasia atas nama Anda yang disimpan di AWS Secrets Manager. Rahasia ini berisi kredensil untuk terhubung ke database Anda.
- AWS Secrets Manager
-
Dengan metode ini, alih-alih nama database, Anda memberikan Rahasia yang disimpan di Secrets Manager yang berisi database dan kredensi login Anda. Untuk informasi tentang membuat rahasia, lihatMembuat rahasia untuk kredensi koneksi database.
Ketika Anda memilih klaster atau workgroup dengan editor kueri v2, tergantung pada konteksnya, Anda dapat membuat, mengedit, dan menghapus koneksi menggunakan menu konteks (klik kanan). Anda dapat melihat atribut seperti ARN Koneksi koneksi dengan memilih Detail koneksi. Anda juga dapat mengedit tag yang dilampirkan ke koneksi.
Menjelajahi database Amazon Redshift
Dalam database, Anda dapat mengelola skema, tabel, tampilan, fungsi, dan prosedur tersimpan di panel tampilan pohon. Setiap objek dalam tampilan memiliki tindakan yang terkait dengannya dalam menu konteks (klik kanan).
Panel tampilan pohon hierarkis menampilkan objek database. Untuk me-refresh panel tampilan pohon untuk menampilkan objek database yang mungkin telah dibuat setelah tampilan pohon terakhir ditampilkan, pilih ikon.
 Buka menu konteks (klik kanan) untuk objek untuk melihat tindakan apa yang dapat Anda lakukan.
Buka menu konteks (klik kanan) untuk objek untuk melihat tindakan apa yang dapat Anda lakukan.
Setelah Anda memilih tabel, Anda dapat melakukan hal berikut:
Untuk memulai kueri di editor dengan pernyataan SELECT yang menanyakan semua kolom dalam tabel, gunakan Pilih tabel.
Untuk melihat atribut atau tabel, gunakan Tampilkan definisi tabel. Gunakan ini untuk melihat nama kolom, jenis kolom, pengkodean, kunci distribusi, kunci pengurutan, dan apakah kolom dapat berisi nilai nol. Untuk informasi selengkapnya tentang atribut tabel, lihat MEMBUAT TABEL di Panduan Pengembang Database Amazon Redshift.
Untuk menghapus tabel, gunakan Hapus. Anda dapat menggunakan tabel Truncate untuk menghapus semua baris dari tabel atau Drop table untuk menghapus tabel dari database. Untuk informasi selengkapnya, lihat TRUNCATE dan DROP TABLE di Panduan Pengembang Database Amazon Redshift.
Pilih skema untuk Refresh atau Drop schema.
Pilih tampilan untuk Tampilkan definisi tampilan atau Tampilan Jatuhkan.
Pilih fungsi untuk Tampilkan definisi fungsi atau fungsi Drop.
Pilih prosedur tersimpan untuk Tampilkan definisi prosedur atau prosedur Drop.
Membuat objek database
Anda dapat membuat objek database, termasuk database, skema, tabel, dan fungsi yang ditentukan pengguna (UDF). Anda harus terhubung ke cluster atau workgroup dan database untuk membuat objek database.
Membuat database
Anda dapat menggunakan query editor v2 untuk membuat database di cluster atau workgroup Anda.
Untuk membuat basis data
Untuk informasi tentang database, lihat MEMBUAT DATABASE di Panduan Pengembang Database Amazon Redshift.
Pilih
Buat, lalu pilih Database.Masukkan nama Database.
(Opsional) Pilih Pengguna dan grup, dan pilih pengguna Database.
(Opsional) Anda dapat membuat database dari datashare atau file. AWS Glue Data Catalog Untuk informasi lebih lanjut tentang AWS Glue, lihat Apa itu AWS Glue? di Panduan AWS Glue Pengembang.
(Opsional) Pilih Buat menggunakan datashare, dan pilih Pilih datashare. Daftar ini mencakup datashares produsen yang dapat digunakan untuk membuat datashare konsumen di cluster atau workgroup saat ini.
(Opsional) Pilih Buat menggunakan AWS Glue Data Catalog, dan pilih database Choose an AWS Glue. Dalam skema katalog Data, masukkan nama yang akan digunakan untuk skema saat mereferensikan data dalam nama tiga bagian (database.schema.table).
Pilih Buat basis data.
Database baru ditampilkan di panel tampilan pohon.
Bila Anda memilih langkah opsional untuk menanyakan database yang dibuat dari datashare, sambungkan ke database Amazon Redshift di cluster atau workgroup (misalnya, database default
dev), dan gunakan notasi tiga bagian (database.schema.table) yang mereferensikan nama database yang Anda buat saat memilih Buat menggunakan datashare. Database datasharing tercantum di tab editor editor kueri v2, tetapi tidak diaktifkan untuk koneksi langsung.Bila Anda memilih langkah opsional untuk menanyakan database yang dibuat dari AWS Glue Data Catalog, sambungkan ke database Amazon Redshift Anda di cluster atau grup kerja (misalnya, database default
dev), dan gunakan notasi tiga bagian (database.schema.table) yang mereferensikan nama database yang Anda buat saat Anda memilih Buat menggunakan AWS Glue Data Catalog, skema yang Anda beri nama dalam skema katalog Data, dan tabel di. AWS Glue Data Catalog Mirip dengan:SELECT * FROMglue-database.glue-schema.glue-tablecatatan
Konfirmasikan bahwa Anda terhubung ke database default menggunakan metode koneksi Kredensial sementara menggunakan identitas IAM Anda, dan bahwa kredenal IAM Anda telah diberikan hak penggunaan ke database. AWS Glue
GRANT USAGE ON DATABASEglue-databaseto "IAM:MyIAMUser"AWS Glue Basis data tercantum di tab editor kueri v2 editor, tetapi tidak diaktifkan untuk koneksi langsung.
Untuk informasi selengkapnya tentang kueri AWS Glue Data Catalog, lihat Bekerja dengan rangkaian data yang dikelola Lake Formation sebagai konsumen dan Bekerja dengan rangkaian data yang dikelola Lake Formation sebagai produsen di Panduan Pengembang Basis Data Amazon Redshift.
Contoh membuat database sebagai konsumen datashare
Contoh berikut menjelaskan skenario tertentu yang digunakan untuk membuat database dari datashare menggunakan query editor v2. Tinjau skenario ini untuk mempelajari cara membuat database dari datashare di lingkungan Anda. Skenario ini menggunakan dua cluster, cluster-base (cluster produsen) dan cluster-view (cluster konsumen).
Gunakan konsol Amazon Redshift untuk membuat datashare untuk tabel di cluster.
category2cluster-baseDatashare produser diberi nama.datashare_baseUntuk informasi tentang membuat rangkaian data, lihat Berbagi data di seluruh klaster di Amazon Redshift di Panduan Pengembang Database Amazon Redshift.
Gunakan konsol Amazon Redshift untuk menerima datashare
datashare_basesebagai konsumen untuk tabel di cluster.category2cluster-viewLihat panel tampilan pohon di editor kueri v2 yang menunjukkan hierarki sebagai:
cluster-baseKluster:
cluster-baseDatabase:
devSkema:
publicTabel:
category2
Pilih
Buat, lalu pilih Database.Masukkan
see_datashare_basenama Database.Pilih Buat menggunakan datashare, dan pilih Pilih datashare. Pilih
datashare_baseuntuk digunakan sebagai sumber database yang Anda buat.Panel tampilan pohon di editor kueri v2 menunjukkan hierarki sebagai:
cluster-viewKluster:
cluster-viewDatabase:
see_datashare_baseSkema:
publicTabel:
category2
Saat Anda menanyakan data, sambungkan ke database default cluster
cluster-view(biasanya bernamadev), tetapi referensi database datasharesee_datashare_basedi SQL Anda.catatan
Dalam tampilan editor editor kueri v2, cluster yang dipilih adalah
cluster-view. Database yang dipilih adalahdev. Databasesee_datashare_baseterdaftar tetapi tidak diaktifkan untuk koneksi langsung. Anda memilihdevdatabase dan referensisee_datashare_basedi SQL yang Anda jalankan.SELECT * FROM "see_datashare_base"."public"."category2";Query mengambil data dari datashare
datashare_basedi cluster.cluster_base
Contoh membuat database dari AWS Glue Data Catalog
Contoh berikut menjelaskan skenario tertentu yang digunakan untuk membuat database dari AWS Glue Data Catalog menggunakan editor query v2. Tinjau skenario ini untuk mempelajari cara membuat database dari AWS Glue Data Catalog lingkungan Anda. Skenario ini menggunakan satu cluster, cluster-view untuk memuat database yang Anda buat.
Pilih
Buat, lalu pilih Database.Masukkan
data_catalog_databasenama Database.Pilih Buat menggunakan AWS Glue Data Catalog, dan pilih Pilih AWS Glue database. Pilih
glue_dbuntuk digunakan sebagai sumber database yang Anda buat.Pilih Skema katalog data dan masukkan
myschemasebagai nama skema yang akan digunakan dalam notasi tiga bagian.Panel tampilan pohon di editor kueri v2 menunjukkan hierarki sebagai:
cluster-viewKluster:
cluster-viewDatabase:
data_catalog_databaseSkema:
myschemaTabel:
category3
Saat Anda menanyakan data, sambungkan ke database default cluster
cluster-view(biasanya bernamadev), tetapi referensi databasedata_catalog_databasedi SQL Anda.catatan
Dalam tampilan editor editor kueri v2, cluster yang dipilih adalah
cluster-view. Database yang dipilih adalahdev. Databasedata_catalog_databaseterdaftar tetapi tidak diaktifkan untuk koneksi langsung. Anda memilihdevdatabase dan referensidata_catalog_databasedi SQL yang Anda jalankan.SELECT * FROM "data_catalog_database"."myschema"."category3";Kueri mengambil data yang dikatalogkan oleh. AWS Glue Data Catalog
Membuat skema
Anda dapat menggunakan editor kueri v2 untuk membuat skema di cluster atau grup kerja Anda.
Untuk membuat skema
Untuk informasi tentang skema, lihat Skema di Panduan Pengembang Database Amazon Redshift.
Pilih
Buat, lalu pilih Skema.Masukkan nama Skema.
Pilih Lokal atau Eksternal sebagai tipe Skema.
Untuk informasi selengkapnya tentang skema lokal, lihat MEMBUAT SKEMA di Panduan Pengembang Database Amazon Redshift. Untuk informasi selengkapnya tentang skema eksternal, lihat MEMBUAT SKEMA EKSTERNAL di Panduan Pengembang Database Amazon Redshift.
Jika Anda memilih Eksternal, maka Anda memiliki pilihan skema eksternal berikut.
Glue Data Catalog — untuk membuat skema eksternal di Amazon Redshift yang mereferensikan tabel. AWS Glue Selain memilih AWS Glue database, pilih peran IAM yang terkait dengan cluster dan peran IAM yang terkait dengan Katalog Data.
PostgreSQL — untuk membuat skema eksternal di Amazon Redshift yang mereferensikan database Amazon RDS for PostgreSQL atau Amazon Aurora PostgreSQL Edition yang kompatibel. Juga berikan informasi koneksi ke database. Untuk informasi selengkapnya tentang kueri federasi, lihat Mengkueri data dengan kueri gabungan di Panduan Pengembang Database Amazon Redshift.
MySQL — untuk membuat skema eksternal di Amazon Redshift yang mereferensikan Amazon RDS untuk MySQL atau dan database Amazon Aurora MySQL Edisi yang kompatibel. Juga berikan informasi koneksi ke database. Untuk informasi selengkapnya tentang kueri federasi, lihat Mengkueri data dengan kueri gabungan di Panduan Pengembang Database Amazon Redshift.
Pilih Buat skema.
Skema baru muncul di panel tampilan pohon.
Membuat tabel
Anda dapat menggunakan editor kueri v2 untuk membuat tabel di cluster atau workgroup Anda.
Untuk membuat tabel
Anda dapat membuat tabel berdasarkan file nilai dipisahkan koma (CSV) yang Anda tentukan atau tentukan setiap kolom tabel. Untuk informasi tentang tabel, lihat Merancang tabel dan MEMBUAT TABEL di Panduan Pengembang Database Amazon Redshift.
Pilih Buka kueri di editor untuk melihat dan mengedit pernyataan CREATE TABLE sebelum Anda menjalankan kueri untuk membuat tabel.
Pilih
Buat, dan pilih Tabel.Pilih skema.
Masukkan nama tabel.
Pilih
Tambahkan bidang untuk menambahkan kolom. Gunakan file CSV sebagai templat untuk definisi tabel:
Pilih Load dari CSV.
Jelajahi lokasi file.
Jika Anda menggunakan file CSV, pastikan baris pertama file berisi judul kolom.
Pilih file dan pilih Buka. Konfirmasikan bahwa nama kolom dan tipe data adalah apa yang Anda inginkan.
Untuk setiap kolom, pilih kolom dan pilih opsi yang Anda inginkan:
Pilih nilai untuk Encoding.
Pilih nilai Default.
Aktifkan Kenaikan secara otomatis jika Anda ingin nilai kolom bertambah. Kemudian tentukan nilai untuk benih kenaikan Otomatis dan langkah kenaikan Otomatis.
Aktifkan Not NULL jika kolom harus selalu berisi nilai.
Masukkan nilai Ukuran untuk kolom.
Aktifkan kunci utama jika Anda ingin kolom menjadi kunci utama.
Aktifkan tombol Unik jika Anda ingin kolom menjadi kunci unik.
(Opsional) Pilih detail Tabel dan pilih salah satu opsi berikut:
Kolom dan gaya kunci distribusi.
Urutkan kolom kunci dan jenis sortir.
Aktifkan Backup untuk menyertakan tabel dalam snapshot.
Nyalakan Tabel sementara untuk membuat tabel sebagai tabel sementara.
Pilih Buka kueri di editor untuk melanjutkan menentukan opsi untuk menentukan tabel atau pilih Buat tabel untuk membuat tabel.
Membuat fungsi
Anda dapat menggunakan query editor v2 untuk membuat fungsi di cluster atau workgroup Anda.
Untuk membuat fungsi
Pilih
Create, dan pilih Function.Untuk Type, pilih SQL atau Python.
Pilih nilai untuk Skema.
Masukkan nilai untuk Nama untuk fungsi tersebut.
Masukkan nilai Volatilitas untuk fungsi tersebut.
Pilih Parameter berdasarkan tipe datanya sesuai urutan parameter input.
Untuk Pengembalian, pilih tipe data.
Masukkan program SQL atau kode program Python untuk fungsi tersebut.
Pilih Buat.
Untuk informasi selengkapnya tentang fungsi yang ditentukan pengguna (UDF), lihat Membuat fungsi yang ditentukan pengguna di Panduan Pengembang Database Amazon Redshift.
Melihat kueri dan riwayat tab
Anda dapat melihat riwayat kueri Anda dengan editor kueri v2. Hanya kueri yang Anda jalankan menggunakan editor kueri v2 yang muncul di riwayat kueri. Kedua kueri yang dijalankan dari menggunakan tab Editor atau tab Notebook ditampilkan. Anda dapat memfilter daftar yang ditampilkan berdasarkan periode waktu, sepertiThis week, di mana seminggu didefinisikan sebagai Senin-Minggu. Daftar kueri mengambil 25 baris kueri yang cocok dengan filter Anda sekaligus. Pilih Muat lebih banyak untuk melihat set berikutnya. Pilih kueri dan dari menu Tindakan. Tindakan yang tersedia tergantung pada apakah kueri yang dipilih telah disimpan. Anda dapat memilih operasi berikut:
Lihat detail kueri - Menampilkan halaman detail kueri dengan informasi lebih lanjut tentang kueri yang dijalankan.
Buka kueri di tab baru — Membuka tab editor baru dan memasangnya dengan kueri yang dipilih. Jika masih terhubung, cluster atau workgroup dan database dipilih secara otomatis. Untuk menjalankan kueri, pertama-tama konfirmasikan bahwa cluster atau workgroup dan database yang benar dipilih.
Tab sumber terbuka — Jika masih terbuka, navigasikan ke tab editor atau buku catatan yang berisi kueri saat dijalankan. Isi editor atau buku catatan mungkin telah berubah setelah kueri dijalankan.
Buka kueri tersimpan — Menavigasi ke tab editor atau buku catatan dan membuka kueri.
Anda juga dapat melihat riwayat kueri yang dijalankan di tab Editor atau riwayat kueri yang dijalankan di tab Notebook. Untuk melihat riwayat kueri di tab, pilih Riwayat tab. Dalam riwayat tab, Anda dapat melakukan operasi berikut:
Salin kueri - Menyalin konten SQL versi kueri ke clipboard.
Buka kueri di tab baru — Membuka tab editor baru dan memasangnya dengan kueri yang dipilih. Untuk menjalankan query, Anda harus memilih cluster atau workgroup dan database.
Lihat detail kueri - Menampilkan halaman detail kueri dengan informasi lebih lanjut tentang kueri yang dijalankan.
Pertimbangan saat bekerja dengan editor kueri v2
Pertimbangkan hal berikut saat bekerja dengan editor kueri v2.
Ukuran hasil kueri maksimum adalah yang lebih kecil dari 5 MB atau 100.000 baris.
Anda dapat menjalankan kueri hingga 300.000 karakter.
Anda dapat menyimpan kueri hingga 30.000 karakter.
Secara default, editor kueri v2 secara otomatis melakukan setiap perintah SQL individual yang berjalan. Ketika pernyataan BEGIN disediakan, pernyataan dalam blok BEGIN-COMMIT atau BEGIN-ROLLBACK dijalankan sebagai satu transaksi. Untuk informasi selengkapnya tentang transaksi, lihat MULAI di Panduan Pengembang Database Amazon Redshift.
Jumlah maksimum peringatan yang ditampilkan oleh editor kueri v2 saat menjalankan pernyataan SQL adalah.
10Misalnya, ketika prosedur tersimpan dijalankan, tidak lebih dari 10 pernyataan RAISE ditampilkan.Editor kueri v2 tidak mendukung IAM
RoleSessionNameyang berisi koma (,). Anda mungkin melihat kesalahan yang mirip dengan berikut ini:Pesan Kesalahan: “'aroa123456789Example:MyText, yourtext' bukan nilai yang valid untuk TagValue - ini berisi karakter ilegal”Masalah ini muncul saat Anda mendefinisikan IAM yang menyertakan koma dan kemudian menggunakan editor kueri v2 dengan peran IAMRoleSessionNametersebut.Untuk informasi selengkapnya tentang IAM
RoleSessionName, lihat atribut RoleSessionName SAMP di Panduan Pengguna IAM.
Mengubah pengaturan akun
Pengguna dengan izin IAM yang tepat dapat melihat dan mengubah pengaturan Akun untuk pengguna lain dalam hal yang sama. Akun AWS Administrator ini dapat melihat atau mengatur hal-hal berikut:
Koneksi database bersamaan maksimum per pengguna di akun. Ini termasuk koneksi untuk sesi Terisolasi. Saat Anda mengubah nilai ini, perlu waktu 10 menit agar perubahan diterapkan.
Izinkan pengguna di akun untuk mengekspor seluruh hasil yang ditetapkan dari perintah SQL ke file.
Muat dan tampilkan database sampel dengan beberapa kueri tersimpan terkait.
Tentukan jalur Amazon S3 yang digunakan oleh pengguna akun untuk memuat data dari file lokal.
Lihat ARN kunci KMS yang digunakan untuk mengenkripsi sumber daya editor kueri v2.
