Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Lihat laporan kinerja model Autopilot
Laporan kualitas SageMaker model Amazon (juga disebut sebagai laporan kinerja) memberikan wawasan dan informasi kualitas untuk kandidat model terbaik yang dihasilkan oleh pekerjaan AutoML. Ini termasuk informasi tentang detail pekerjaan, jenis masalah model, fungsi tujuan, dan informasi lain yang terkait dengan jenis masalah. Panduan ini menunjukkan cara melihat metrik kinerja Amazon SageMaker Autopilot secara grafis, atau melihat metrik sebagai data mentah dalam file. JSON
Misalnya, dalam masalah klasifikasi, laporan kualitas model meliputi yang berikut:
-
Matriks kebingungan
-
Area di bawah kurva karakteristik operasi penerima (AUC)
-
Informasi untuk memahami positif palsu dan negatif palsu
-
Pengorbanan antara positif benar dan positif palsu
-
Pengorbanan antara presisi dan penarikan
Autopilot juga menyediakan metrik kinerja untuk semua model kandidat Anda. Metrik ini dihitung menggunakan semua data pelatihan dan digunakan untuk memperkirakan kinerja model. Area kerja utama mencakup metrik ini secara default. Jenis metrik ditentukan oleh jenis masalah yang ditangani.
Lihat dokumentasi SageMaker API referensi Amazon untuk daftar metrik yang tersedia yang didukung oleh Autopilot.
Anda dapat mengurutkan kandidat model Anda dengan metrik yang relevan untuk membantu Anda memilih dan menerapkan model yang memenuhi kebutuhan bisnis Anda. Untuk definisi metrik ini, lihat topik metrik kandidat Autopilot.
Untuk melihat laporan kinerja dari pekerjaan Autopilot, ikuti langkah-langkah berikut:
-
Pilih ikon Beranda (
 ) dari panel navigasi kiri untuk melihat menu navigasi Amazon SageMaker Studio Classic tingkat atas.
) dari panel navigasi kiri untuk melihat menu navigasi Amazon SageMaker Studio Classic tingkat atas. -
Pilih kartu AutoML dari area kerja utama. Ini membuka tab Autopilot baru.
-
Di bagian Nama, pilih pekerjaan Autopilot yang memiliki detail yang ingin Anda periksa. Ini membuka tab pekerjaan Autopilot baru.
-
Panel pekerjaan Autopilot mencantumkan nilai metrik termasuk metrik Objektif untuk setiap model di bawah nama Model. Model Terbaik tercantum di bagian atas daftar di bawah nama Model dan disorot di tab Model.
-
Untuk meninjau detail model, pilih model yang Anda minati dan pilih Lihat dalam detail model. Ini membuka tab Detail Model baru.
-
-
Pilih tab Performance antara tab Explainability dan Artefacts.
-
Di bagian kanan atas tab, pilih panah bawah pada tombol Unduh Laporan Kinerja.
-
Panah bawah menyediakan dua opsi untuk melihat metrik kinerja Autopilot:
-
Anda dapat mengunduh laporan kinerja untuk melihat metrik secara grafis. PDF
-
Anda dapat melihat metrik sebagai data mentah dan mengunduhnya sebagai JSON file.
-
-
Untuk petunjuk tentang cara membuat dan menjalankan pekerjaan AutoML di SageMaker Studio Classic, lihat. Buat Pekerjaan Regresi atau Klasifikasi untuk Data Tabular Menggunakan AutoML API
Laporan kinerja berisi dua bagian. Yang pertama berisi detail tentang pekerjaan Autopilot yang menghasilkan model. Bagian kedua berisi laporan kualitas model.
Autopilot Job Detail
Bagian pertama dari laporan ini memberikan beberapa informasi umum tentang pekerjaan Autopilot yang menghasilkan model. Rincian pekerjaan ini mencakup informasi berikut:
-
Nama kandidat autopilot
-
Nama pekerjaan Autopilot
-
Jenis masalah
-
Metrik obyektif
-
Arah optimasi
Laporan kualitas model
Informasi kualitas model dihasilkan oleh wawasan model Autopilot. Konten laporan yang dihasilkan bergantung pada jenis masalah yang ditangani: regresi, klasifikasi biner, atau klasifikasi multikelas. Laporan tersebut menentukan jumlah baris yang termasuk dalam dataset evaluasi dan waktu evaluasi terjadi.
Tabel metrik
Bagian pertama dari laporan kualitas model berisi tabel metrik. Ini sesuai untuk jenis masalah yang ditangani model.
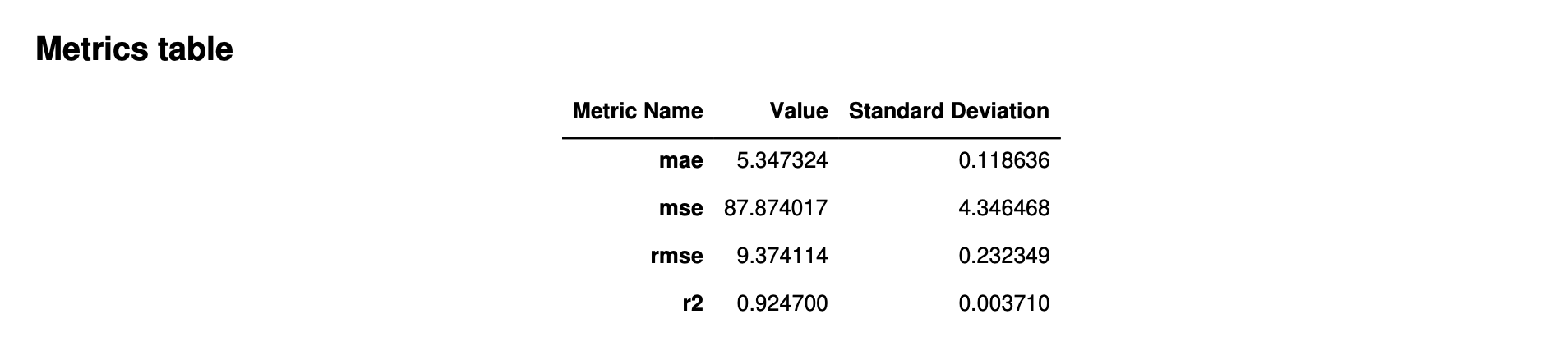
Gambar berikut adalah contoh tabel metrik yang dihasilkan Autopilot untuk masalah regresi. Ini menunjukkan nama metrik, nilai, dan standar deviasi.
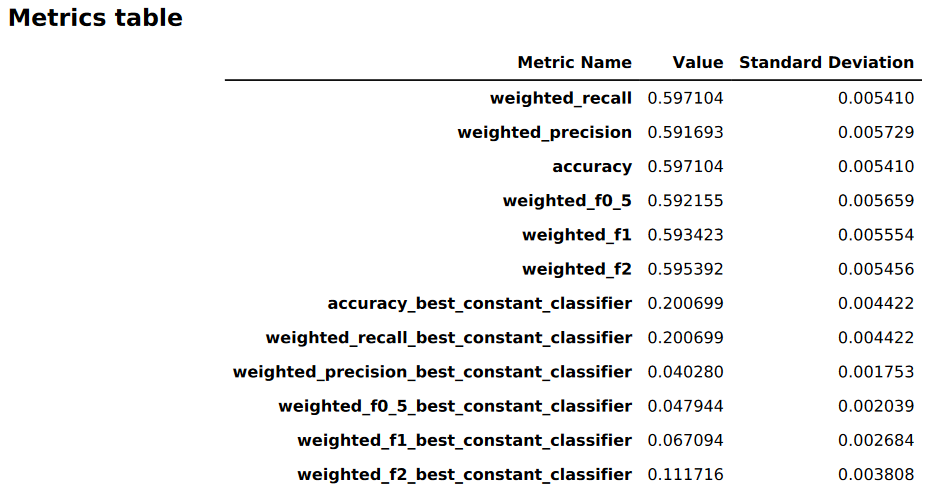
Gambar berikut adalah contoh tabel metrik yang dihasilkan oleh Autopilot untuk masalah klasifikasi multiclass. Ini menunjukkan nama metrik, nilai, dan standar deviasi.
Informasi kinerja model grafis
Bagian kedua dari laporan kualitas model berisi informasi grafis untuk membantu Anda mengevaluasi kinerja model. Isi bagian ini tergantung pada jenis masalah yang digunakan dalam pemodelan.
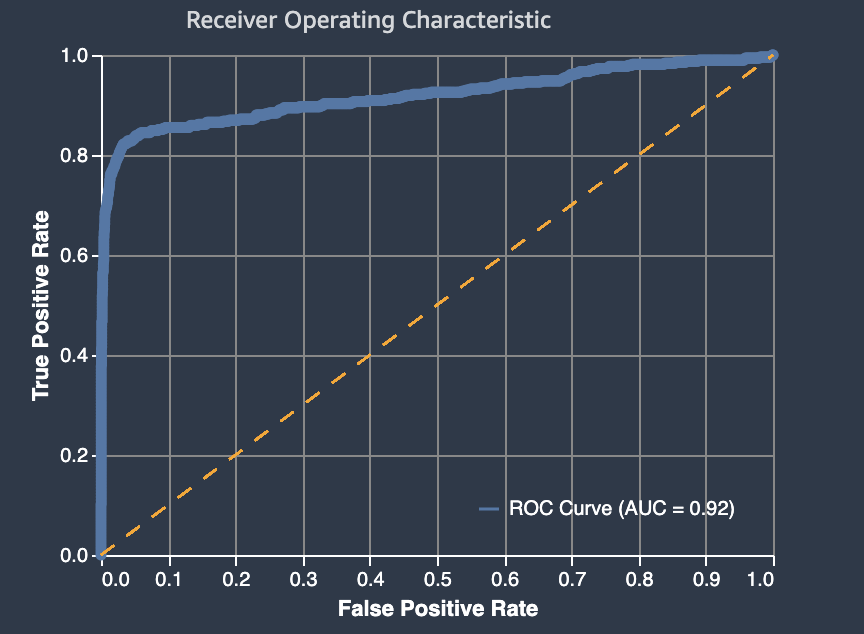
Area di bawah kurva karakteristik operasi penerima
Area di bawah kurva karakteristik operasi penerima mewakili trade-off antara tingkat positif benar dan positif palsu. Ini adalah metrik akurasi standar industri yang digunakan untuk model klasifikasi biner. AUC(area di bawah kurva) mengukur kemampuan model untuk memprediksi skor yang lebih tinggi untuk contoh positif, dibandingkan dengan contoh negatif. AUCMetrik memberikan ukuran agregat kinerja model di semua ambang batas klasifikasi yang mungkin.
AUCMetrik mengembalikan nilai desimal dari 0 ke 1. AUCnilai mendekati 1 menunjukkan bahwa model pembelajaran mesin sangat akurat. Nilai mendekati 0,5 menunjukkan bahwa model berkinerja tidak lebih baik daripada menebak secara acak. AUCNilai mendekati 0 menunjukkan bahwa model telah mempelajari pola yang benar, tetapi membuat prediksi yang seakurat mungkin. Nilai mendekati nol dapat menunjukkan masalah dengan data. Untuk informasi selengkapnya tentang AUC metrik, lihat artikel Karakteristik operasi Penerima
Berikut ini adalah contoh area di bawah grafik kurva karakteristik operasi penerima untuk mengevaluasi prediksi yang dibuat oleh model klasifikasi biner. Garis tipis putus-putus mewakili area di bawah kurva karakteristik operasi penerima yang akan dinilai oleh model yang mengklasifikasikan no-better-than-random tebakan, dengan skor 0,5. AUC Kurva model klasifikasi yang lebih akurat terletak di atas garis dasar acak ini, di mana tingkat positif sejati melebihi tingkat positif palsu. Area di bawah kurva karakteristik operasi penerima yang mewakili kinerja model klasifikasi biner adalah garis padat yang lebih tebal.
Ringkasan komponen grafik dari tingkat positif palsu (FPR) dan tingkat positif sejati (TPR) didefinisikan sebagai berikut.
-
Prediksi yang benar
-
True positive (TP): Nilai yang diprediksi adalah 1, dan nilai sebenarnya adalah 1.
-
Benar negatif (TN): Nilai yang diprediksi adalah 0, dan nilai sebenarnya adalah 0.
-
-
Prediksi yang salah
-
Positif palsu (FP): Nilai yang diprediksi adalah 1, tetapi nilai sebenarnya adalah 0.
-
False negative (FN): Nilai yang diprediksi adalah 0, tetapi nilai sebenarnya adalah 1.
-
Tingkat positif palsu (FPR) mengukur fraksi negatif sejati (TN) yang diprediksi secara salah sebagai positif (FP), atas jumlah FP dan TN. Kisarannya adalah 0 hingga 1. Nilai yang lebih kecil menunjukkan akurasi prediksi yang lebih baik.
-
FPR= FP/ (FP+TN)
Tingkat positif sejati (TPR) mengukur fraksi positif sejati yang diprediksi dengan benar sebagai positif (TP) atas jumlah TP dan negatif palsu (FN). Kisarannya adalah 0 hingga 1. Nilai yang lebih besar menunjukkan akurasi prediksi yang lebih baik.
-
TPR= TP/ (TP+FN)
Matriks kebingungan
Matriks kebingungan menyediakan cara untuk memvisualisasikan keakuratan prediksi yang dibuat oleh model untuk klasifikasi biner dan multikelas untuk masalah yang berbeda. Matriks kebingungan dalam laporan kualitas model berisi yang berikut ini.
-
Jumlah dan persentase prediksi yang benar dan salah untuk label yang sebenarnya
-
Jumlah dan persentase prediksi akurat pada diagonal dari kiri atas ke pojok kanan bawah
-
Jumlah dan persentase prediksi yang tidak akurat pada diagonal dari kanan atas ke sudut kiri bawah
Prediksi yang salah pada matriks kebingungan adalah nilai kebingungan.
Diagram berikut adalah contoh matriks kebingungan untuk masalah klasifikasi biner. Itu berisi informasi berikut:
-
Sumbu vertikal dibagi menjadi dua baris yang berisi label aktual benar dan salah.
-
Sumbu horizontal dibagi menjadi dua kolom yang berisi label benar dan salah yang diprediksi oleh model.
-
Bilah warna memberikan nada yang lebih gelap ke sejumlah besar sampel untuk secara visual menunjukkan jumlah nilai yang diklasifikasikan dalam setiap kategori.
Dalam contoh ini, model memprediksi 2817 nilai palsu aktual dengan benar, dan 353 nilai sebenarnya sebenarnya dengan benar. Model salah memprediksi 130 nilai sebenarnya sebenarnya menjadi salah dan 33 nilai palsu aktual menjadi benar. Perbedaan nada menunjukkan bahwa dataset tidak seimbang. Ketidakseimbangan ini karena ada lebih banyak label palsu yang sebenarnya daripada label sebenarnya.
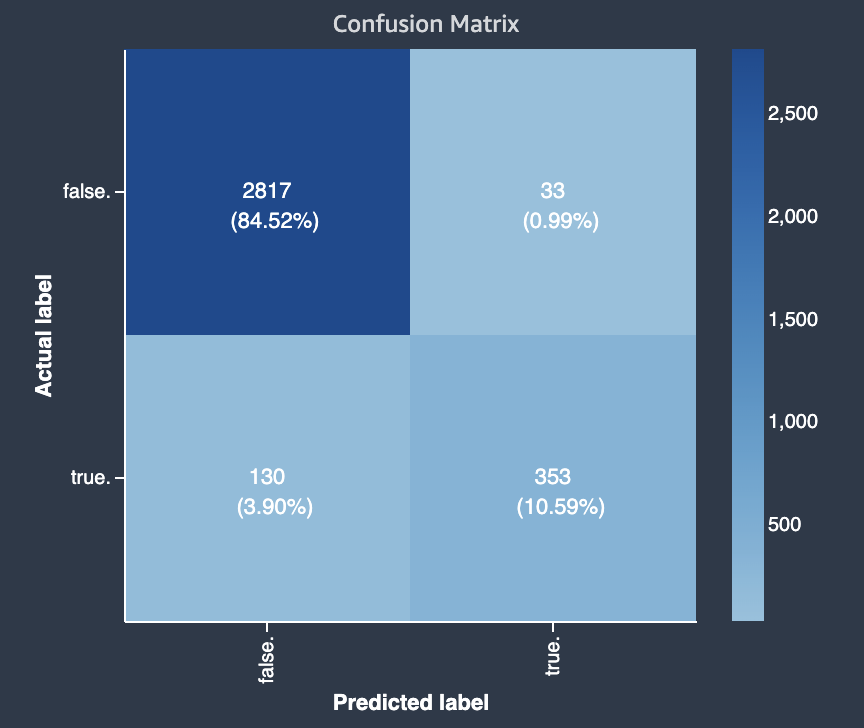
Diagram berikut adalah contoh matriks kebingungan untuk masalah klasifikasi multi-kelas. Matriks kebingungan dalam laporan kualitas model berisi yang berikut ini.
-
Sumbu vertikal dibagi menjadi tiga baris yang berisi tiga label aktual yang berbeda.
-
Sumbu horizontal dibagi menjadi tiga kolom yang berisi label yang diprediksi oleh model.
-
Bilah warna memberikan nada yang lebih gelap ke sejumlah besar sampel untuk secara visual menunjukkan jumlah nilai yang diklasifikasikan dalam setiap kategori.
Dalam contoh di bawah ini, model dengan benar memprediksi 354 nilai aktual untuk label f, 1094 nilai untuk label i dan 852 nilai untuk label m. Perbedaan nada menunjukkan bahwa kumpulan data tidak seimbang karena ada lebih banyak label untuk nilai i daripada untuk f atau m.
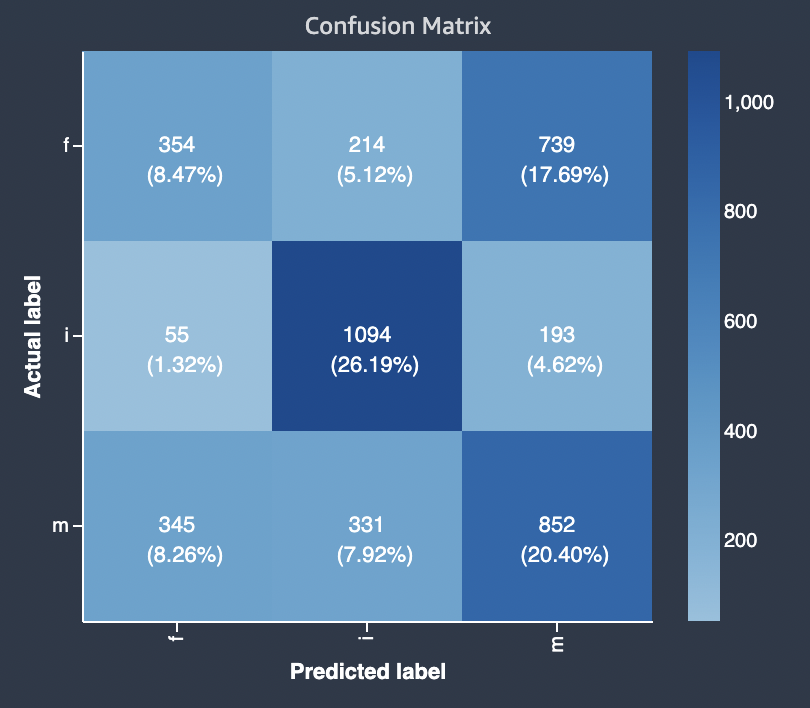
Matriks kebingungan dalam laporan kualitas model yang disediakan dapat mengakomodasi maksimum 15 label untuk jenis masalah klasifikasi multikelas. Jika baris yang sesuai dengan label menunjukkan Nan nilai, itu berarti kumpulan data validasi yang digunakan untuk memeriksa prediksi model tidak berisi data dengan label tersebut.
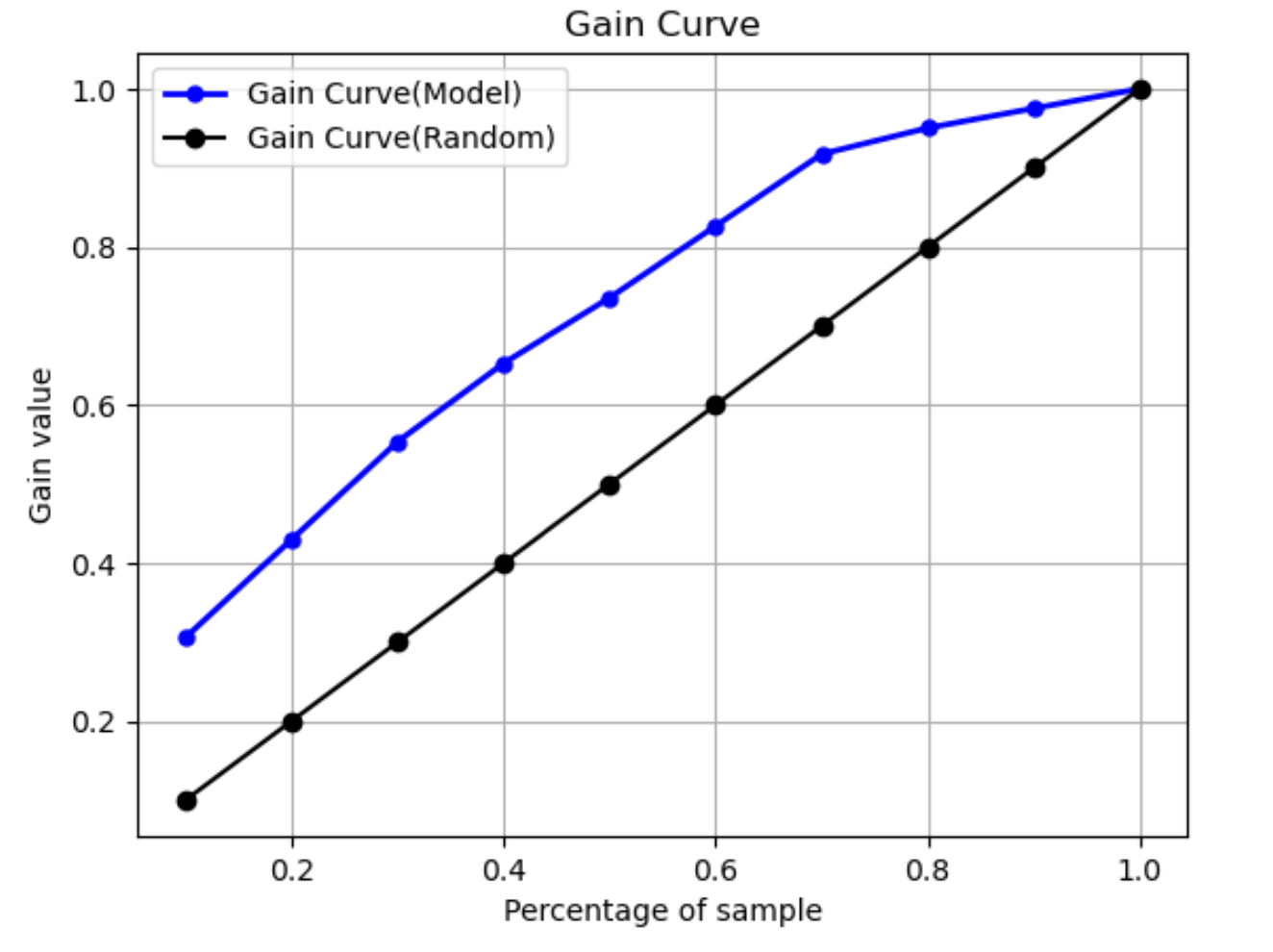
Kurva keuntungan
Dalam klasifikasi biner, kurva penguatan memprediksi manfaat kumulatif menggunakan persentase kumpulan data untuk menemukan label positif. Nilai gain dihitung selama pelatihan dengan membagi jumlah kumulatif pengamatan positif dengan jumlah total pengamatan positif dalam data, pada setiap desil. Jika model klasifikasi yang dibuat selama pelatihan mewakili data yang tidak terlihat, Anda dapat menggunakan kurva penguatan untuk memprediksi persentase data yang harus Anda targetkan untuk mendapatkan persentase label positif. Semakin besar persentase dataset yang digunakan, semakin tinggi persentase label positif yang ditemukan.
Dalam contoh grafik berikut, kurva penguatan adalah garis dengan kemiringan yang berubah. Garis lurus adalah persentase label positif yang ditemukan dengan memilih persentase data dari kumpulan data secara acak. Setelah menargetkan 20% dari kumpulan data, Anda akan menemukan lebih besar dari 40% label positif. Misalnya, Anda dapat mempertimbangkan untuk menggunakan kurva keuntungan untuk menentukan upaya Anda dalam kampanye pemasaran. Menggunakan contoh kurva keuntungan kami, untuk 83% orang di lingkungan untuk membeli cookie, Anda akan mengirim iklan ke sekitar 60% dari lingkungan sekitar.
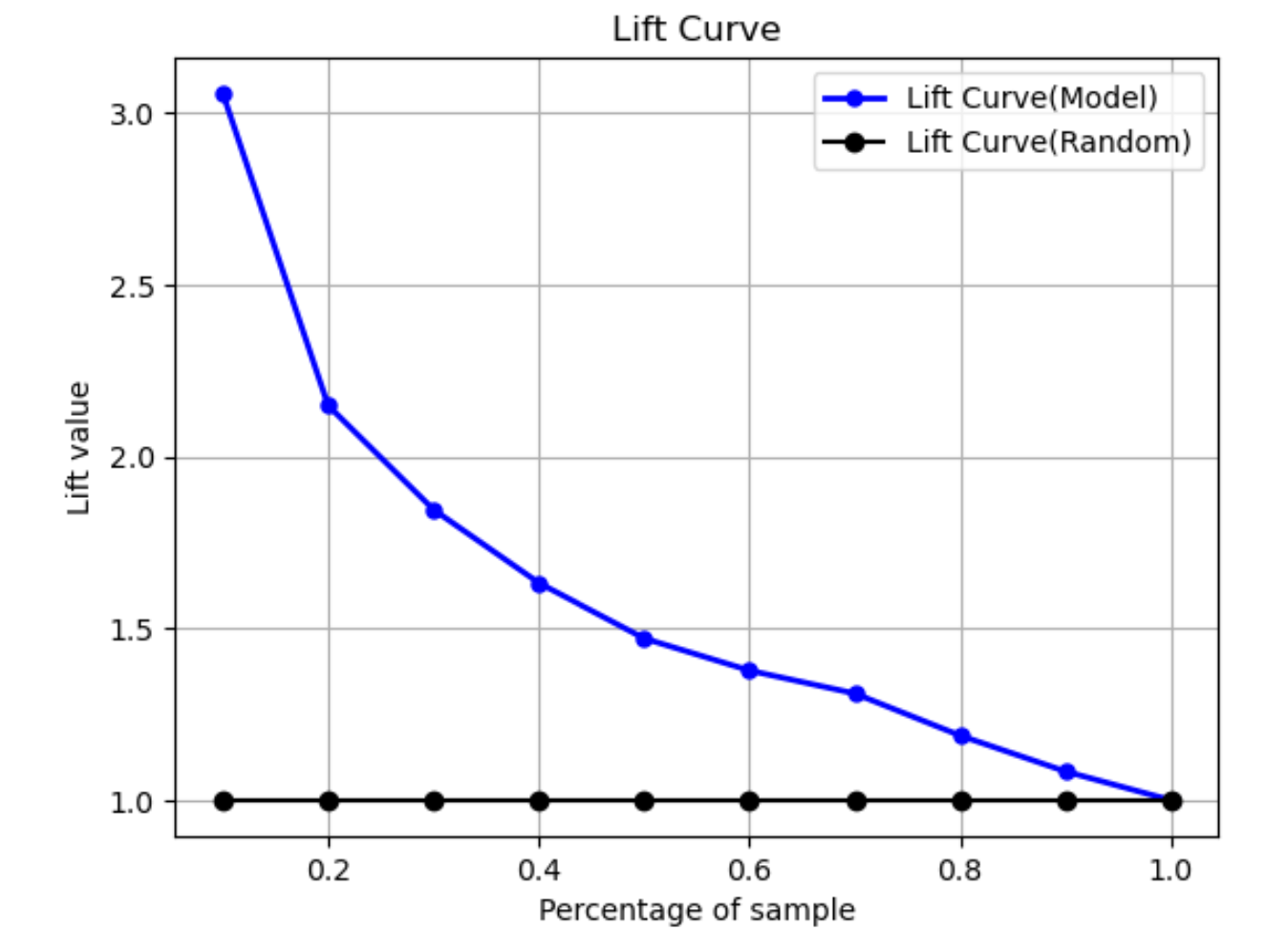
Kurva angkat
Dalam klasifikasi biner, kurva angkat menggambarkan peningkatan menggunakan model terlatih untuk memprediksi kemungkinan menemukan label positif dibandingkan dengan tebakan acak. Nilai angkat dihitung selama pelatihan menggunakan rasio kenaikan persentase dengan rasio label positif pada setiap desil. Jika model yang dibuat selama pelatihan mewakili data yang tidak terlihat, gunakan kurva angkat untuk memprediksi manfaat menggunakan model daripada menebak secara acak.
Pada contoh grafik berikut, kurva angkat adalah garis dengan kemiringan yang berubah. Garis lurus adalah kurva angkat yang terkait dengan pemilihan persentase yang sesuai secara acak dari kumpulan data. Setelah menargetkan 40% kumpulan data dengan label klasifikasi model Anda, Anda akan menemukan sekitar 1,7 kali jumlah label positif yang akan Anda temukan dengan memilih secara acak 40% dari data yang tidak terlihat.
Kurva penarikan presisi
Kurva recall presisi mewakili tradeoff antara presisi dan recall untuk masalah klasifikasi biner.
Presisi mengukur fraksi positif aktual yang diprediksi positif (TP) dari semua prediksi positif (TP dan positif palsu). Kisarannya adalah 0 hingga 1. Nilai yang lebih besar menunjukkan akurasi yang lebih baik dalam nilai yang diprediksi.
-
Presisi = TP/ (TP+FP)
Ingat mengukur fraksi positif aktual yang diprediksi sebagai positif (TP) dari semua prediksi positif aktual (TP dan negatif palsu). Ini juga dikenal sebagai sensitivitas atau sebagai tingkat positif sejati. Kisarannya adalah 0 hingga 1. Nilai yang lebih besar menunjukkan deteksi nilai positif yang lebih baik dari sampel.
-
Ingat = TP/ (TP+FN)
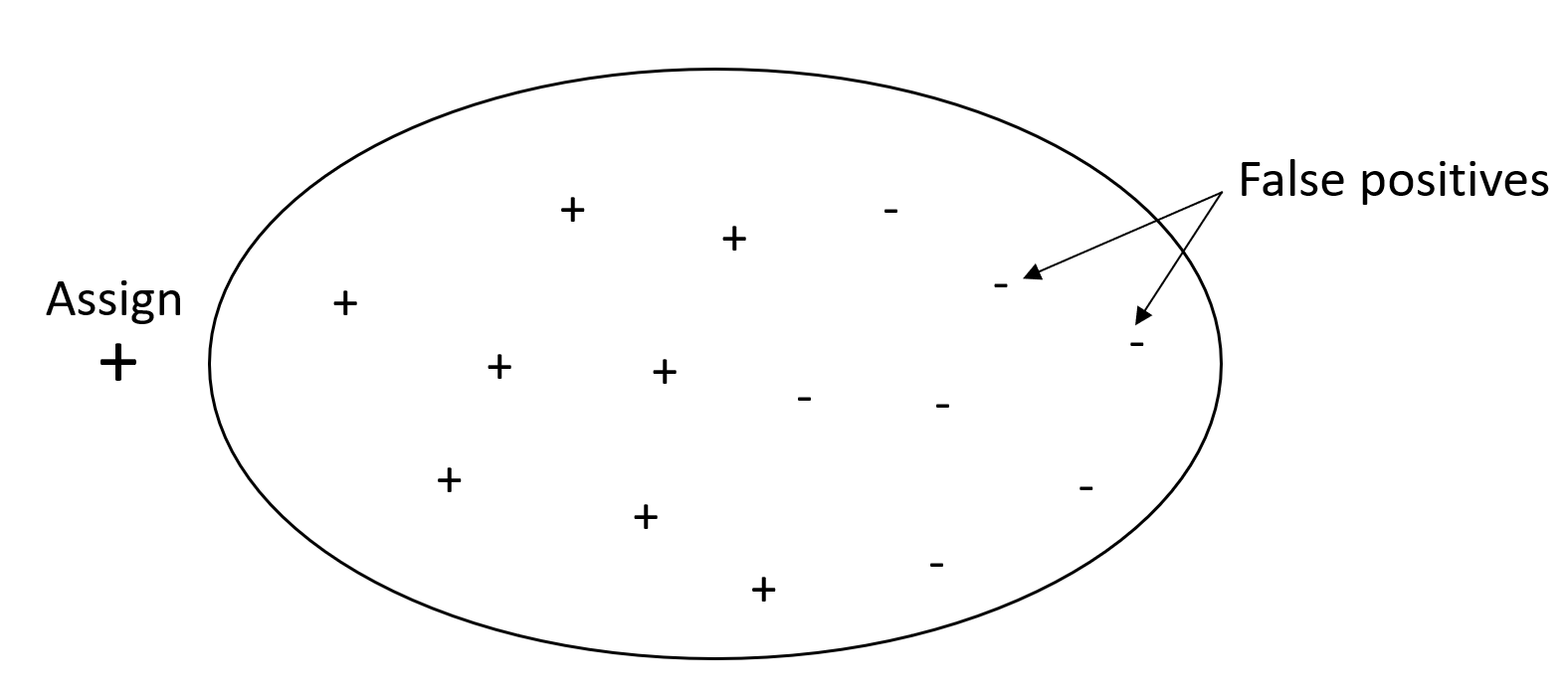
Tujuan dari masalah klasifikasi adalah untuk memberi label dengan benar sebanyak mungkin elemen. Sebuah sistem dengan recall tinggi tetapi presisi rendah mengembalikan persentase positif palsu yang tinggi.
Grafik berikut menggambarkan filter spam yang menandai setiap email sebagai spam. Ini memiliki daya ingat tinggi, tetapi presisi rendah, karena mengingat tidak mengukur positif palsu.
Berikan lebih banyak bobot untuk mengingat lebih presisi jika masalah Anda memiliki penalti rendah untuk nilai positif palsu, tetapi penalti tinggi karena kehilangan hasil positif yang sebenarnya. Misalnya, mendeteksi tabrakan yang akan datang di kendaraan self-driving.
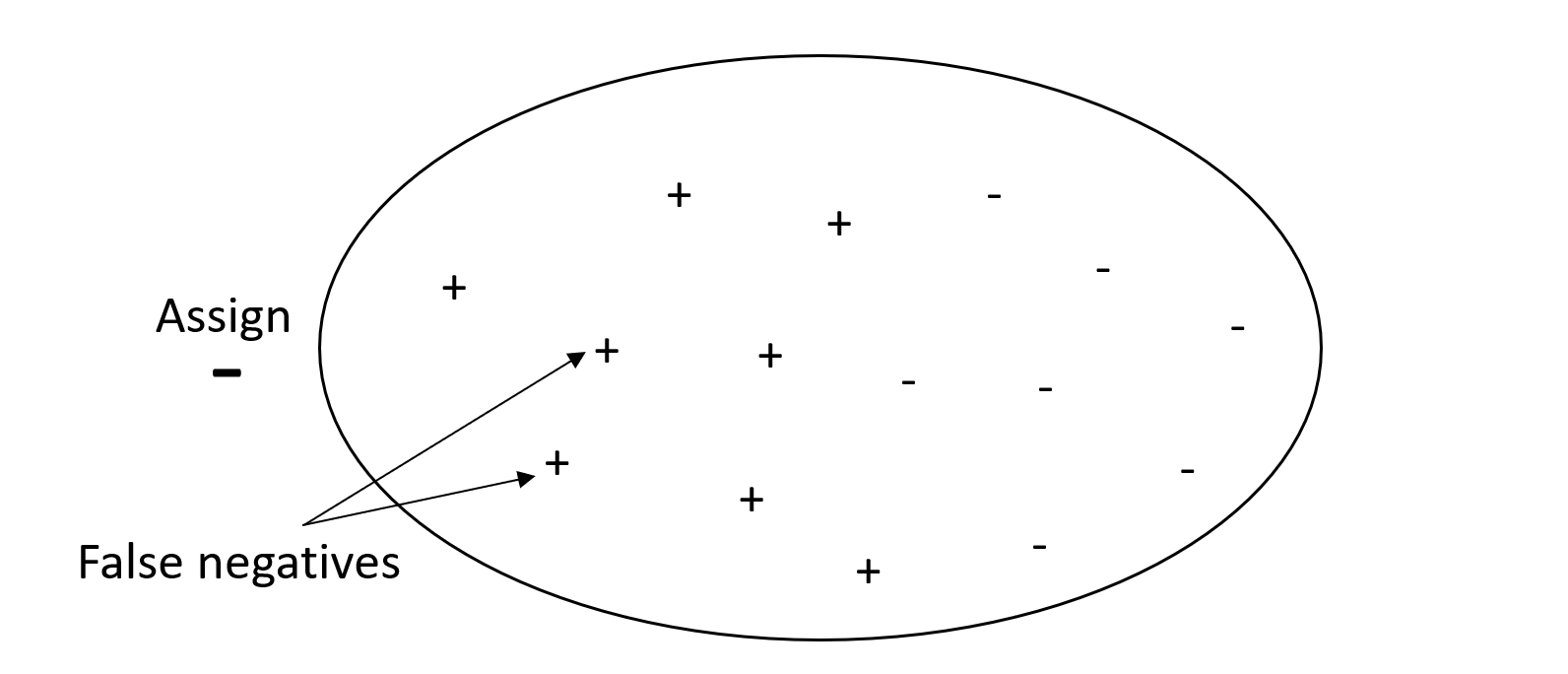
Sebaliknya, sistem dengan presisi tinggi, tetapi penarikan rendah, mengembalikan persentase negatif palsu yang tinggi. Filter spam yang menandai setiap email sebagai diinginkan (bukan spam) memiliki presisi tinggi tetapi penarikan rendah karena presisi tidak mengukur negatif palsu.
Jika masalah Anda memiliki penalti rendah untuk nilai negatif palsu, tetapi penalti tinggi karena kehilangan hasil negatif yang sebenarnya, berikan bobot lebih pada presisi daripada mengingat. Misalnya, menandai filter mencurigakan untuk audit pajak.
Grafik berikut menggambarkan filter spam yang memiliki presisi tinggi tetapi daya ingat rendah, karena presisi tidak mengukur negatif palsu.
Model yang membuat prediksi dengan presisi tinggi dan ingatan tinggi menghasilkan sejumlah besar hasil berlabel dengan benar. Untuk informasi lebih lanjut, lihat artikel Presisi dan ingat
Area di bawah kurva penarikan presisi () AUPRC
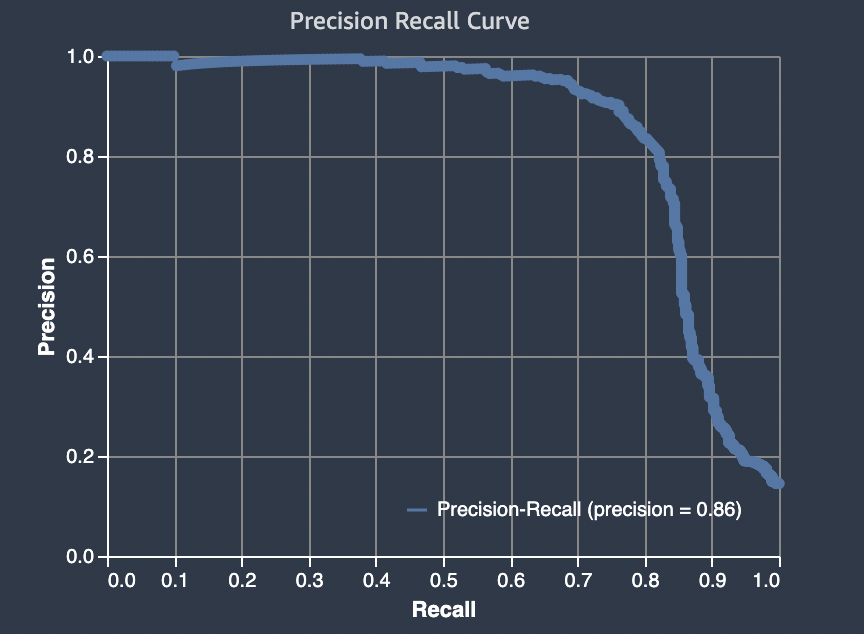
Untuk masalah klasifikasi biner, Amazon SageMaker Autopilot menyertakan grafik area di bawah kurva penarikan presisi (). AUPRC AUPRCMetrik memberikan ukuran agregat kinerja model di semua ambang klasifikasi yang mungkin dan menggunakan presisi dan penarikan kembali. AUPRCtidak memperhitungkan jumlah negatif sejati. Oleh karena itu, dapat berguna untuk mengevaluasi kinerja model dalam kasus di mana ada sejumlah besar negatif sejati dalam data. Misalnya, untuk memodelkan gen yang mengandung mutasi langka.
Grafik berikut adalah contoh AUPRC grafik. Presisi pada nilai tertinggi adalah 1, dan recall berada pada 0. Di sudut kanan bawah grafik, recall adalah nilai tertinggi (1) dan presisi adalah 0. Di antara dua titik ini, AUPRC kurva menggambarkan tradeoff antara presisi dan recall pada ambang batas yang berbeda.
Aktual terhadap plot yang diprediksi
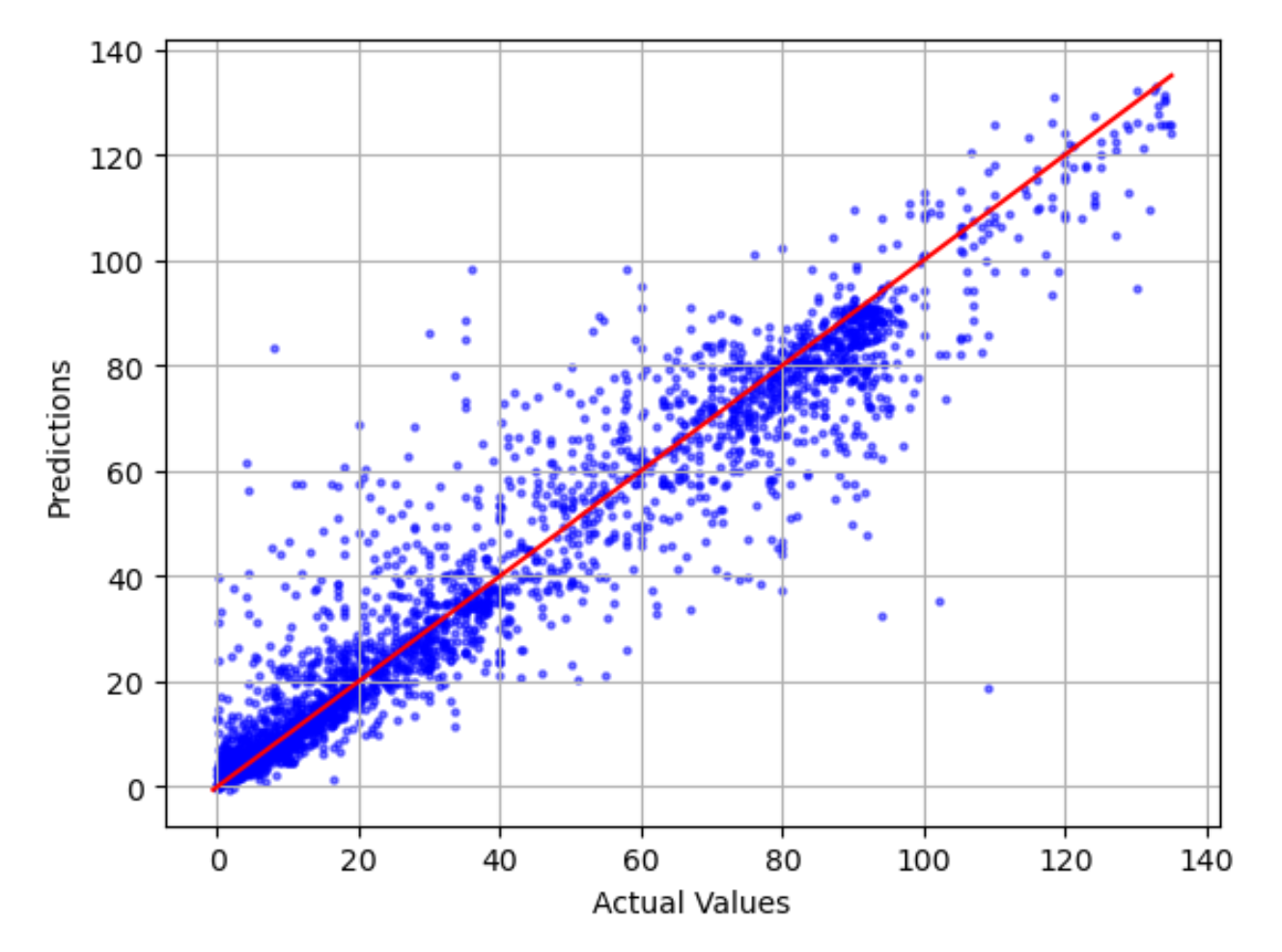
Plot aktual terhadap prediksi menunjukkan perbedaan antara nilai model aktual dan prediksi. Dalam contoh grafik berikut, garis padat adalah garis linier yang paling cocok. Jika modelnya 100% akurat, setiap titik yang diprediksi akan sama dengan titik aktual yang sesuai dan terletak pada garis yang paling cocok ini. Jarak jauh dari garis yang paling cocok adalah indikasi visual kesalahan model. Semakin besar jarak dari garis yang paling cocok, semakin tinggi kesalahan model.
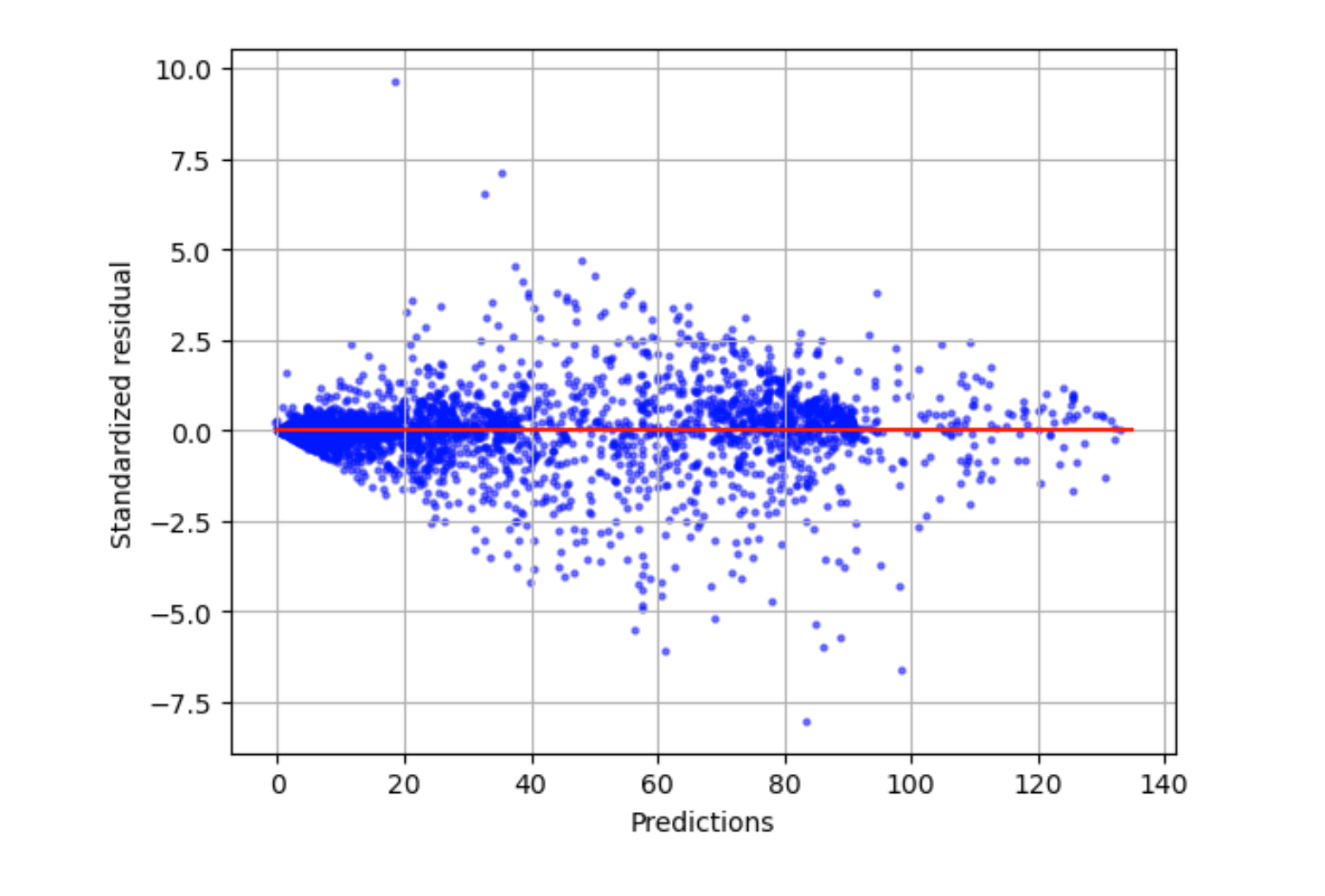
Plot residu standar
Plot residu standar menggabungkan istilah statistik berikut:
residual-
Sisa (mentah) menunjukkan perbedaan antara aktual dan nilai yang diprediksi oleh model Anda. Semakin besar perbedaannya, semakin besar nilai residu.
standard deviation-
Standar deviasi adalah ukuran bagaimana nilai bervariasi dari nilai rata-rata. Standar deviasi yang tinggi menunjukkan bahwa banyak nilai sangat berbeda dari nilai rata-ratanya. Standar deviasi yang rendah menunjukkan bahwa banyak nilai mendekati nilai rata-ratanya.
standardized residual-
Residu standar membagi residu mentah dengan standar deviasi mereka. Residu standar memiliki satuan standar deviasi dan berguna dalam mengidentifikasi outlier dalam data terlepas dari perbedaan skala residu mentah. Jika residu standar jauh lebih kecil atau lebih besar daripada residu standar lainnya, ini menunjukkan bahwa model tersebut tidak sesuai dengan pengamatan ini dengan baik.
Plot residu standar mengukur kekuatan perbedaan antara nilai yang diamati dan yang diharapkan. Nilai prediksi aktual ditampilkan pada sumbu x. Titik dengan nilai lebih besar dari nilai absolut 3 umumnya dianggap sebagai outlier.
Contoh grafik berikut menunjukkan bahwa sejumlah besar residu standar dikelompokkan sekitar 0 pada sumbu horizontal. Nilai mendekati nol menunjukkan bahwa model cocok dengan titik-titik ini dengan baik. Titik-titik ke arah atas dan bawah plot tidak diprediksi dengan baik oleh model.
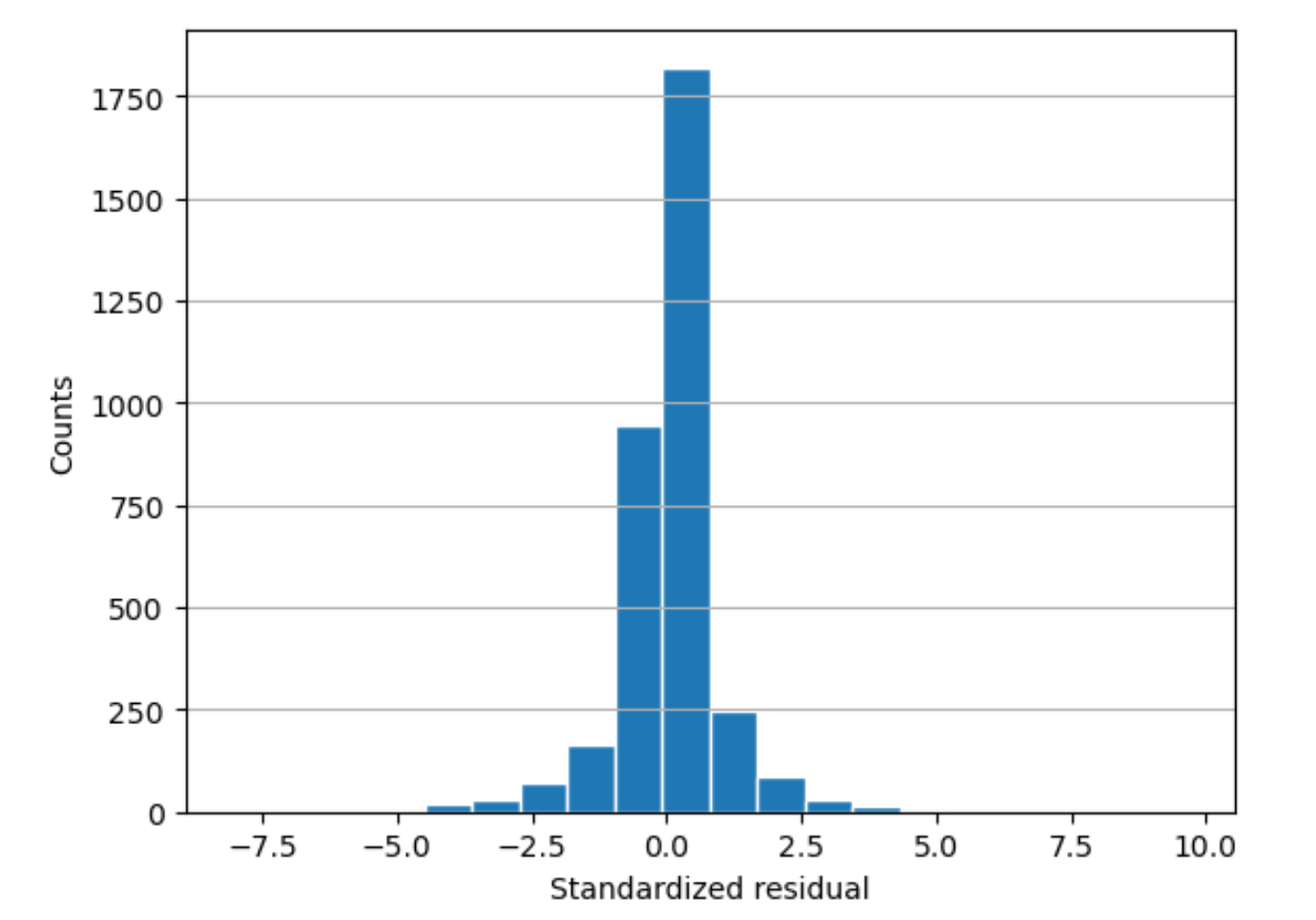
Histogram sisa
Histogram residual menggabungkan istilah statistik berikut:
residual-
Sisa (mentah) menunjukkan perbedaan antara aktual dan nilai yang diprediksi oleh model Anda. Semakin besar perbedaannya, semakin besar nilai residu.
standard deviation-
Standar deviasi adalah ukuran seberapa banyak nilai bervariasi dari nilai rata-rata. Standar deviasi yang tinggi menunjukkan bahwa banyak nilai sangat berbeda dari nilai rata-ratanya. Standar deviasi yang rendah menunjukkan bahwa banyak nilai mendekati nilai rata-ratanya.
standardized residual-
Residu standar membagi residu mentah dengan standar deviasi mereka. Residu standar memiliki satuan standar deviasi. Ini berguna dalam mengidentifikasi outlier dalam data terlepas dari perbedaan skala residu mentah. Jika residu standar jauh lebih kecil atau lebih besar daripada residu standar lainnya, itu akan menunjukkan bahwa model tersebut tidak sesuai dengan pengamatan ini dengan baik.
histogram-
Histogram adalah grafik yang menunjukkan seberapa sering suatu nilai terjadi.
Histogram residu menunjukkan distribusi nilai residu standar. Histogram yang didistribusikan dalam bentuk lonceng dan berpusat pada nol menunjukkan bahwa model tidak secara sistematis memprediksi atau meremehkan rentang nilai target tertentu.
Dalam grafik berikut, nilai residu standar menunjukkan bahwa model tersebut sesuai dengan data dengan baik. Jika grafik menunjukkan nilai yang jauh dari nilai pusat, itu akan menunjukkan bahwa nilai-nilai tersebut tidak sesuai dengan model dengan baik.