Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Mengaitkan Hasil Prediksi dengan Catatan Input
Saat membuat prediksi pada kumpulan data besar, Anda dapat mengecualikan atribut yang tidak diperlukan untuk prediksi. Setelah prediksi dibuat, Anda dapat mengaitkan beberapa atribut yang dikecualikan dengan prediksi tersebut atau dengan data masukan lainnya dalam laporan Anda. Dengan menggunakan transformasi batch untuk melakukan langkah-langkah pemrosesan data ini, Anda sering dapat menghilangkan preprocessing atau postprocessing tambahan. Anda dapat menggunakan file input dalam format JSON dan CSV saja.
Topik
Alur Kerja untuk Mengaitkan Inferensi dengan Catatan Input
Diagram berikut menunjukkan alur kerja untuk mengaitkan kesimpulan dengan catatan masukan.
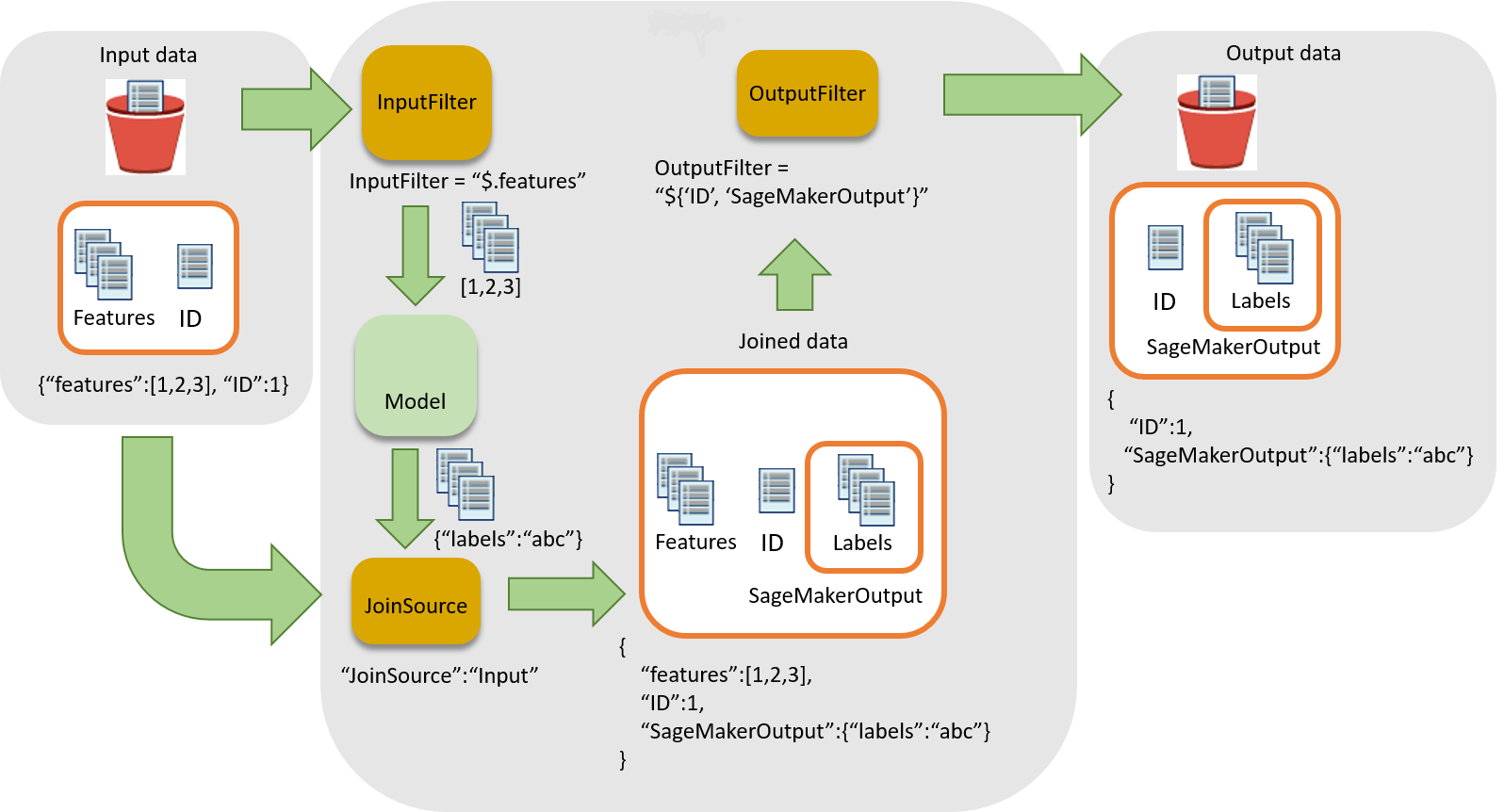
Untuk mengaitkan kesimpulan dengan data input, ada tiga langkah utama:
-
Filter data input yang tidak diperlukan untuk inferensi sebelum meneruskan data input ke pekerjaan transformasi batch. Gunakan
InputFilterparameter untuk menentukan atribut mana yang akan digunakan sebagai input untuk model. -
Kaitkan data input dengan hasil inferensi. Gunakan
JoinSourceparameter untuk menggabungkan data input dengan inferensi. -
Filter data gabungan untuk mempertahankan input yang diperlukan untuk menyediakan konteks untuk menafsirkan prediksi dalam laporan. Gunakan
OutputFilteruntuk menyimpan bagian tertentu dari dataset bergabung dalam file output.
Menggunakan Pemrosesan Data dalam Pekerjaan Transformasi Batch
Saat membuat pekerjaan transformasi batch dengan CreateTransformJobmemproses data:
-
Tentukan bagian input yang akan diteruskan ke model dengan
InputFilterparameter dalam strukturDataProcessingdata. -
Bergabunglah dengan data input mentah dengan data yang diubah dengan
JoinSourceparameter. -
Tentukan bagian mana dari input yang digabungkan dan data yang diubah dari pekerjaan transformasi batch yang akan disertakan dalam file output dengan
OutputFilterparameter. -
Pilih JSON- atau CSV-formatted file untuk masukan:
-
Untuk file Lines-formatted input JSON- atau JSON, SageMaker AI menambahkan
SageMakerOutputatribut ke file input atau membuat file keluaran JSON baru dengan atribut and.SageMakerInputSageMakerOutputUntuk informasi selengkapnya, lihatDataProcessing. -
Untuk file CSV-formatted input, data input yang digabungkan diikuti oleh data yang diubah dan outputnya adalah file CSV.
-
Jika Anda menggunakan algoritma dengan DataProcessing struktur, itu harus mendukung format yang Anda pilih untuk file input dan output. Misalnya, dengan TransformOutputbidang CreateTransformJob API, Anda harus mengatur Acceptparameter ContentTypedan parameter ke salah satu nilai berikut:text/csv,application/json, atauapplication/jsonlines. Sintaks untuk menentukan kolom dalam file CSV dan menentukan atribut dalam file JSON berbeda. Menggunakan sintaks yang salah menyebabkan kesalahan. Untuk informasi selengkapnya, lihat Contoh Transformasi Batch. Untuk informasi selengkapnya tentang format file input dan output untuk algoritme bawaan, lihatBuilt-in algoritma dan model terlatih di Amazon SageMaker.
Pembatas catatan untuk input dan output juga harus konsisten dengan input file yang Anda pilih. SplitTypeParameter menunjukkan cara membagi catatan dalam dataset input. AssembleWithParameter menunjukkan cara memasang kembali catatan untuk output. Jika Anda mengatur format input dan output ketext/csv, Anda juga harus mengatur AssembleWith parameter SplitType dan keline. Jika Anda mengatur format input dan output keapplication/jsonlines, Anda dapat mengatur keduanya SplitType dan AssembleWith keline.
Untuk file CSV, Anda tidak dapat menggunakan karakter baris baru yang disematkan. Untuk file JSON, nama atribut SageMakerOutput dicadangkan untuk output. File input JSON tidak dapat memiliki atribut dengan nama ini. Jika ya, data dalam file input mungkin akan ditimpa.
Operator JSONPath yang Didukung
Untuk memfilter dan menggabungkan data input dan inferensi, gunakan subexpression JsonPath. SageMaker AI hanya mendukung sebagian dari operator JsonPath yang ditentukan. Tabel berikut mencantumkan operator JSONPath yang didukung. Untuk data CSV, setiap baris diambil sebagai array JSON, jadi hanya JSONPaths berbasis indeks yang dapat diterapkan, misalnya,. $[0] $[1:] Data CSV juga harus mengikuti format RFC
| Operator JsonPath | Deskripsi | Contoh |
|---|---|---|
$ |
Elemen root untuk query. Operator ini diperlukan di awal semua ekspresi jalur. |
$ |
. |
Elemen anak bernotasi titik. |
|
* |
Wildcard. Gunakan sebagai pengganti nama atribut atau nilai numerik. |
|
[' |
Sebuah elemen bertanda kurung atau beberapa elemen anak. |
|
[ |
Sebuah indeks atau array indeks. Nilai indeks negatif juga didukung. |
|
[ |
Operator irisan array. Metode array slice () mengekstrak bagian dari array dan mengembalikan array baru. Jika Anda menghilangkan |
|
Saat menggunakan notasi kurung untuk menentukan beberapa elemen anak dari bidang tertentu, penyarangan tambahan anak dalam tanda kurung tidak didukung. Misalnya, $.field1.['child1','child2'] didukung sementara $.field1.['child1','child2.grandchild'] tidak.
Untuk informasi selengkapnya tentang operator JsonPath, lihat JsonPath
Contoh Transformasi Batch
Contoh berikut menunjukkan beberapa cara umum untuk menggabungkan data input dengan hasil prediksi.
Topik
Contoh: Output Only Inferences
Secara default, DataProcessingparameter tidak menggabungkan hasil inferensi dengan input. Ini hanya menghasilkan hasil inferensi.
Jika Anda ingin secara eksplisit menentukan untuk tidak menggabungkan hasil dengan input, gunakan Amazon SageMaker Python SDK
sm_transformer = sagemaker.transformer.Transformer(…) sm_transformer.transform(…, input_filter="$", join_source= "None", output_filter="$")
Untuk menghasilkan inferensi menggunakan AWS SDK untuk Python, tambahkan kode berikut ke permintaan Anda. CreateTransformJob Kode berikut meniru perilaku default.
{ "DataProcessing": { "InputFilter": "$", "JoinSource": "None", "OutputFilter": "$" } }
Contoh: Inferensi Output Bergabung dengan Data Input
Jika Anda menggunakan Amazon SageMaker Python SDKaccept parameter assemble_with dan saat menginisialisasi objek transformator. Saat Anda menggunakan panggilan transformasi, tentukan Input join_source parameternya, dan tentukan content_type parameter split_type dan juga. split_typeParameter harus memiliki nilai yang sama denganassemble_with, dan content_type parameter harus memiliki nilai yang sama denganaccept. Untuk informasi selengkapnya tentang parameter dan nilai yang diterima, lihat halaman Transformer
sm_transformer = sagemaker.transformer.Transformer(…, assemble_with="Line", accept="text/csv") sm_transformer.transform(…, join_source="Input", split_type="Line", content_type="text/csv")
Jika Anda menggunakan AWS SDK untuk Python (Boto 3), gabungkan semua data input dengan inferensi dengan menambahkan kode berikut ke permintaan Anda. CreateTransformJob Nilai untuk Accept dan ContentType harus cocok, dan nilai untuk AssembleWith dan juga SplitType harus cocok.
{ "DataProcessing": { "JoinSource": "Input" }, "TransformOutput": { "Accept": "text/csv", "AssembleWith": "Line" }, "TransformInput": { "ContentType": "text/csv", "SplitType": "Line" } }
Untuk file input JSON atau JSON Lines, hasilnya ada di SageMakerOutput kunci dalam file JSON input. Misalnya, jika input adalah file JSON yang berisi pasangan kunci-nilai{"key":1}, hasil transformasi data mungkin. {"label":1}
SageMaker AI menyimpan keduanya dalam file input di SageMakerInput kunci.
{ "key":1, "SageMakerOutput":{"label":1} }
catatan
Hasil gabungan untuk JSON harus berupa objek pasangan kunci-nilai. Jika input bukan objek pasangan nilai kunci, SageMaker AI membuat file JSON baru. Dalam file JSON baru, data input disimpan dalam SageMakerInput kunci dan hasilnya disimpan sebagai SageMakerOutput nilai.
Untuk file CSV, misalnya, jika catatannya[1,2,3], dan hasil labelnya[1], maka file keluaran akan berisi[1,2,3,1].
Contoh: Inferensi Output Bergabung dengan Data Input dan Kecualikan Kolom ID dari Input (CSV)
Jika Anda menggunakan Amazon SageMaker Python SDKinput_filter Misalnya, jika data masukan Anda menyertakan lima kolom dan yang pertama adalah kolom ID, gunakan permintaan transformasi berikut untuk memilih semua kolom kecuali kolom ID sebagai fitur. Transformator masih mengeluarkan semua kolom input yang bergabung dengan inferensi. Untuk informasi selengkapnya tentang parameter dan nilai yang diterima, lihat halaman Transformer
sm_transformer = sagemaker.transformer.Transformer(…, assemble_with="Line", accept="text/csv") sm_transformer.transform(…, split_type="Line", content_type="text/csv", input_filter="$[1:]", join_source="Input")
Jika Anda menggunakan AWS SDK untuk Python (Boto 3), tambahkan kode berikut ke permintaan Anda.
CreateTransformJob
{ "DataProcessing": { "InputFilter": "$[1:]", "JoinSource": "Input" }, "TransformOutput": { "Accept": "text/csv", "AssembleWith": "Line" }, "TransformInput": { "ContentType": "text/csv", "SplitType": "Line" } }
Untuk menentukan kolom di SageMaker AI, gunakan indeks elemen array. Kolom pertama adalah indeks 0, kolom kedua adalah indeks 1, dan kolom keenam adalah indeks 5.
Untuk mengecualikan kolom pertama dari input, atur InputFilter ke"$[1:]". Titik dua (:) memberitahu SageMaker AI untuk memasukkan semua elemen antara dua nilai, inklusif. Misalnya, $[1:4] menentukan kolom kedua hingga kelima.
Jika Anda menghilangkan angka setelah titik dua, misalnya[5:], subset mencakup semua kolom dari kolom ke-6 melalui kolom terakhir. Jika Anda menghilangkan angka sebelum titik dua, misalnya[:5], subset mencakup semua kolom dari kolom pertama (indeks 0) hingga kolom keenam.
Contoh: Inferensi Keluaran Bergabung dengan Kolom ID dan Kecualikan Kolom ID dari Input (CSV)
Jika Anda menggunakan Amazon SageMaker Python SDKoutput_filter output_filterMenggunakan subexpression JsonPath untuk menentukan kolom mana yang akan dikembalikan sebagai output setelah menggabungkan data input dengan hasil inferensi. Permintaan berikut menunjukkan bagaimana Anda dapat membuat prediksi sambil mengecualikan kolom ID dan kemudian menggabungkan kolom ID dengan kesimpulan. Perhatikan bahwa dalam contoh berikut, kolom terakhir (-1) dari output berisi kesimpulan. Jika Anda menggunakan file JSON, SageMaker AI menyimpan hasil inferensi di atribut. SageMakerOutput Untuk informasi selengkapnya tentang parameter dan nilai yang diterima, lihat halaman Transformer
sm_transformer = sagemaker.transformer.Transformer(…, assemble_with="Line", accept="text/csv") sm_transformer.transform(…, split_type="Line", content_type="text/csv", input_filter="$[1:]", join_source="Input", output_filter="$[0,-1]")
Jika Anda menggunakan AWS SDK untuk Python (Boto 3), gabungkan hanya kolom ID dengan kesimpulan dengan menambahkan kode berikut ke permintaan Anda. CreateTransformJob
{ "DataProcessing": { "InputFilter": "$[1:]", "JoinSource": "Input", "OutputFilter": "$[0,-1]" }, "TransformOutput": { "Accept": "text/csv", "AssembleWith": "Line" }, "TransformInput": { "ContentType": "text/csv", "SplitType": "Line" } }
Awas
Jika Anda menggunakan file JSON-formatted input, file tidak dapat berisi nama atributSageMakerOutput. Nama atribut ini dicadangkan untuk kesimpulan dalam file output. Jika file JSON-formatted input Anda berisi atribut dengan nama ini, nilai dalam file input mungkin ditimpa dengan inferensi.
