Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Buat prediksi untuk data teks
Prosedur berikut menjelaskan cara membuat prediksi tunggal dan batch untuk kumpulan data teks. Setiap Ready-to-use model mendukung prediksi Tunggal dan prediksi Batch untuk kumpulan data Anda. Prediksi tunggal adalah ketika Anda hanya perlu membuat satu prediksi. Misalnya, Anda memiliki satu gambar dari mana Anda ingin mengekstrak teks, atau satu paragraf teks yang ingin Anda deteksi bahasa dominannya. Prediksi Batch adalah saat Anda ingin membuat prediksi untuk seluruh kumpulan data. Misalnya, Anda mungkin memiliki CSV file ulasan pelanggan yang ingin Anda analisis sentimen pelanggan, atau Anda mungkin memiliki file gambar di mana Anda ingin mendeteksi objek.
Anda dapat menggunakan prosedur ini untuk jenis Ready-to-use model berikut: analisis sentimen, ekstraksi entitas, deteksi bahasa, dan deteksi informasi pribadi.
catatan
Untuk analisis sentimen, Anda hanya dapat menggunakan teks bahasa Inggris.
Prediksi tunggal
Untuk membuat prediksi tunggal untuk Ready-to-use model yang menerima data teks, lakukan hal berikut:
-
Di panel navigasi kiri aplikasi Canvas, pilih eady-to-usemodel R.
-
Pada halaman Ready-to-use model, pilih Ready-to-use model untuk kasus penggunaan Anda. Untuk data teks, harus salah satu dari yang berikut: Analisis sentimen, ekstraksi Entitas, Deteksi bahasa, atau Deteksi informasi pribadi.
-
Pada halaman Jalankan prediksi untuk Ready-to-use model yang Anda pilih, pilih Prediksi tunggal.
-
Untuk bidang Teks, masukkan teks yang ingin Anda prediksi.
-
Pilih Hasilkan hasil prediksi untuk mendapatkan prediksi Anda.
Di panel kanan hasil Prediksi, Anda menerima analisis teks Anda selain skor Keyakinan untuk setiap hasil atau label. Misalnya, jika Anda memilih deteksi bahasa dan memasukkan bagian teks dalam bahasa Prancis, Anda mungkin mendapatkan bahasa Prancis dengan skor kepercayaan 95% dan jejak bahasa lain, seperti bahasa Inggris, dengan skor kepercayaan 5%.
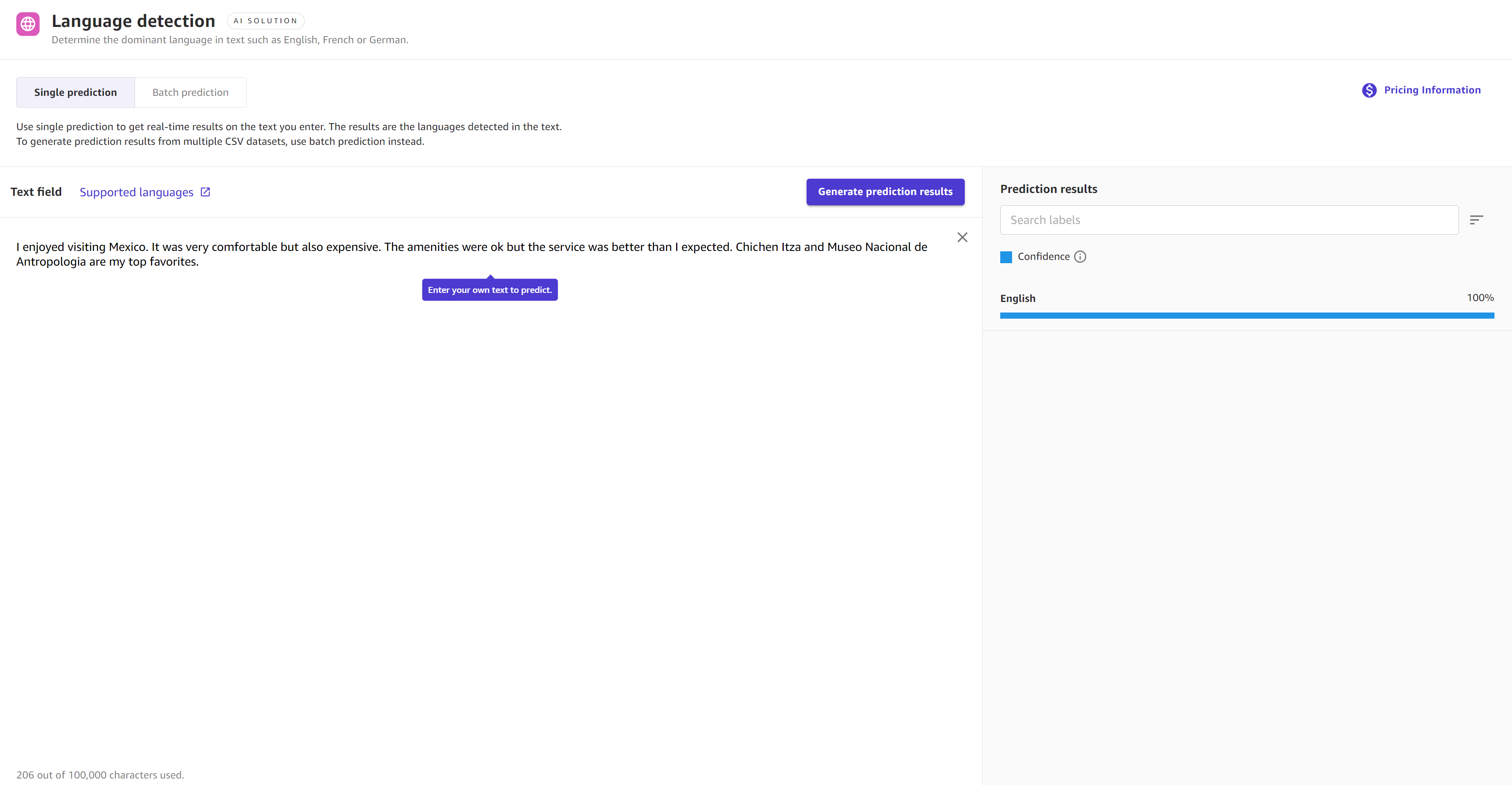
Tangkapan layar berikut menunjukkan hasil untuk prediksi tunggal menggunakan deteksi bahasa di mana modelnya 100% yakin bahwa bagian tersebut adalah bahasa Inggris.
Prediksi Batch
Untuk membuat prediksi batch untuk Ready-to-use model yang menerima data teks, lakukan hal berikut:
-
Di panel navigasi kiri aplikasi Canvas, pilih eady-to-usemodel R.
-
Pada halaman Ready-to-use model, pilih Ready-to-use model untuk kasus penggunaan Anda. Untuk data teks, harus salah satu dari yang berikut: Analisis sentimen, ekstraksi Entitas, Deteksi bahasa, atau Deteksi informasi pribadi.
-
Pada halaman Jalankan prediksi untuk Ready-to-use model yang Anda pilih, pilih prediksi Batch.
-
Pilih Pilih kumpulan data jika Anda telah mengimpor dataset Anda. Jika tidak, pilih Impor dataset baru, dan kemudian Anda diarahkan melalui alur kerja data impor.
-
Dari daftar kumpulan data yang tersedia, pilih kumpulan data Anda dan pilih Hasilkan prediksi untuk mendapatkan prediksi Anda.
Setelah pekerjaan prediksi selesai berjalan, pada halaman Jalankan prediksi, Anda akan melihat kumpulan data keluaran yang tercantum di bawah Prediksi. Kumpulan data ini berisi hasil Anda, dan jika Anda memilih ikon Opsi lainnya (
![]() ), Anda dapat Pratinjau data keluaran. Kemudian, Anda dapat memilih Unduh untuk mengunduh hasilnya.
), Anda dapat Pratinjau data keluaran. Kemudian, Anda dapat memilih Unduh untuk mengunduh hasilnya.
