Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Contoh kode: SDK untuk Python
Bagian ini menyediakan contoh kode untuk membuat dan memanggil titik akhir yang menggunakan SageMaker Clarify online explainability. Contoh kode ini menggunakan AWS SDKuntuk Python
Data tabular
Contoh berikut menggunakan data tabular dan SageMaker model yang disebutmodel_name. Dalam contoh ini, wadah model menerima data dalam CSV format, dan setiap catatan memiliki empat fitur numerik. Dalam konfigurasi minimal ini, hanya untuk tujuan demonstrasi, data SHAP dasar diatur ke nol. Lihat SHAPBaseline untuk Keterjelasan untuk mempelajari cara memilih nilai yang lebih sesuai untukShapBaseline.
Konfigurasikan titik akhir, sebagai berikut:
endpoint_config_name = 'tabular_explainer_endpoint_config' response = sagemaker_client.create_endpoint_config( EndpointConfigName=endpoint_config_name, ProductionVariants=[{ 'VariantName': 'AllTraffic', 'ModelName': model_name, 'InitialInstanceCount': 1, 'InstanceType': 'ml.m5.xlarge', }], ExplainerConfig={ 'ClarifyExplainerConfig': { 'ShapConfig': { 'ShapBaselineConfig': { 'ShapBaseline': '0,0,0,0', }, }, }, }, )
Gunakan konfigurasi endpoint untuk membuat endpoint, sebagai berikut:
endpoint_name = 'tabular_explainer_endpoint' response = sagemaker_client.create_endpoint( EndpointName=endpoint_name, EndpointConfigName=endpoint_config_name, )
Gunakan DescribeEndpoint API untuk memeriksa kemajuan pembuatan titik akhir, sebagai berikut:
response = sagemaker_client.describe_endpoint( EndpointName=endpoint_name, ) response['EndpointStatus']
Setelah status endpoint adalah "InService“, panggil titik akhir dengan catatan pengujian, sebagai berikut:
response = sagemaker_runtime_client.invoke_endpoint( EndpointName=endpoint_name, ContentType='text/csv', Accept='text/csv', Body='1,2,3,4', )
catatan
Dalam contoh kode sebelumnya, untuk titik akhir multi-model, berikan TargetModel parameter tambahan dalam permintaan untuk menentukan model mana yang akan ditargetkan pada titik akhir.
Asumsikan bahwa respons memiliki kode status 200 (tidak ada kesalahan), dan muat badan respons, sebagai berikut:
import codecs import json json.load(codecs.getreader('utf-8')(response['Body']))
Tindakan default untuk titik akhir adalah menjelaskan catatan. Berikut ini menunjukkan contoh output dalam JSON objek dikembalikan.
{ "version": "1.0", "predictions": { "content_type": "text/csv; charset=utf-8", "data": "0.0006380207487381" }, "explanations": { "kernel_shap": [ [ { "attributions": [ { "attribution": [-0.00433456] } ] }, { "attributions": [ { "attribution": [-0.005369821] } ] }, { "attributions": [ { "attribution": [0.007917749] } ] }, { "attributions": [ { "attribution": [-0.00261214] } ] } ] ] } }
Gunakan EnableExplanations parameter untuk mengaktifkan penjelasan sesuai permintaan, sebagai berikut:
response = sagemaker_runtime_client.invoke_endpoint( EndpointName=endpoint_name, ContentType='text/csv', Accept='text/csv', Body='1,2,3,4', EnableExplanations='[0]>`0.8`', )
catatan
Dalam contoh kode sebelumnya, untuk titik akhir multi-model, berikan TargetModel parameter tambahan dalam permintaan untuk menentukan model mana yang akan ditargetkan pada titik akhir.
Dalam contoh ini, nilai prediksi kurang dari nilai ambang batas0.8, sehingga catatan tidak dijelaskan:
{ "version": "1.0", "predictions": { "content_type": "text/csv; charset=utf-8", "data": "0.6380207487381995" }, "explanations": {} }
Gunakan alat visualisasi untuk membantu menafsirkan penjelasan yang dikembalikan. Gambar berikut menunjukkan bagaimana SHAP plot dapat digunakan untuk memahami bagaimana setiap fitur berkontribusi pada prediksi. Nilai dasar pada diagram, juga disebut nilai yang diharapkan, adalah prediksi rata-rata dari kumpulan data pelatihan. Fitur yang mendorong nilai yang diharapkan lebih tinggi berwarna merah, dan fitur yang mendorong nilai yang diharapkan lebih rendah berwarna biru. Lihat tata letak gaya SHAP aditif
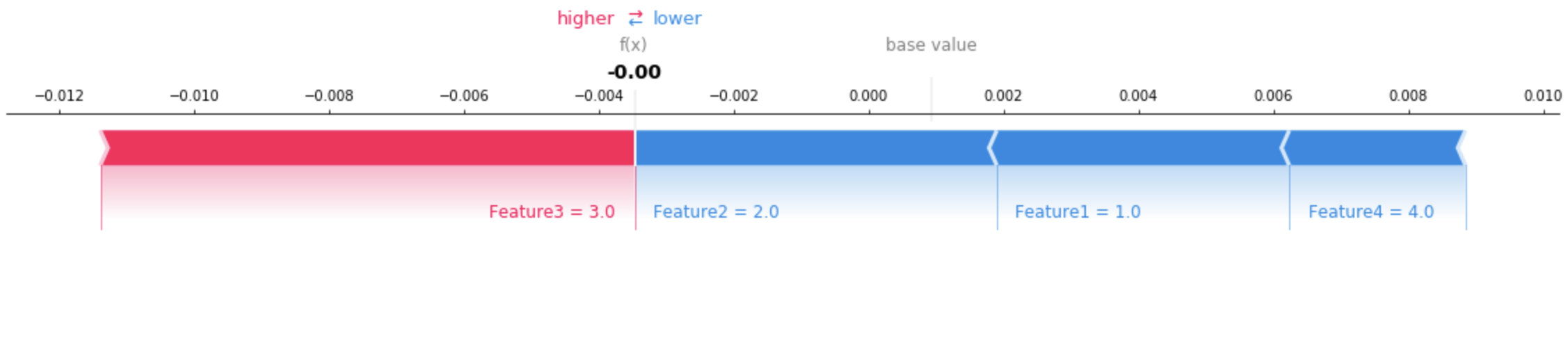
Lihat contoh buku catatan lengkap untuk data tabular
Data teks
Bagian ini memberikan contoh kode untuk membuat dan memanggil titik akhir penjelasan online untuk data teks. Contoh kode yang digunakan SDK untuk Python.
Contoh berikut menggunakan data teks dan SageMaker model yang disebutmodel_name. Dalam contoh ini, wadah model menerima data dalam CSV format, dan setiap catatan adalah string tunggal.
endpoint_config_name = 'text_explainer_endpoint_config' response = sagemaker_client.create_endpoint_config( EndpointConfigName=endpoint_config_name, ProductionVariants=[{ 'VariantName': 'AllTraffic', 'ModelName': model_name, 'InitialInstanceCount': 1, 'InstanceType': 'ml.m5.xlarge', }], ExplainerConfig={ 'ClarifyExplainerConfig': { 'InferenceConfig': { 'FeatureTypes': ['text'], 'MaxRecordCount': 100, }, 'ShapConfig': { 'ShapBaselineConfig': { 'ShapBaseline': '"<MASK>"', }, 'TextConfig': { 'Granularity': 'token', 'Language': 'en', }, 'NumberOfSamples': 100, }, }, }, )
-
ShapBaseline: Token khusus yang disediakan untuk pemrosesan bahasa alami (NLP) pemrosesan. -
FeatureTypes: Mengidentifikasi fitur sebagai teks. Jika parameter ini tidak disediakan, penjelasan akan mencoba menyimpulkan jenis fitur. -
TextConfig: Menentukan unit granularitas dan bahasa untuk analisis fitur teks. Dalam contoh ini, bahasanya adalah bahasa Inggris, dan granularitastokenberarti kata dalam teks bahasa Inggris. -
NumberOfSamples: Batas untuk mengatur batas atas ukuran dataset sintetis. -
MaxRecordCount: Jumlah maksimum catatan dalam permintaan yang dapat ditangani oleh wadah model. Parameter ini diatur untuk menstabilkan kinerja.
Gunakan konfigurasi endpoint untuk membuat endpoint, sebagai berikut:
endpoint_name = 'text_explainer_endpoint' response = sagemaker_client.create_endpoint( EndpointName=endpoint_name, EndpointConfigName=endpoint_config_name, )
Setelah status titik akhir menjadiInService, panggil titik akhir. Contoh kode berikut menggunakan catatan uji sebagai berikut:
response = sagemaker_runtime_client.invoke_endpoint( EndpointName=endpoint_name, ContentType='text/csv', Accept='text/csv', Body='"This is a good product"', )
Jika permintaan berhasil diselesaikan, badan respons akan mengembalikan JSON objek yang valid yang mirip dengan yang berikut ini:
{ "version": "1.0", "predictions": { "content_type": "text/csv", "data": "0.9766594\n" }, "explanations": { "kernel_shap": [ [ { "attributions": [ { "attribution": [ -0.007270948666666712 ], "description": { "partial_text": "This", "start_idx": 0 } }, { "attribution": [ -0.018199033666666628 ], "description": { "partial_text": "is", "start_idx": 5 } }, { "attribution": [ 0.01970993241666666 ], "description": { "partial_text": "a", "start_idx": 8 } }, { "attribution": [ 0.1253469515833334 ], "description": { "partial_text": "good", "start_idx": 10 } }, { "attribution": [ 0.03291143366666657 ], "description": { "partial_text": "product", "start_idx": 15 } } ], "feature_type": "text" } ] ] } }
Gunakan alat visualisasi untuk membantu menafsirkan atribusi teks yang dikembalikan. Gambar berikut menunjukkan bagaimana utilitas visualisasi captum dapat digunakan untuk memahami bagaimana setiap kata berkontribusi pada prediksi. Semakin tinggi saturasi warna, semakin tinggi pentingnya kata tersebut. Dalam contoh ini, warna merah cerah yang sangat jenuh menunjukkan kontribusi negatif yang kuat. Warna hijau yang sangat jenuh menunjukkan kontribusi positif yang kuat. Warna putih menunjukkan bahwa kata tersebut memiliki kontribusi netral. Lihat perpustakaan captum

Lihat contoh buku catatan lengkap untuk data teks
