Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Pengantar perpustakaan paralelisme data terdistribusi SageMaker AI
Pustaka SageMaker AI distributed data parallelism (SMDDP) adalah perpustakaan komunikasi kolektif yang meningkatkan kinerja komputasi pelatihan paralel data terdistribusi. Perpustakaan SMDDP menangani overhead komunikasi dari operasi komunikasi kolektif utama dengan menawarkan yang berikut ini.
-
Perpustakaan menawarkan
AllReducedioptimalkan untuk AWS.AllReduceadalah operasi kunci yang digunakan untuk menyinkronkan gradien di seluruh GPU pada akhir setiap iterasi pelatihan selama pelatihan data terdistribusi. -
Perpustakaan menawarkan
AllGatherdioptimalkan untuk AWS.AllGatheradalah operasi kunci lain yang digunakan dalam pelatihan paralelisme data sharded, yang merupakan teknik paralelisme data hemat memori yang ditawarkan oleh perpustakaan populer seperti perpustakaan paralelisme model SageMaker AI (SMP), DeepSpeed Zero Redundancy Optimizer (Zero), dan Fully Sharded Data Parallelism (FSDP). PyTorch -
Library melakukan komunikasi node-to-node yang dioptimalkan dengan sepenuhnya memanfaatkan infrastruktur AWS jaringan dan topologi instans Amazon EC2.
Pustaka SMDDP dapat meningkatkan kecepatan pelatihan dengan menawarkan peningkatan kinerja saat Anda menskalakan klaster pelatihan Anda, dengan efisiensi penskalaan hampir linier.
catatan
Perpustakaan pelatihan terdistribusi SageMaker AI tersedia melalui wadah pembelajaran AWS mendalam untuk PyTorch dan Hugging Face dalam platform SageMaker Pelatihan. Untuk menggunakan library, Anda harus menggunakan SageMaker Python SDK atau API melalui SDK for SageMaker Python (Boto3) atau. AWS Command Line Interface Sepanjang dokumentasi, instruksi dan contoh berfokus pada cara menggunakan pustaka pelatihan terdistribusi dengan SageMaker Python SDK.
Operasi komunikasi kolektif SMDDP dioptimalkan untuk AWS menghitung sumber daya dan infrastruktur jaringan
Perpustakaan SMDDP menyediakan implementasi operasi AllGather kolektif yang dioptimalkan untuk sumber daya AWS komputasi AllReduce dan infrastruktur jaringan.
Operasi kolektif SMDDP AllReduce
Pustaka SMDDP mencapai tumpang tindih AllReduce operasi yang optimal dengan backward pass, secara signifikan meningkatkan pemanfaatan GPU. Ini mencapai efisiensi penskalaan hampir linier dan kecepatan pelatihan yang lebih cepat dengan mengoptimalkan operasi kernel antara CPU dan GPU. Library bekerja AllReduce secara paralel saat GPU menghitung gradien tanpa menghilangkan siklus GPU tambahan, yang membuat perpustakaan mencapai pelatihan yang lebih cepat.
-
Memanfaatkan CPU: Perpustakaan menggunakan CPU untuk
AllReducegradien, membongkar tugas ini dari GPU. -
Peningkatan penggunaan GPU: GPU cluster fokus pada gradien komputasi, meningkatkan pemanfaatannya selama pelatihan.
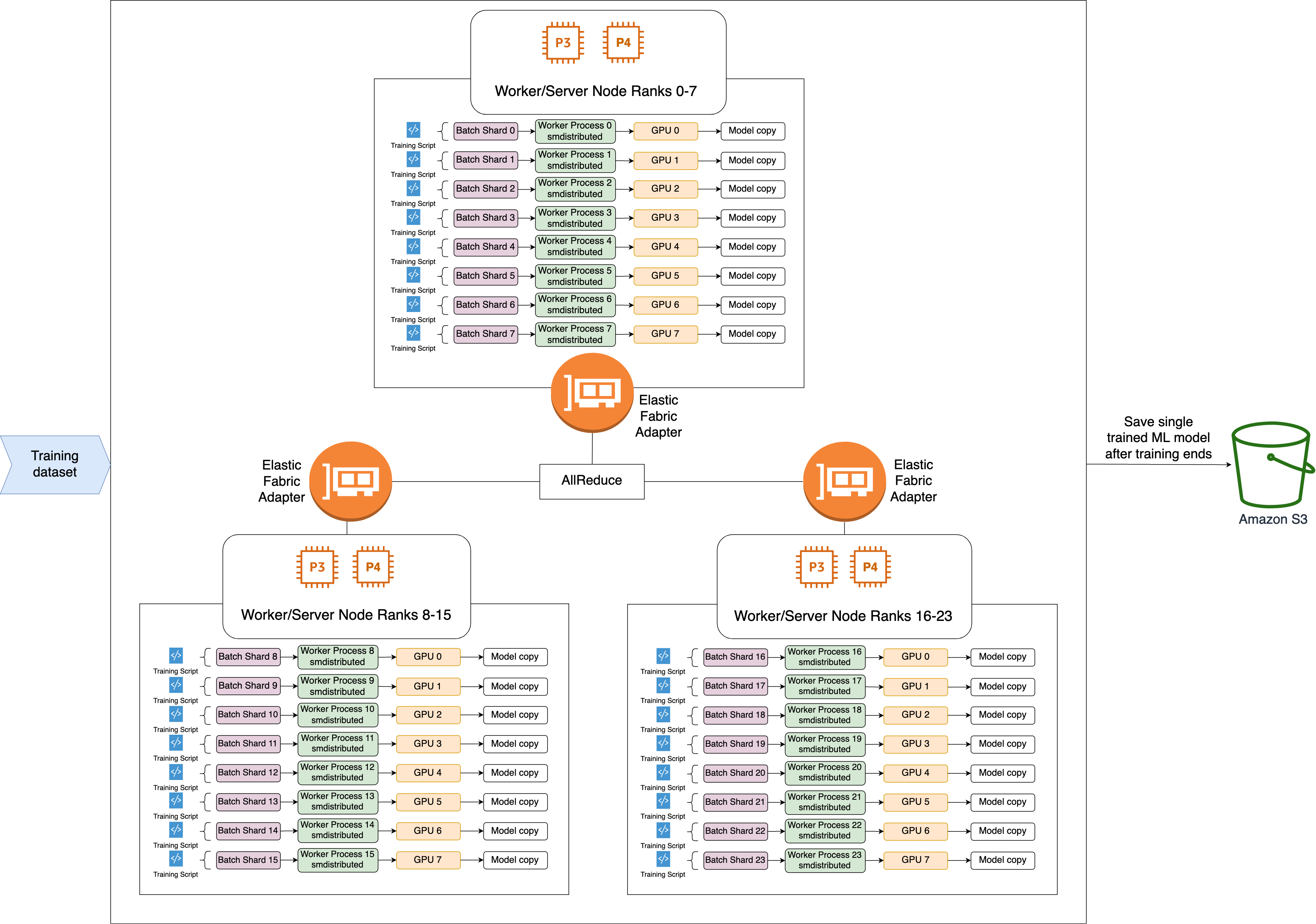
Berikut ini adalah alur kerja tingkat tinggi dari operasi AllReduce SMDDP.
-
Perpustakaan memberikan peringkat ke GPU (pekerja).
-
Pada setiap iterasi, perpustakaan membagi setiap batch global dengan jumlah total pekerja (ukuran dunia) dan memberikan batch kecil (pecahan batch) kepada pekerja.
-
Ukuran batch global adalah
(number of nodes in a cluster) * (number of GPUs per node) * (per batch shard). -
Batch shard (batch kecil) adalah subset dari dataset yang ditetapkan untuk setiap GPU (pekerja) per iterasi.
-
-
Perpustakaan meluncurkan skrip pelatihan pada setiap pekerja.
-
Pustaka mengelola salinan bobot model dan gradien dari pekerja di akhir setiap iterasi.
-
Pustaka menyinkronkan bobot dan gradien model di seluruh pekerja untuk menggabungkan satu model terlatih.
Diagram arsitektur berikut menunjukkan contoh bagaimana perpustakaan mengatur paralelisme data untuk cluster 3 node.
Operasi kolektif SMDDP AllGather
AllGatheradalah operasi kolektif di mana setiap pekerja memulai dengan buffer input, dan kemudian menggabungkan atau mengumpulkan buffer input dari semua pekerja lain ke dalam buffer output.
catatan
Operasi AllGather kolektif SMDDP tersedia di AWS Deep Learning Containers (DLC) untuk PyTorch v2.0.1 smdistributed-dataparallel>=2.0.1 dan yang lebih baru.
AllGatherbanyak digunakan dalam teknik pelatihan terdistribusi seperti paralelisme data sharded di mana setiap pekerja individu memegang sebagian kecil dari model, atau lapisan sharded. Para pekerja memanggil AllGather sebelum umpan maju dan mundur untuk merekonstruksi lapisan yang dipecah. Pass maju dan mundur terus berlanjut setelah semua parameter dikumpulkan. Selama pass mundur, setiap pekerja juga memanggil ReduceScatter untuk mengumpulkan (mengurangi) gradien dan memecah (menyebarkan) mereka menjadi pecahan gradien untuk memperbarui lapisan sharded yang sesuai. Untuk detail lebih lanjut tentang peran operasi kolektif ini dalam paralelisme data sharded, lihat implementasi perpustakaan SMP tentang paralelisme data sharded, Zero
Karena operasi kolektif seperti AllGather dipanggil dalam setiap iterasi, mereka adalah kontributor utama untuk overhead komunikasi GPU. Perhitungan yang lebih cepat dari operasi kolektif ini secara langsung diterjemahkan ke waktu pelatihan yang lebih singkat tanpa efek samping pada konvergensi. Untuk mencapai hal ini, perpustakaan SMDDP menawarkan AllGather dioptimalkan untuk instance P4d
SMDDP AllGather menggunakan teknik berikut untuk meningkatkan kinerja komputasi pada instance P4d.
-
Ini mentransfer data antar instance (antar-node) melalui jaringan Elastic Fabric Adapter
(EFA) dengan topologi mesh. EFA adalah solusi jaringan AWS latensi rendah dan throughput tinggi. Topologi mesh untuk komunikasi jaringan antar simpul lebih disesuaikan dengan karakteristik EFA dan infrastruktur jaringan. AWS Dibandingkan dengan cincin NCCL atau topologi pohon yang melibatkan beberapa packet hop, SMDDP menghindari akumulasi latensi dari beberapa hop karena hanya membutuhkan satu hop. SMDDP mengimplementasikan algoritma kontrol laju jaringan yang menyeimbangkan beban kerja untuk setiap rekan komunikasi dalam topologi mesh dan mencapai throughput jaringan global yang lebih tinggi. -
Ini mengadopsi perpustakaan salinan memori GPU latensi rendah berdasarkan teknologi NVIDIA GPUDirect RDMA (GDRCopy
) untuk mengoordinasikan lalu lintas jaringan NVLink dan EFA lokal. GDRCopy, pustaka salinan memori GPU latensi rendah yang ditawarkan oleh NVIDIA, menyediakan komunikasi latensi rendah antara proses CPU dan kernel GPU CUDA. Dengan teknologi ini, perpustakaan SMDDP mampu menyalurkan pergerakan data intra-node dan antar-node. -
Ini mengurangi penggunaan multiprosesor streaming GPU untuk meningkatkan daya komputasi untuk menjalankan kernel model. Instans P4d dan P4de dilengkapi dengan GPU NVIDIA A100, yang masing-masing memiliki 108 multiprosesor streaming. Sementara NCCL membutuhkan hingga 24 multiprosesor streaming untuk menjalankan operasi kolektif, SMDDP menggunakan kurang dari 9 multiprosesor streaming. Kernel komputasi model mengambil multiprosesor streaming yang disimpan untuk komputasi yang lebih cepat.
