Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Gunakan algoritme peramalan SageMaker AI DeepAR
Algoritma peramalan Amazon SageMaker AI DeepAR adalah algoritma pembelajaran yang diawasi untuk meramalkan deret waktu skalar (satu dimensi) menggunakan jaringan saraf berulang (RNN). Metode peramalan klasik, seperti autoregressive integrated moving average (ARIMA) atau exponential smoothing (ETS), cocok dengan satu model untuk setiap deret waktu individu. Mereka kemudian menggunakan model itu untuk mengekstrapolasi deret waktu ke masa depan.
Namun, dalam banyak aplikasi, Anda memiliki banyak deret waktu serupa di satu set unit penampang. Misalnya, Anda mungkin memiliki pengelompokan deret waktu untuk permintaan berbagai produk, pemuatan server, dan permintaan untuk halaman web. Untuk jenis aplikasi ini, Anda bisa mendapatkan keuntungan dari melatih satu model secara bersama-sama di semua deret waktu. DeepAR mengambil pendekatan ini. Ketika kumpulan data Anda berisi ratusan deret waktu terkait, DeepAR mengungguli metode ARIMA dan ETS standar. Anda juga dapat menggunakan model terlatih untuk menghasilkan perkiraan untuk deret waktu baru yang mirip dengan yang telah dilatih.
Input pelatihan untuk algoritma DeepAR adalah satu atau, lebih disukai, lebih banyak deret target waktu yang telah dihasilkan oleh proses yang sama atau proses serupa. Berdasarkan kumpulan data input ini, algoritme melatih model yang mempelajari perkiraan ini process/processes dan menggunakannya untuk memprediksi bagaimana deret waktu target berkembang. Setiap deret waktu target dapat secara opsional dikaitkan dengan vektor fitur kategoris statis (independen waktu) yang disediakan oleh cat lapangan dan vektor deret waktu dinamis (bergantung waktu) yang disediakan oleh lapangan. dynamic_feat SageMaker AI melatih model DeepAR dengan mengambil sampel contoh pelatihan secara acak dari setiap deret waktu target dalam kumpulan data pelatihan. Setiap contoh pelatihan terdiri dari sepasang konteks dan jendela prediksi yang berdekatan dengan panjang yang telah ditentukan sebelumnya. Untuk mengontrol seberapa jauh di masa lalu jaringan dapat melihat, gunakan context_length hyperparameter. Untuk mengontrol seberapa jauh prediksi future dapat dibuat, gunakan prediction_length hyperparameter. Untuk informasi selengkapnya, lihat Bagaimana Algoritma DeepAR Bekerja.
Topik
Input/Output Antarmuka untuk Algoritma DeepAR
DeepAR mendukung dua saluran data. trainSaluran yang diperlukan menjelaskan kumpulan data pelatihan. testSaluran opsional menjelaskan kumpulan data yang digunakan algoritme untuk mengevaluasi akurasi model setelah pelatihan. Anda dapat memberikan kumpulan data pelatihan dan pengujian dalam format JSON Lines
Saat menentukan jalur untuk data pelatihan dan pengujian, Anda dapat menentukan satu file atau direktori yang berisi banyak file, yang dapat disimpan dalam subdirektori. Jika Anda menentukan direktori, DeepAR menggunakan semua file dalam direktori sebagai input untuk saluran yang sesuai, kecuali yang dimulai dengan periode (.) dan yang bernama _SUCCESS. Ini memastikan bahwa Anda dapat langsung menggunakan folder keluaran yang dihasilkan oleh pekerjaan Spark sebagai saluran input untuk pekerjaan pelatihan DeepAR Anda.
Secara default, model DeepAR menentukan format input dari ekstensi file (.json,.json.gz, atau.parquet) di jalur input yang ditentukan. Jika jalur tidak berakhir di salah satu ekstensi ini, Anda harus secara eksplisit menentukan format dalam SDK untuk Python. Gunakan content_type parameter kelas s3_input
Catatan dalam file input Anda harus berisi bidang berikut:
-
start—Sebuah string dengan formatYYYY-MM-DD HH:MM:SS. Stempel waktu awal tidak dapat berisi informasi zona waktu. -
target—Sebuah array nilai floating-point atau bilangan bulat yang mewakili deret waktu. Anda dapat menyandikan nilai yang hilang sebagainullliteral, atau sebagai"NaN"string di JSON, atau sebagai nilainanfloating-point di Parquet. -
dynamic_feat(opsional) —Sebuah array dari nilai floating-point atau bilangan bulat yang mewakili vektor deret waktu fitur kustom (fitur dinamis). Jika Anda mengatur bidang ini, semua catatan harus memiliki jumlah array dalam yang sama (jumlah rangkaian waktu fitur yang sama). Selain itu, setiap array dalam harus memiliki panjang yang sama dengantargetnilai plus yang terkaitprediction_length. Nilai yang hilang tidak didukung dalam fitur. Misalnya, jika deret waktu target mewakili permintaan produk yang berbeda, yang terkaitdynamic_featmungkin berupa deret waktu boolean yang menunjukkan apakah promosi diterapkan (1) ke produk tertentu atau tidak (0):{"start": ..., "target": [1, 5, 10, 2], "dynamic_feat": [[0, 1, 1, 0]]} -
cat(opsional) —Sebuah array fitur kategoris yang dapat digunakan untuk menyandikan grup yang dimiliki rekaman tersebut. Fitur kategoris harus dikodekan sebagai urutan bilangan bulat positif berbasis 0. Misalnya, domain kategoris {R, G, B} dapat dikodekan sebagai {0, 1, 2}. Semua nilai dari setiap domain kategoris harus diwakili dalam kumpulan data pelatihan. Itu karena algoritma DeepAR hanya dapat memperkirakan untuk kategori yang telah diamati selama pelatihan. Dan, setiap fitur kategoris tertanam dalam ruang dimensi rendah yang dimensionalitasnya dikendalikan oleh hyperparameter.embedding_dimensionUntuk informasi selengkapnya, lihat DeepAR Hyperparameter.
Jika Anda menggunakan file JSON, itu harus dalam format JSON Lines
{"start": "2009-11-01 00:00:00", "target": [4.3, "NaN", 5.1, ...], "cat": [0, 1], "dynamic_feat": [[1.1, 1.2, 0.5, ...]]} {"start": "2012-01-30 00:00:00", "target": [1.0, -5.0, ...], "cat": [2, 3], "dynamic_feat": [[1.1, 2.05, ...]]} {"start": "1999-01-30 00:00:00", "target": [2.0, 1.0], "cat": [1, 4], "dynamic_feat": [[1.3, 0.4]]}
Dalam contoh ini, setiap deret waktu memiliki dua fitur kategoris terkait dan satu fitur deret waktu.
Untuk Parket, Anda menggunakan tiga bidang yang sama dengan kolom. Selain itu, "start" bisa menjadi datetime tipenya. Anda dapat mengompres file Parket menggunakan gzip (gzip) atau pustaka kompresi Snappy (). snappy
Jika algoritma dilatih tanpa cat dan dynamic_feat bidang, ia mempelajari model “global”, yaitu model yang agnostik dengan identitas spesifik dari deret waktu target pada waktu inferensi dan hanya dikondisikan pada bentuknya.
Jika model dikondisikan pada cat dan dynamic_feat fitur data yang disediakan untuk setiap deret waktu, prediksi mungkin akan dipengaruhi oleh karakter deret waktu dengan cat fitur yang sesuai. Misalnya, jika deret target waktu mewakili permintaan item pakaian, Anda dapat mengaitkan cat vektor dua dimensi yang mengkodekan jenis item (misalnya 0 = sepatu, 1 = pakaian) di komponen pertama dan warna item (misalnya 0 = merah, 1 = biru) di komponen kedua. Masukan sampel akan terlihat sebagai berikut:
{ "start": ..., "target": ..., "cat": [0, 0], ... } # red shoes { "start": ..., "target": ..., "cat": [1, 1], ... } # blue dress
Pada waktu inferensi, Anda dapat meminta prediksi untuk target dengan cat nilai yang merupakan kombinasi dari cat nilai yang diamati dalam data pelatihan, misalnya:
{ "start": ..., "target": ..., "cat": [0, 1], ... } # blue shoes { "start": ..., "target": ..., "cat": [1, 0], ... } # red dress
Pedoman berikut berlaku untuk data pelatihan:
-
Waktu mulai dan panjang deret waktu dapat berbeda. Misalnya, dalam pemasaran, produk sering memasuki katalog ritel pada tanggal yang berbeda, sehingga tanggal mulai mereka secara alami berbeda. Tetapi semua seri harus memiliki frekuensi yang sama, jumlah fitur kategoris, dan jumlah fitur dinamis.
-
Kocokkan file pelatihan sehubungan dengan posisi deret waktu dalam file. Dengan kata lain, deret waktu harus terjadi secara acak dalam file.
-
Pastikan untuk mengatur
startbidang dengan benar. Algoritma menggunakanstartstempel waktu untuk mendapatkan fitur internal. -
Jika Anda menggunakan fitur kategoris (
cat), semua deret waktu harus memiliki jumlah fitur kategoris yang sama. Jika kumpulan data berisicatbidang, algoritme menggunakannya dan mengekstrak kardinalitas grup dari kumpulan data. Secara default,cardinalityadalah"auto". Jika kumpulan data berisicatbidang, tetapi Anda tidak ingin menggunakannya, Anda dapat menonaktifkannya dengan menyetelcardinalityke"". Jika model dilatih menggunakancatfitur, Anda harus memasukkannya untuk inferensi. -
Jika kumpulan data Anda berisi
dynamic_featbidang, algoritme menggunakannya secara otomatis. Semua deret waktu harus memiliki jumlah rangkaian waktu fitur yang sama. Titik waktu di masing-masing deret waktu fitur sesuai satu-ke-satu dengan titik waktu dalam target. Selain itu, entri didynamic_featlapangan harus memiliki panjang yang sama dengantarget. Jika kumpulan data berisidynamic_featbidang, tetapi Anda tidak ingin menggunakannya, nonaktifkan dengan menyetel (num_dynamic_featto""). Jika model dilatih dengandynamic_featlapangan, Anda harus menyediakan bidang ini untuk inferensi. Selain itu, masing-masing fitur harus memiliki panjang target yang disediakan ditambahprediction_length. Dengan kata lain, Anda harus memberikan nilai fitur di masa depan.
Jika Anda menentukan data saluran uji opsional, algoritme DeepAR mengevaluasi model terlatih dengan metrik akurasi yang berbeda. Algoritma menghitung root mean square error (RMSE) atas data uji sebagai berikut:
![Rumus RMSE: Sqrt (1/nT(Jumlah [i, t] (y-hat (i, t) -y (i, t)) ^2)).](images/deepar-1.png)
y i,t adalah nilai sebenarnya dari deret waktu i pada waktu t. i,tadalah prediksi rata-rata. Jumlahnya melebihi semua n deret waktu dalam set uji dan selama τ titik waktu terakhir untuk setiap deret waktu, di mana τ sesuai dengan cakrawala perkiraan. Anda menentukan panjang horizon perkiraan dengan mengatur prediction_length hyperparameter. Untuk informasi selengkapnya, lihat DeepAR Hyperparameter.
Selain itu, algoritme mengevaluasi keakuratan distribusi perkiraan menggunakan kerugian kuantil tertimbang. Untuk kuantil dalam kisaran [0, 1], kerugian kuantil tertimbang didefinisikan sebagai berikut:
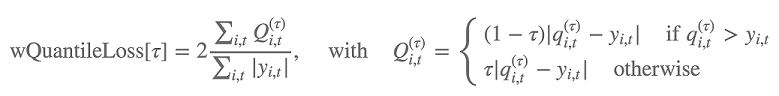
q i,t (τ) adalah τ-kuantil distribusi yang diprediksi model. Untuk menentukan kuantil mana yang akan menghitung kerugian, atur hyperparameter. test_quantiles Selain itu, rata-rata kerugian kuantil yang ditentukan dilaporkan sebagai bagian dari log pelatihan. Untuk informasi, lihat DeepAR Hyperparameter.
Untuk inferensi, DeepAR menerima format JSON dan bidang berikut:
-
"instances", yang mencakup satu atau lebih deret waktu dalam format JSON Lines -
Nama
"configuration", yang mencakup parameter untuk menghasilkan perkiraan
Untuk informasi selengkapnya, lihat Format Inferensi DeepAR.
Praktik Terbaik untuk Menggunakan Algoritma DeepAR
Saat menyiapkan data deret waktu Anda, ikuti praktik terbaik ini untuk mencapai hasil terbaik:
-
Kecuali saat membagi kumpulan data Anda untuk pelatihan dan pengujian, selalu sediakan seluruh deret waktu untuk pelatihan, pengujian, dan saat memanggil model untuk inferensi. Terlepas dari bagaimana Anda mengatur
context_length, jangan memecah deret waktu atau hanya menyediakan sebagian saja. Model menggunakan titik data lebih jauh ke belakang daripada nilai yang ditetapkancontext_lengthuntuk fitur nilai tertinggal. -
Saat menyetel model DeepAR, Anda dapat membagi kumpulan data untuk membuat kumpulan data pelatihan dan kumpulan data pengujian. Dalam evaluasi tipikal, Anda akan menguji model pada deret waktu yang sama yang digunakan untuk pelatihan, tetapi pada titik
prediction_lengthwaktu future yang mengikuti segera setelah titik waktu terakhir terlihat selama pelatihan. Anda dapat membuat kumpulan data pelatihan dan pengujian yang memenuhi kriteria ini dengan menggunakan seluruh kumpulan data (panjang penuh dari semua deret waktu yang tersedia) sebagai set pengujian dan menghapusprediction_lengthpoin terakhir dari setiap deret waktu untuk pelatihan. Selama pelatihan, model tidak melihat nilai target untuk titik waktu yang dievaluasi selama pengujian. Selama pengujian, algoritma menahanprediction_lengthpoin terakhir dari setiap deret waktu dalam set pengujian dan menghasilkan prediksi. Kemudian membandingkan perkiraan dengan nilai yang ditahan. Anda dapat membuat evaluasi yang lebih kompleks dengan mengulangi deret waktu beberapa kali dalam set pengujian, tetapi memotongnya pada titik akhir yang berbeda. Dengan pendekatan ini, metrik akurasi dirata-ratakan pada beberapa perkiraan dari titik waktu yang berbeda. Untuk informasi selengkapnya, lihat Menyetel Model DeepAR. -
Hindari menggunakan nilai yang sangat besar (>400)
prediction_lengthkarena itu membuat model lambat dan kurang akurat. Jika Anda ingin memperkirakan lebih jauh ke masa depan, pertimbangkan untuk menggabungkan data Anda pada frekuensi yang lebih rendah. Misalnya, gunakan5minsebagai ganti dari1min. -
Karena kelambatan digunakan, model dapat melihat lebih jauh ke belakang dalam deret waktu daripada nilai yang ditentukan.
context_lengthOleh karena itu, Anda tidak perlu mengatur parameter ini ke nilai yang besar. Sebaiknya mulai dengan nilai yang Anda gunakanprediction_length. -
Kami merekomendasikan pelatihan model DeepAR pada deret waktu sebanyak yang tersedia. Meskipun model DeepAR yang dilatih pada satu deret waktu mungkin bekerja dengan baik, algoritma peramalan standar, seperti ARIMA atau ETS, mungkin memberikan hasil yang lebih akurat. Algoritma DeepAR mulai mengungguli metode standar ketika dataset Anda berisi ratusan deret waktu terkait. Saat ini, DeepAR mensyaratkan bahwa jumlah total pengamatan yang tersedia di semua deret waktu pelatihan setidaknya 300.
Rekomendasi Instans EC2 untuk Algoritma DeepAR
Anda dapat melatih DeepAR pada instans GPU dan CPU dan dalam pengaturan tunggal dan multi-mesin. Sebaiknya mulai dengan satu instance CPU (misalnya, ml.c4.2xlarge atau ml.c4.4xlarge), dan beralih ke instance GPU dan beberapa mesin hanya jika diperlukan. Menggunakan GPU dan beberapa mesin meningkatkan throughput hanya untuk model yang lebih besar (dengan banyak sel per lapisan dan banyak lapisan) dan untuk ukuran mini-batch besar (misalnya, lebih besar dari 512).
Untuk inferensi, DeepAR hanya mendukung instance CPU.
Menentukan nilai besar untukcontext_length,prediction_length,num_cells,num_layers, atau mini_batch_size dapat membuat model yang terlalu besar untuk instance kecil. Dalam hal ini, gunakan jenis instance yang lebih besar atau kurangi nilai untuk parameter ini. Masalah ini juga sering terjadi saat menjalankan pekerjaan tuning hyperparameter. Dalam hal ini, gunakan tipe instance yang cukup besar untuk pekerjaan penyetelan model dan pertimbangkan untuk membatasi nilai atas parameter kritis untuk menghindari kegagalan pekerjaan.
Notebook Contoh DeepAR
Untuk contoh notebook yang menunjukkan cara menyiapkan kumpulan data deret waktu untuk melatih algoritme SageMaker AI DeepAR dan cara menerapkan model terlatih untuk melakukan inferensi, lihat Demo DeepAR tentang dataset listrik, yang menggambarkan fitur-fitur canggih DeepAR pada
Untuk informasi selengkapnya tentang algoritma Amazon SageMaker AI DeepAR, lihat posting blog berikut:
