Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Tentukan pipa
Untuk mengatur alur kerja Anda dengan SageMaker Amazon Pipelines, Anda harus membuat grafik asiklik terarah (DAG) dalam bentuk definisi pipeline JSON. DAG menentukan berbagai langkah yang terlibat dalam proses ML Anda, seperti prapemrosesan data, pelatihan model, evaluasi model, dan penerapan model, serta dependensi dan aliran data di antara langkah-langkah ini. Topik berikut menunjukkan cara menghasilkan definisi pipeline.
Anda dapat membuat definisi pipeline JSON menggunakan SageMaker Python SDK atau fitur drag-and-drop visual Pipeline Designer di Amazon Studio. SageMaker Gambar berikut adalah representasi dari pipeline DAG yang Anda buat dalam tutorial ini:
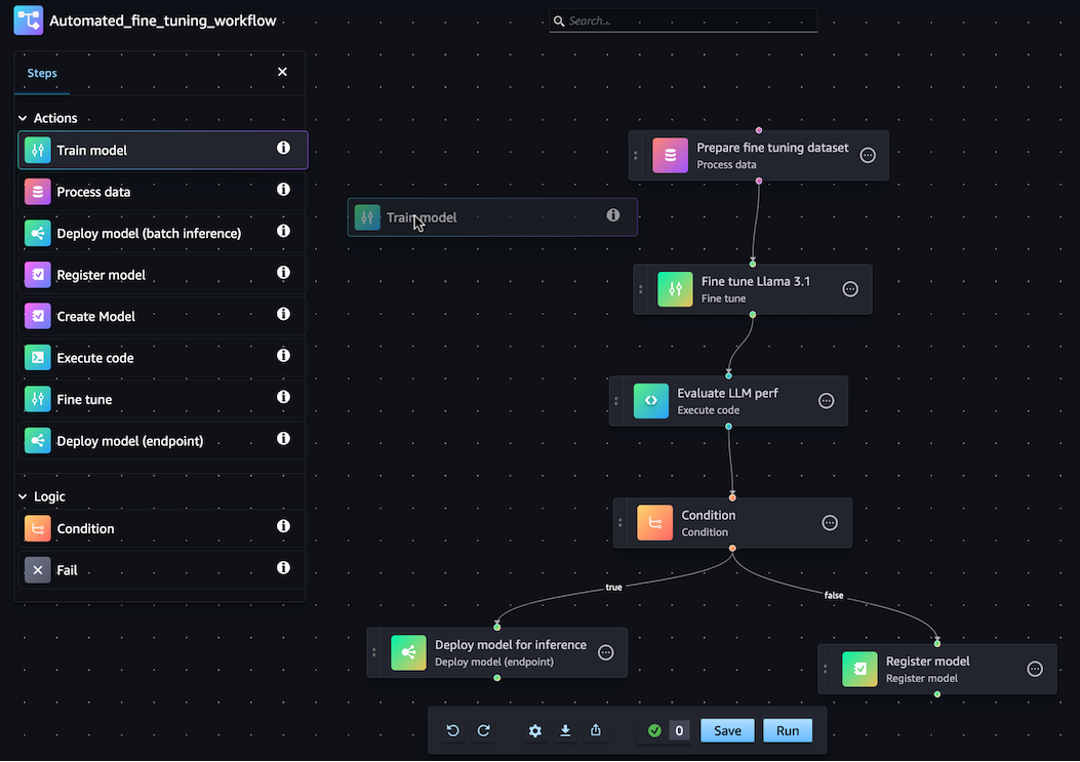
Pipa yang Anda tentukan di bagian berikut memecahkan masalah regresi untuk menentukan usia abalon berdasarkan pengukuran fisiknya. Untuk buku catatan Jupyter yang dapat dijalankan yang menyertakan konten dalam tutorial ini, lihat Mengatur Pekerjaan dengan Pipa Bangunan Model Amazon
catatan
Anda dapat mereferensikan lokasi model sebagai properti dari langkah pelatihan, seperti yang ditunjukkan pada end-to-end contoh CustomerChurn pipeline
Topik
Panduan berikut memandu Anda melalui langkah-langkah untuk membuat pipeline barebone menggunakan Pipeline Designer. drag-and-drop Jika Anda perlu menjeda atau mengakhiri sesi pengeditan Pipeline Anda di desainer visual kapan saja, klik opsi Ekspor. Ini memungkinkan Anda mengunduh definisi Pipeline saat ini ke lingkungan lokal Anda. Kemudian, ketika Anda ingin melanjutkan proses pengeditan Pipeline, Anda dapat mengimpor file definisi JSON yang sama ke desainer visual.
Buat langkah Pemrosesan
Untuk membuat langkah pekerjaan pemrosesan data, lakukan hal berikut:
-
Buka konsol Studio dengan mengikuti petunjuk diLuncurkan Amazon SageMaker Studio.
-
Di panel navigasi kiri, pilih Pipelines.
-
Pilih Buat.
-
Pilih Kosong.
-
Di bilah sisi kiri, pilih Proses data dan seret ke kanvas.
-
Di kanvas, pilih langkah Proses data yang Anda tambahkan.
-
Untuk menambahkan kumpulan data input, pilih Tambah di bawah Data (input) di bilah sisi kanan dan pilih kumpulan data.
-
Untuk menambahkan lokasi untuk menyimpan kumpulan data keluaran, pilih Tambah di bawah Data (output) di bilah sisi kanan dan arahkan ke tujuan.
-
Lengkapi bidang yang tersisa di sidebar kanan. Untuk informasi tentang bidang di tab ini, lihat sagemaker.workflow.steps. ProcessingStep
.
Buat langkah Pelatihan
Untuk mengatur langkah pelatihan model, lakukan hal berikut:
-
Di sidebar kiri, pilih Train model dan seret ke kanvas.
-
Di kanvas, pilih langkah model Kereta yang Anda tambahkan.
-
Untuk menambahkan kumpulan data input, pilih Tambah di bawah Data (input) di bilah sisi kanan dan pilih kumpulan data.
-
Untuk memilih lokasi untuk menyimpan artefak model Anda, masukkan URI Amazon S3 di bidang Lokasi (URI S3), atau pilih Jelajahi S3 untuk menavigasi ke lokasi tujuan.
-
Lengkapi bidang yang tersisa di sidebar kanan. Untuk informasi tentang bidang di tab ini, lihat sagemaker.workflow.steps. TrainingStep
. -
Klik dan seret kursor dari langkah Proses data yang Anda tambahkan di bagian sebelumnya ke langkah Model kereta untuk membuat tepi yang menghubungkan dua langkah.
Buat paket model dengan langkah model Register
Untuk membuat paket model dengan langkah pendaftaran model, lakukan hal berikut:
-
Di bilah sisi kiri, pilih Daftar model dan seret ke kanvas.
-
Di kanvas, pilih langkah model Daftar yang Anda tambahkan.
-
Untuk memilih model yang akan didaftarkan, pilih Tambah di bawah Model (input).
-
Pilih Buat grup model untuk menambahkan model Anda ke grup model baru.
-
Lengkapi bidang yang tersisa di sidebar kanan. Untuk informasi tentang bidang di tab ini, lihat sagemaker.workflow.step_collections. RegisterModel
. -
Klik dan seret kursor dari langkah model Kereta yang Anda tambahkan di bagian sebelumnya ke langkah model Daftar untuk membuat tepi yang menghubungkan dua langkah.
Terapkan model ke titik akhir dengan langkah model Deploy (titik akhir)
Untuk menerapkan model Anda menggunakan langkah penerapan model, lakukan hal berikut:
-
Di sidebar kiri, pilih Deploy model (endpoint) dan seret ke kanvas.
-
Di kanvas, pilih langkah Deploy model (endpoint) yang Anda tambahkan.
-
Untuk memilih model yang akan digunakan, pilih Tambah di bawah Model (input).
-
Pilih tombol Create endpoint radio untuk membuat endpoint baru.
-
Masukkan Nama dan Deskripsi untuk titik akhir Anda.
-
Klik dan seret kursor dari langkah model Register yang Anda tambahkan di bagian sebelumnya ke langkah Deploy model (endpoint) untuk membuat tepi yang menghubungkan dua langkah.
-
Lengkapi bidang yang tersisa di sidebar kanan.
Tentukan parameter Pipeline
Anda dapat mengonfigurasi satu set parameter Pipeline yang nilainya dapat diperbarui untuk setiap eksekusi. Untuk menentukan parameter pipa dan mengatur nilai default, klik ikon roda gigi di bagian bawah desainer visual.
Simpan Pipeline
Setelah Anda memasukkan semua informasi yang diperlukan untuk membuat pipeline Anda, klik Simpan di bagian bawah desainer visual. Ini memvalidasi pipeline Anda untuk setiap potensi kesalahan saat runtime dan memberi tahu Anda. Operasi Simpan tidak akan berhasil sampai Anda mengatasi semua kesalahan yang ditandai oleh pemeriksaan validasi otomatis. Jika Anda ingin melanjutkan pengeditan di lain waktu, Anda dapat menyimpan pipeline yang sedang berlangsung sebagai definisi JSON di lingkungan lokal Anda. Anda dapat mengekspor Pipeline Anda sebagai file definisi JSON dengan mengklik tombol Ekspor di bagian bawah desainer visual. Kemudian, untuk melanjutkan memperbarui Pipeline Anda, unggah file definisi JSON itu dengan mengklik tombol Impor.
Prasyarat
Untuk menjalankan tutorial berikut, lengkapi yang berikut ini:
-
Siapkan instance notebook Anda seperti yang diuraikan dalam Buat instance notebook. Ini memberi izin peran Anda untuk membaca dan menulis ke Amazon S3, dan membuat pelatihan, transformasi batch, dan pekerjaan SageMaker pemrosesan di AI.
-
Berikan izin buku catatan Anda untuk mendapatkan dan meneruskan perannya sendiri seperti yang ditunjukkan dalam Memodifikasi kebijakan izin peran. Tambahkan cuplikan JSON berikut untuk melampirkan kebijakan ini ke peran Anda. Ganti
<your-role-arn>dengan ARN yang digunakan untuk membuat instance notebook Anda.{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "iam:GetRole", "iam:PassRole" ], "Resource": "<your-role-arn>" } ] } -
Percayai prinsip layanan SageMaker AI dengan mengikuti langkah-langkah dalam Memodifikasi kebijakan kepercayaan peran. Tambahkan fragmen pernyataan berikut ke hubungan kepercayaan peran Anda:
{ "Sid": "", "Effect": "Allow", "Principal": { "Service": "sagemaker.amazonaws.com" }, "Action": "sts:AssumeRole" }
Siapkan lingkungan Anda
Buat sesi SageMaker AI baru menggunakan blok kode berikut. Ini mengembalikan peran ARN untuk sesi tersebut. Peran ARN ini harus menjadi peran eksekusi ARN yang Anda tetapkan sebagai prasyarat.
import boto3 import sagemaker import sagemaker.session from sagemaker.workflow.pipeline_context import PipelineSession region = boto3.Session().region_name sagemaker_session = sagemaker.session.Session() role = sagemaker.get_execution_role() default_bucket = sagemaker_session.default_bucket() pipeline_session = PipelineSession() model_package_group_name = f"AbaloneModelPackageGroupName"
Buat pipeline
penting
Kebijakan IAM khusus yang memungkinkan Amazon SageMaker Studio atau Amazon SageMaker Studio Classic membuat SageMaker sumber daya Amazon juga harus memberikan izin untuk menambahkan tag ke sumber daya tersebut. Izin untuk menambahkan tag ke sumber daya diperlukan karena Studio dan Studio Classic secara otomatis menandai sumber daya apa pun yang mereka buat. Jika kebijakan IAM memungkinkan Studio dan Studio Classic membuat sumber daya tetapi tidak mengizinkan penandaan, kesalahan "AccessDenied" dapat terjadi saat mencoba membuat sumber daya. Untuk informasi selengkapnya, lihat Berikan izin untuk menandai sumber daya AI SageMaker .
AWS kebijakan terkelola untuk Amazon SageMaker AIyang memberikan izin untuk membuat SageMaker sumber daya sudah menyertakan izin untuk menambahkan tag saat membuat sumber daya tersebut.
Jalankan langkah-langkah berikut dari instance notebook SageMaker AI Anda untuk membuat pipeline yang menyertakan langkah-langkah untuk:
-
prapemrosesan
-
pelatihan
-
evaluasi
-
evaluasi bersyarat
-
pendaftaran model
catatan
Anda dapat menggunakan ExecutionVariablesExecutionVariablesdiselesaikan saat runtime. Misalnya, ExecutionVariables.PIPELINE_EXECUTION_ID diselesaikan ke ID eksekusi saat ini, yang dapat digunakan sebagai pengidentifikasi unik di berbagai proses.
Langkah 1: Unduh dataset
Notebook ini menggunakan Dataset Abalone Machine Learning UCI. Dataset berisi fitur-fitur berikut:
-
length— Pengukuran cangkang terpanjang dari abalon. -
diameter— Diameter abalon tegak lurus dengan panjangnya. -
height— Ketinggian abalon dengan daging di cangkang. -
whole_weight— Berat seluruh abalon. -
shucked_weight— Berat daging dikeluarkan dari abalon. -
viscera_weight— Berat visera abalon setelah pendarahan. -
shell_weight— Berat cangkang abalon setelah pengangkatan dan pengeringan daging. -
sex- Jenis kelamin abalon. Salah satu dari 'M', 'F', atau 'I', di mana 'I' adalah abalon bayi. -
rings— Jumlah cincin di cangkang abalon.
Jumlah cincin dalam cangkang abalon adalah perkiraan yang baik untuk usianya menggunakan rumus. age=rings + 1.5 Namun, mendapatkan nomor ini adalah tugas yang memakan waktu. Anda harus memotong cangkang melalui kerucut, menodai bagian, dan menghitung jumlah cincin melalui mikroskop. Namun, pengukuran fisik lainnya lebih mudah didapat. Notebook ini menggunakan dataset untuk membangun model prediktif dari cincin variabel menggunakan pengukuran fisik lainnya.
Untuk mengunduh dataset
-
Unduh kumpulan data ke bucket Amazon S3 default akun Anda.
!mkdir -p data local_path = "data/abalone-dataset.csv" s3 = boto3.resource("s3") s3.Bucket(f"sagemaker-servicecatalog-seedcode-{region}").download_file( "dataset/abalone-dataset.csv", local_path ) base_uri = f"s3://{default_bucket}/abalone" input_data_uri = sagemaker.s3.S3Uploader.upload( local_path=local_path, desired_s3_uri=base_uri, ) print(input_data_uri) -
Unduh kumpulan data kedua untuk transformasi batch setelah model Anda dibuat.
local_path = "data/abalone-dataset-batch.csv" s3 = boto3.resource("s3") s3.Bucket(f"sagemaker-servicecatalog-seedcode-{region}").download_file( "dataset/abalone-dataset-batch", local_path ) base_uri = f"s3://{default_bucket}/abalone" batch_data_uri = sagemaker.s3.S3Uploader.upload( local_path=local_path, desired_s3_uri=base_uri, ) print(batch_data_uri)
Langkah 2: Tentukan parameter pipa
Blok kode ini mendefinisikan parameter berikut untuk pipeline Anda:
-
processing_instance_count— Jumlah instance dari pekerjaan pemrosesan. -
input_data— Lokasi Amazon S3 dari data input. -
batch_data— Lokasi Amazon S3 dari data input untuk transformasi batch. -
model_approval_status— Status persetujuan untuk mendaftarkan model terlatih untuk CI/CD. Untuk informasi selengkapnya, lihat MLOps Otomasi Dengan SageMaker Proyek.
from sagemaker.workflow.parameters import ( ParameterInteger, ParameterString, ) processing_instance_count = ParameterInteger( name="ProcessingInstanceCount", default_value=1 ) model_approval_status = ParameterString( name="ModelApprovalStatus", default_value="PendingManualApproval" ) input_data = ParameterString( name="InputData", default_value=input_data_uri, ) batch_data = ParameterString( name="BatchData", default_value=batch_data_uri, )
Langkah 3: Tentukan langkah pemrosesan untuk rekayasa fitur
Bagian ini menunjukkan cara membuat langkah pemrosesan untuk menyiapkan data dari kumpulan data untuk pelatihan.
Untuk membuat langkah pemrosesan
-
Buat direktori untuk skrip pemrosesan.
!mkdir -p abalone -
Buat file di
/abalonedirektori bernamapreprocessing.pydengan konten berikut. Skrip preprocessing ini diteruskan ke langkah pemrosesan untuk berjalan pada data input. Langkah pelatihan kemudian menggunakan fitur dan label pelatihan yang telah diproses sebelumnya untuk melatih model. Langkah evaluasi menggunakan model terlatih dan fitur dan label uji yang telah diproses sebelumnya untuk mengevaluasi model. Skrip digunakanscikit-learnuntuk melakukan hal berikut:-
Isi data
sexkategoris yang hilang dan kodekan sehingga cocok untuk pelatihan. -
Skala dan normalkan semua bidang numerik kecuali untuk
ringsdansex. -
Pisahkan data menjadi kumpulan data pelatihan, pengujian, dan validasi.
%%writefile abalone/preprocessing.py import argparse import os import requests import tempfile import numpy as np import pandas as pd from sklearn.compose import ColumnTransformer from sklearn.impute import SimpleImputer from sklearn.pipeline import Pipeline from sklearn.preprocessing import StandardScaler, OneHotEncoder # Because this is a headerless CSV file, specify the column names here. feature_columns_names = [ "sex", "length", "diameter", "height", "whole_weight", "shucked_weight", "viscera_weight", "shell_weight", ] label_column = "rings" feature_columns_dtype = { "sex": str, "length": np.float64, "diameter": np.float64, "height": np.float64, "whole_weight": np.float64, "shucked_weight": np.float64, "viscera_weight": np.float64, "shell_weight": np.float64 } label_column_dtype = {"rings": np.float64} def merge_two_dicts(x, y): z = x.copy() z.update(y) return z if __name__ == "__main__": base_dir = "/opt/ml/processing" df = pd.read_csv( f"{base_dir}/input/abalone-dataset.csv", header=None, names=feature_columns_names + [label_column], dtype=merge_two_dicts(feature_columns_dtype, label_column_dtype) ) numeric_features = list(feature_columns_names) numeric_features.remove("sex") numeric_transformer = Pipeline( steps=[ ("imputer", SimpleImputer(strategy="median")), ("scaler", StandardScaler()) ] ) categorical_features = ["sex"] categorical_transformer = Pipeline( steps=[ ("imputer", SimpleImputer(strategy="constant", fill_value="missing")), ("onehot", OneHotEncoder(handle_unknown="ignore")) ] ) preprocess = ColumnTransformer( transformers=[ ("num", numeric_transformer, numeric_features), ("cat", categorical_transformer, categorical_features) ] ) y = df.pop("rings") X_pre = preprocess.fit_transform(df) y_pre = y.to_numpy().reshape(len(y), 1) X = np.concatenate((y_pre, X_pre), axis=1) np.random.shuffle(X) train, validation, test = np.split(X, [int(.7*len(X)), int(.85*len(X))]) pd.DataFrame(train).to_csv(f"{base_dir}/train/train.csv", header=False, index=False) pd.DataFrame(validation).to_csv(f"{base_dir}/validation/validation.csv", header=False, index=False) pd.DataFrame(test).to_csv(f"{base_dir}/test/test.csv", header=False, index=False) -
-
Buat instance dari an
SKLearnProcessoruntuk diteruskan ke langkah pemrosesan.from sagemaker.sklearn.processing import SKLearnProcessor framework_version = "0.23-1" sklearn_processor = SKLearnProcessor( framework_version=framework_version, instance_type="ml.m5.xlarge", instance_count=processing_instance_count, base_job_name="sklearn-abalone-process", sagemaker_session=pipeline_session, role=role, ) -
Buat langkah pemrosesan. Langkah ini mengambil
SKLearnProcessor, saluran input dan output, danpreprocessing.pyskrip yang Anda buat. Ini sangat mirip denganrunmetode instance prosesor di SageMaker AI Python SDK.input_dataParameter yang diteruskanProcessingStepadalah data input dari langkah itu sendiri. Data input ini digunakan oleh instance prosesor saat berjalan.Perhatikan
"train,"validation, dan saluran"test"bernama yang ditentukan dalam konfigurasi output untuk pekerjaan pemrosesan. LangkahPropertiesseperti ini dapat digunakan dalam langkah-langkah berikutnya dan menyelesaikan nilai runtime mereka saat runtime.from sagemaker.processing import ProcessingInput, ProcessingOutput from sagemaker.workflow.steps import ProcessingStep processor_args = sklearn_processor.run( inputs=[ ProcessingInput(source=input_data, destination="/opt/ml/processing/input"), ], outputs=[ ProcessingOutput(output_name="train", source="/opt/ml/processing/train"), ProcessingOutput(output_name="validation", source="/opt/ml/processing/validation"), ProcessingOutput(output_name="test", source="/opt/ml/processing/test") ], code="abalone/preprocessing.py", ) step_process = ProcessingStep( name="AbaloneProcess", step_args=processor_args )
Langkah 4: Tentukan langkah pelatihan
Bagian ini menunjukkan cara menggunakan XGBoostAlgoritma SageMaker AI untuk melatih model pada output data pelatihan dari langkah-langkah pemrosesan.
Untuk menentukan langkah pelatihan
-
Tentukan jalur model tempat Anda ingin menyimpan model dari pelatihan.
model_path = f"s3://{default_bucket}/AbaloneTrain" -
Konfigurasikan estimator untuk XGBoost algoritme dan kumpulan data input. Jenis instance pelatihan diteruskan ke estimator. Skrip pelatihan yang khas:
-
memuat data dari saluran input
-
mengonfigurasi pelatihan dengan hyperparameters
-
melatih model
-
menyimpan model
model_diragar dapat di-host nanti
SageMaker AI mengunggah model ke Amazon S3 dalam bentuk
model.tar.gza di akhir pekerjaan pelatihan.from sagemaker.estimator import Estimator image_uri = sagemaker.image_uris.retrieve( framework="xgboost", region=region, version="1.0-1", py_version="py3", instance_type="ml.m5.xlarge" ) xgb_train = Estimator( image_uri=image_uri, instance_type="ml.m5.xlarge", instance_count=1, output_path=model_path, sagemaker_session=pipeline_session, role=role, ) xgb_train.set_hyperparameters( objective="reg:linear", num_round=50, max_depth=5, eta=0.2, gamma=4, min_child_weight=6, subsample=0.7, silent=0 ) -
-
Buat
TrainingStepmenggunakan instance estimator dan properti dari.ProcessingStepLewatiS3Urisaluran"train"dan"validation"output keTrainingStep.from sagemaker.inputs import TrainingInput from sagemaker.workflow.steps import TrainingStep train_args = xgb_train.fit( inputs={ "train": TrainingInput( s3_data=step_process.properties.ProcessingOutputConfig.Outputs[ "train" ].S3Output.S3Uri, content_type="text/csv" ), "validation": TrainingInput( s3_data=step_process.properties.ProcessingOutputConfig.Outputs[ "validation" ].S3Output.S3Uri, content_type="text/csv" ) }, ) step_train = TrainingStep( name="AbaloneTrain", step_args = train_args )
Langkah 5: Tentukan langkah pemrosesan untuk evaluasi model
Bagian ini menunjukkan cara membuat langkah pemrosesan untuk mengevaluasi keakuratan model. Hasil evaluasi model ini digunakan dalam langkah kondisi untuk menentukan jalur lari mana yang akan diambil.
Untuk menentukan langkah pemrosesan untuk evaluasi model
-
Buat file di
/abalonedirektori bernamaevaluation.py. Skrip ini digunakan dalam langkah pemrosesan untuk melakukan evaluasi model. Dibutuhkan model terlatih dan kumpulan data pengujian sebagai input, kemudian menghasilkan file JSON yang berisi metrik evaluasi klasifikasi.%%writefile abalone/evaluation.py import json import pathlib import pickle import tarfile import joblib import numpy as np import pandas as pd import xgboost from sklearn.metrics import mean_squared_error if __name__ == "__main__": model_path = f"/opt/ml/processing/model/model.tar.gz" with tarfile.open(model_path) as tar: tar.extractall(path=".") model = pickle.load(open("xgboost-model", "rb")) test_path = "/opt/ml/processing/test/test.csv" df = pd.read_csv(test_path, header=None) y_test = df.iloc[:, 0].to_numpy() df.drop(df.columns[0], axis=1, inplace=True) X_test = xgboost.DMatrix(df.values) predictions = model.predict(X_test) mse = mean_squared_error(y_test, predictions) std = np.std(y_test - predictions) report_dict = { "regression_metrics": { "mse": { "value": mse, "standard_deviation": std }, }, } output_dir = "/opt/ml/processing/evaluation" pathlib.Path(output_dir).mkdir(parents=True, exist_ok=True) evaluation_path = f"{output_dir}/evaluation.json" with open(evaluation_path, "w") as f: f.write(json.dumps(report_dict)) -
Buat sebuah instance dari
ScriptProcessoryang digunakan untuk membuatProcessingStep.from sagemaker.processing import ScriptProcessor script_eval = ScriptProcessor( image_uri=image_uri, command=["python3"], instance_type="ml.m5.xlarge", instance_count=1, base_job_name="script-abalone-eval", sagemaker_session=pipeline_session, role=role, ) -
Buat
ProcessingStepmenggunakan instance prosesor, saluran input dan output, danevaluation.pyskrip. Lulus:-
S3ModelArtifactsproperti dari langkahstep_trainpelatihan -
S3Urisaluran"test"output dari langkahstep_processpemrosesan
Ini sangat mirip dengan
runmetode instance prosesor di SageMaker AI Python SDK.from sagemaker.workflow.properties import PropertyFile evaluation_report = PropertyFile( name="EvaluationReport", output_name="evaluation", path="evaluation.json" ) eval_args = script_eval.run( inputs=[ ProcessingInput( source=step_train.properties.ModelArtifacts.S3ModelArtifacts, destination="/opt/ml/processing/model" ), ProcessingInput( source=step_process.properties.ProcessingOutputConfig.Outputs[ "test" ].S3Output.S3Uri, destination="/opt/ml/processing/test" ) ], outputs=[ ProcessingOutput(output_name="evaluation", source="/opt/ml/processing/evaluation"), ], code="abalone/evaluation.py", ) step_eval = ProcessingStep( name="AbaloneEval", step_args=eval_args, property_files=[evaluation_report], ) -
Langkah 6: Tentukan CreateModelStep untuk transformasi batch
penting
Kami merekomendasikan penggunaan Langkah model untuk membuat model pada v2.90.0 dari Python SDK. SageMaker CreateModelStepakan terus bekerja di versi SDK SageMaker Python sebelumnya, tetapi tidak lagi didukung secara aktif.
Bagian ini menunjukkan cara membuat model SageMaker AI dari output langkah pelatihan. Model ini digunakan untuk transformasi batch pada dataset baru. Langkah ini diteruskan ke langkah kondisi dan hanya berjalan jika langkah kondisi dievaluasi. true
Untuk menentukan transformasi CreateModelStep untuk batch
-
Buat model SageMaker AI. Lewati
S3ModelArtifactsproperti dari langkahstep_trainpelatihan.from sagemaker.model import Model model = Model( image_uri=image_uri, model_data=step_train.properties.ModelArtifacts.S3ModelArtifacts, sagemaker_session=pipeline_session, role=role, ) -
Tentukan input model untuk model SageMaker AI Anda.
from sagemaker.inputs import CreateModelInput inputs = CreateModelInput( instance_type="ml.m5.large", accelerator_type="ml.eia1.medium", ) -
Buat
CreateModelStepcontoh modelCreateModelInputdan SageMaker AI yang Anda tentukan.from sagemaker.workflow.steps import CreateModelStep step_create_model = CreateModelStep( name="AbaloneCreateModel", model=model, inputs=inputs, )
Langkah 7: Tentukan TransformStep untuk melakukan transformasi batch
Bagian ini menunjukkan cara membuat TransformStep untuk melakukan transformasi batch pada kumpulan data setelah model dilatih. Langkah ini diteruskan ke langkah kondisi dan hanya berjalan jika langkah kondisi dievaluasi. true
Untuk menentukan TransformStep untuk melakukan transformasi batch
-
Buat instance transformator dengan jenis instans komputasi yang sesuai, jumlah instans, dan URI bucket Amazon S3 keluaran yang diinginkan. Lewati
ModelNameproperti daristep_create_modelCreateModellangkah.from sagemaker.transformer import Transformer transformer = Transformer( model_name=step_create_model.properties.ModelName, instance_type="ml.m5.xlarge", instance_count=1, output_path=f"s3://{default_bucket}/AbaloneTransform" ) -
Buat
TransformStepmenggunakan instance transformator yang Anda tentukan dan parameterbatch_datapipeline.from sagemaker.inputs import TransformInput from sagemaker.workflow.steps import TransformStep step_transform = TransformStep( name="AbaloneTransform", transformer=transformer, inputs=TransformInput(data=batch_data) )
Langkah 8: Tentukan RegisterModel langkah untuk membuat paket model
penting
Kami merekomendasikan penggunaan Langkah model untuk mendaftarkan model pada v2.90.0 dari Python SDK. SageMaker RegisterModelakan terus bekerja di versi SDK SageMaker Python sebelumnya, tetapi tidak lagi didukung secara aktif.
Bagian ini menunjukkan cara membuat instance dariRegisterModel. Hasil berjalan RegisterModel dalam pipa adalah paket model. Paket model adalah abstraksi artefak model yang dapat digunakan kembali yang mengemas semua bahan yang diperlukan untuk inferensi. Ini terdiri dari spesifikasi inferensi yang mendefinisikan gambar inferensi untuk digunakan bersama dengan lokasi bobot model opsional. Grup paket model adalah kumpulan paket model. Anda dapat menggunakan ModelPackageGroup for Pipelines untuk menambahkan versi baru dan paket model ke grup untuk setiap pipeline yang dijalankan. Untuk informasi selengkapnya tentang registri model, lihatPenerapan Registrasi Model dengan Model Registry.
Langkah ini diteruskan ke langkah kondisi dan hanya berjalan jika langkah kondisi dievaluasi. true
Untuk menentukan RegisterModel langkah untuk membuat paket model
-
Buat
RegisterModellangkah menggunakan instance estimator yang Anda gunakan untuk langkah pelatihan. LewatiS3ModelArtifactsproperti dari langkahstep_trainpelatihan dan tentukan aModelPackageGroup. Pipelines menciptakan iniModelPackageGroupuntuk Anda.from sagemaker.model_metrics import MetricsSource, ModelMetrics from sagemaker.workflow.step_collections import RegisterModel model_metrics = ModelMetrics( model_statistics=MetricsSource( s3_uri="{}/evaluation.json".format( step_eval.arguments["ProcessingOutputConfig"]["Outputs"][0]["S3Output"]["S3Uri"] ), content_type="application/json" ) ) step_register = RegisterModel( name="AbaloneRegisterModel", estimator=xgb_train, model_data=step_train.properties.ModelArtifacts.S3ModelArtifacts, content_types=["text/csv"], response_types=["text/csv"], inference_instances=["ml.t2.medium", "ml.m5.xlarge"], transform_instances=["ml.m5.xlarge"], model_package_group_name=model_package_group_name, approval_status=model_approval_status, model_metrics=model_metrics )
Langkah 9: Tentukan langkah kondisi untuk memverifikasi akurasi model
A ConditionStep memungkinkan Pipelines untuk mendukung pengoperasian bersyarat di DAG pipeline Anda berdasarkan kondisi properti langkah. Dalam hal ini, Anda hanya ingin mendaftarkan paket model jika keakuratan model tersebut melebihi nilai yang diperlukan. Keakuratan model ditentukan oleh langkah evaluasi model. Jika akurasi melebihi nilai yang diperlukan, pipeline juga membuat Model SageMaker AI dan menjalankan transformasi batch pada kumpulan data. Bagian ini menunjukkan cara mendefinisikan langkah Kondisi.
Untuk menentukan langkah kondisi untuk memverifikasi akurasi model
-
Tentukan
ConditionLessThanOrEqualTokondisi menggunakan nilai akurasi yang ditemukan dalam output dari langkah pemrosesan evaluasi model,step_eval. Dapatkan output ini menggunakan file properti yang Anda indeks dalam langkah pemrosesan dan masing-masing JSONPath nilai kesalahan kuadrat rata-rata,."mse"from sagemaker.workflow.conditions import ConditionLessThanOrEqualTo from sagemaker.workflow.condition_step import ConditionStep from sagemaker.workflow.functions import JsonGet cond_lte = ConditionLessThanOrEqualTo( left=JsonGet( step_name=step_eval.name, property_file=evaluation_report, json_path="regression_metrics.mse.value" ), right=6.0 ) -
Membangun a.
ConditionStepLulusConditionEqualskondisi, lalu atur pendaftaran paket model dan langkah transformasi batch sebagai langkah selanjutnya jika kondisi berlalu.step_cond = ConditionStep( name="AbaloneMSECond", conditions=[cond_lte], if_steps=[step_register, step_create_model, step_transform], else_steps=[], )
Langkah 10: Buat pipeline
Sekarang setelah Anda membuat semua langkah, gabungkan mereka ke dalam pipeline.
Untuk membuat pipa
-
Tentukan hal berikut untuk pipeline Anda:
name,parameters, dansteps. Nama harus unik dalam(account, region)pasangan.catatan
Sebuah langkah hanya dapat muncul sekali di daftar langkah pipeline atau daftar langkah jika/lain dari langkah kondisi. Itu tidak bisa muncul di keduanya.
from sagemaker.workflow.pipeline import Pipeline pipeline_name = f"AbalonePipeline" pipeline = Pipeline( name=pipeline_name, parameters=[ processing_instance_count, model_approval_status, input_data, batch_data, ], steps=[step_process, step_train, step_eval, step_cond], ) -
(Opsional) Periksa definisi pipa JSON untuk memastikan bahwa itu terbentuk dengan baik.
import json json.loads(pipeline.definition())
Definisi pipeline ini siap dikirimkan ke SageMaker AI. Dalam tutorial berikutnya, Anda mengirimkan pipeline ini ke SageMaker AI dan mulai menjalankan.
Anda juga dapat menggunakan boto3
{'Version': '2020-12-01', 'Metadata': {}, 'Parameters': [{'Name': 'ProcessingInstanceType', 'Type': 'String', 'DefaultValue': 'ml.m5.xlarge'}, {'Name': 'ProcessingInstanceCount', 'Type': 'Integer', 'DefaultValue': 1}, {'Name': 'TrainingInstanceType', 'Type': 'String', 'DefaultValue': 'ml.m5.xlarge'}, {'Name': 'ModelApprovalStatus', 'Type': 'String', 'DefaultValue': 'PendingManualApproval'}, {'Name': 'ProcessedData', 'Type': 'String', 'DefaultValue': 'S3_URL', {'Name': 'InputDataUrl', 'Type': 'String', 'DefaultValue': 'S3_URL', 'PipelineExperimentConfig': {'ExperimentName': {'Get': 'Execution.PipelineName'}, 'TrialName': {'Get': 'Execution.PipelineExecutionId'}}, 'Steps': [{'Name': 'ReadTrainDataFromFS', 'Type': 'Processing', 'Arguments': {'ProcessingResources': {'ClusterConfig': {'InstanceType': 'ml.m5.4xlarge', 'InstanceCount': 2, 'VolumeSizeInGB': 30}}, 'AppSpecification': {'ImageUri': 'IMAGE_URI', 'ContainerArguments': [....]}, 'RoleArn': 'ROLE', 'ProcessingInputs': [...], 'ProcessingOutputConfig': {'Outputs': [.....]}, 'StoppingCondition': {'MaxRuntimeInSeconds': 86400}}, 'CacheConfig': {'Enabled': True, 'ExpireAfter': '30d'}}, ... ... ... }
Langkah selanjutnya: Jalankan pipa
