Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Siapkan kumpulan data
Pada langkah ini, Anda memuat kumpulan data Sensus Dewasa
Untuk menjalankan contoh berikut, tempelkan kode sampel ke dalam sel di instance notebook Anda.
Muat Dataset Sensus Dewasa Menggunakan SHAP
Menggunakan pustaka SHAP, impor dataset Sensus Dewasa seperti yang ditunjukkan berikut:
import shap X, y = shap.datasets.adult() X_display, y_display = shap.datasets.adult(display=True) feature_names = list(X.columns) feature_names
catatan
Jika kernel Jupyter saat ini tidak memiliki pustaka SHAP, instal dengan menjalankan perintah berikut: conda
%conda install -c conda-forge shap
Jika Anda menggunakan JupyterLab, Anda harus menyegarkan kernel secara manual setelah instalasi dan pembaruan selesai. Jalankan skrip IPython berikut untuk mematikan kernel (kernel akan restart secara otomatis):
import IPython IPython.Application.instance().kernel.do_shutdown(True)
Objek feature_names daftar harus mengembalikan daftar fitur berikut:
['Age', 'Workclass', 'Education-Num', 'Marital Status', 'Occupation', 'Relationship', 'Race', 'Sex', 'Capital Gain', 'Capital Loss', 'Hours per week', 'Country']
Tip
Jika memulai dengan data yang tidak berlabel, Anda dapat menggunakan Amazon SageMaker Ground Truth untuk membuat alur kerja pelabelan data dalam hitungan menit. Untuk mempelajari lebih lanjut, lihat Data Label.
Ikhtisar Dataset
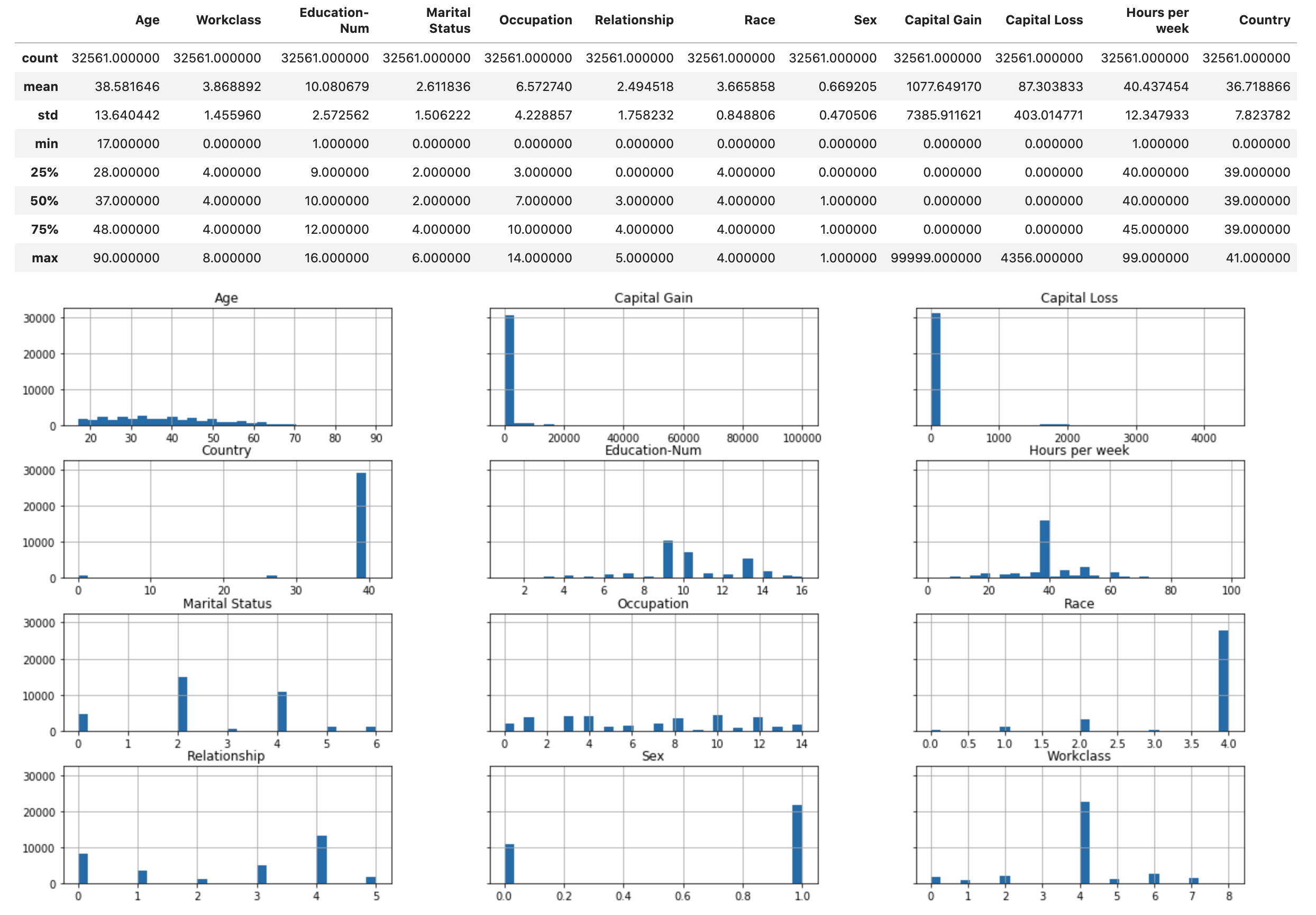
Jalankan skrip berikut untuk menampilkan ikhtisar statistik kumpulan data dan histogram fitur numerik.
display(X.describe()) hist = X.hist(bins=30, sharey=True, figsize=(20, 10))
Tip
Jika Anda ingin menggunakan kumpulan data yang perlu dibersihkan dan diubah, Anda dapat menyederhanakan dan merampingkan preprocessing data dan rekayasa fitur menggunakan Amazon Data Wrangler. SageMaker Untuk mempelajari lebih lanjut, lihat Mempersiapkan Data ML dengan Amazon SageMaker Data Wrangler.
Pisahkan Dataset menjadi Train, Validation, dan Test Datasets
Menggunakan Sklearn, bagi dataset menjadi satu set pelatihan dan set tes. Set pelatihan digunakan untuk melatih model, sedangkan set tes digunakan untuk mengevaluasi kinerja model terlatih akhir. Dataset diurutkan secara acak dengan benih acak tetap: 80 persen dari kumpulan data untuk set pelatihan dan 20 persennya untuk satu set tes.
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1) X_train_display = X_display.loc[X_train.index]
Pisahkan set pelatihan untuk memisahkan set validasi. Set validasi digunakan untuk mengevaluasi kinerja model yang dilatih sambil menyetel hiperparameter model. 75 persen dari set pelatihan menjadi set pelatihan akhir, dan sisanya adalah set validasi.
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.25, random_state=1) X_train_display = X_display.loc[X_train.index] X_val_display = X_display.loc[X_val.index]
Menggunakan paket pandas, secara eksplisit menyelaraskan setiap dataset dengan menggabungkan fitur numerik dengan label sebenarnya.
import pandas as pd train = pd.concat([pd.Series(y_train, index=X_train.index, name='Income>50K', dtype=int), X_train], axis=1) validation = pd.concat([pd.Series(y_val, index=X_val.index, name='Income>50K', dtype=int), X_val], axis=1) test = pd.concat([pd.Series(y_test, index=X_test.index, name='Income>50K', dtype=int), X_test], axis=1)
Periksa apakah kumpulan data dibagi dan terstruktur seperti yang diharapkan:
train
validation
test
Ubah Kumpulan Data Kereta dan Validasi ke File CSV
Konversi objek train dan kerangka validation data ke file CSV agar sesuai dengan format file input untuk algoritma XGBoost.
# Use 'csv' format to store the data # The first column is expected to be the output column train.to_csv('train.csv', index=False, header=False) validation.to_csv('validation.csv', index=False, header=False)
Unggah Kumpulan Data ke Amazon S3
Menggunakan SageMaker AI dan Boto3, unggah kumpulan data pelatihan dan validasi ke bucket Amazon S3 default. Kumpulan data dalam bucket S3 akan digunakan oleh instans yang dioptimalkan komputasi SageMaker di Amazon EC2 untuk pelatihan.
Kode berikut menyiapkan URI bucket S3 default untuk sesi SageMaker AI Anda saat ini, membuat demo-sagemaker-xgboost-adult-income-prediction folder baru, dan mengunggah kumpulan data pelatihan dan validasi ke subfolder. data
import sagemaker, boto3, os bucket = sagemaker.Session().default_bucket() prefix = "demo-sagemaker-xgboost-adult-income-prediction" boto3.Session().resource('s3').Bucket(bucket).Object( os.path.join(prefix, 'data/train.csv')).upload_file('train.csv') boto3.Session().resource('s3').Bucket(bucket).Object( os.path.join(prefix, 'data/validation.csv')).upload_file('validation.csv')
Jalankan berikut ini AWS CLI untuk memeriksa apakah file CSV berhasil diunggah ke bucket S3.
! aws s3 ls {bucket}/{prefix}/data --recursive
Ini harus mengembalikan output berikut:

