Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Bagaimana PCA Bekerja
Principal Component Analysis (PCA) adalah algoritma pembelajaran yang mengurangi dimensi (jumlah fitur) dalam kumpulan data sambil tetap mempertahankan informasi sebanyak mungkin.
PCA mengurangi dimensi dengan menemukan serangkaian fitur baru yang disebut komponen, yang merupakan komposit dari fitur asli, tetapi tidak berkorelasi satu sama lain. Komponen pertama menyumbang variabilitas terbesar yang mungkin dalam data, komponen kedua adalah variabilitas terbanyak kedua, dan seterusnya.
Ini adalah algoritma pengurangan dimensi tanpa pengawasan. Dalam pembelajaran tanpa pengawasan, label yang mungkin terkait dengan objek dalam kumpulan data pelatihan tidak digunakan.
Mengingat masukan matriks dengan baris
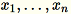 masing-masing dimensi
masing-masing dimensi1 * d, data dipartisi menjadi mini-batch baris dan didistribusikan di antara node pelatihan (pekerja). Setiap pekerja kemudian menghitung ringkasan datanya. Ringkasan dari pekerja yang berbeda kemudian disatukan menjadi satu solusi pada akhir perhitungan.
Modus
Algoritma Amazon SageMaker AI PCA menggunakan salah satu dari dua mode untuk menghitung ringkasan ini, tergantung pada situasinya:
-
reguler: untuk kumpulan data dengan data yang jarang dan jumlah pengamatan dan fitur yang moderat.
-
acak: untuk kumpulan data dengan sejumlah besar pengamatan dan fitur. Mode ini menggunakan algoritma aproksimasi.
Sebagai langkah terakhir algoritma, ia melakukan dekomposisi nilai tunggal pada solusi terpadu, dari mana komponen utama kemudian diturunkan.
Mode 1: Reguler
Para pekerja bersama-sama menghitung keduanya
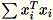 dan.
dan.
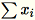
catatan
Karena
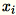 adalah vektor
adalah vektor 1 * d baris,
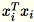 adalah matriks (bukan skalar). Menggunakan vektor baris dalam kode memungkinkan kita untuk mendapatkan caching yang efisien.
adalah matriks (bukan skalar). Menggunakan vektor baris dalam kode memungkinkan kita untuk mendapatkan caching yang efisien.
Matriks kovarians dihitung sebagai
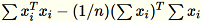 , dan vektor
, dan vektor num_components tunggal atasnya membentuk model.
catatan
Jika subtract_mean yaFalse, kami menghindari komputasi dan pengurangan
.
Gunakan algoritma ini ketika d dimensi vektor cukup kecil sehingga
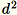 dapat masuk ke dalam memori.
dapat masuk ke dalam memori.
Mode 2: Acak
Ketika jumlah fitur dalam kumpulan data input besar, kami menggunakan metode untuk memperkirakan metrik kovarians. Untuk setiap mini-batch
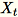 dimensi
dimensib * d, kami secara acak menginisialisasi (num_components + extra_components) * b matriks yang kami kalikan dengan setiap mini-batch, untuk membuat matriks. (num_components + extra_components) * d Jumlah matriks ini dihitung oleh pekerja, dan server melakukan SVD pada matriks akhir. (num_components + extra_components) * d Vektor num_components tunggal kanan atas itu adalah perkiraan vektor tunggal atas dari matriks input.
Biarkan
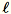
= num_components + extra_components. Diberikan kumpulan
dimensi minib * d, pekerja menggambar matriks
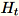 dimensi
dimensi
 acak. Tergantung pada apakah lingkungan menggunakan GPU atau CPU dan ukuran dimensi, matriks adalah matriks tanda acak di mana setiap entri
acak. Tergantung pada apakah lingkungan menggunakan GPU atau CPU dan ukuran dimensi, matriks adalah matriks tanda acak di mana setiap entri +-1 atau FJLT (transformasi cepat Johnson Lindenstrauss; untuk informasi, lihat Transformasi FJLT dan makalah tindak lanjut).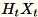 dan memelihara
dan memelihara
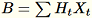 . Pekerja juga mempertahankan
. Pekerja juga mempertahankan
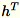 , jumlah kolom
, jumlah kolom
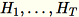 (
(Tmenjadi jumlah total mini-batch), dans, jumlah semua baris input. Setelah memproses seluruh pecahan data, pekerja mengirimkan serverB,, hs, dan n (jumlah baris input).
Menunjukkan input yang berbeda ke server sebagai Server
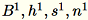 menghitung
menghitungB,, hs, n jumlah input masing-masing. Kemudian menghitung
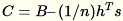 , dan menemukan dekomposisi nilai tunggalnya. Vektor tunggal kanan atas dan nilai tunggal
, dan menemukan dekomposisi nilai tunggalnya. Vektor tunggal kanan atas dan nilai tunggal C digunakan sebagai solusi perkiraan untuk masalah tersebut.
