Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Menyiapkan pekerjaan pelatihan untuk mengakses kumpulan data
Saat membuat pekerjaan pelatihan, Anda menentukan lokasi kumpulan data pelatihan dalam penyimpanan data pilihan Anda dan mode input data untuk pekerjaan itu. Amazon SageMaker AI mendukung Amazon Simple Storage Service (Amazon S3), Amazon Elastic File System (Amazon EFS), dan Amazon FSx for Lustre. Anda dapat memilih salah satu mode input untuk mengalirkan kumpulan data secara real time atau mengunduh seluruh kumpulan data di awal pekerjaan pelatihan.
catatan
Dataset Anda harus berada di tempat yang Wilayah AWS sama dengan pekerjaan pelatihan.
SageMaker Mode input AI dan AWS opsi penyimpanan cloud
Bagian ini memberikan gambaran umum tentang mode input file yang didukung oleh SageMaker untuk data yang disimpan di Amazon EFS dan Amazon FSx for Lustre.
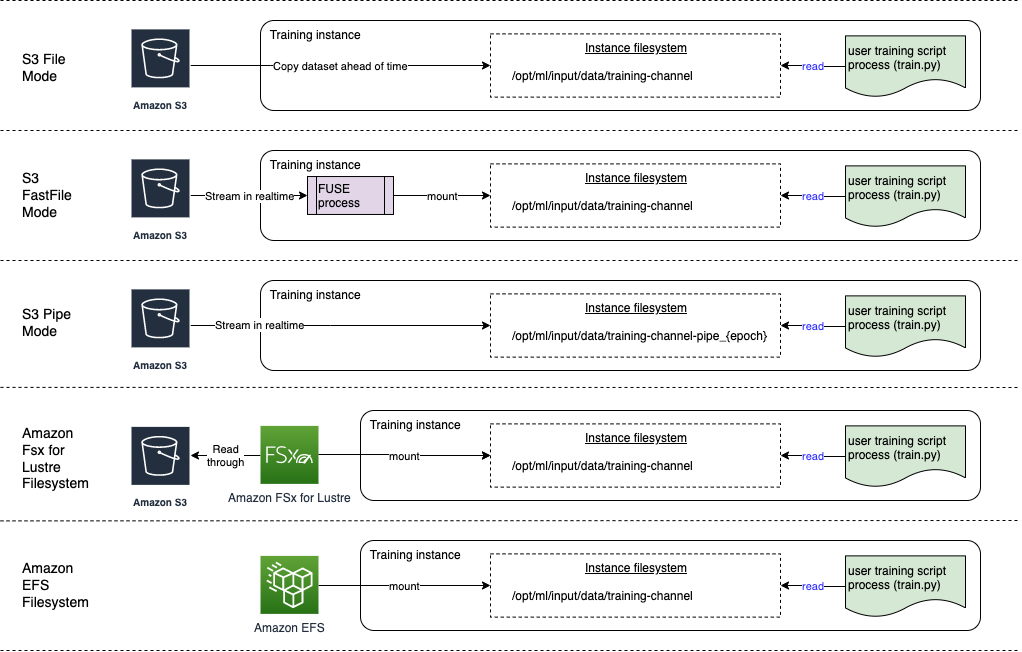
-
Mode file menyajikan tampilan sistem file dari kumpulan data ke wadah pelatihan. Ini adalah mode input default jika Anda tidak secara eksplisit menentukan salah satu dari dua opsi lainnya. Jika Anda menggunakan mode file, SageMaker AI mengunduh data pelatihan dari lokasi penyimpanan ke direktori lokal di wadah Docker. Pelatihan dimulai setelah kumpulan data lengkap diunduh. Dalam mode file, instance pelatihan harus memiliki ruang penyimpanan yang cukup agar sesuai dengan seluruh kumpulan data. Kecepatan unduh mode file tergantung pada ukuran kumpulan data, ukuran rata-rata file, dan jumlah file. Anda dapat mengonfigurasi kumpulan data untuk mode file dengan menyediakan awalan Amazon S3, file manifes, atau file manifes tambahan. Anda harus menggunakan awalan S3 ketika semua file dataset Anda berada dalam awalan S3 umum. Mode file kompatibel dengan mode lokal SageMaker AI
(memulai wadah SageMaker pelatihan secara interaktif dalam hitungan detik). Untuk pelatihan terdistribusi, Anda dapat memisahkan kumpulan data di beberapa instance dengan opsi. ShardedByS3Key -
Mode file cepat menyediakan akses sistem file ke sumber data Amazon S3 sambil memanfaatkan keunggulan kinerja mode pipa. Pada awal pelatihan, mode file cepat mengidentifikasi file data tetapi tidak mengunduhnya. Pelatihan dapat dimulai tanpa menunggu seluruh kumpulan data diunduh. Ini berarti bahwa startup pelatihan membutuhkan waktu lebih sedikit ketika ada lebih sedikit file di awalan Amazon S3 yang disediakan.
Berbeda dengan mode pipa, mode file cepat bekerja dengan akses acak ke data. Namun, ini berfungsi paling baik ketika data dibaca secara berurutan. Mode file cepat tidak mendukung file manifes tambahan.
Mode file cepat mengekspos objek S3 menggunakan antarmuka sistem POSIX-compliant file, seolah-olah file tersedia di disk lokal instance pelatihan Anda. Ini mengalirkan konten S3 sesuai permintaan karena skrip pelatihan Anda mengkonsumsi data. Ini berarti bahwa kumpulan data Anda tidak perlu lagi masuk ke dalam ruang penyimpanan instans pelatihan secara keseluruhan, dan Anda tidak perlu menunggu dataset diunduh ke instans pelatihan sebelum pelatihan dimulai. File cepat saat ini hanya mendukung awalan S3 (tidak mendukung manifes dan augmented manifest). Mode file cepat kompatibel dengan mode lokal SageMaker AI.
catatan
Menggunakan mode File Cepat dapat menyebabkan peningkatan CloudTrail biaya karena pencatatan tambahan:
-
Peristiwa data Amazon S3 (jika diaktifkan). CloudTrail
-
AWS KMS peristiwa dekripsi saat mengakses objek Amazon S3 yang dienkripsi dengan kunci. AWS KMS
-
Acara manajemen yang terkait dengan AWS KMS operasi.
Tinjau CloudTrail konfigurasi dan pemantauan biaya jika Anda mengaktifkan CloudTrail pencatatan untuk jenis acara ini.
-
-
Mode pipa mengalirkan data langsung dari sumber data Amazon S3. Streaming dapat memberikan waktu mulai yang lebih cepat dan throughput yang lebih baik daripada mode file.
Saat melakukan streaming data secara langsung, Anda dapat mengurangi ukuran volume Amazon EBS yang digunakan oleh instans pelatihan. Mode pipa hanya membutuhkan ruang disk yang cukup untuk menyimpan artefak model akhir.
Ini adalah mode streaming lain yang sebagian besar digantikan oleh mode file cepat yang lebih baru dan lebih mudah digunakan. Dalam mode pipa, data diambil sebelumnya dari Amazon S3 pada konkurensi dan throughput tinggi, dan dialirkan ke pipa bernama, yang juga dikenal sebagai pipa (FIFO) karena First-In-First-Out perilakunya. Setiap pipa hanya dapat dibaca dengan satu proses. Ekstensi khusus SageMaker AI untuk mengintegrasikan mode Pipa TensorFlow dengan mudah ke pemuat TensorFlow data asli
untuk streaming teks, TFRecords, atau format file Recordio. Mode pipa juga mendukung sharding dan shuffling data yang dikelola. -
Amazon S3 Express One Zone adalah kelas penyimpanan Availability Zone tunggal berkinerja tinggi yang dapat memberikan akses data milidetik satu digit yang konsisten untuk aplikasi yang paling sensitif terhadap latensi termasuk pelatihan model. SageMaker Amazon S3 Express One Zone memungkinkan pelanggan untuk mengumpulkan penyimpanan objek mereka dan menghitung sumber daya dalam satu AWS Availability Zone, mengoptimalkan kinerja komputasi dan biaya dengan peningkatan kecepatan pemrosesan data. Untuk lebih meningkatkan kecepatan akses dan mendukung ratusan ribu permintaan per detik, data disimpan dalam jenis bucket baru, bucket direktori Amazon S3.
SageMaker Pelatihan model AI mendukung bucket direktori Amazon S3 Express One Zone berkinerja tinggi sebagai lokasi input data untuk mode file, mode file cepat, dan mode pipa. Untuk menggunakan Amazon S3 Express One Zone, masukkan lokasi bucket direktori Amazon S3 Express One Zone, bukan bucket Amazon S3. Berikan ARN untuk peran IAM dengan kebijakan kontrol akses dan izin yang diperlukan. Lihat AmazonSageMakerFullAccesspolicy untuk detailnya. Anda hanya dapat mengenkripsi data keluaran SageMaker AI di bucket direktori dengan enkripsi sisi server dengan kunci terkelola Amazon S3 (). SSE-S3 Server-side enkripsi dengan AWS KMS keys (SSE-KMS) saat ini tidak didukung untuk menyimpan data keluaran SageMaker AI di bucket direktori. Untuk informasi selengkapnya, lihat Amazon S3 Express One Zone.
-
Amazon FSx for Lustre — FSx for Lustre dapat menskalakan hingga ratusan gigabyte throughput dan jutaan IOPS dengan pengambilan file latensi rendah. Saat memulai pekerjaan pelatihan, SageMaker AI memasang sistem file FSx for Lustre ke sistem file instance pelatihan, lalu memulai skrip pelatihan Anda. Pemasangan itu sendiri adalah operasi yang relatif cepat yang tidak bergantung pada ukuran kumpulan data yang disimpan di FSx for Lustre.
Untuk mengakses FSx for Lustre, tugas pelatihan Anda harus terhubung ke Amazon Virtual Private Cloud (VPC), yang memerlukan penyiapan dan keterlibatan. DevOps Untuk menghindari biaya transfer data, sistem file menggunakan Availability Zone tunggal, dan Anda perlu menentukan subnet VPC yang memetakan ke ID Availability Zone ini saat menjalankan tugas pelatihan.
-
Amazon EFS — Untuk menggunakan Amazon EFS sebagai sumber data, data harus sudah berada di Amazon EFS sebelum pelatihan. SageMaker AI memasang sistem file Amazon EFS yang ditentukan ke instans pelatihan, lalu memulai skrip pelatihan Anda. Pekerjaan pelatihan Anda harus terhubung ke VPC untuk mengakses Amazon EFS.
Tip
Untuk mempelajari lebih lanjut tentang cara menentukan konfigurasi VPC Anda ke estimator SageMaker AI, lihat Menggunakan Sistem File sebagai Input Pelatihan
dalam dokumentasi AI SageMaker Python SDK.
