Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Pengantar Paralelisme Model
Paralelisme model adalah metode pelatihan terdistribusi di mana model pembelajaran mendalam dipartisi di beberapa perangkat, di dalam atau di seluruh instance. Halaman pengantar ini memberikan gambaran tingkat tinggi tentang paralelisme model, deskripsi tentang bagaimana hal itu dapat membantu mengatasi masalah yang muncul saat melatih model DL yang biasanya berukuran sangat besar, dan contoh apa yang ditawarkan perpustakaan SageMaker paralel model untuk membantu mengelola strategi paralel model serta konsumsi memori.
Apa itu Paralelisme Model?
Meningkatkan ukuran model pembelajaran mendalam (lapisan dan parameter) menghasilkan akurasi yang lebih baik untuk tugas-tugas kompleks seperti visi komputer dan pemrosesan bahasa alami. Namun, ada batasan untuk ukuran model maksimum yang dapat Anda muat dalam memori satu GPU. Saat melatih model DL, batasan memori GPU dapat menjadi hambatan dengan cara berikut:
-
Mereka membatasi ukuran model yang dapat Anda latih, karena jejak memori model berskala proporsional dengan jumlah parameter.
-
Mereka membatasi ukuran batch per GPU selama pelatihan, menurunkan pemanfaatan GPU dan efisiensi pelatihan.
Untuk mengatasi keterbatasan yang terkait dengan pelatihan model pada satu GPU, SageMaker sediakan pustaka paralel model untuk membantu mendistribusikan dan melatih model DL secara efisien pada beberapa node komputasi. Selain itu, dengan perpustakaan, Anda dapat mencapai pelatihan terdistribusi yang paling dioptimalkan menggunakan EFA-supported perangkat, yang meningkatkan kinerja komunikasi antar-node dengan latensi rendah, throughput tinggi, dan bypass OS.
Perkirakan Persyaratan Memori Sebelum Menggunakan Paralelisme Model
Sebelum Anda menggunakan perpustakaan paralel SageMaker model, pertimbangkan hal berikut untuk memahami persyaratan memori untuk melatih model DL besar.
Untuk pekerjaan pelatihan yang menggunakan pengoptimal AMP (FP16) dan Adam, memori GPU yang diperlukan per parameter adalah sekitar 20 byte, yang dapat kami uraikan sebagai berikut:
-
Parameter FP16 ~ 2 byte
-
Gradien FP16 ~ 2 byte
-
Status pengoptimal FP32 ~ 8 byte berdasarkan pengoptimal Adam
-
Salinan parameter FP32 ~ 4 byte (diperlukan untuk operasi (OA
optimizer apply)) -
Salinan gradien FP32 ~ 4 byte (diperlukan untuk operasi OA)
Bahkan untuk model DL yang relatif kecil dengan 10 miliar parameter, dapat memerlukan setidaknya 200GB memori, yang jauh lebih besar daripada memori GPU biasa (misalnya, NVIDIA A100 dengan 40GB/80GB memori dan V100 dengan 16/32 GB) tersedia pada satu GPU. Perhatikan bahwa di atas persyaratan memori untuk status model dan pengoptimal, ada konsumen memori lain seperti aktivasi yang dihasilkan dalam pass maju. Memori yang dibutuhkan bisa jauh lebih besar dari 200GB.
Untuk pelatihan terdistribusi, kami menyarankan Anda menggunakan instans Amazon EC2 P3 dan P4 yang masing-masing memiliki GPU NVIDIA V100 dan A100 Tensor Core. Untuk detail selengkapnya tentang spesifikasi seperti inti CPU, RAM, volume penyimpanan terlampir, dan bandwidth jaringan, lihat bagian Komputasi Akselerasi di halaman Jenis Instans Amazon EC2
Bahkan dengan instans komputasi yang dipercepat, jelas bahwa model dengan sekitar 10 miliar parameter seperti Megatron-LM dan T5 dan bahkan model yang lebih besar dengan ratusan miliar parameter seperti GPT-3 tidak dapat memuat replika model di setiap perangkat GPU.
Bagaimana Perpustakaan Menggunakan Paralelisme Model dan Teknik Penghematan Memori
Pustaka terdiri dari berbagai jenis fitur paralelisme model dan fitur hemat memori seperti sharding status pengoptimal, checkpointing aktivasi, dan pembongkaran aktivasi. Semua teknik ini dapat digabungkan untuk melatih model besar secara efisien yang terdiri dari ratusan miliar parameter.
Paralelisme data sharded (tersedia untuk) PyTorch
Paralelisme data sharded adalah teknik pelatihan terdistribusi hemat memori yang membagi status model (parameter model, gradien, dan status pengoptimal) di seluruh GPU dalam grup data-paralel.
Anda dapat menerapkan paralelisme data sharded ke model Anda sebagai strategi yang berdiri sendiri. Selain itu, jika Anda menggunakan instans GPU paling berkinerja yang dilengkapi dengan GPU NVIDIA A100 Tensor Coreml.p4d.24xlarge, Anda dapat memanfaatkan peningkatan kecepatan pelatihan dari operasi yang ditawarkan oleh SMDDP Collectives. AllGather
Untuk menyelam jauh ke dalam paralelisme data sharded dan mempelajari cara mengaturnya atau menggunakan kombinasi paralelisme data sharded dengan teknik lain seperti paralelisme tensor dan pelatihan FP16, lihat. Paralelisme Data Sharded
Paralelisme pipa (tersedia untuk PyTorch dan) TensorFlow
Paralelisme pipa mempartisi kumpulan lapisan atau operasi di seluruh rangkaian perangkat, membiarkan setiap operasi tetap utuh. Ketika Anda menentukan nilai untuk jumlah partisi model (pipeline_parallel_degree), jumlah total GPU (processes_per_host) harus habis dibagi dengan jumlah partisi model. Untuk mengatur ini dengan benar, Anda harus menentukan nilai yang benar untuk pipeline_parallel_degree dan processes_per_host parameter. Matematika sederhana adalah sebagai berikut:
(pipeline_parallel_degree) x (data_parallel_degree) = processes_per_host
Pustaka menangani penghitungan jumlah replika model (juga disebutdata_parallel_degree) mengingat dua parameter input yang Anda berikan.
Misalnya, jika Anda menyetel "pipeline_parallel_degree": 2 dan "processes_per_host": 8 menggunakan instance ML dengan delapan pekerja GPU sepertiml.p3.16xlarge, pustaka akan secara otomatis menyiapkan model terdistribusi di seluruh GPU dan paralelisme data empat arah. Gambar berikut menggambarkan bagaimana model didistribusikan di delapan GPU yang mencapai paralelisme data empat arah dan paralelisme pipa dua arah. Setiap replika model, di mana kami mendefinisikannya sebagai grup paralel pipeline dan memberi label sebagaiPP_GROUP, dipartisi di dua GPU. Setiap partisi model ditetapkan ke empat GPU, di mana empat replika partisi berada dalam grup paralel data dan diberi label sebagai. DP_GROUP Tanpa paralelisme tensor, grup paralel pipa pada dasarnya adalah kelompok paralel model.
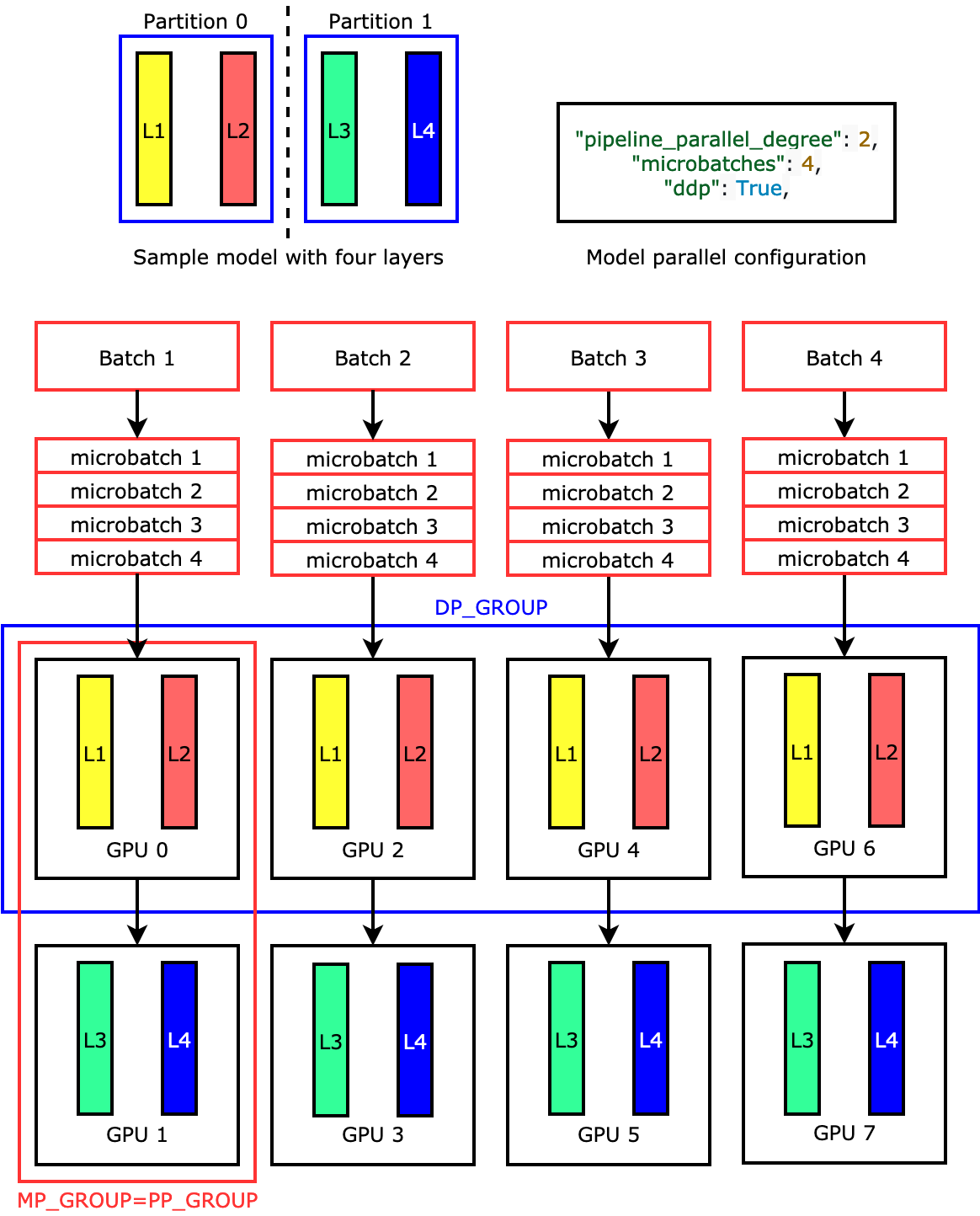
Untuk menyelam jauh ke dalam paralelisme pipa, lihat. Fitur Inti dari Perpustakaan Paralelisme SageMaker Model
Untuk memulai menjalankan model menggunakan paralelisme pipeline, lihat Menjalankan Job Pelatihan SageMaker Terdistribusi dengan Perpustakaan Paralel SageMaker Model.
Paralelisme tensor (tersedia untuk) PyTorch
Paralelisme tensor membagi lapisan individu, atau, di seluruh perangkatnn.Modules, untuk dijalankan secara paralel. Gambar berikut menunjukkan contoh paling sederhana tentang bagaimana perpustakaan membagi model dengan empat lapisan untuk mencapai paralelisme tensor dua arah (). "tensor_parallel_degree": 2 Lapisan setiap replika model dibagi dua dan didistribusikan menjadi dua GPU. Dalam contoh kasus ini, konfigurasi paralel model juga mencakup "pipeline_parallel_degree": 1 dan "ddp": True (menggunakan PyTorch DistributedDataParallel paket di latar belakang), sehingga tingkat paralelisme data menjadi delapan. Perpustakaan mengelola komunikasi di seluruh replika model terdistribusi tensor.
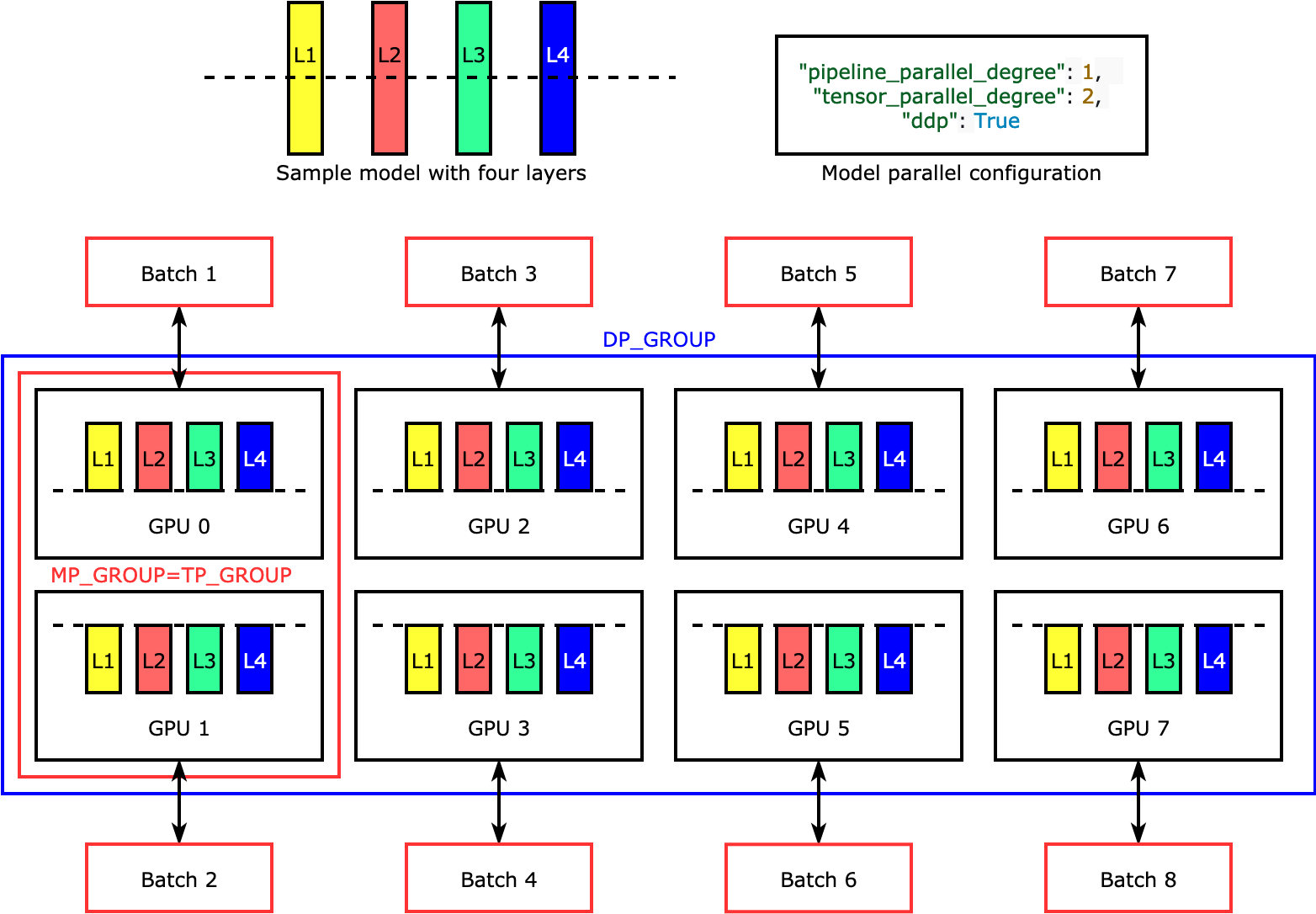
Kegunaan fitur ini adalah kenyataan bahwa Anda dapat memilih lapisan tertentu atau subset lapisan untuk menerapkan paralelisme tensor. Untuk menyelam jauh ke dalam paralelisme tensor dan fitur hemat memori lainnya untuk PyTorch, dan untuk mempelajari cara mengatur kombinasi paralelisme pipa dan tensor, lihat. Paralelisme Tensor
Sharding status pengoptimal (tersedia untuk) PyTorch
Untuk memahami bagaimana pustaka melakukan sharding status pengoptimal, pertimbangkan contoh model sederhana dengan empat lapisan. Ide kunci dalam mengoptimalkan sharding status adalah Anda tidak perlu mereplikasi status pengoptimal Anda di semua GPU Anda. Sebagai gantinya, satu replika status pengoptimal dibagi di seluruh peringkat paralel data, tanpa redundansi di seluruh perangkat. Misalnya, GPU 0 memegang status pengoptimal untuk lapisan satu, GPU 1 berikutnya memegang status pengoptimal untuk L2, dan seterusnya. Gambar animasi berikut menunjukkan propagasi mundur dengan teknik sharding status pengoptimal. Di akhir propagasi mundur, ada waktu komputasi dan jaringan untuk operasi optimizer apply (OA) untuk memperbarui status pengoptimal dan operasi all-gather (AG) untuk memperbarui parameter model untuk iterasi berikutnya. Yang terpenting, reduce operasi dapat tumpang tindih dengan komputasi pada GPU 0, menghasilkan propagasi mundur yang lebih efisien memori dan lebih cepat. Dalam implementasi saat ini, operasi AG dan OA tidak tumpang tindih dengancompute. Ini dapat menghasilkan perhitungan yang diperpanjang selama operasi AG, jadi mungkin ada tradeoff.
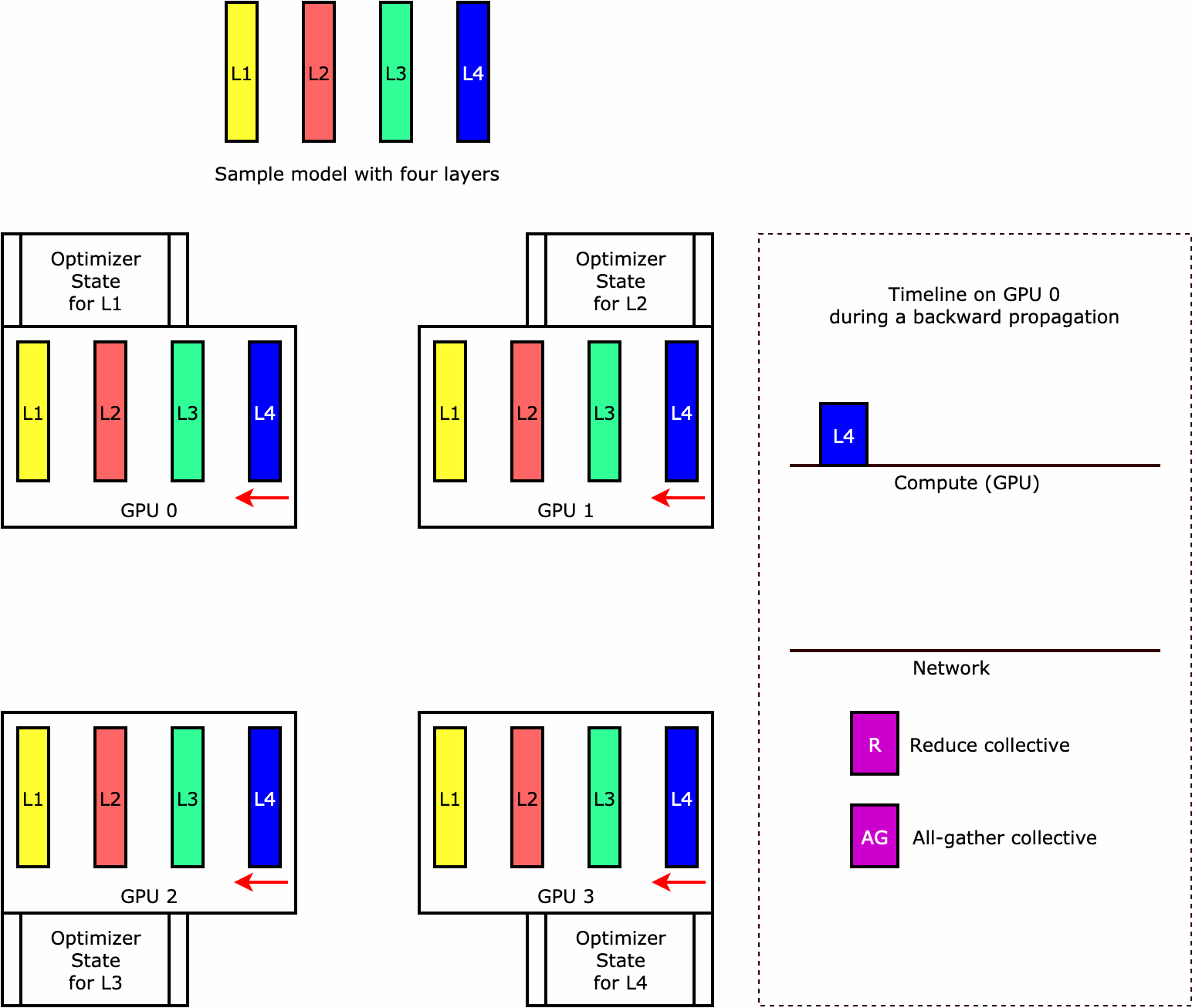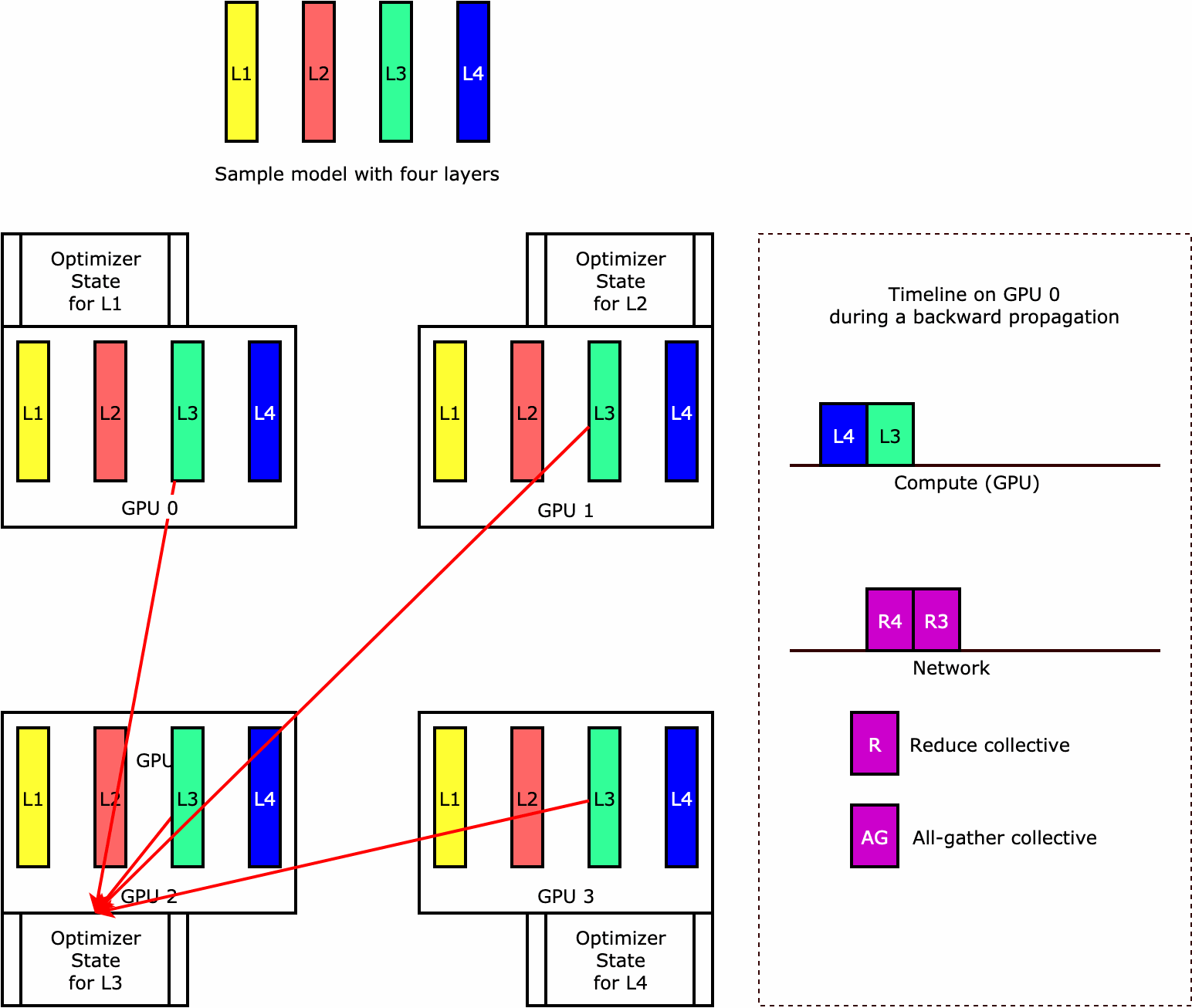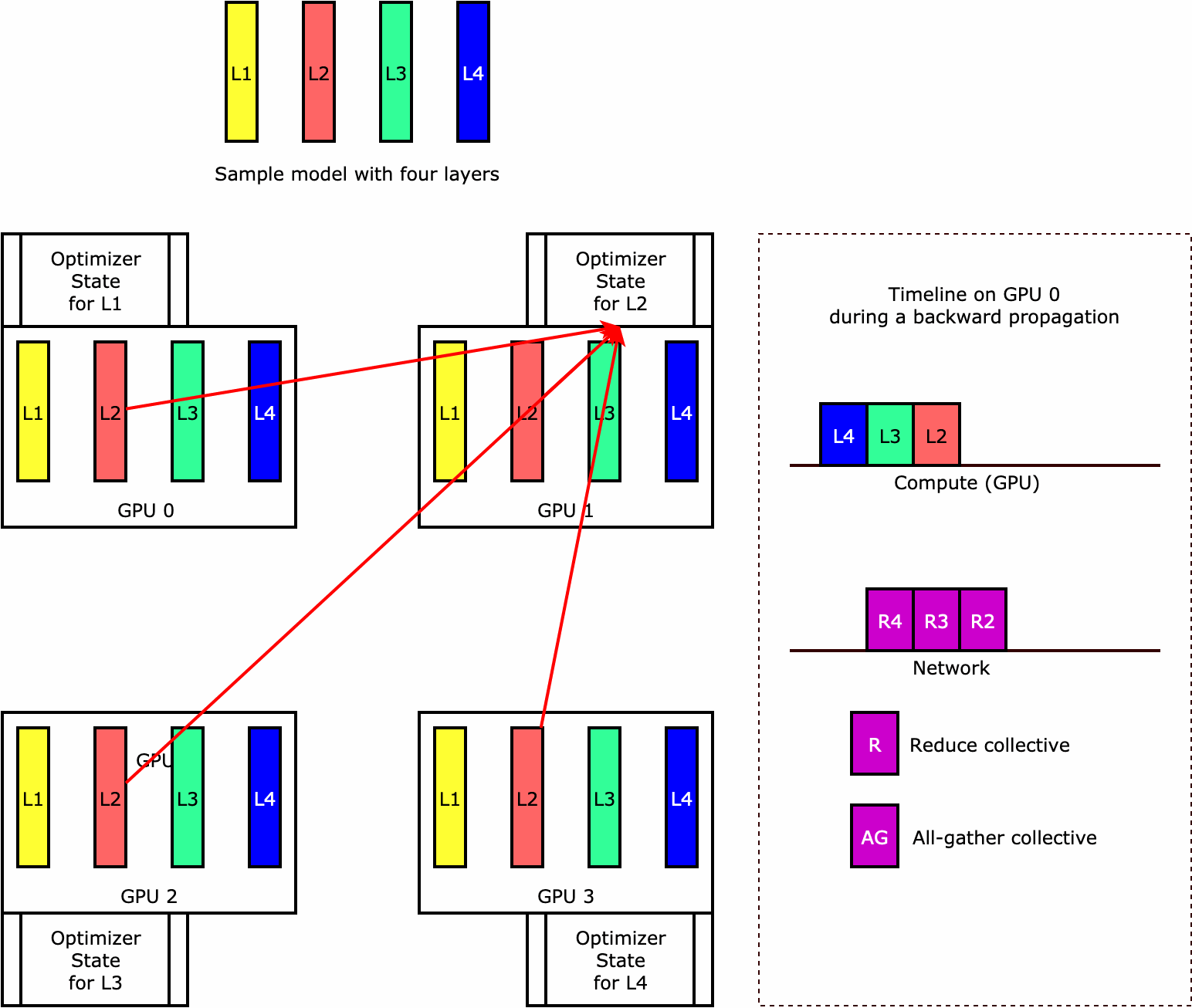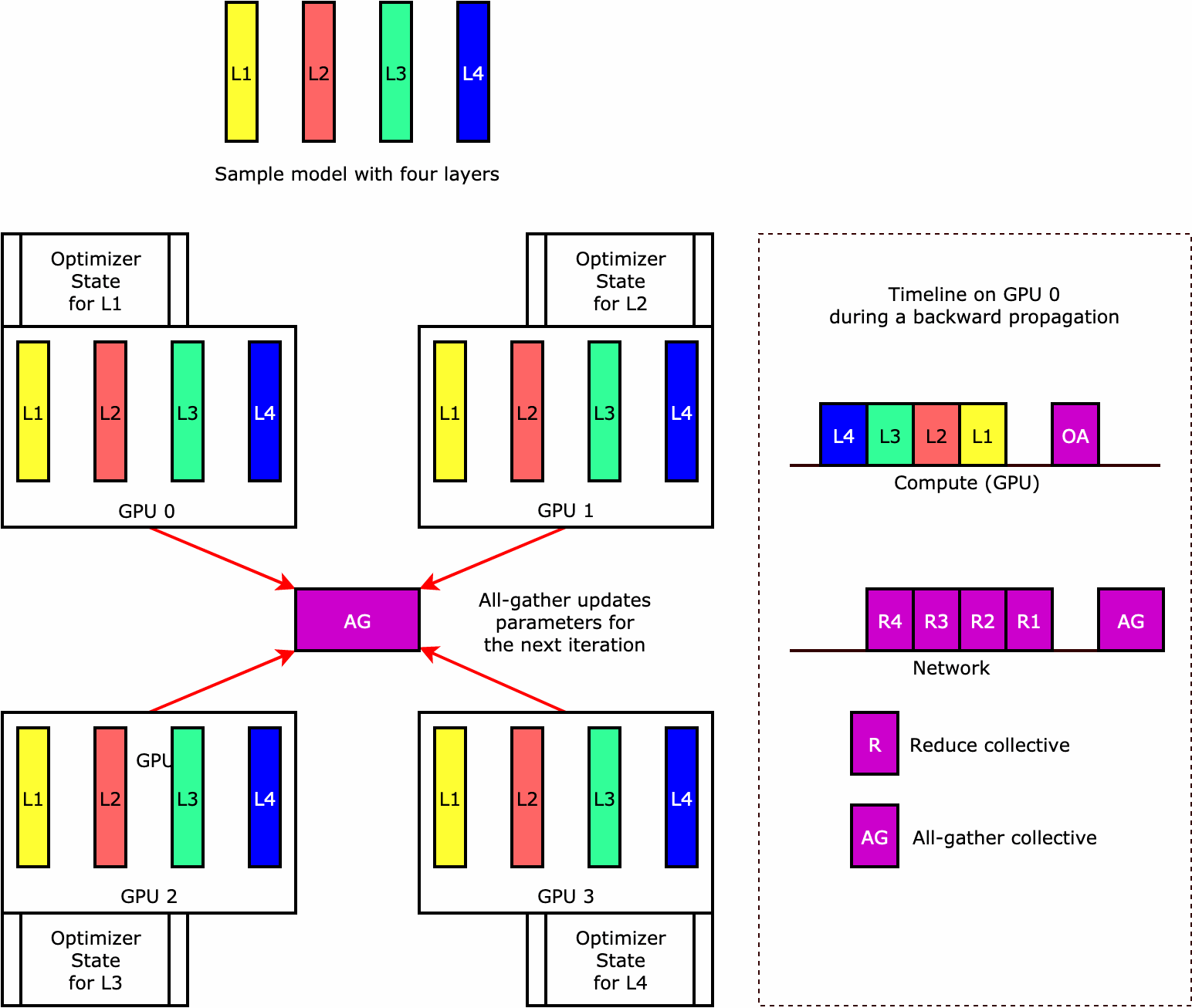
Untuk informasi selengkapnya tentang cara menggunakan fitur ini, lihat Sharding Status Optimizer.
Aktivasi pembongkaran dan checkpointing (tersedia untuk) PyTorch
Untuk menyimpan memori GPU, pustaka mendukung checkpointing aktivasi untuk menghindari penyimpanan aktivasi internal dalam memori GPU untuk modul yang ditentukan pengguna selama forward pass. Pustaka menghitung ulang aktivasi ini selama pass mundur. Selain itu, fitur pembongkaran aktivasi menurunkan aktivasi yang disimpan ke memori CPU dan mengambil kembali ke GPU selama lintasan mundur untuk lebih mengurangi jejak memori aktivasi. Untuk informasi selengkapnya tentang cara menggunakan fitur ini, lihat Pos Pemeriksaan Aktivasi dan Pembongkaran Aktivasi.
Memilih teknik yang tepat untuk model Anda
Untuk informasi selengkapnya tentang memilih teknik dan konfigurasi yang tepat, lihat Praktik Terbaik Paralel Model SageMaker Terdistribusi dan Tips dan Perangkap Konfigurasi.
