Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Laporan kinerja model
Laporan kualitas SageMaker model Amazon (juga disebut sebagai laporan kinerja) memberikan wawasan dan informasi kualitas untuk kandidat model terbaik yang dihasilkan oleh pekerjaan AutoML. Ini termasuk informasi tentang detail pekerjaan, jenis masalah model, fungsi objektif, dan berbagai metrik. Bagian ini merinci isi laporan kinerja untuk masalah klasifikasi teks dan menjelaskan cara mengakses metrik sebagai data mentah dalam JSON file.
Anda dapat menemukan awalan Amazon S3 untuk artefak laporan kualitas model yang dihasilkan untuk kandidat terbaik dalam menanggapi at. DescribeAutoMLJobV2 BestCandidate.CandidateProperties.CandidateArtifactLocations.ModelInsights
Laporan kinerja berisi dua bagian:
-
Bagian pertama berisi rincian tentang pekerjaan Autopilot yang menghasilkan model.
-
Bagian kedua berisi laporan kualitas model dengan berbagai metrik kinerja.
Detail pekerjaan Autopilot
Bagian pertama dari laporan ini memberikan beberapa informasi umum tentang pekerjaan Autopilot yang menghasilkan model. Rincian ini mencakup informasi berikut:
-
Nama kandidat autopilot: Nama kandidat model terbaik.
-
Nama pekerjaan autopilot: Nama pekerjaan.
-
Jenis masalah: Jenis masalah. Dalam kasus kami, klasifikasi teks.
-
Metrik objektif: Metrik objektif yang digunakan untuk mengoptimalkan kinerja model. Dalam kasus kami, Akurasi.
-
Arah optimasi: Menunjukkan apakah akan meminimalkan atau memaksimalkan metrik objektif.
Laporan kualitas model
Informasi kualitas model dihasilkan oleh wawasan model Autopilot. Konten laporan yang dihasilkan bergantung pada jenis masalah yang ditangani. Laporan tersebut menentukan jumlah baris yang disertakan dalam dataset evaluasi dan waktu evaluasi terjadi.
Tabel metrik
Bagian pertama dari laporan kualitas model berisi tabel metrik. Ini sesuai untuk jenis masalah yang ditangani model.
Gambar berikut adalah contoh tabel metrik yang dihasilkan oleh Autopilot untuk masalah klasifikasi gambar atau teks. Ini menunjukkan nama metrik, nilai, dan standar deviasi.
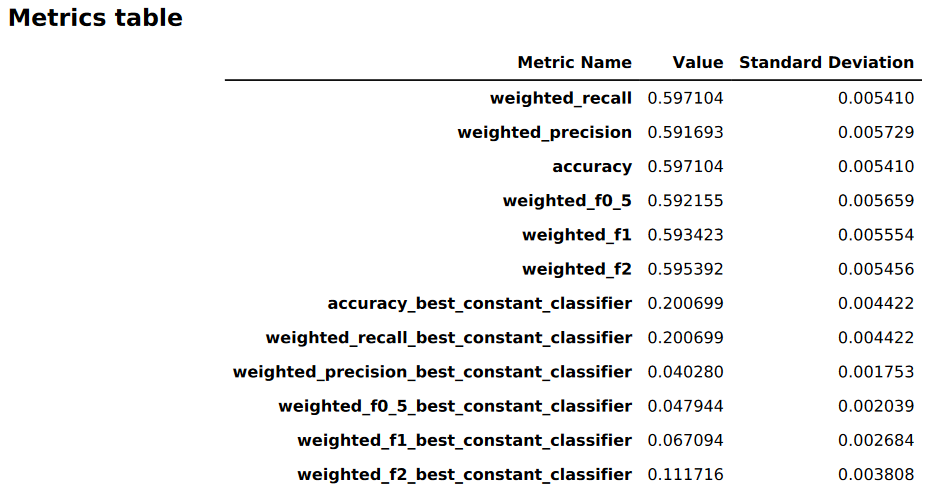
Informasi kinerja model grafis
Bagian kedua dari laporan kualitas model berisi informasi grafis untuk membantu Anda mengevaluasi kinerja model. Isi bagian ini tergantung pada jenis masalah yang dipilih.
Matriks kebingungan
Matriks kebingungan menyediakan cara untuk memvisualisasikan keakuratan prediksi yang dibuat oleh model untuk klasifikasi biner dan multikelas untuk masalah yang berbeda.
Ringkasan komponen grafik dari tingkat positif palsu (FPR) dan tingkat positif sejati (TPR) didefinisikan sebagai berikut.
-
Prediksi yang benar
-
True positive (TP): Nilai yang diprediksi adalah 1, dan nilai sebenarnya adalah 1.
-
Benar negatif (TN): Nilai yang diprediksi adalah 0, dan nilai sebenarnya adalah 0.
-
-
Prediksi yang salah
-
Positif palsu (FP): Nilai yang diprediksi adalah 1, tetapi nilai sebenarnya adalah 0.
-
False negative (FN): Nilai yang diprediksi adalah 0, tetapi nilai sebenarnya adalah 1.
-
Matriks kebingungan dalam laporan kualitas model berisi yang berikut ini.
-
Jumlah dan persentase prediksi yang benar dan salah untuk label yang sebenarnya
-
Jumlah dan persentase prediksi akurat pada diagonal dari kiri atas ke pojok kanan bawah
-
Jumlah dan persentase prediksi yang tidak akurat pada diagonal dari kanan atas ke sudut kiri bawah
Prediksi yang salah pada matriks kebingungan adalah nilai kebingungan.
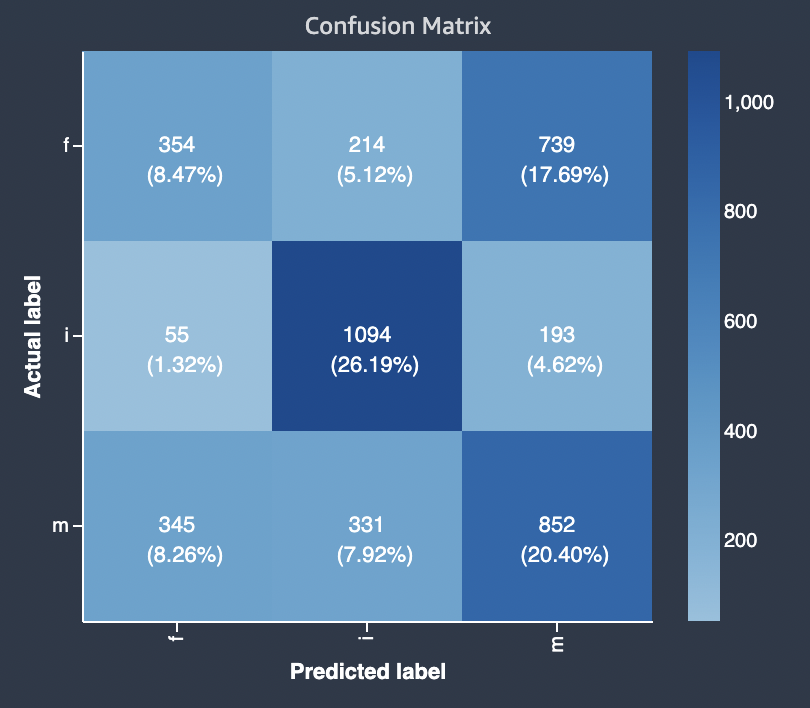
Diagram berikut adalah contoh matriks kebingungan untuk masalah klasifikasi multi-kelas. Matriks kebingungan dalam laporan kualitas model berisi yang berikut ini.
-
Sumbu vertikal dibagi menjadi tiga baris yang berisi tiga label aktual yang berbeda.
-
Sumbu horizontal dibagi menjadi tiga kolom yang berisi label yang diprediksi oleh model.
-
Bilah warna memberikan nada yang lebih gelap ke sejumlah besar sampel untuk secara visual menunjukkan jumlah nilai yang diklasifikasikan dalam setiap kategori.
Dalam contoh di bawah ini, model dengan benar memprediksi 354 nilai aktual untuk label f, 1094 nilai untuk label i dan 852 nilai untuk label m. Perbedaan nada menunjukkan bahwa kumpulan data tidak seimbang karena ada lebih banyak label untuk nilai i daripada untuk f atau m.
Matriks kebingungan dalam laporan kualitas model yang disediakan dapat mengakomodasi maksimum 15 label untuk jenis masalah klasifikasi multikelas. Jika baris yang sesuai dengan label menunjukkan Nan nilai, itu berarti kumpulan data validasi yang digunakan untuk memeriksa prediksi model tidak berisi data dengan label tersebut.
