Untuk kemampuan serupa dengan Amazon Timestream LiveAnalytics, pertimbangkan Amazon Timestream untuk InfluxDB. Ini menawarkan konsumsi data yang disederhanakan dan waktu respons kueri milidetik satu digit untuk analitik waktu nyata. Pelajari lebih lanjut di sini.
Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Arsitektur
Amazon Timestream untuk Live Analytics telah dirancang dari bawah ke atas untuk mengumpulkan, menyimpan, dan memproses data deret waktu dalam skala besar. Arsitektur tanpa servernya mendukung penyerapan data, penyimpanan, dan sistem pemrosesan kueri yang sepenuhnya dipisahkan yang dapat diskalakan secara independen. Desain ini menyederhanakan setiap subsistem, membuatnya lebih mudah untuk mencapai keandalan yang tak tergoyahkan, menghilangkan hambatan penskalaan, dan mengurangi kemungkinan kegagalan sistem yang berkorelasi. Masing-masing faktor ini menjadi lebih penting seiring dengan skala sistem.
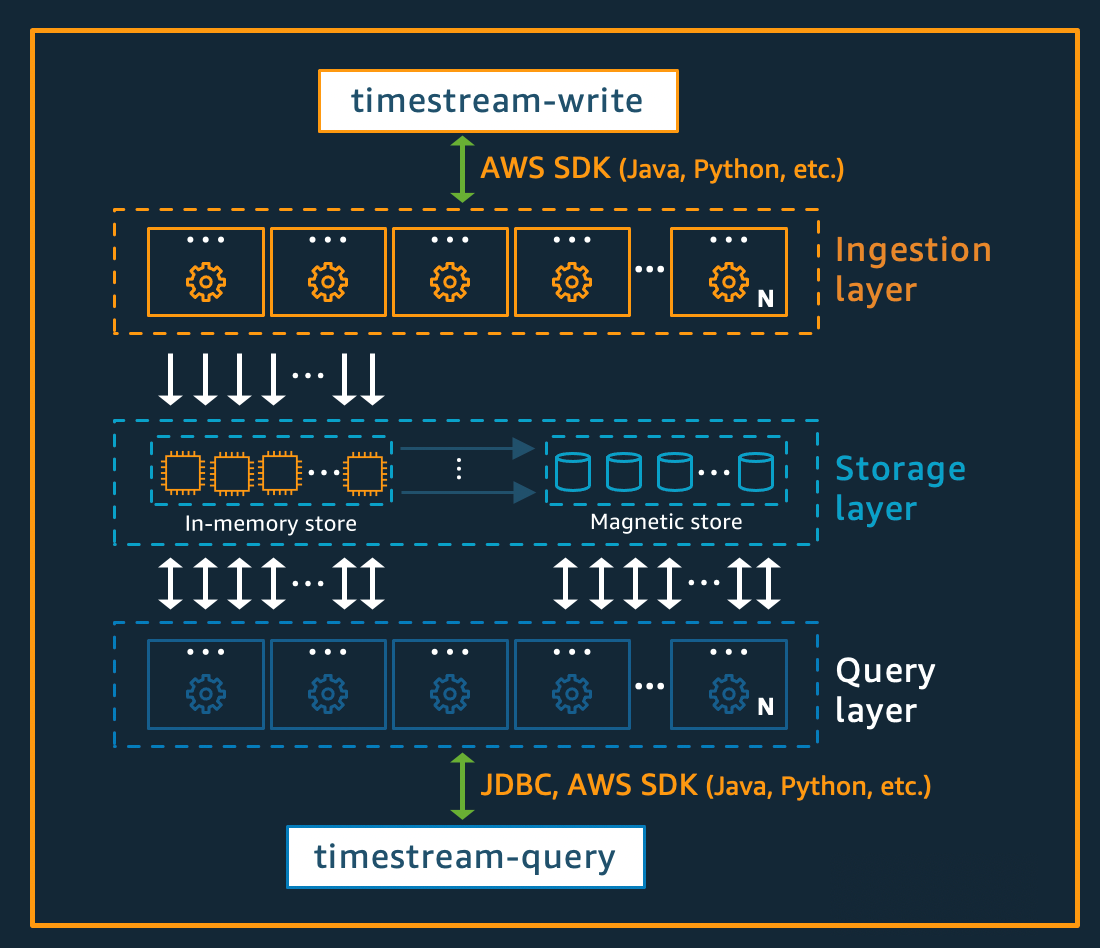
Tulis arsitektur
Saat menulis data deret waktu, rute Amazon Timestream untuk Live Analytics menulis untuk tabel, partisi, ke instance penyimpanan memori toleran kesalahan yang memproses penulisan data throughput tinggi. Penyimpanan memori pada gilirannya mencapai daya tahan dalam sistem penyimpanan terpisah yang mereplikasi data di tiga Availability Zones ()AZs. Replikasi berbasis kuorum sehingga hilangnya node, atau seluruh AZ, tidak akan mengganggu ketersediaan penulisan. Dalam waktu dekat, node penyimpanan dalam memori lainnya disinkronkan ke data untuk melayani kueri. Node replika pembaca AZs juga menjangkau, untuk memastikan ketersediaan baca yang tinggi.
Timestream untuk Live Analytics mendukung penulisan data langsung ke penyimpanan magnetik, untuk aplikasi yang menghasilkan data yang datang terlambat dengan throughput yang lebih rendah. Data yang datang terlambat adalah data dengan stempel waktu lebih awal dari waktu saat ini. Mirip dengan throughput tinggi yang ditulis di penyimpanan memori, data yang ditulis ke dalam penyimpanan magnetik direplikasi di tiga AZs dan replikasi berbasis kuorum.
Baik data ditulis ke memori atau penyimpanan magnetik, Timestream for Live Analytics secara otomatis mengindeks dan mempartisi data sebelum menulisnya ke penyimpanan. Satu tabel Timestream untuk Live Analytics mungkin memiliki ratusan, ribuan, atau bahkan jutaan partisi. Partisi individu tidak, secara langsung, berkomunikasi satu sama lain dan tidak berbagi data apa pun (arsitektur tanpa berbagi). Sebaliknya, partisi tabel dilacak melalui layanan pelacakan dan pengindeksan partisi yang sangat tersedia. Ini memberikan pemisahan masalah lain yang dirancang khusus untuk meminimalkan efek kegagalan dalam sistem dan membuat kegagalan yang berkorelasi jauh lebih kecil kemungkinannya.
Arsitektur penyimpanan
Ketika data disimpan dalam Timestream untuk Live Analytics, data diatur dalam urutan waktu serta sepanjang waktu berdasarkan atribut konteks yang ditulis dengan data. Memiliki skema partisi yang membagi “ruang” selain waktu penting untuk menskalakan sistem deret waktu secara besar-besaran. Ini karena sebagian besar data deret waktu ditulis pada atau sekitar waktu saat ini. Akibatnya, partisi berdasarkan waktu saja tidak melakukan pekerjaan yang baik dalam mendistribusikan lalu lintas tulis atau memungkinkan pemangkasan data yang efektif pada waktu kueri. Ini penting untuk pemrosesan deret waktu skala ekstrim, dan ini memungkinkan Timestream untuk Live Analytics untuk menskalakan urutan besarnya lebih tinggi daripada sistem terkemuka lainnya di luar sana saat ini dengan cara tanpa server. Partisi yang dihasilkan disebut sebagai “ubin” karena mereka mewakili divisi dari ruang dua dimensi (yang dirancang untuk menjadi ukuran yang sama). Timestream untuk tabel Live Analytics dimulai sebagai partisi tunggal (ubin), dan kemudian dibagi dalam dimensi spasial sesuai kebutuhan throughput. Ketika ubin mencapai ukuran tertentu, mereka kemudian membelah dalam dimensi waktu untuk mencapai paralelisme baca yang lebih baik saat ukuran data tumbuh.
Timestream for Live Analytics dirancang untuk mengelola siklus hidup data deret waktu secara otomatis. Timestream for Live Analytics menawarkan dua penyimpanan data—penyimpanan dalam memori dan penyimpanan magnetik yang hemat biaya. Ini juga mendukung konfigurasi kebijakan tingkat tabel untuk secara otomatis mentransfer data di seluruh toko. Data throughput tinggi yang masuk menulis mendarat di penyimpanan memori tempat data dioptimalkan untuk penulisan, serta pembacaan yang dilakukan sekitar waktu saat ini untuk memberi daya pada dasbor dan mengingatkan kueri jenis. Ketika kerangka waktu utama untuk kebutuhan penulisan, peringatan, dan dasbor telah berlalu, memungkinkan data mengalir secara otomatis dari penyimpanan memori ke penyimpanan magnetik untuk mengoptimalkan biaya. Timestream untuk Live Analytics memungkinkan pengaturan kebijakan penyimpanan data di penyimpanan memori untuk tujuan ini. Data yang ditulis untuk data yang datang terlambat secara langsung ditulis ke dalam penyimpanan magnetik.
Setelah data tersedia di penyimpanan magnetik (karena berakhirnya periode penyimpanan penyimpanan memori atau karena penulisan langsung ke penyimpanan magnetik), itu direorganisasi ke dalam format yang sangat dioptimalkan untuk pembacaan data volume besar. Penyimpanan magnetik juga memiliki kebijakan retensi data yang dapat dikonfigurasi jika ada ambang waktu di mana data melebihi kegunaannya. Ketika data melebihi rentang waktu yang ditentukan untuk kebijakan penyimpanan penyimpanan magnetik, data akan dihapus secara otomatis. Oleh karena itu, dengan Timestream untuk Live Analytics, selain beberapa konfigurasi, manajemen siklus hidup data terjadi dengan mulus di belakang layar.
Arsitektur kueri
Kueri Timestream untuk Live Analytics dinyatakan dalam tata bahasa SQL yang memiliki ekstensi untuk dukungan khusus seri waktu (tipe dan fungsi data spesifik seri waktu), sehingga kurva pembelajaran mudah bagi pengembang yang sudah terbiasa dengan SQL. Kueri kemudian diproses oleh mesin kueri terdistribusi adaptif yang menggunakan metadata dari layanan pelacakan dan pengindeksan ubin untuk mengakses dan menggabungkan data dengan mulus di seluruh penyimpanan data pada saat kueri dikeluarkan. Ini membuat pengalaman yang beresonansi dengan baik dengan pelanggan karena meruntuhkan banyak kompleksitas Rube Goldberg menjadi abstraksi database yang sederhana dan akrab.
Kueri dijalankan oleh armada pekerja khusus di mana jumlah pekerja yang terdaftar untuk menjalankan kueri tertentu ditentukan oleh kompleksitas kueri dan ukuran data. Kinerja untuk kueri kompleks pada kumpulan data besar dicapai melalui paralelisme masif, baik pada armada runtime kueri maupun armada penyimpanan sistem. Kemampuan untuk menganalisis sejumlah besar data dengan cepat dan efisien adalah salah satu kekuatan terbesar Timestream untuk Live Analytics. Satu kueri yang berjalan di atas terabyte atau bahkan petabyte data mungkin memiliki ribuan mesin yang bekerja pada semuanya pada saat yang bersamaan.
Arsitektur seluler
Untuk memastikan bahwa Timestream for Live Analytics dapat menawarkan skala hampir tak terbatas untuk aplikasi Anda, sekaligus memastikan ketersediaan 99,99%, sistem ini juga dirancang menggunakan arsitektur seluler. Alih-alih menskalakan sistem secara keseluruhan, Timestream untuk Live Analytics segmen menjadi beberapa salinan yang lebih kecil dari dirinya sendiri, disebut sebagai sel. Hal ini memungkinkan sel untuk diuji pada skala penuh, dan mencegah masalah sistem dalam satu sel mempengaruhi aktivitas di sel lain di wilayah tertentu. Sementara Timestream untuk Live Analytics dirancang untuk mendukung beberapa sel per wilayah, pertimbangkan skenario fiktif berikut, di mana ada 2 sel di suatu wilayah.
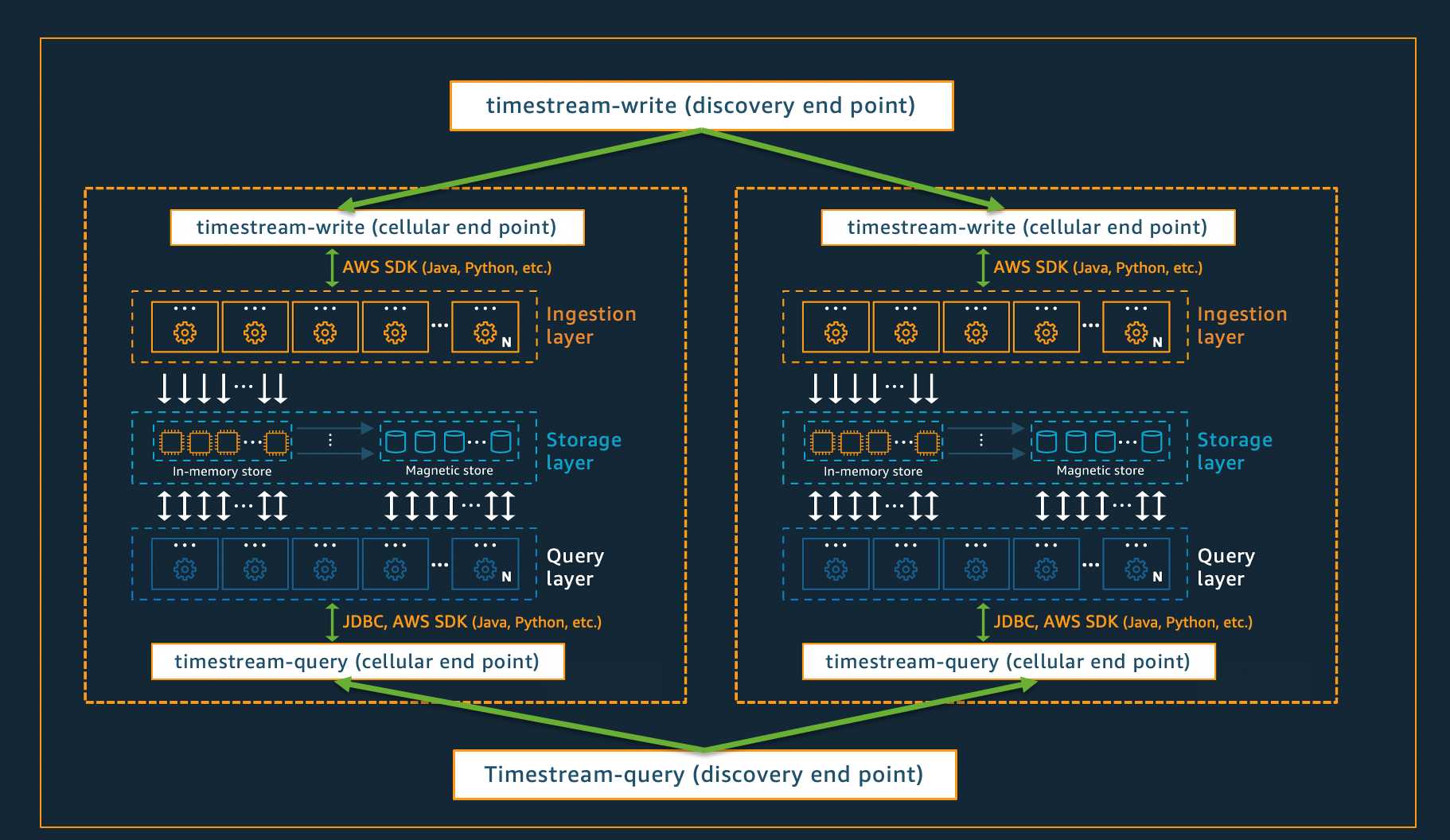
Dalam skenario yang digambarkan di atas, konsumsi data dan permintaan kueri pertama kali diproses oleh titik akhir penemuan untuk konsumsi data dan kueri, masing-masing. Kemudian, titik akhir penemuan mengidentifikasi sel yang berisi data pelanggan, dan mengarahkan permintaan ke titik akhir konsumsi atau kueri yang sesuai untuk sel tersebut. Saat menggunakan SDKs, tugas manajemen titik akhir ini ditangani secara transparan untuk Anda.
catatan
Saat menggunakan titik akhir VPC dengan Timestream untuk Live Analytics atau langsung mengakses operasi REST API untuk Timestream for Live Analytics, Anda harus berinteraksi langsung dengan titik akhir seluler. Untuk panduan tentang cara melakukannya, lihat Titik Akhir VPC untuk petunjuk tentang cara menyiapkan titik akhir VPC, dan Pola Penemuan Titik Akhir untuk petunjuk tentang pemanggilan langsung operasi REST API.
