Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Konsep UNLOAD
Sintaks
UNLOAD (SELECT statement) TO 's3://bucket-name/folder' WITH ( option = expression [, ...] )
optiondimana
{ partitioned_by = ARRAY[ col_name[,…] ] | format = [ '{ CSV | PARQUET }' ] | compression = [ '{ GZIP | NONE }' ] | encryption = [ '{ SSE_KMS | SSE_S3 }' ] | kms_key = '<string>' | field_delimiter ='<character>' | escaped_by = '<character>' | include_header = ['{true, false}'] | max_file_size = '<value>' | }
Parameter
- SELECTpernyataan
-
Pernyataan query yang digunakan untuk memilih dan mengambil data dari satu atau lebih Timestream untuk LiveAnalytics tabel.
(SELECT column 1, column 2, column 3 from database.table where measure_name = "ABC" and timestamp between ago (1d) and now() ) - Klausul TO
-
TO 's3://bucket-name/folder'atau
TO 's3://access-point-alias/folder'TOKlausa dalamUNLOADpernyataan menentukan tujuan untuk output dari hasil query. Anda perlu menyediakan jalur lengkap, termasuk nama ember Amazon S3 atau Amazon S3 dengan lokasi folder di Amazon S3 access-point-alias tempat Timestream untuk menulis objek file output. LiveAnalytics Bucket S3 harus dimiliki oleh akun yang sama dan di wilayah yang sama. Selain set hasil kueri, Timestream untuk LiveAnalytics menulis file manifes dan metadata ke folder tujuan tertentu. - PARTITIONED_BY klausa
-
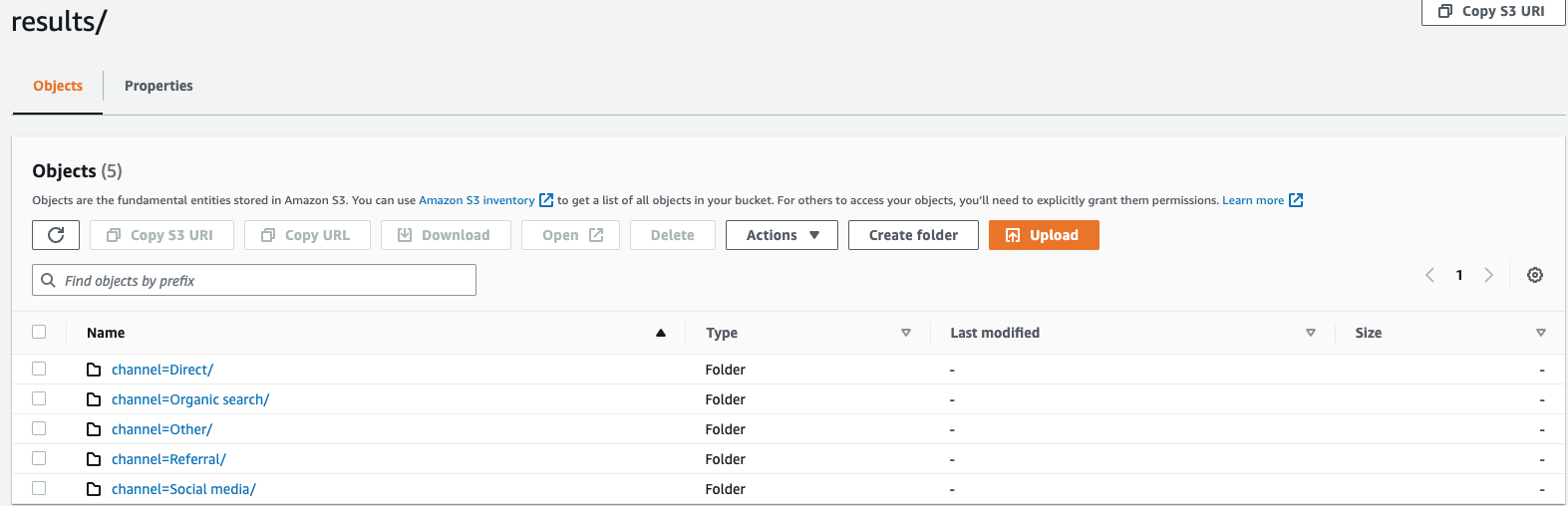
partitioned_by = ARRAY [col_name[,…] , (default: none)partitioned_byKlausa ini digunakan dalam kueri untuk mengelompokkan dan menganalisis data pada tingkat granular. Saat mengekspor hasil kueri ke bucket S3, Anda dapat memilih untuk mempartisi data berdasarkan satu atau beberapa kolom dalam kueri pilih. Saat mempartisi data, data yang diekspor dibagi menjadi himpunan bagian berdasarkan kolom partisi dan setiap subset disimpan dalam folder terpisah. Dalam folder hasil yang berisi data yang diekspor, sub-folder dibuatfolder/results/partition column = partition value/secara otomatis. Namun, perhatikan bahwa kolom yang dipartisi tidak termasuk dalam file output.partitioned_bybukan klausa wajib dalam sintaks. Jika Anda memilih untuk mengekspor data tanpa partisi apa pun, Anda dapat mengecualikan klausa dalam sintaks.Dengan asumsi Anda memantau data clickstream situs web Anda dan memiliki 5 saluran lalu lintas yaitu
direct,,,Social MediaOrganic Search,Otherdan.ReferralSaat mengekspor data, Anda dapat memilih untuk mempartisi data menggunakan kolomChannel. Dalam folder data Andas3://bucketname/results,, Anda akan memiliki lima folder masing-masing dengan nama saluran masing-masing, misalnya,s3://bucketname/results/channel=Social Media/.Dalam folder ini Anda akan menemukan data semua pelanggan yang mendarat di situs web Anda melaluiSocial Mediasaluran. Demikian pula, Anda akan memiliki folder lain untuk saluran yang tersisa.Data yang diekspor dipartisi oleh kolom Channel
- FORMAT
-
format = [ '{ CSV | PARQUET }' , default: CSVKata kunci untuk menentukan format hasil kueri yang ditulis ke bucket S3 Anda. Anda dapat mengekspor data baik sebagai nilai dipisahkan koma (CSV) menggunakan koma (,) sebagai pembatas default atau dalam format Apache Parquet, format penyimpanan kolom terbuka yang efisien untuk analitik.
- COMPRESSION
-
compression = [ '{ GZIP | NONE }' ], default: GZIPAnda dapat mengompres data yang diekspor menggunakan algoritma kompresi GZIP atau membuatnya tidak dikompresi dengan menentukan opsi.
NONE - ENCRYPTION
-
encryption = [ '{ SSE_KMS | SSE_S3 }' ], default: SSE_S3File output di Amazon S3 dienkripsi menggunakan opsi enkripsi yang Anda pilih. Selain data Anda, file manifes dan metadata juga dienkripsi berdasarkan opsi enkripsi yang Anda pilih. Saat ini kami mendukung SSE enkripsi _S3 dan SSE _KMS. SSE_S3 adalah enkripsi sisi server dengan Amazon S3 mengenkripsi data menggunakan enkripsi standar enkripsi lanjutan () 256-bit. AES SSE_ KMS adalah enkripsi sisi server untuk mengenkripsi data menggunakan kunci yang dikelola pelanggan.
- KMS_KEY
-
kms_key = '<string>'KMSKunci adalah kunci yang ditentukan pelanggan untuk mengenkripsi hasil kueri yang diekspor. KMSKey dikelola dengan aman oleh AWS Key Management Service (AWS KMS) dan digunakan untuk mengenkripsi file data di Amazon S3.
- FIELD_DELIMITER
-
field_delimiter ='<character>' , default: (,)Saat mengekspor data dalam CSV format, bidang ini menentukan satu ASCII karakter yang digunakan untuk memisahkan bidang dalam file output, seperti karakter pipa (|), koma (,), atau tab (/t). Pembatas default untuk CSV file adalah karakter koma. Jika nilai dalam data Anda berisi pembatas yang dipilih, pembatas akan dikutip dengan karakter kutipan. Misalnya, jika nilai dalam data Anda berisi
Time,stream, maka nilai ini akan dikutip seperti"Time,stream"pada data yang diekspor. Karakter kutipan yang digunakan oleh Timestream untuk LiveAnalytics adalah tanda kutip ganda (“).Hindari menentukan karakter carriage return (ASCII13, hex
0D, text '\ r') atau karakter line break (ASCII10, hex 0A, text'\n') sebagaiFIELD_DELIMITERjika Anda ingin memasukkan header dalamCSV, karena itu akan mencegah banyak parser dari dapat mengurai header dengan benar dalam output yang dihasilkan. CSV - ESCAPED_OLEH
-
escaped_by = '<character>', default: (\)Saat mengekspor data dalam CSV format, bidang ini menentukan karakter yang harus diperlakukan sebagai karakter escape dalam file data yang ditulis ke bucket S3. Melarikan diri terjadi dalam skenario berikut:
-
Jika nilai itu sendiri berisi karakter kutipan (“) maka itu akan diloloskan menggunakan karakter escape. Misalnya, jika nilainya
Time"stream, di mana (\) adalah karakter escape yang dikonfigurasi, maka itu akan lolos sebagaiTime\"stream. -
Jika nilai berisi karakter escape dikonfigurasi, itu akan lolos. Misalnya, jika nilainya
Time\stream, maka itu akan lolos sebagaiTime\\stream.
catatan
Jika output yang diekspor berisi tipe data yang kompleks seperti Array, Rows atau Timeseries, itu akan diserialisasi sebagai string. JSON Berikut adalah contohnya.
Tipe data Nilai aktual Bagaimana nilai diloloskan dalam CSV format [serial stringJSON] Array
[ 23,24,25 ]"[23,24,25]"Baris
( x=23.0, y=hello )"{\"x\":23.0,\"y\":\"hello\"}"Timeseries
[ ( time=1970-01-01 00:00:00.000000010, value=100.0 ),( time=1970-01-01 00:00:00.000000012, value=120.0 ) ]"[{\"time\":\"1970-01-01 00:00:00.000000010Z\",\"value\":100.0},{\"time\":\"1970-01-01 00:00:00.000000012Z\",\"value\":120.0}]" -
- INCLUDE_HEADER
-
include_header = 'true' , default: 'false'Saat mengekspor data dalam CSV format, bidang ini memungkinkan Anda menyertakan nama kolom sebagai baris pertama dari file CSV data yang diekspor.
Nilai yang diterima adalah 'true' dan 'false' dan nilai default adalah 'false'. Opsi transformasi teks seperti
escaped_bydanfield_delimiterberlaku untuk header juga.catatan
Saat menyertakan header, penting bahwa Anda tidak memilih karakter carriage return (ASCII13, hex 0D, text '\ r') atau karakter pemisah baris (ASCII10, hex 0A, teks'\n') sebagai
FIELD_DELIMITER, karena itu akan mencegah banyak parser untuk dapat mengurai header dengan benar dalam output yang dihasilkan. CSV - MAX_FILE_SIZE
-
max_file_size = 'X[MB|GB]' , default: '78GB'Bidang ini menentukan ukuran maksimum file yang dibuat
UNLOADpernyataan di Amazon S3.UNLOADPernyataan tersebut dapat membuat beberapa file tetapi ukuran maksimum setiap file yang ditulis ke Amazon S3 akan kira-kira apa yang ditentukan dalam bidang ini.Nilai bidang harus antara 16 MB dan 78 GB, inklusif. Anda dapat menentukannya dalam bilangan bulat seperti
12GB, atau dalam desimal seperti atau.0.5GB24.7MBNilai default adalah 78 GB.Ukuran file sebenarnya diperkirakan saat file sedang ditulis, sehingga ukuran maksimum sebenarnya mungkin tidak persis sama dengan angka yang Anda tentukan.
Apa yang ditulis ke ember S3 saya?
Untuk setiap UNLOAD kueri yang berhasil dijalankan, Timestream untuk LiveAnalytics menulis hasil kueri, file metadata, dan file manifes Anda ke dalam bucket S3. Jika Anda telah mempartisi data, Anda memiliki semua folder partisi di folder hasil. File manifes berisi daftar file yang ditulis oleh UNLOAD perintah. File metadata berisi informasi yang menjelaskan karakteristik, properti, dan atribut data tertulis.
Apa nama file yang diekspor?
Nama file yang diekspor berisi dua komponen, komponen pertama adalah QueryID dan komponen kedua adalah pengidentifikasi unik.
CSVberkas
S3://bucket_name/results/<queryid>_<UUID>.csv S3://bucket_name/results/<partitioncolumn>=<partitionvalue>/<queryid>_<UUID>.csv
File terkompresi CSV
S3://bucket_name/results/<partitioncolumn>=<partitionvalue>/<queryid>_<UUID>.gz
File parket
S3://bucket_name/results/<partitioncolumn>=<partitionvalue>/<queryid>_<UUID>.parquet
File metadata dan Manifest
S3://bucket_name/<queryid>_<UUID>_manifest.json S3://bucket_name/<queryid>_<UUID>_metadata.json
Karena data dalam CSV format disimpan pada tingkat file, saat Anda mengompres data saat mengekspor ke S3, file tersebut akan memiliki ekstensi “.gz”. Namun, data di Parket dikompresi pada tingkat kolom sehingga bahkan ketika Anda mengompres data saat mengekspor, file tersebut masih akan memiliki ekstensi.parquet.
Informasi apa yang terkandung dalam setiap file?
File manifes
File manifes memberikan informasi tentang daftar file yang diekspor dengan UNLOAD eksekusi. File manifes tersedia di bucket S3 yang disediakan dengan nama file:s3://<bucket_name>/<queryid>_<UUID>_manifest.json. File manifes akan berisi url file di folder hasil, jumlah catatan dan ukuran file masing-masing, dan metadata kueri (yang merupakan total byte dan total baris yang diekspor ke S3 untuk kueri).
{ "result_files": [ { "url":"s3://my_timestream_unloads/ec2_metrics/AEDAGANLHLBH4OLISD3CVOZZRWPX5GV2XCXRBKCVD554N6GWPWWXBP7LSG74V2Q_1448466917_szCL4YgVYzGXj2lS.gz", "file_metadata": { "content_length_in_bytes": 32295, "row_count": 10 } }, { "url":"s3://my_timestream_unloads/ec2_metrics/AEDAGANLHLBH4OLISD3CVOZZRWPX5GV2XCXRBKCVD554N6GWPWWXBP7LSG74V2Q_1448466917_szCL4YgVYzGXj2lS.gz", "file_metadata": { "content_length_in_bytes": 62295, "row_count": 20 } }, ], "query_metadata": { "content_length_in_bytes": 94590, "total_row_count": 30, "result_format": "CSV", "result_version": "Amazon Timestream version 1.0.0" }, "author": { "name": "Amazon Timestream", "manifest_file_version": "1.0" } }
Metadata
File metadata memberikan informasi tambahan tentang kumpulan data seperti nama kolom, jenis kolom, dan skema. <queryid>File metadata tersedia di bucket S3 yang disediakan dengan nama file: S3: //bucket_name/ _< >_metadata.json UUID
Berikut ini adalah contoh dari file metadata.
{ "ColumnInfo": [ { "Name": "hostname", "Type": { "ScalarType": "VARCHAR" } }, { "Name": "region", "Type": { "ScalarType": "VARCHAR" } }, { "Name": "measure_name", "Type": { "ScalarType": "VARCHAR" } }, { "Name": "cpu_utilization", "Type": { "TimeSeriesMeasureValueColumnInfo": { "Type": { "ScalarType": "DOUBLE" } } } } ], "Author": { "Name": "Amazon Timestream", "MetadataFileVersion": "1.0" } }
Informasi kolom yang dibagikan dalam file metadata memiliki struktur yang sama seperti yang ColumnInfo dikirim dalam API respons Kueri untuk SELECT kueri.
Hasil
Folder hasil berisi data yang diekspor dalam Apache Parquet atau format. CSV
Contoh
Saat Anda mengirimkan UNLOAD kueri seperti di bawah ini melalui QueryAPI,
UNLOAD(SELECT user_id, ip_address, event, session_id, measure_name, time, query, quantity, product_id, channel FROM sample_clickstream.sample_shopping WHERE time BETWEEN ago(2d) AND now()) TO 's3://my_timestream_unloads/withoutpartition/' WITH ( format='CSV', compression='GZIP')
UNLOADrespon query akan memiliki 1 baris* 3 kolom. 3 kolom tersebut adalah:
-
baris tipe BIGINT - menunjukkan jumlah baris yang diekspor
-
metadataFile tipe VARCHAR - yang merupakan S3 dari file URI metadata yang diekspor
-
manifestFile tipe VARCHAR - yang merupakan S3 dari file manifes URI yang diekspor
Anda akan mendapatkan jawaban berikut dari QueryAPI:
{ "Rows": [ { "Data": [ { "ScalarValue": "20" # No of rows in output across all files }, { "ScalarValue": "s3://my_timestream_unloads/withoutpartition/AEDAAANGH3D7FYHOBQGQQMEAISCJ45B42OWWJMOT4N6RRJICZUA7R25VYVOHJIY_<UUID>_metadata.json" #Metadata file }, { "ScalarValue": "s3://my_timestream_unloads/withoutpartition/AEDAAANGH3D7FYHOBQGQQMEAISCJ45B42OWWJMOT4N6RRJICZUA7R25VYVOHJIY_<UUID>_manifest.json" #Manifest file } ] } ], "ColumnInfo": [ { "Name": "rows", "Type": { "ScalarType": "BIGINT" } }, { "Name": "metadataFile", "Type": { "ScalarType": "VARCHAR" } }, { "Name": "manifestFile", "Type": { "ScalarType": "VARCHAR" } } ], "QueryId": "AEDAAANGH3D7FYHOBQGQQMEAISCJ45B42OWWJMOT4N6RRJICZUA7R25VYVOHJIY", "QueryStatus": { "ProgressPercentage": 100.0, "CumulativeBytesScanned": 1000, "CumulativeBytesMetered": 10000000 } }
Jenis data
UNLOADPernyataan ini mendukung semua tipe data Timestream untuk bahasa LiveAnalytics kueri yang dijelaskan dalam Jenis data yang didukung kecuali time danunknown.
