Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Membuat model bahasa khusus
Sebelum Anda dapat membuat model bahasa kustom Anda, Anda harus:
-
Siapkan data Anda. Data harus disimpan dalam format teks biasa dan tidak dapat berisi karakter khusus apa pun.
-
Unggah data Anda ke dalam Amazon S3 ember. Disarankan untuk membuat folder terpisah untuk pelatihan dan penyetelan data.
-
Pastikan Anda Amazon Transcribe memiliki akses ke Amazon S3 bucket Anda. Anda harus menentukan IAM peran yang memiliki izin akses untuk menggunakan data Anda.
Mempersiapkan data Anda
Anda dapat mengkompilasi semua data Anda dalam satu file atau menyimpannya sebagai beberapa file. Perhatikan bahwa jika Anda memilih untuk menyertakan data penyetelan, data tersebut harus disimpan dalam file terpisah dari data pelatihan Anda.
Tidak masalah berapa banyak file teks yang Anda gunakan untuk pelatihan atau penyetelan data Anda. Mengunggah satu file dengan 100.000 kata menghasilkan hasil yang sama dengan mengunggah 10 file dengan 10.000 kata. Siapkan data teks Anda dengan cara yang paling nyaman bagi Anda.
Pastikan semua file data Anda memenuhi kriteria berikut:
-
Mereka semua dalam bahasa yang sama dengan model yang ingin Anda buat. Misalnya, jika Anda ingin membuat model bahasa khusus yang mentranskripsikan audio dalam bahasa Inggris AS (
en-US), semua data teks Anda harus dalam bahasa Inggris AS. -
Mereka dalam format teks biasa dengan UTF-8 pengkodean.
-
Mereka tidak mengandung karakter khusus atau format, seperti tag HTML.
-
Mereka berjumlah total gabungan maksimum 2 GB untuk data pelatihan dan 200 MB untuk menyetel data.
Jika salah satu kriteria ini tidak terpenuhi, model Anda gagal.
Mengunggah data Anda
Sebelum mengunggah data Anda, buat folder baru untuk data pelatihan Anda. Jika menggunakan data penyetelan, buat folder terpisah lainnya.
URI untuk ember Anda mungkin terlihat seperti:
-
s3://amzn-s3-demo-bucket/my-model-training-data/ -
s3://amzn-s3-demo-bucket/my-model-tuning-data/
Unggah data pelatihan dan tuning Anda ke dalam bucket yang sesuai.
Anda dapat menambahkan lebih banyak data ke bucket ini di kemudian hari. Namun, jika Anda melakukannya, Anda perlu membuat ulang model Anda dengan data baru. Model yang ada tidak dapat diperbarui dengan data baru.
Mengizinkan akses ke data Anda
Untuk membuat model bahasa kustom, Anda harus menentukan IAM peran yang memiliki izin untuk mengakses Amazon S3 bucket Anda. Jika Anda belum memiliki peran dengan akses ke Amazon S3 bucket tempat Anda menempatkan data pelatihan, Anda harus membuatnya. Setelah membuat peran, Anda dapat melampirkan kebijakan untuk memberikan izin peran tersebut. Jangan melampirkan kebijakan ke pengguna.
Untuk kebijakan-kebijakan contoh, lihat Amazon Transcribe contoh kebijakan berbasis identitas.
Untuk mempelajari cara membuat IAM identitas baru, lihat IAM Identitas (pengguna, grup pengguna, dan peran).
Untuk mempelajari lebih lanjut tentang kebijakan, lihat:
Membuat model bahasa kustom Anda
Saat membuat model bahasa kustom Anda, Anda harus memilih model dasar. Ada dua opsi model dasar:
-
NarrowBand: Gunakan opsi ini untuk audio dengan laju sampel kurang dari 16.000 Hz. Jenis model ini biasanya digunakan untuk percakapan telepon yang direkam pada 8.000 Hz. -
WideBand: Gunakan opsi ini untuk audio dengan laju sampel lebih besar dari atau sama dengan 16.000 Hz.
Anda dapat membuat model bahasa kustom menggunakan AWS Management Console, AWS CLI, atau AWS SDK.; lihat contoh berikut:
-
Masuk ke AWS Management Console
. -
Di panel navigasi, pilih Model bahasa kustom. Ini membuka halaman model bahasa kustom di mana Anda dapat melihat model bahasa kustom yang ada atau melatih model bahasa kustom baru.
-
Untuk melatih model baru, pilih Model kereta.
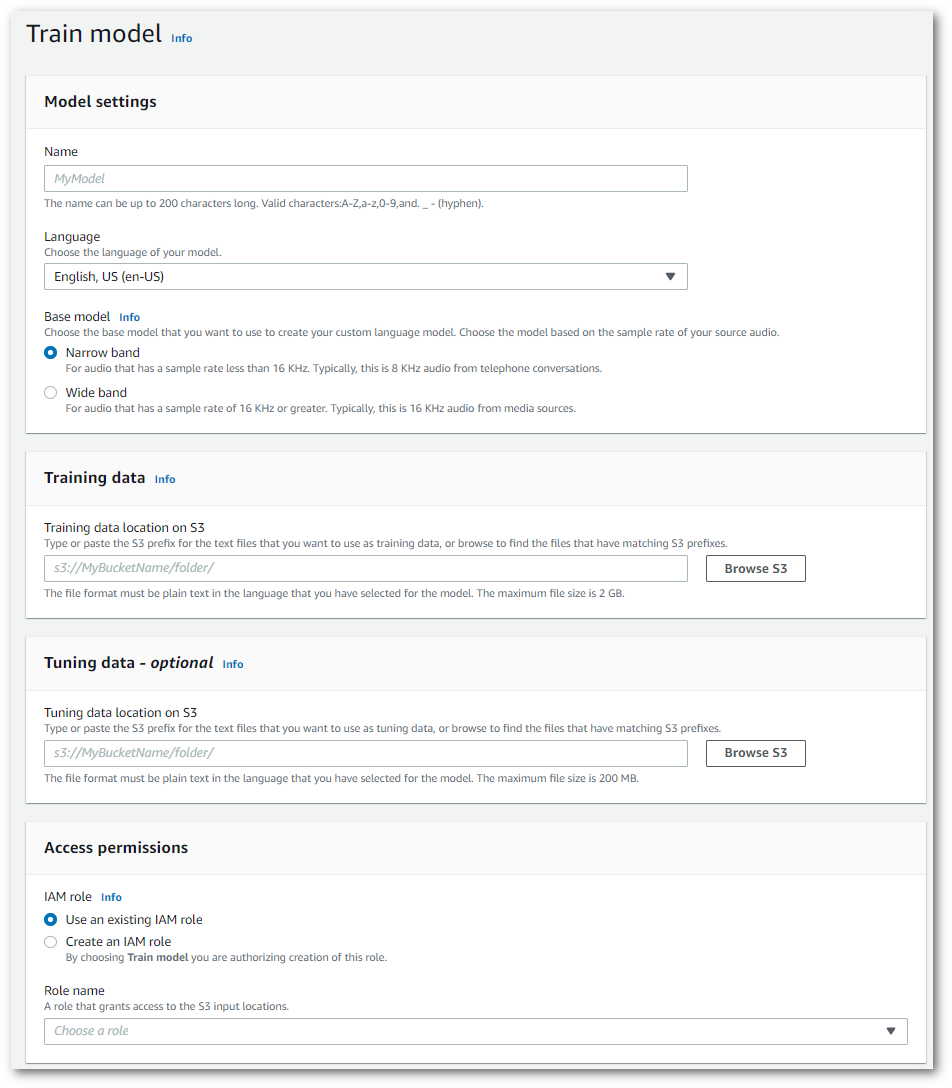
Ini membawa Anda ke halaman model Kereta. Tambahkan nama, tentukan bahasa, dan pilih model dasar yang Anda inginkan untuk model Anda. Kemudian, tambahkan jalur ke pelatihan Anda dan, secara opsional, data penyetelan Anda. Anda harus menyertakan IAM peran yang memiliki izin untuk mengakses data Anda.
-
Setelah semua bidang selesai, pilih Model kereta api di bagian bawah halaman.
Contoh ini menggunakan perintah create-language-modelCreateLanguageModel dan LanguageModel.
aws transcribe create-language-model \ --base-model-nameNarrowBand\ --model-namemy-first-language-model\ --input-data-config S3Uri=s3://amzn-s3-demo-bucket/my-clm-training-data/,TuningDataS3Uri=s3://amzn-s3-demo-bucket/my-clm-tuning-data/,DataAccessRoleArn=arn:aws:iam::111122223333:role/ExampleRole\ --language-codeen-US
Berikut contoh lain menggunakan perintah create-language-model
aws transcribe create-language-model \ --cli-input-json file://filepath/my-first-language-model.json
File my-first-language-model.json berisi badan permintaan berikut.
{ "BaseModelName": "NarrowBand", "ModelName": "my-first-language-model", "InputDataConfig": { "S3Uri": "s3://amzn-s3-demo-bucket/my-clm-training-data/", "TuningDataS3Uri"="s3://amzn-s3-demo-bucket/my-clm-tuning-data/", "DataAccessRoleArn": "arn:aws:iam::111122223333:role/ExampleRole" }, "LanguageCode": "en-US" }
Contoh ini menggunakan AWS SDK untuk Python (Boto3) untuk membuat CLM menggunakan metode create_language_modelCreateLanguageModel dan LanguageModel.
Untuk contoh tambahan yang menggunakan AWS SDK, termasuk contoh khusus fitur, skenario, dan lintas layanan, lihat bagian ini. Contoh kode untuk Amazon Transcribe menggunakan AWS SDK
from __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe', 'us-west-2') model_name = 'my-first-language-model', transcribe.create_language_model( LanguageCode = 'en-US', BaseModelName = 'NarrowBand', ModelName = model_name, InputDataConfig = { 'S3Uri':'s3://amzn-s3-demo-bucket/my-clm-training-data/', 'TuningDataS3Uri':'s3://amzn-s3-demo-bucket/my-clm-tuning-data/', 'DataAccessRoleArn':'arn:aws:iam::111122223333:role/ExampleRole' } ) while True: status = transcribe.get_language_model(ModelName = model_name) if status['LanguageModel']['ModelStatus'] in ['COMPLETED', 'FAILED']: break print("Not ready yet...") time.sleep(5) print(status)
Memperbarui model bahasa kustom Anda
Amazon Transcribe terus memperbarui model dasar yang tersedia untuk model bahasa khusus. Untuk mendapatkan manfaat dari pembaruan ini, kami merekomendasikan pelatihan model bahasa kustom baru setiap 6 hingga 12 bulan.
Untuk melihat apakah model bahasa kustom Anda menggunakan model dasar terbaru, jalankan DescribeLanguageModelpermintaan menggunakan AWS CLI atau AWS SDK, lalu temukan UpgradeAvailability bidang dalam respons Anda.
Jika UpgradeAvailability yatrue, model Anda tidak menjalankan versi terbaru dari model dasar. Untuk menggunakan model dasar terbaru dalam model bahasa kustom, Anda harus membuat model bahasa kustom baru. Model bahasa khusus tidak dapat ditingkatkan.
