Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Membuat filter kosakata
Ada dua opsi untuk membuat filter kosakata khusus:
-
Simpan daftar kata-kata yang dipisahkan baris sebagai file teks biasa dengan pengkodean UTF-8.
Anda dapat menggunakan pendekatan ini dengan AWS Management Console, AWS CLI, atau AWS SDKs.
Jika menggunakan AWS Management Console, Anda dapat memberikan jalur lokal atau Amazon S3 URI untuk file kosakata kustom Anda.
Jika menggunakan AWS CLI or AWS SDKs, Anda harus mengunggah file kosakata kustom Anda ke Amazon S3 bucket dan menyertakan Amazon S3 URI dalam permintaan Anda.
-
Sertakan daftar kata yang dipisahkan koma secara langsung dalam permintaan API Anda.
-
Anda dapat menggunakan pendekatan ini dengan AWS CLI atau AWS SDKs menggunakan
Wordsparameter.
-
Untuk contoh setiap metode, lihat Membuat filter kosakata khusus
Hal-hal yang perlu diperhatikan saat membuat filter kosakata khusus Anda:
-
Kata-kata tidak peka huruf besar/kecil. Misalnya, “kutukan” dan “KUTUKAN” diperlakukan sama.
-
Hanya kecocokan kata yang tepat yang difilter. Misalnya, jika filter Anda menyertakan “sumpah” tetapi media Anda berisi kata “sumpah” atau “sumpah”, ini tidak disaring. Hanya contoh “sumpah” yang disaring. Karena itu Anda harus menyertakan semua variasi kata yang ingin Anda filter.
-
Filter tidak berlaku untuk kata-kata yang terkandung dalam kata lain. Misalnya, jika filter kosakata khusus berisi “laut” tetapi bukan “kapal selam”, “kapal selam” tidak diubah dalam transkrip.
-
Setiap entri hanya dapat berisi satu kata (tidak ada spasi).
-
Jika Anda menyimpan filter kosakata kustom Anda sebagai file teks, itu harus dalam format teks biasa dengan pengkodean UTF-8.
-
Anda dapat memiliki hingga 100 filter kosakata khusus per Akun AWS dan masing-masing dapat berukuran hingga 50 Kb.
-
Anda hanya dapat menggunakan karakter yang didukung untuk bahasa Anda. Lihat set karakter bahasa Anda untuk detailnya.
Membuat filter kosakata khusus
Untuk memproses filter kosakata khusus untuk digunakan Amazon Transcribe, lihat contoh berikut:
Sebelum melanjutkan, simpan filter kosakata kustom Anda sebagai file teks (*.txt). Anda dapat secara opsional mengunggah file Anda ke Amazon S3 ember.
-
Masuk ke AWS Management Console
. -
Di panel navigasi, pilih Pemfilteran kosakata. Ini membuka halaman filter Kosakata di mana Anda dapat melihat filter kosakata kustom yang ada atau membuat yang baru.
-
Pilih Buat filter kosakata.
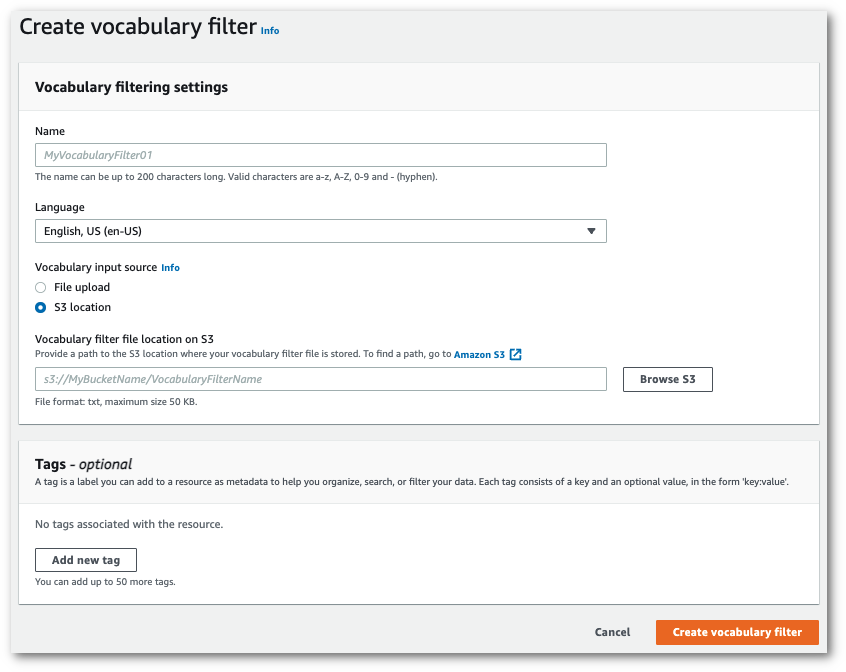
Ini membawa Anda ke halaman filter Buat kosakata. Masukkan nama untuk filter kosakata kustom baru Anda.
Pilih opsi Unggah file atau lokasi S3 di bawah Sumber input kosakata. Kemudian tentukan lokasi file kosakata khusus Anda.
-
Secara opsional, tambahkan tag ke filter kosakata khusus Anda. Setelah semua bidang selesai, pilih Buat filter kosakata di bagian bawah halaman. Jika tidak ada kesalahan dalam memproses file Anda, ini akan membawa Anda kembali ke halaman filter Kosakata.
Filter kosakata kustom Anda sekarang siap digunakan.
Contoh ini menggunakan create-vocabulary-filterperintah untuk memproses daftar kata menjadi filter kosakata kustom yang dapat digunakan. Untuk informasi selengkapnya, lihat CreateVocabularyFilter.
Opsi 1: Anda dapat memasukkan daftar kata ke permintaan Anda menggunakan words parameter.
aws transcribe create-vocabulary-filter \ --vocabulary-filter-namemy-first-vocabulary-filter\ --language-codeen-US\ --wordsprofane,offensive,Amazon,Transcribe
Opsi 2: Anda dapat menyimpan daftar kata sebagai file teks dan mengunggahnya ke Amazon S3 bucket, lalu menyertakan URI file dalam permintaan Anda menggunakan vocabulary-filter-file-uri parameter.
aws transcribe create-vocabulary-filter \ --vocabulary-filter-namemy-first-vocabulary-filter\ --language-codeen-US\ --vocabulary-filter-file-uri s3://amzn-s3-demo-bucket/my-vocabulary-filters/my-vocabulary-filter.txt
Berikut contoh lain menggunakan create-vocabulary-filterperintah, dan badan permintaan yang membuat filter kosakata kustom Anda.
aws transcribe create-vocabulary-filter \ --cli-input-json file://filepath/my-first-vocab-filter.json
File my-first-vocab-filter.json berisi badan permintaan berikut.
Opsi 1: Anda dapat memasukkan daftar kata ke permintaan Anda menggunakan Words parameter.
{ "VocabularyFilterName": "my-first-vocabulary-filter", "LanguageCode": "en-US", "Words": [ "profane","offensive","Amazon","Transcribe" ] }
Opsi 2: Anda dapat menyimpan daftar kata sebagai file teks dan mengunggahnya ke Amazon S3 bucket, lalu menyertakan URI file dalam permintaan Anda menggunakan VocabularyFilterFileUri parameter.
{ "VocabularyFilterName": "my-first-vocabulary-filter", "LanguageCode": "en-US", "VocabularyFilterFileUri": "s3://amzn-s3-demo-bucket/my-vocabulary-filters/my-vocabulary-filter.txt" }
catatan
Jika Anda memasukkan VocabularyFilterFileUri dalam permintaan Anda, Anda tidak dapat menggunakanWords; Anda harus memilih satu atau yang lain.
Contoh ini menggunakan AWS SDK for Python (Boto3) untuk membuat filter kosakata kustom menggunakan metode create_vocabulary_filterCreateVocabularyFilter.
Untuk contoh tambahan menggunakan AWS SDKs, termasuk contoh khusus fitur, skenario, dan lintas layanan, lihat bagian ini. Contoh kode untuk Amazon Transcribe menggunakan AWS SDKs
Opsi 1: Anda dapat memasukkan daftar kata ke permintaan Anda menggunakan Words parameter.
from __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe', 'us-west-2') vocab_name = "my-first-vocabulary-filter" response = transcribe.create_vocabulary_filter( LanguageCode = 'en-US', VocabularyFilterName = vocab_name, Words = [ 'profane','offensive','Amazon','Transcribe' ] )
Opsi 2: Anda dapat menyimpan daftar kata sebagai file teks dan mengunggahnya ke Amazon S3 bucket, lalu menyertakan URI file dalam permintaan Anda menggunakan VocabularyFilterFileUri parameter.
from __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe', 'us-west-2') vocab_name = "my-first-vocabulary-filter" response = transcribe.create_vocabulary_filter( LanguageCode = 'en-US', VocabularyFilterName = vocab_name, VocabularyFilterFileUri = 's3://amzn-s3-demo-bucket/my-vocabulary-filters/my-vocabulary-filter.txt' )
catatan
Jika Anda memasukkan VocabularyFilterFileUri dalam permintaan Anda, Anda tidak dapat menggunakanWords; Anda harus memilih satu atau yang lain.
catatan
Jika Anda membuat Amazon S3 bucket baru untuk file filter kosakata kustom Anda, pastikan IAM peran yang membuat CreateVocabularyFilterpermintaan memiliki izin untuk mengakses bucket ini. Jika peran tidak memiliki izin yang benar, permintaan Anda gagal. Anda dapat secara opsional menentukan IAM peran dalam permintaan Anda dengan menyertakan DataAccessRoleArn parameter. Untuk informasi selengkapnya tentang IAM peran dan kebijakan di Amazon Transcribe, lihatAmazon Transcribe contoh kebijakan berbasis identitas.
