Ketersediaan
Ketersediaan (juga dikenal dengan ketersediaan layanan) adalah metrik yang umum digunakan untuk mengukur ketahanan secara kuantitatif, serta merupakan target tujuan ketahanan.
-
Ketersediaan adalah persentase waktu ketika beban kerja tersedia untuk digunakan.
Tersedia untuk digunakan artinya beban kerja berhasil memberikan kinerja sesuai fungsinya yang disepakati ketika diperlukan.
Persentase ini dihitung dengan jangka waktu tertentu, seperti bulan, tahun, atau tiga tahun ke belakang. Dengan memberlakukan interpretasi seketat mungkin, maka ketersediaan akan berkurang setiap kali aplikasi tidak beroperasi secara normal, termasuk gangguan terjadwal dan di luar jadwal. Kami mendefinisikan ketersediaan seperti berikut:
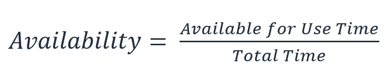
-
Ketersediaan adalah persentase waktu aktif (seperti 99,9%) selama jangka waktu tertentu (umumnya satu bulan atau tahun)
-
Penulisan singkat yang umum digunakan adalah “jumlah angka sembilan”; misalnya, “lima angka sembilan” artinya tingkat ketersediaannya adalah 99,999%
-
Beberapa pelanggan memilih untuk mengecualikan waktu henti layanan terjadwal (misalnya pemeliharaan terencana) dari Total Waktu dalam formula. Namun demikian, ini tidak disarankan, karena pengguna Anda kemungkinan ingin menggunakan layanan Anda selama waktu-waktu tersebut.
Berikut ini adalah tabel tujuan desain ketersediaan aplikasi umum dan durasi maksimum gangguan yang dapat terjadi dalam satu tahun namun tetap memenuhi tujuan-tujuan yang sudah ditetapkan. Tabel ini berisi contoh-contoh tipe aplikasi yang umum kita lihat pada tiap-tiap tingkatan ketersediaan. Di sepanjang dokumen ini, kita mengacu pada nilai-nilai ini.
| Ketersediaan | Ketidaktersediaan Maksimum (per tahun) | Kategori Aplikasi |
|---|---|---|
| 99% | 3 hari 15 jam | Pemrosesan batch, ekstraksi data, transfer, dan tugas-tugas pemuatan |
| 99,9% | 8 jam 45 menit | Alat internal seperti manajemen pengetahuan, pelacakan proyek |
| 99,95% | 4 jam 22 menit | Niaga online, titik penjualan |
| 99,99% | 52 menit | Pengiriman video, beban kerja siaran |
| 99,999% | 5 menit | Transaksi ATM, beban kerja telekomunikasi |
Mengukur ketersediaan berdasarkan permintaan. Untuk layanan Anda, mungkin akan lebih mudah untuk menghitung permintaan yang berhasil dan gagal daripada “waktu yang tersedia untuk digunakan”. Dalam kasus ini, dapat digunakan hitungan berikut:

Ini sering kali dihitung untuk periode satu menit atau lima menit. Lalu, persentase waktu aktif bulanan (pengukuran ketersediaan berbasis waktu) dapat dihitung dari rata-rata semua periode ini. Jika tidak ada permintaan yang diterima dalam jangka waktu tertentu, maka aplikasi terhitung 100% tersedia untuk waktu tersebut.
Menghitung ketersediaan dengan dependensi keras. Banyak sekali sistem yang memiliki dependensi keras (hard dependency) pada sistem lain, di mana gangguan pada sebuah sistem dependen secara langsung diartikan sebagai gangguan pada sistem yang menginvokasi. Ini adalah kebalikan dari dependensi lembut (soft dependency), di mana sebuah kegagalan yang terjadi pada sistem dependen diimbangi di dalam aplikasi. Ketika dependensi keras terjadi, ketersediaan sistem yang menginvokasi adalah produk dari ketersediaan sistem dependen tersebut. Misalnya, jika Anda memiliki sistem yang dirancang untuk ketersediaan 99,99% yang memiliki dependensi keras pada dua sistem independen lain yang masing-masing dirancang untuk ketersediaan 99,99%, maka secara teori beban kerja tersebut dapat meraih ketersediaan 99,97%:
Availinvok × Availdep1 × Availdep2 = Availworkload
99,99% × 99,99% × 99,99% = 99,97%
Oleh karena itu, penting untuk memahami dependensi Anda serta tujuan-tujuan desain ketersediaannya saat Anda menghitung ketersediaan Anda sendiri.
Menghitung ketersediaan dengan komponen redundan. Ketika suatu sistem melibatkan penggunaan komponen redundan dan independen (misalnya sumber daya redundan di beberapa Zona Ketersediaan yang berbeda), maka secara teori, ketersediaan sistem tersebut dihitung 100% dikurangi hasil tingkat kegagalan komponen. Misalnya, jika suatu sistem memanfaatkan dua komponen independen, masing-masing memiliki ketersediaan 99,9%, maka ketersediaan efektif dependensi ini adalah 99,9999%:

Availeffective = AvailMAX − ((100%−Availdependency)×(100%−Availdependency))
99,9999% = 100% − (0,1%×0,1%)
Perhitungan pintasan: Jika ketersediaan semua komponen di dalam hitungan Anda hanya terdiri dari angka sembilan, maka Anda dapat menjumlah hitungan jumlah angka sembilan untuk mendapatkan jawaban. Pada contoh di atas, dua komponen independen dan redundan dengan ketersediaan tiga angka sembilan menghasilkan enam angka sembilan.
Menghitung ketersediaan dependensi. Beberapa dependensi menyediakan panduan tentang ketersediaannya, termasuk tujuan desain ketersediaan untuk banyak layanan AWS. Tetapi pada kasus-kasus di mana ini tidak tersedia (misalnya, komponen yang produsennya tidak mempublikasikan informasi ketersediaan), satu cara untuk menghitung adalah dengan menentukan Waktu Rata-rata Antara Kegagalan (MTBF) dan Waktu Rata-rata Pemulihan (MTTR). Hitungan ketersediaan dapat dilakukan dengan:
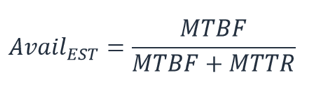
Misalnya, jika MTBF 150 hari dan MTTR 1 jam, maka hitungan ketersediaannya adalah 99,97%.
Untuk detail tambahan, silakan lihat Availability and Beyond: Memahami dan meningkatkan ketahanan sistem terdistribusi AWS, yang dapat membantu Anda menghitung ketersediaan Anda.
Biaya ketersediaan. Merancang desain aplikasi untuk tingkat ketersediaan yang lebih tinggi umumnya akan menyebabkan terjadinya peningkatan biaya, sehingga sebaiknya Anda mengidentifikasi kebutuhan ketersediaan yang sebenarnya sebelum mulai merancang desain aplikasi Anda. Tingkat ketersediaan yang tinggi menghadirkan persyaratan pengujian dan validasi yang lebih ketat berdasarkan skenario kegagalan yang lengkap. Tingkat ketersediaan ini memerlukan otomatisasi untuk pemulihan dari semua bentuk kegagalan, dan mengharuskan semua aspek yang ada dalam operasi sistem tersebut dibangun serupa dan diuji dengan standar yang sama. Misalnya, penambahan atau penghapusan kapasitas, deployment atau pembatalan (roll back) pembaruan perangkat lunak atau perubahan konfigurasi, atau migrasi data sistem harus dilakukan sesuai tujuan-tujuan ketersediaan yang dikehendaki. Selain biaya untuk pengembangan perangkat lunak, pada tingkat ketersediaan yang sangat tinggi, inovasi juga terkena dampak dikarenakan adanya kebutuhan untuk bergerak lebih lambat dalam melakukan deployment sistem. Oleh karena itu, panduan harus dibuat menyeluruh dalam menerapkan standar dan mempertimbangkan target-target ketersediaan yang tepat untuk seluruh siklus hidup pengoperasian sistem.
Faktor lain yang menyebabkan peningkatan biaya dalam sistem yang beroperasi dengan tujuan desain ketersediaan yang lebih tinggi adalah pemilihan dependensi. Pada tujuan-tujuan yang lebih tinggi ini, serangkaian perangkat lunak atau layanan yang dapat dipilih sebagai dependensi berkurang berdasarkan layanan mana yang telah memiliki investasi mendalam yang telah kami jelaskan sebelumnya untuk Anda. Seiring dengan meningkatnya tujuan-tujuan desain ketersediaan, merupakan hal umum untuk menemukan lebih sedikit layanan multi-tujuan (seperti basis data relasional) dan lebih banyak layanan yang dibuat khusus. Alasannya adalah bahwa jenis-jenis layanan yang dibuat khusus lebih mudah untuk dievaluasi, diuji, dan diotomatisasi, serta memiliki lebih sedikit potensi interaksi kejutan dengan fungsionalitas yang disertakan namun tidak digunakan.
