Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
REL13-BP02 Gunakan strategi pemulihan yang ditentukan untuk memenuhi tujuan pemulihan
Tentukan strategi pemulihan bencana (DR) yang memenuhi sasaran pemulihan beban kerja. Pilih strategi seperti pencadangan dan pemulihan, standby (aktif/pasif), atau aktif/aktif.
Hasil yang diinginkan: Strategi DR ditentukan dan diimplementasikan untuk setiap beban kerja agar beban kerja dapat mencapai sasaran DR. Strategi DR antara beban kerja menggunakan pola yang dapat digunakan kembali (seperti strategi yang telah dijelaskan sebelumnya),
Anti-pola umum:
-
Mengimplementasikan prosedur pemulihan yang tidak konsisten untuk beban kerja dengan sasaran DR yang serupa.
-
Membiarkan strategi DR diimplementasikan secara ad-hoc saat bencana terjadi.
-
Tidak memiliki rencana untuk pemulihan bencana.
-
Dependensi pada operasi bidang kontrol selama pemulihan.
Manfaat menjalankan praktik terbaik ini:
-
Dengan strategi pemulihan yang ditentukan, Anda dapat menggunakan prosedur tes dan peralatan umum.
-
Menggunakan strategi pemulihan yang ditentukan akan meningkatkan penyebaran pengetahuan antara tim dan implementasi DR pada beban kerja milik mereka.
Tingkat risiko yang terjadi jika praktik terbaik ini tidak diterapkan: Tinggi. Tanpa strategi DR yang direncanakan, diimplementasikan, dan diuji, Anda akan kesulitan mencapai sasaran pemulihan ketika bencana terjadi.
Panduan implementasi
Strategi DR mengandalkan kemampuan untuk mempertahankan beban kerja di situs pemulihan jika lokasi utama tidak dapat menjalankan beban kerja. Tujuan pemulihan yang paling umum adalah RTO danRPO, seperti yang dibahas dalamREL13-BP01 Menentukan tujuan pemulihan untuk downtime dan kehilangan data.
Strategi DR di beberapa Availability Zone (AZs) dalam satu Wilayah AWS, dapat memberikan mitigasi terhadap peristiwa bencana seperti kebakaran, banjir, dan pemadaman listrik besar. Jika merupakan persyaratan untuk menerapkan perlindungan terhadap peristiwa yang tidak mungkin yang mencegah beban kerja Anda agar tidak dapat berjalan di tempat tertentu Wilayah AWS, Anda dapat menggunakan strategi DR yang menggunakan beberapa Wilayah.
Anda harus memilih salah satu dari strategi berikut saat merancang strategi DR di beberapa Wilayah. Mereka terdaftar dalam urutan peningkatan biaya dan kompleksitas, dan penurunan urutan dan. RTO RPO Wilayah Pemulihan mengacu pada yang Wilayah AWS lain selain yang utama yang digunakan untuk beban kerja Anda.
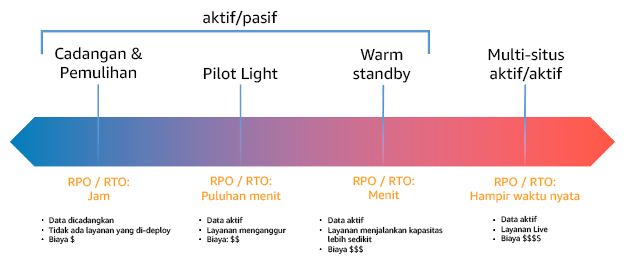
Gambar 17: Strategi pemulihan bencana (DR)
-
Backup dan restore (RPOdalam jam, RTO dalam 24 jam atau kurang): Cadangkan data dan aplikasi Anda ke Wilayah pemulihan. Menggunakan backup otomatis atau kontinu akan memungkinkan point in time recovery (PITR), yang dapat turun RPO hingga serendah 5 menit dalam beberapa kasus. Jika terjadi bencana, Anda akan menggunakan infrastruktur Anda (menggunakan infrastruktur sebagai kode untuk mengurangiRTO), menyebarkan kode Anda, dan memulihkan data cadangan untuk pulih dari bencana di Wilayah pemulihan.
-
Lampu pilot (RPOdalam hitungan menit, RTO dalam puluhan menit): Menyediakan salinan infrastruktur beban kerja inti Anda di Wilayah pemulihan. Replikasikan data ke Wilayah pemulihan dan buat cadangan di sana. Sumber daya yang diperlukan untuk mendukung replikasi dan pencadangan data, misalnya basis data dan penyimpanan objek, selalu aktif. Elemen lainnya seperti server aplikasi atau komputasi nirserver tidak di-deploy, tetapi dapat dibuat saat dibutuhkan dengan kode aplikasi dan konfigurasi yang diperlukan.
-
Siaga hangat (RPOdalam hitungan detik, RTO dalam hitungan menit): Pertahankan versi beban kerja Anda yang diperkecil namun berfungsi penuh yang selalu berjalan di Wilayah pemulihan. Sistem yang vital untuk bisnis sepenuhnya digandakan dan selalu aktif, tetapi dengan armada yang diturunkan skalanya. Data direplikasi dan berada dalam Wilayah pemulihan. Ketika pemulihan diperlukan, sistem dinaikkan skalanya dengan cepat untuk menangani beban produksi. Semakin ditingkatkan siaga hangat, semakin rendah RTO dan ketergantungan bidang kontrol. Saat skala sesuai sepenuhnya, ini disebut sebagai hot standby.
-
Multi-Region (multi-situs) aktif-aktif (RPOmendekati nol, RTO berpotensi nol): Beban kerja Anda diterapkan ke, dan secara aktif melayani lalu lintas dari, beberapa. Wilayah AWS Strategi ini perlu menyinkronkan data di seluruh Wilayah. Konflik potensial yang disebabkan oleh menulis catatan yang sama di dua replika wilayah yang berbeda harus dihindari atau ditangani, karena bisa menjadi kompleks. Replikasi data berguna untuk sinkronisasi data dan akan melindungi Anda dari beberapa jenis bencana, tetapi tidak akan melindungi Anda dari korupsi atau kerusakan data kecuali solusi Anda juga menyertakan opsi untuk point-in-time pemulihan.
catatan
Perbedaan antara pilot light dan warm standby terkadang sulit dimengerti. Keduanya menyertakan lingkungan di Wilayah pemulihan dengan salinan aset wilayah utama. Perbedaannya adalah pilot light tidak dapat memproses permintaan tanpa lebih dulu melakukan tindakan tambahan, sedangkan warm standby dapat menangani lalu lintas (pada kapasitas yang dikurangi) dengan cepat. Pilot light mengharuskan Anda mengaktifkan server, menaikkan skala, dan mungkin mengharuskan Anda melakukan deployment infrastruktur tambahan (bukan inti). Sementara itu, warm standby hanya meminta Anda untuk menaikkan skala (semuanya sudah di-deploy dan dijalankan). Pilih antara ini berdasarkan RPO kebutuhan RTO dan kebutuhan Anda.
Ketika biaya menjadi perhatian, dan Anda ingin mencapai RTO tujuan yang sama RPO dan seperti yang didefinisikan dalam strategi siaga hangat, Anda dapat mempertimbangkan solusi cloud native, seperti AWS Elastic Disaster Recovery, yang mengambil pendekatan ringan pilot dan menawarkan peningkatan RPO dan RTO target.
Langkah-langkah implementasi
-
Tentukan strategi DR yang akan memenuhi persyaratan pemulihan untuk beban kerja ini.
Memilih strategi DR adalah trade-off antara mengurangi downtime dan kehilangan data (danRPO) RTO dan biaya dan kompleksitas penerapan strategi. Sebaiknya hindari strategi yang lebih sulit dari yang dibutuhkan, karena hal ini akan menambah biaya yang tidak perlu.
Misalnya, dalam diagram berikut, bisnis telah menentukan maksimum yang diizinkan RTO serta batas dari apa yang dapat mereka belanjakan untuk strategi pemulihan layanan mereka. Mengingat tujuan bisnis, strategi DR pilot light atau warm standby akan memenuhi kriteria RTO dan biaya.
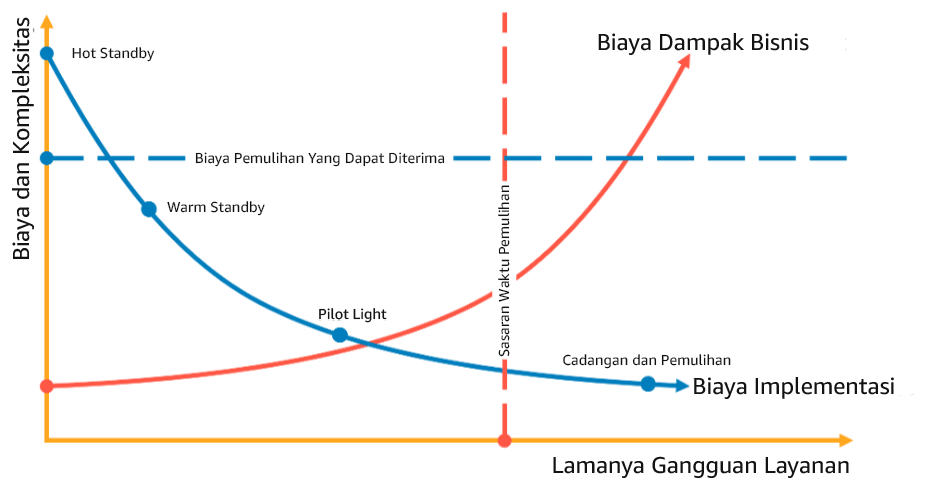
Gambar 18: Memilih strategi DR berdasarkan RTO dan biaya
Untuk mempelajari lebih lanjut, lihat Business Continuity Plan (BCP).
-
Tinjau pola tentang bagaimana strategi DR yang dipilih dapat diimplementasikan.
Langkah ini digunakan untuk memahami cara Anda mengimplementasikan strategi yang dipilih. Strategi dijelaskan menggunakan Wilayah AWS sebagai situs utama dan pemulihan. Namun, Anda juga dapat memilih untuk menggunakan Zona Ketersediaan dalam Wilayah tunggal sebagai strategi DR, yang menggunakan beberapa elemen dari berbagai strategi tersebut.
Dalam langkah berikut ini, Anda dapat menerapkan strategi pada beban kerja spesifik Anda.
Pencadangan dan pemulihan
Backup dan restore adalah strategi yang paling tidak rumit untuk diterapkan, tetapi akan membutuhkan lebih banyak waktu dan upaya untuk memulihkan beban kerja, yang mengarah ke lebih tinggi RTO danRPO. Merupakan praktik yang baik untuk selalu membuat cadangan data Anda, dan menyalinnya ke situs lain (seperti yang lain Wilayah AWS).
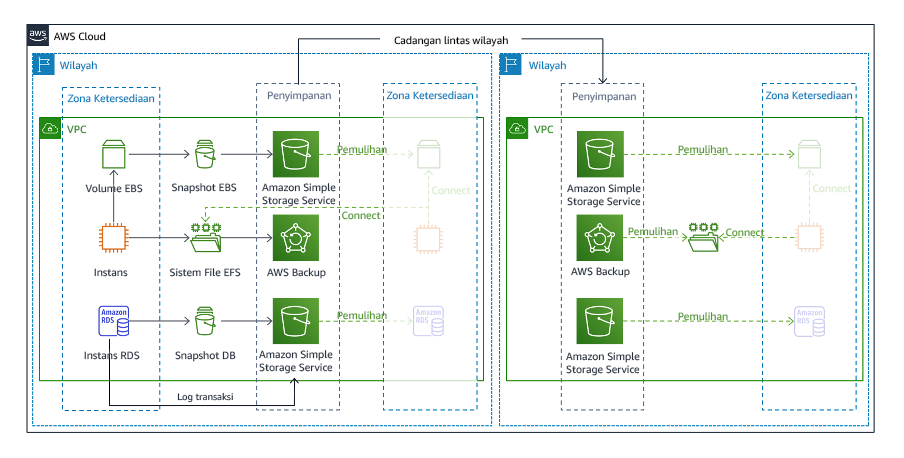
Gambar 19: Arsitektur pencadangan dan pemulihan
Untuk detail lebih lanjut tentang strategi ini, lihat Arsitektur Disaster Recovery (DR) pada AWS, Bagian II: Backup and Restore with Rapid Recovery
. Pilot light
Dengan pendekatan pilot light, Anda mereplikasi data dari Wilayah utama ke Wilayah pemulihan. Sumber daya inti yang digunakan untuk infrastruktur beban kerja di-deploy di Wilayah pemulihan. Namun, sumber daya tambahan dan dependensi lainnya masih diperlukan untuk membuat tumpukan fungsional ini. Misalnya, dalam gambar 20, tidak ada instans komputasi yang di-deploy.
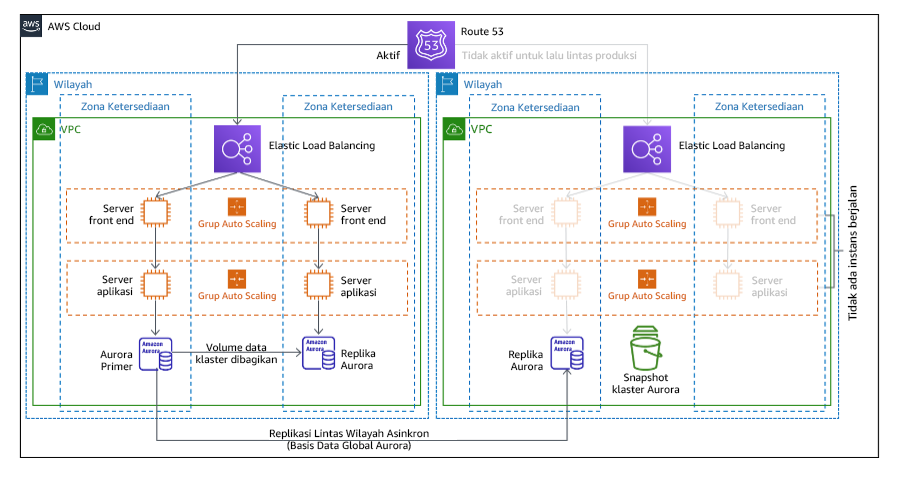
Gambar 20: Arsitektur pilot light
Untuk detail lebih lanjut tentang strategi ini, lihat Arsitektur Pemulihan Bencana (DR) di AWS, BagianIII: Pilot Light dan Warm Standby
. Warm standby
Pendekatan warm standby melibatkan memastikan ada salinan lingkungan produksi yang skalanya diturunkan tetapi berfungsi sepenuhnya di Wilayah lainnya. Pendekatan ini memperpanjang konsep pilot light dan mempercepat waktu pemulihan karena beban kerja selalu aktif di Wilayah lainnya. Jika Wilayah pemulihan di-deploy pada kapasitas penuh, hal ini disebut dengan hot standby.
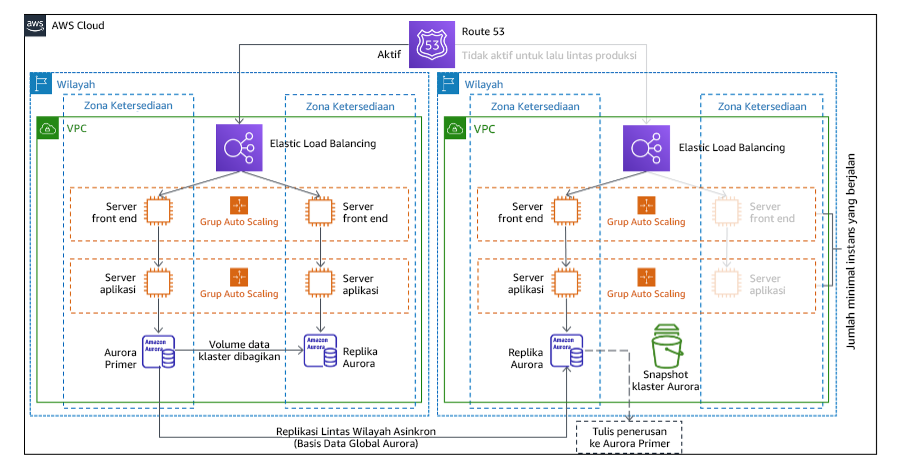
Gambar 21: Arsitektur warm standby
Saat menggunakan warm standby atau pilot light, Anda perlu menaikkan skala sumber daya di Wilayah pemulihan. Untuk memverifikasi kapasitas yang tersedia bila diperlukan, pertimbangkan penggunaan untuk reservasi kapasitas untuk EC2 instans. Jika menggunakan AWS Lambda, maka konkurensi yang disediakan dapat menyediakan lingkungan runtime sehingga mereka siap untuk segera merespons pemanggilan fungsi Anda.
Untuk detail lebih lanjut tentang strategi ini, lihat Arsitektur Pemulihan Bencana (DR) di AWS, BagianIII: Pilot Light dan Warm Standby
. Multi-situs aktif/aktif
Anda dapat menjalankan beban kerja secara berkelanjutan di beberapa Wilayah sebagai bagian dari strategi multi-situs aktif/aktif. Multi-situs aktif/aktif menjalankan lalu lintas dari semua wilayah ke wilayah tempatnya di-deploy. Konsumen dapat memilih strategi ini untuk alasan selain dari DR. Strategi ini dapat digunakan untuk meningkatkan ketersediaan, atau saat melakukan deployment beban kerja ke audiens global (untuk menempatkan titik akhir lebih dekat dengan pengguna dan/atau melakukan deployment tumpukan yang dilokalkan untuk audiens di wilayah tersebut). Sebagai strategi DR, jika beban kerja tidak dapat didukung di salah satu tempat penyebarannya, maka Wilayah tersebut dievakuasi, dan Wilayah yang tersisa digunakan untuk menjaga ketersediaan. Wilayah AWS Multi-situs aktif/aktif adalah strategi DR yang paling sulit dioperasikan, dan sebaiknya hanya dipilih saat persyaratan bisnis mengharuskannya.
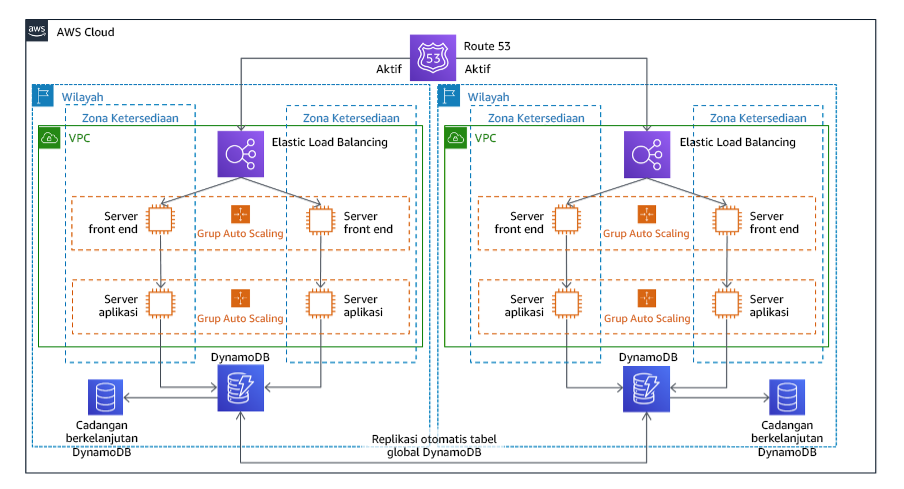
Gambar 22: Arsitektur multi-situs aktif/aktif
Untuk detail lebih lanjut tentang strategi ini, lihat Arsitektur Pemulihan Bencana (DR) di AWS, Bagian IV: Multi-situs Aktif/Aktif
. AWS Elastic Disaster Recovery
Jika Anda mempertimbangkan lampu pilot atau strategi siaga hangat untuk pemulihan bencana, AWS Elastic Disaster Recovery dapat memberikan pendekatan alternatif dengan manfaat yang lebih baik. Elastic Disaster Recovery dapat menawarkan RPO dan RTO menargetkan yang mirip dengan siaga hangat, tetapi mempertahankan pendekatan lampu pilot yang berbiaya rendah. Elastic Disaster Recovery mereplikasi data Anda dari wilayah utama Anda ke Wilayah pemulihan Anda, menggunakan perlindungan data berkelanjutan untuk mencapai RPO pengukuran dalam hitungan detik dan RTO yang dapat diukur dalam hitungan menit. Hanya sumber daya yang diperlukan untuk mereplikasi data yang di-deploy di wilayah pemulihan, yang menekan biaya tetap rendah, serupa dengan strategi pilot light. Ketika menggunakan Pemulihan Bencana Elastis, layanan mengoordinasi dan mengatur pemulihan sumber daya komputasi ketika dimulai sebagai bagian dari failover atau latihan.
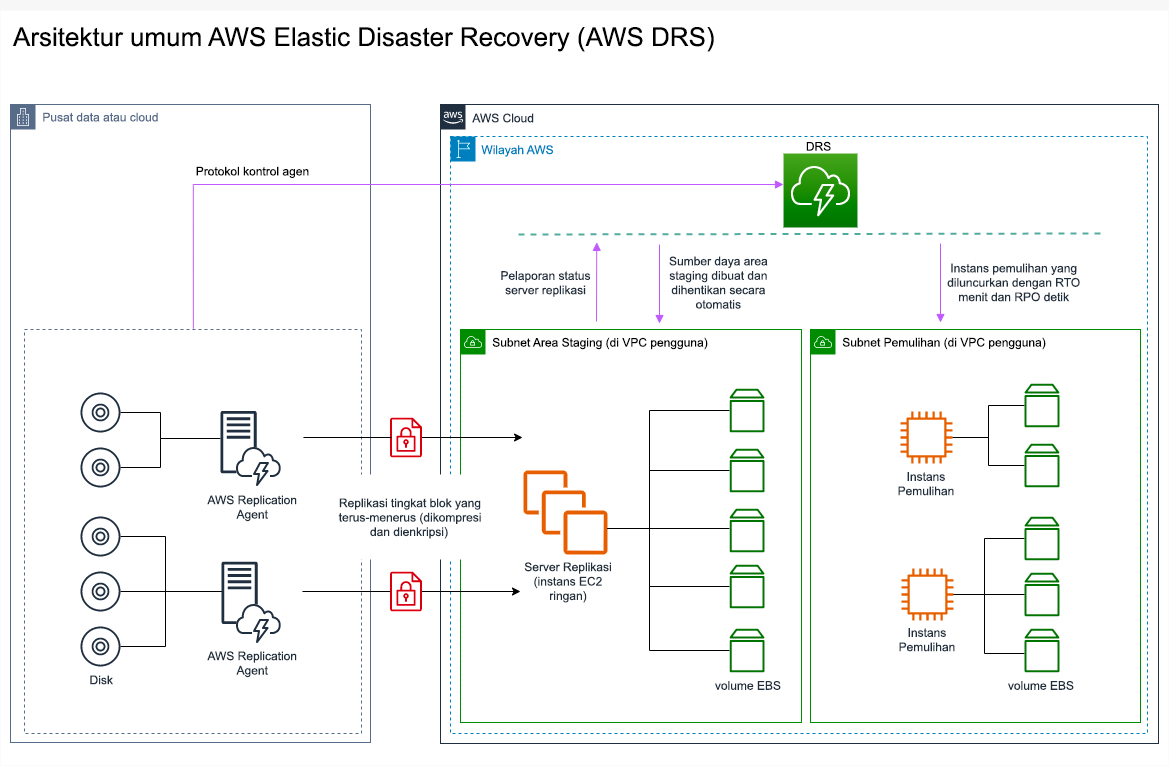
Gambar 23: AWS Elastic Disaster Recovery arsitektur
Praktik tambahan untuk melindungi data
Dengan semua strategi, Anda juga harus melakukan mitigasi terhadap bencana data. Replikasi data berkelanjutan melindungi Anda dari beberapa jenis bencana, tetapi mungkin tidak melindungi Anda dari korupsi atau penghancuran data kecuali strategi Anda juga mencakup versi data yang disimpan atau opsi untuk pemulihan. point-in-time Anda juga harus mencadangkan data yang direplikasi di situs pemulihan untuk membuat point-in-time cadangan selain replika.
Menggunakan beberapa Availability Zones (AZs) dalam satu Wilayah AWS
Saat menggunakan beberapa AZs dalam satu Wilayah, implementasi DR Anda menggunakan beberapa elemen dari strategi di atas. Pertama, Anda harus membuat arsitektur ketersediaan tinggi (HA), menggunakan beberapa AZs seperti yang ditunjukkan pada Gambar 23. Arsitektur ini menggunakan pendekatan aktif/aktif multi-situs, karena EC2instans Amazon dan Elastic Load Balancer memiliki sumber daya yang digunakan dalam beberapa permintaan yang secara aktif menyerahkan. AZs Arsitektur juga menunjukkan siaga panas, di mana jika RDS instance Amazon utama gagal (atau AZ itu sendiri gagal), maka instance siaga dipromosikan ke primer.
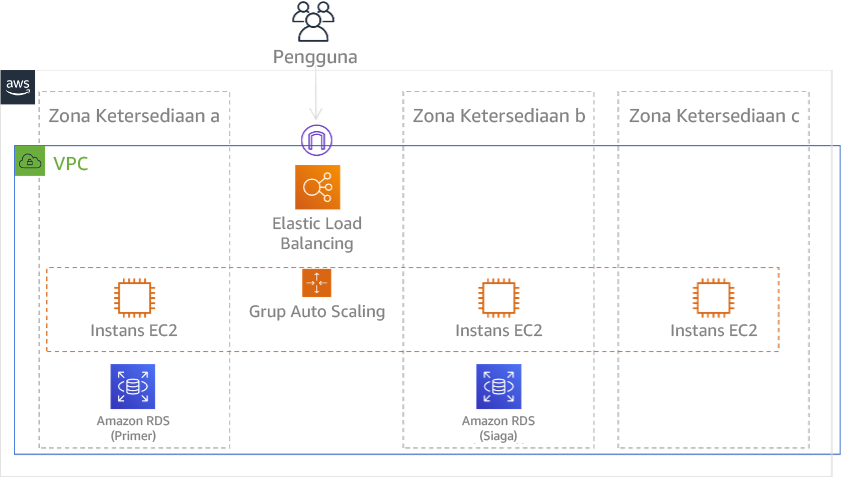
Gambar 24: Arsitektur Multi-AZ
Selain arsitektur HA ini, Anda perlu menambahkan cadangan data yang dibutuhkan untuk menjalankan beban kerja. Ini sangat penting untuk data yang dibatasi ke satu zona seperti EBSvolume Amazon atau cluster Amazon Redshift. Jika sebuah AZ gagal, Anda perlu memulihkan data ini ke AZ lainnya. Jika memungkinkan, Anda juga harus menyalin cadangan data ke yang lain Wilayah AWS sebagai lapisan perlindungan tambahan.
Pendekatan alternatif yang kurang umum untuk Wilayah tunggal, Multi-AZ DR diilustrasikan dalam posting blog, Membangun aplikasi yang sangat tangguh menggunakan Pengontrol Pemulihan Aplikasi Amazon, Bagian 1
: tumpukan Wilayah Tunggal. Di sini, strateginya adalah mempertahankan isolasi sebanyak mungkin antara yang AZs mungkin, seperti bagaimana Wilayah beroperasi. Dengan menggunakan strategi alternatif ini, Anda dapat memilih pendekatan aktif/aktif atau aktif/pasif. catatan
Beberapa beban kerja memiliki persyaratan residensi data peraturan. Jika ini berlaku untuk beban kerja Anda di wilayah yang saat ini hanya memiliki satu Wilayah AWS, maka Multi-region tidak akan sesuai dengan kebutuhan bisnis Anda. Strategi multi-AZ memberikan perlindungan yang baik terhadap sebagian besar bencana.
-
Evaluasikan sumber daya beban kerja, dan seperti apa konfigurasinya di Wilayah pemulihan sebelum failover (selama operasi normal).
Untuk infrastruktur dan AWS sumber daya gunakan infrastruktur sebagai kode seperti AWS CloudFormation
atau alat pihak ketiga seperti Hashicorp Terraform. Untuk menyebarkan di beberapa akun dan Wilayah dengan satu operasi yang dapat Anda gunakan AWS CloudFormation StackSets. Untuk strategi Multi-situs aktif/aktif dan Hot Standby, infrastruktur yang di-deploy di Wilayah pemulihan memiliki sumber daya yang sama seperti Wilayah utama. Untuk strategi Pilot Light dan Warm Standby, infrastruktur yang di-deploy memerlukan tindakan tambahan agar berubah menjadi siap produksi. Dengan menggunakan CloudFormation parameter dan logika bersyarat, Anda dapat mengontrol apakah tumpukan yang digunakan aktif atau siaga dengan satu templat . Ketika menggunakan Pemulihan Bencana Elastis, layanan akan mereplikasi dan mengatur pemulihan konfigurasi aplikasi dan sumber daya komputasi. Semua strategi DR mengharuskan sumber data dicadangkan di dalam Wilayah AWS, dan kemudian cadangan tersebut disalin ke Wilayah pemulihan. AWS Backup
menyediakan tampilan terpusat di mana Anda dapat mengonfigurasi, menjadwalkan, dan memantau cadangan untuk sumber daya ini. Untuk Pilot Light, Warm Standby, dan Multi-situs aktif/aktif, Anda juga harus mereplikasi data dari Wilayah utama ke sumber daya data di Wilayah pemulihan, seperti instans RDSDB Amazon Relational Database Service (Amazon) atau tabel Amazon DynamoDB . Dengan demikian, sumber data ini aktif dan siap menangani permintaan di Wilayah pemulihan. Untuk mempelajari lebih lanjut tentang cara AWS layanan beroperasi di seluruh Wilayah, lihat seri blog ini tentang Membuat Aplikasi Multi-Wilayah dengan AWS Layanan
. -
Tentukan dan implementasikan cara Anda mempersiapkan Wilayah untuk failover saat dibutuhkan (selama peristiwa bencana).
Untuk multi-situs aktif/aktif, failover berarti mengevakuasi Wilayah dan mengandalkan Wilayah aktif yang tersisa. Secara umum, Wilayah tersebut siap menerima lalu lintas. Untuk strategi Pilot Light dan Warm Standby, tindakan pemulihan Anda perlu menerapkan sumber daya yang hilang, seperti EC2 instance pada Gambar 20, ditambah sumber daya lain yang hilang.
Untuk semua strategi di atas, Anda mungkin perlu mengubah instans hanya-baca basis data menjadi instans baca/tulis.
Untuk pencadangan dan pemulihan, memulihkan data dari cadangan menciptakan sumber daya untuk data tersebut seperti EBS volume, instans RDS DB, dan tabel DynamoDB. Anda juga perlu memulihkan infrastruktur dan melakukan deployment kode. Anda dapat menggunakan AWS Backup untuk memulihkan data di wilayah pemulihan. Lihat REL09-BP01 Mengidentifikasi dan mencadangkan semua data yang perlu dicadangkan, atau mereproduksi data dari sumber untuk detail selengkapnya. Membangun kembali infrastruktur termasuk membuat sumber daya seperti EC2 instance selain Amazon Virtual Private Cloud VPC (Amazon)
, subnet, dan grup keamanan yang diperlukan. Anda dapat mengotomatiskan banyak proses pemulihan. Untuk mempelajari caranya, silakan lihat posting blog ini . -
Tentukan dan implementasikan cara Anda akan merutekan kembali lalu lintas ke failover saat dibutuhkan (selama peristiwa bencana).
Operasi failover ini dapat dimulai secara otomatis dan manual. Failover yang dimulai secara otomatis berdasarkan pemeriksaan kondisi atau alarm harus digunakan dengan hati-hati karena failover yang tidak perlu (alarm palsu) dapat dikenakan biaya seperti ketidaktersediaan dan kehilangan data. Oleh karena itu, Failover yang dimulai secara manual sering digunakan. Dalam kasus ini, Anda masih harus mengotomatiskan langkah failover, sehingga inisiasi manual akan seperti menekan tombol.
Ada beberapa opsi manajemen lalu lintas yang perlu dipertimbangkan saat menggunakan AWS layanan. Salah satu opsinya adalah menggunakan Amazon Route 53
. Menggunakan Amazon Route 53, Anda dapat mengaitkan beberapa titik akhir IP dalam satu atau lebih Wilayah AWS dengan nama domain Route 53. Untuk mengimplementasikan failover yang dimulai secara manual, Anda dapat menggunakan Amazon Application Recovery Controller , yang menyediakan pesawat data yang sangat tersedia API untuk mengalihkan lalu lintas ke Wilayah pemulihan. Saat mengimplementasikan failover, gunakan operasi bidang data dan hindari bidang kontrol yang dideskripsikan di REL11-BP04 Mengandalkan bidang data dan bukan bidang kontrol selama pemulihan. Untuk mempelajari lebih lanjut tentang ini dan opsi lainnya, lihat bagian ini dari Laporan Resmi Pemulihan Bencana.
-
Rancang rencana terkait bagaimana beban kerja akan failback.
Failback adalah saat Anda mengembalikan operasi beban kerja ke Wilayah utama, setelah bencana berakhir. Penyediaan infrastruktur dan kode untuk Wilayah utama umumnya mengikuti langkah yang sama yang digunakan saat memulai, dengan mengandalkan infrastruktur sebagai kode dan pipeline deployment kode. Tantangan failback adalah mengembalikan penyimpanan data, dan memastikan konsistensi dengan Wilayah pemulihan dalam operasi.
Dalam keadaan gagal, database di Wilayah pemulihan hidup dan memiliki up-to-date data. Tujuannya kemudian adalah untuk menyinkronkan kembali dari Wilayah pemulihan ke Wilayah utama, memastikannya. up-to-date
Beberapa AWS layanan akan melakukan ini secara otomatis. Jika menggunakan tabel global Amazon DynamoDB
, meskipun tabel di Wilayah utama menjadi tidak tersedia, saat kembali online, DynamoDB akan melanjutkan penulisan yang tertunda. Jika menggunakan Basis Data Global Amazon Aurora dan menggunakan failover terencana dan terkelola, topologi replikasi Aurora basis data global yang ada dipertahankan. Dengan demikian, instans baca/tulis sebelumnya di Wilayah utama akan menjadi replika dan menerima pembaruan dari Wilayah pemulihan. Dalam kasus saat ini tidak dibuat otomatis, Anda perlu menetapkan ulang basis data di Wilayah utama sebagai replika dari basis data di Wilayah pemulihan. Dalam banyak kasus, ini akan melibatkan penghapusan basis data utama yang lama dan membuat replika yang baru.
Setelah failover, jika Anda dapat tetap menjalankannya di Wilayah pemulihan, pertimbangkan untuk membuat ini menjadi Wilayah utama yang baru. Anda masih harus melakukan semua langkah di atas untuk membuat Wilayah utama sebelumnya menjadi Wilayah pemulihan. Beberapa organisasi melakukan rotasi terjadwal, menukar Wilayah utama dan pemulihan secara berkala (misalnya setiap tiga bulan).
Semua langkah yang diperlukan untuk failover dan failback harus diperiksa di buku pedoman yang tersedia untuk semua anggota tim dan ditinjau secara berkala.
Ketika menggunakan Pemulihan Bencana Elastis, layanan akan membantu mengatur dan mengotomatiskan proses failback. Untuk detail selengkapnya, lihat Melakukan failback.
Tingkat upaya untuk Rencana Implementasi: Tinggi
Sumber daya
Praktik-praktik terbaik terkait:
Dokumen terkait:
Video terkait:
Contoh terkait:
-
Lab Well-Architected - Pemulihan Bencana
- Rangkaian lokakarya yang menggambarkan strategi DR
