Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Model Tanggung Jawab Bersama untuk Ketangguhan
Ketahanan adalah tanggung jawab bersama antara Anda AWS dan Anda. Anda harus memahami cara pemulihan bencana (DR) dan ketersediaan beroperasi, sebagai bagian dari ketangguhan, menurut model tanggung jawab bersama ini.
AWS tanggung jawab - Ketahanan cloud
AWS bertanggung jawab atas ketahanan infrastruktur yang menjalankan semua layanan yang ditawarkan di. AWS Cloud Infrastruktur ini terdiri dari perangkat keras, perangkat lunak, jaringan, dan fasilitas yang menjalankan AWS Cloud layanan. AWS menggunakan upaya yang wajar secara komersial untuk membuat AWS Cloud layanan ini tersedia, memastikan ketersediaan layanan memenuhi atau melampaui Perjanjian Tingkat AWS Layanan (SLAs)
Infrastruktur Cloud Global AWS
Tanggung jawab pelanggan - Ketahanan di cloud
Tanggung jawab Anda ditentukan oleh AWS Cloud layanan yang Anda pilih. Hal ini akan menentukan jumlah konfigurasi kerja yang harus Anda lakukan sebagai bagian dari tanggung jawab ketangguhan Anda. Misalnya, layanan seperti Amazon Elastic Compute Cloud (AmazonEC2) mengharuskan pelanggan untuk melakukan semua konfigurasi ketahanan dan tugas manajemen yang diperlukan. Pelanggan yang menerapkan EC2 instans Amazon bertanggung jawab untuk menerapkan instans EC2 Amazon di beberapa lokasi (seperti AWS Availability Zone), menerapkan penyembuhan mandiri menggunakan layanan seperti Auto Scaling, dan menggunakan praktik terbaik arsitektur beban kerja tangguh untuk aplikasi yang diinstal pada instans. Untuk layanan terkelola, seperti Amazon S3 dan Amazon DynamoDB AWS , mengoperasikan lapisan infrastruktur, sistem operasi, dan platform, dan pelanggan mengakses titik akhir untuk menyimpan dan mengambil data. Anda bertanggung jawab untuk mengelola ketangguhan data Anda, termasuk strategi pencadangan, penentuan versi, dan replikasi.
Menerapkan beban kerja Anda di beberapa Availability Zone Wilayah AWS merupakan bagian dari strategi ketersediaan tinggi yang dirancang untuk melindungi beban kerja dengan mengisolasi masalah ke satu Availability Zone, yang menggunakan redundansi Availability Zone lainnya untuk terus melayani permintaan. Arsitektur Multi-AZ juga merupakan bagian dari strategi DR yang didesain untuk membuat beban kerja menjadi lebih terisolasi dan terlindungi dari masalah-masalah seperti pemadaman listrik, sambaran petir, angin topan, gempa bumi, dan lain-lain. Strategi DR juga dapat menggunakan beberapa Wilayah AWS. Contohnya, dalam sebuah konfigurasi aktif/pasif, layanan untuk beban kerja mengalami failover dari Wilayah aktifnya ke Wilayah DR-nya jika Wilayah aktif tidak dapat lagi melayani permintaan.
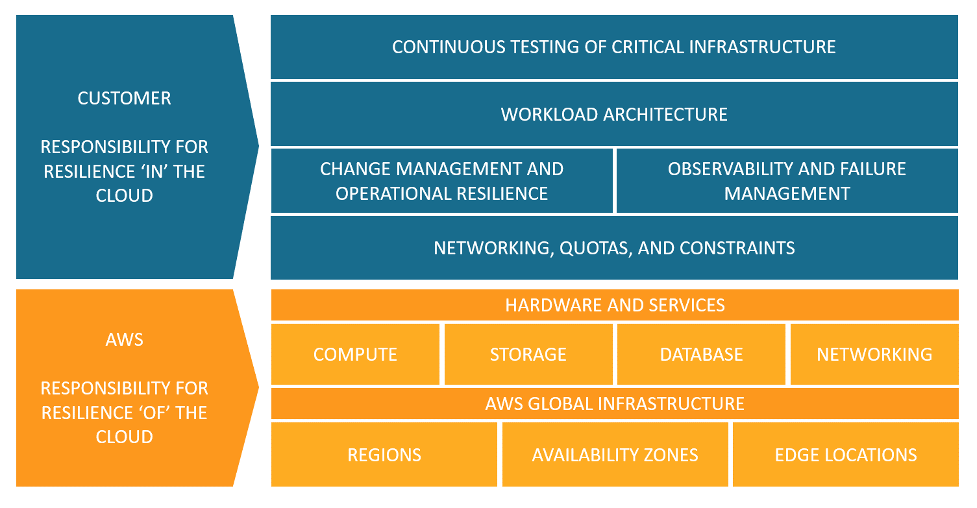
Tanggung jawab untuk ketahanan di dalam dan dari cloud untuk pelanggan dan AWS.
Anda dapat menggunakan AWS layanan untuk mencapai tujuan ketahanan Anda. Sebagai pelanggan, Anda bertanggung jawab atas manajemen aspek-aspek berikut dari sistem Anda untuk mencapai ketangguhan di cloud. Untuk detail lebih lanjut tentang masing-masing layanan secara khusus, lihat dokumentasi AWS.
Jaringan, kuota, dan kendala
-
Praktik terbaik untuk area model tanggung jawab bersama ini dijelaskan secara rinci di bagian Landasan.
-
Rencanakan arsitektur Anda dengan ruang yang memadai untuk menskalakan dan pahami kuota layanan (service quotas) dan kendala layanan yang Anda sertakan, berdasarkan peningkatan permintaan beban yang diharapkan jika berlaku.
-
Rancang desain topologi jaringan Anda agar mempunyai ketersediaan yang tinggi, redundan, dan dapat diskalakan.
Manajemen perubahan dan ketahanan operasional
-
Manajemen perubahan mencakup cara memperkenalkan dan mengelola perubahan yang dibuat di lingkungan Anda. Menerapkan perubahan memerlukan pembuatan dan pemeliharaan runbook agar tetap mutakhir dan strategi deployment untuk aplikasi dan infrastruktur Anda.
-
Strategi tangguh untuk memantau sumber daya beban kerja harus mempertimbangkan semua komponen, termasuk metrik teknis dan bisnis, notifikasi, otomatisasi, dan analisis.
-
Beban kerja di cloud harus beradaptasi dengan perubahan pada penskalaan permintaan sebagai reaksi terhadap gangguan atau fluktuasi penggunaan.
Manajemen observabilitas dan kegagalan
-
Mengamati kegagalan melalui pemantauan diperlukan untuk melakukan otomatisasi penyembuhan sehingga beban kerja Anda dapat menahan kegagalan komponen.
-
Manajemen kegagalan memerlukan pencadangan data, menerapkan praktik terbaik untuk memungkinkan beban kerja Anda bisa bertahan dari kegagalan komponen, dan perencanaan pemulihan bencana.
Arsitektur beban kerja
-
Arsitektur beban kerja Anda mencakup cara Anda merancang layanan di sekitar domain bisnis, menerapkan SOA dan mendistribusikan desain sistem untuk mencegah kegagalan, dan membangun kemampuan seperti pelambatan, percobaan ulang, manajemen antrian, batas waktu, dan tuas darurat.
-
Andalkan solusi AWS
yang telah terbukti, Amazon Builders Library , dan pola nirserver untuk menyelaraskan dengan praktik terbaik dan implementasi jump start. -
Gunakan peningkatan berkelanjutan untuk menguraikan sistem Anda menjadi layanan-layanan terdistribusi guna menskalakan dan berinovasi lebih cepat. Gunakan panduan layanan mikro AWS
dan opsi layanan terkelola untuk menyederhanakan dan mempercepat kemampuan Anda untuk memperkenalkan perubahan dan melahirkan inovasi.
Pengujian terus-menerus atas infrastruktur penting
-
Menguji keandalan adalah pengujian yang dilakukan pada tingkat fungsional, kinerja, dan kekacauan, serta mengadopsi analisis insiden dan praktik game day untuk membangun keahlian dalam menyelesaikan masalah yang tidak dipahami dengan baik.
-
Untuk aplikasi cloud all-in maupun aplikasi hibrida, mengetahui perilaku aplikasi ketika ada masalah yang timbul atau ketika ada komponen yang tidak berfungsi akan memampukan Anda untuk pulih dari penghentian dengan cepat dan andal.
-
Buat dan dokumentasikan eksperimen yang dapat diulang untuk memahami perilaku sistem Anda ketika operasi tidak berjalan sesuai harapan. Pengujian ini akan membuktikan keefektifan ketangguhan secara keseluruhan dan memberikan Anda lingkaran umpan balik untuk prosedur operasional Anda sebelum menghadapi skenario kegagalan yang sebenarnya.
