Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Throughput elevato per le code FIFO in Amazon SQS
Le code FIFO ad alto throughput di Amazon SQS gestiscono in modo efficiente un'elevata velocità di trasmissione dei messaggi mantenendo al contempo un ordine rigoroso dei messaggi, garantendo affidabilità e scalabilità per le applicazioni che elaborano numerosi messaggi. Questa soluzione è ideale per scenari che richiedono sia un throughput elevato che la consegna di messaggi ordinati.
Le code FIFO ad alta velocità di Amazon SQS non sono necessarie in scenari in cui l'ordinamento rigoroso dei messaggi non è fondamentale e in cui il volume dei messaggi in arrivo è relativamente basso o sporadico. Ad esempio, se disponi di un'applicazione su piccola scala che elabora messaggi poco frequenti o non sequenziali, la complessità e i costi aggiuntivi associati alle code FIFO ad alta velocità potrebbero non essere giustificati. Inoltre, se la tua applicazione non richiede le funzionalità di throughput avanzate fornite dalle code FIFO ad alto throughput, optare per una coda Amazon SQS standard potrebbe essere più conveniente e più semplice da gestire.
Per migliorare la capacità di richiesta nelle code FIFO ad alta velocità di trasmissione, si consiglia di aumentare il numero di gruppi di messaggi. Per ulteriori informazioni sulle quote di messaggi a throughput elevato, consulta Amazon SQS service quotas nella Riferimenti generali di Amazon Web Services.
Per informazioni sulle quote per coda e sulle strategie di distribuzione dei dati, vedere e. Quote di messaggi Amazon SQS Partizioni e distribuzione dei dati per una velocità di trasmissione effettiva elevata per le code FIFO SQS
Casi d'uso per un throughput elevato per le code FIFO di Amazon SQS
I seguenti casi d'uso evidenziano le diverse applicazioni delle code FIFO ad alta velocità e ne dimostrano l'efficacia in diversi settori e scenari:
-
Elaborazione dei dati in tempo reale: le applicazioni che gestiscono flussi di dati in tempo reale, come l'elaborazione di eventi o l'inserimento di dati di telemetria, possono trarre vantaggio dalle code FIFO ad alta velocità per gestire l'afflusso continuo di messaggi preservandone l'ordine per un'analisi accurata.
-
Elaborazione degli ordini di e-commerce: nelle piattaforme di e-commerce in cui il mantenimento dell'ordine delle transazioni con i clienti è fondamentale, le code FIFO ad alta produttività assicurano che gli ordini vengano elaborati in sequenza e senza ritardi, anche durante l'alta stagione degli acquisti.
-
Servizi finanziari: gli istituti finanziari che gestiscono dati di negoziazione o transazionali ad alta frequenza si affidano a code FIFO ad alta velocità per elaborare i dati di mercato e le transazioni con una latenza minima, rispettando al contempo i severi requisiti normativi per l'ordinazione dei messaggi.
-
Streaming multimediale: le piattaforme di streaming e i servizi di distribuzione multimediale utilizzano code FIFO ad alta velocità per gestire la distribuzione di file multimediali e contenuti in streaming, garantendo esperienze di riproduzione fluide per gli utenti e mantenendo il corretto ordine di distribuzione dei contenuti.
Partizioni e distribuzione dei dati per una velocità di trasmissione effettiva elevata per le code FIFO SQS
Amazon SQS memorizza i dati delle code FIFO nelle partizioni. Una partizione è un'allocazione di spazio di archiviazione per una coda che viene replicata automaticamente su più zone di disponibilità all'interno di una regione. AWS Non si gestiscono le partizioni. Al contrario, Amazon SQS gestisce la gestione delle partizioni.
Per le code FIFO, Amazon SQS modifica il numero di partizioni in una coda nelle seguenti situazioni:
-
Se la frequenza di richiesta corrente si avvicina o supera quella supportata dalle partizioni esistenti, vengono allocate partizioni aggiuntive finché la coda non raggiunge la quota regionale. Per informazioni sulle quote, consulta Quote di messaggi Amazon SQS.
-
Se le partizioni correnti sono poco utilizzate, il numero di partizioni può essere ridotto.
La gestione delle partizioni avviene automaticamente in background ed è trasparente per le tue applicazioni. La coda e i messaggi sono sempre disponibili.
Distribuzione dei dati per gruppo di messaggi IDs
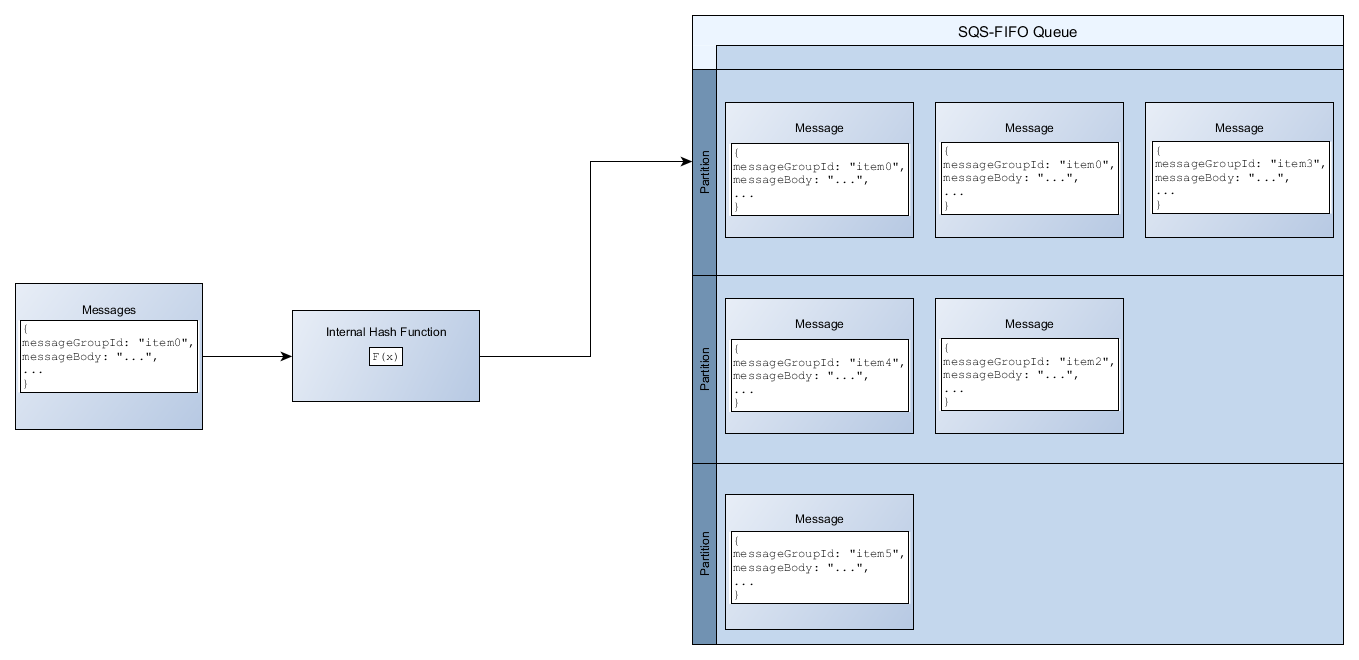
Per aggiungere un messaggio a una coda FIFO, Amazon SQS utilizza il valore dell'ID del gruppo di messaggi di ogni messaggio come input per una funzione hash interna. Il valore di output dalla funzione hash determina la partizione in cui verrà memorizzato il messaggio.
Il seguente diagramma mostra una coda che si estende su più partizioni. L'ID del gruppo di messaggi della coda si basa sul numero dell'elemento. Amazon SQS utilizza la funzione hash per determinare dove memorizzare un nuovo elemento, in questo caso in base al valore hash della stringa item0. Si noti che gli elementi vengono memorizzati nello stesso ordine in cui vengono aggiunti alla coda. La posizione di ciascun item è determinata dal valore hash dell’ID del gruppo di messaggi.
Nota
Amazon SQS è ottimizzato per la distribuzione uniforme degli elementi nelle partizioni di una coda FIFO, indipendentemente dal numero di partizioni. AWS consiglia di utilizzare un gruppo di messaggi IDs che può avere un gran numero di valori distinti.
Ottimizzazione dell'utilizzo delle partizioni
Ogni partizione supporta fino a 3.000 messaggi al secondo con batch o fino a 300 messaggi al secondo per operazioni di invio, ricezione ed eliminazione nelle regioni supportate. Per ulteriori informazioni sulle quote di messaggi a throughput elevato, consulta Amazon SQS service quotas nella Riferimenti generali di Amazon Web Services.
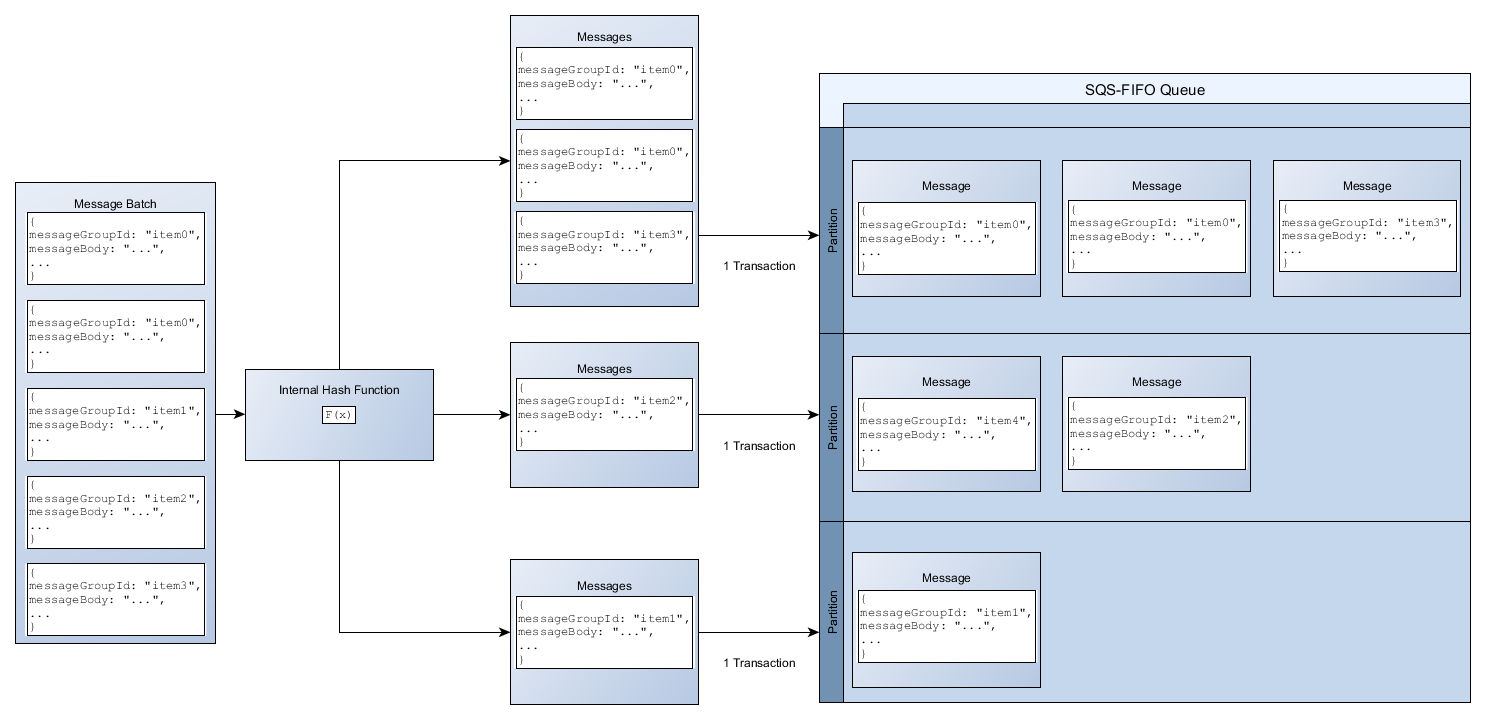
Quando si utilizza il batch APIs, ogni messaggio viene instradato in base al processo descritto inDistribuzione dei dati per gruppo di messaggi IDs. I messaggi indirizzati alla stessa partizione vengono raggruppati ed elaborati in un'unica transazione.
Per ottimizzare l'utilizzo delle partizioni per l'SendMessageBatchAPI, AWS consiglia di raggruppare i messaggi in batch con lo stesso gruppo di messaggi, quando possibile. IDs
Per ottimizzare l'utilizzo della partizione per DeleteMessageBatch and ChangeMessageVisibilityBatch APIs, AWS consiglia di utilizzare le ReceiveMessage richieste con il MaxNumberOfMessages parametro impostato su 10 e di raggruppare in batch gli handle di ricezione restituiti da una singola richiesta. ReceiveMessage
Nell'esempio seguente, viene inviato un batch di messaggi con diversi gruppi di messaggi. IDs Il batch viene suddiviso in tre gruppi, ognuno dei quali viene conteggiato nella quota della partizione.
Nota
Amazon SQS garantisce solo che i messaggi con la funzione hash interna dello stesso ID del gruppo di messaggi siano raggruppati all'interno di una richiesta batch. A seconda dell'output della funzione hash interna e del numero di partizioni, è IDs possibile raggruppare i messaggi con gruppi di messaggi diversi. Poiché la funzione hash o il numero di partizioni possono cambiare in qualsiasi momento, i messaggi raggruppati in un punto non possono essere raggruppati in un secondo momento.
