Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Auto Scaling dei cluster Valkey e Redis OSS
Prerequisiti
ElastiCache L'Auto Scaling è limitato a quanto segue:
-
Cluster Valkey o Redis OSS (modalità cluster abilitata) che eseguono Valkey 7.2 e versioni successive o Redis OSS 6.0 in poi
-
Cluster di data tiering (modalità cluster abilitata) che eseguono Valkey 7.2 e versioni successive o Redis OSS 7.0.7 in poi
-
Dimensioni istanza - Large, XL, 2xLarge
-
Famiglie di tipi di istanza: R7g, R6g, R6gd, R5, M7g, M6g, M5, C7gn
-
L'Auto Scaling in non ElastiCache è supportato per i cluster in esecuzione in datastore globali, Outposts o Local Zones.
Gestione automatica della capacità con ElastiCache Auto Scaling con Valkey o Redis OSS
ElastiCache la scalabilità automatica con Valkey o Redis OSS è la capacità di aumentare o diminuire automaticamente gli shard o le repliche desiderati nel servizio. ElastiCache ElastiCache sfrutta il servizio Application Auto Scaling per fornire questa funzionalità. Per ulteriori informazioni, consulta Application Auto Scaling. Per utilizzare il ridimensionamento automatico, è necessario definire e applicare una politica di ridimensionamento che utilizza CloudWatch metriche e valori target assegnati dall'utente. ElastiCache la scalabilità automatica utilizza la policy per aumentare o diminuire il numero di istanze in risposta ai carichi di lavoro effettivi.
È possibile utilizzare il AWS Management Console per applicare una politica di scalabilità basata su una metrica predefinita. Un predefined metric viene definito in un'enumerazione in modo che tu possa specificarlo per nome nel codice o utilizzarlo nella AWS Management Console. I parametri personalizzati non possono essere selezionati tramite AWS Management Console. In alternativa, puoi utilizzare l'API Application Auto Scaling AWS CLI o l'API Application Auto Scaling per applicare una politica di scalabilità basata su una metrica predefinita o personalizzata.
ElastiCache per Valkey e Redis OSS supporta la scalabilità per le seguenti dimensioni:
-
Shards: shard add/remove automatici nel cluster, in modo simile al resharding manuale online. In questo caso, il ridimensionamento ElastiCache automatico attiva la scalabilità per tuo conto.
-
Repliche: repliche add/remove automatiche nel cluster in modo simile alle operazioni di replica manuali. Increase/Decrease ElastiCache scalabilità automatica per le adds/removes repliche Valkey e Redis OSS in modo uniforme su tutti gli shard del cluster.
ElastiCache per Valkey e Redis OSS supporta i seguenti tipi di politiche di scalabilità automatica:
-
Policy di dimensionamento con monitoraggio degli obiettivi— Aumenta o diminuisci il numero di operazioni shards/replicas eseguite dal servizio in base a un valore target per una metrica specifica. Questa operazione può essere paragonata al modo in cui il termostato regola la temperatura di una casa. Tu selezioni la temperatura, il termostato si occupa del resto.
-
Scalabilità pianificata per la tua applicazione. — ElastiCache per Valkey e Redis OSS, la scalabilità automatica può aumentare o diminuire il numero di operazioni eseguite shards/replicas dal servizio in base alla data e all'ora.
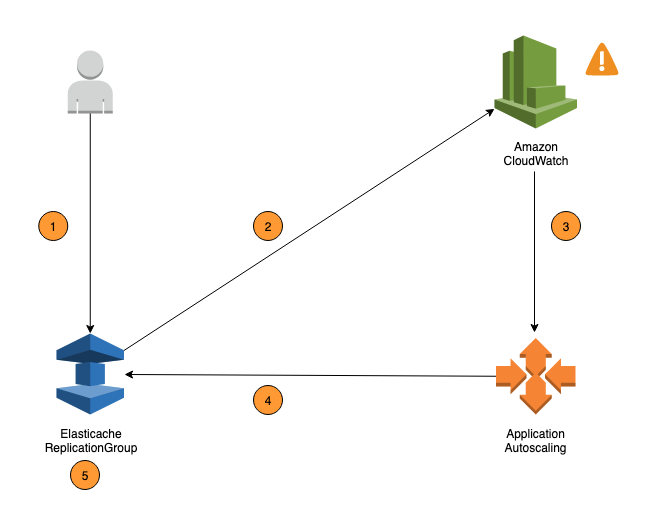
I seguenti passaggi riassumono il processo di scalabilità automatica ElastiCache per Valkey e Redis OSS come mostrato nel diagramma precedente:
-
È possibile creare una policy di scalabilità ElastiCache automatica per il gruppo di replica.
-
ElastiCache il ridimensionamento automatico crea un paio di CloudWatch allarmi per tuo conto. Ogni coppia rappresenta i tuoi limiti superiore e inferiore per i parametri. Questi CloudWatch allarmi vengono attivati quando l'utilizzo effettivo del cluster si discosta dall'utilizzo previsto per un periodo di tempo prolungato. Puoi ora visualizzare gli allarm nella console .
-
Se il valore della metrica configurata supera l'utilizzo previsto (o scende al di sotto dell'obiettivo) per un periodo di tempo specifico, CloudWatch attiva un allarme che richiama l'auto scaling per valutare la politica di scalabilità.
-
ElastiCache auto scaling invia una richiesta di modifica per regolare la capacità del cluster.
-
ElastiCache elabora la richiesta di modifica, aumentando (o diminuendo) dinamicamente la Shards/Replicas capacità del cluster in modo che si avvicini all'utilizzo previsto.
Per capire come funziona ElastiCache Auto Scaling, supponiamo di avere un cluster denominato. UsersCluster Monitorando le CloudWatch metriche perUsersCluster, si determina il numero massimo di shard richiesti dal cluster quando il traffico è al suo picco e il numero minimo di shard quando il traffico è nel punto più basso. Decidi anche un valore di destinazione per l'utilizzo della CPU per il cluster. UsersCluster ElastiCache auto scaling utilizza il suo algoritmo di tracciamento del target per garantire che gli shard di UsersCluster forniti vengano regolati secondo necessità in modo che l'utilizzo rimanga pari o vicino al valore target.
Nota
La scalabilità potrebbe richiedere molto tempo e richiederà risorse di cluster aggiuntive per il ribilanciamento degli shard. ElastiCache Auto Scaling modifica le impostazioni delle risorse solo quando il carico di lavoro effettivo rimane elevato (o depresso) per un periodo prolungato di diversi minuti. L'algoritmo di tracciamento del target con scalabilità automatica cerca di mantenere l'utilizzo del target pari o vicino al valore prescelto a lungo termine.
Autorizzazioni IAM richieste per l'Auto Scaling
ElastiCache per Valkey e Redis OSS Auto Scaling è reso possibile da una combinazione delle API e ElastiCache Application CloudWatch Auto Scaling. I cluster vengono creati e aggiornati con ElastiCache, gli allarmi vengono creati e le politiche di scalabilità vengono create con CloudWatch Application Auto Scaling. Oltre alle autorizzazioni IAM standard per la creazione e l'aggiornamento dei cluster, l'utente IAM che accede alle impostazioni di ElastiCache Auto Scaling deve disporre delle autorizzazioni appropriate per i servizi che supportano la scalabilità dinamica. In questa policy più recente abbiamo aggiunto il supporto per il ridimensionamento verticale di Memcached, con l'azione. elasticache:ModifyCacheCluster Gli utenti IAM devono disporre dell'autorizzazione per utilizzare le operazioni nella seguente policy di esempio:
Service-linked ruolo
Il servizio di scalabilità automatica ElastiCache per Valkey e Redis OSS richiede inoltre l'autorizzazione per descrivere i cluster e gli CloudWatch allarmi e le autorizzazioni per modificare la capacità di destinazione per tuo ElastiCache conto. Se abiliti Auto Scaling per il tuo cluster, viene creato un ruolo collegato al servizio denominato. AWSServiceRoleForApplicationAutoScaling_ElastiCacheRG Questo ruolo collegato al servizio concede l'autorizzazione alla scalabilità ElastiCache automatica per descrivere gli allarmi per le tue politiche, monitorare la capacità attuale del parco veicoli e modificare la capacità del parco veicoli. Il ruolo collegato al servizio è il ruolo predefinito per la scalabilità ElastiCache automatica. Per ulteriori informazioni, consulta Service-linked i ruoli ElastiCache per l'autoscaling Redis OSS nella Application Auto Scaling User Guide.
Best practice Auto Scaling
Prima di effettuare la registrazione a Auto Scaling, ti consigliamo di attenerti alle seguenti indicazioni:
-
Usa una sola metrica di tracciamento: consente di identificare se il cluster dispone di carichi di lavoro che utilizzano notevoli risorse di CPU o dati e di utilizzare la metrica predefinita corrispondente per definire la policy di dimensionamento.
-
CPU del motore:
ElastiCachePrimaryEngineCPUUtilization(dimensione partizione) oElastiCacheReplicaEngineCPUUtilization(dimensione replica) -
Utilizzo del database:
ElastiCacheDatabaseCapacityUsageCountedForEvictPercentagequesta policy di dimensionamento è ideale con maxmemory-policy impostato su noeviction sul cluster.
Ti consigliamo di evitare più policy per dimensione nel cluster. ElastiCache per Valkey e Redis OSS Auto scaling ridimensionerà la destinazione scalabile se alcune policy di tracciamento delle destinazioni sono pronte per la scalabilità orizzontale, ma la scalerà solo se tutte le politiche di tracciamento della destinazione (con la parte scalabile abilitata) sono pronte per la scalabilità orizzontale. Se più policy impongono alla destinazione scalabile un dimensionamento orizzontale o verticale contemporaneamente, viene dimensionata in base al criterio che fornisce la capacità massima sia per riduzione orizzontale che per il dimensionamento orizzontale.
-
-
Metriche personalizzate per il monitoraggio di Target: fai attenzione quando utilizzi metriche personalizzate per il monitoraggio di Target, poiché la scalabilità automatica è più adatta alla scalabilità, proporzionale alle variazioni delle metriche scelte per la policy. out/in Se tali metriche non cambiano proporzionalmente alle operazioni di dimensionamento utilizzate per la creazione della policy, potrebbero verificarsi operazioni di scalabilità orizzontale o ridimensionamento continue che possono influire sulla disponibilità o sui costi.
Per i cluster dei livelli di dati (tipi di istanza della famiglia r6gd), evita di utilizzare metriche basate sulla memoria per il dimensionamento.
-
Scalabilità pianificata: se ritieni che il tuo carico di lavoro sia deterministico (viene raggiunto high/low in un momento specifico), ti consigliamo di utilizzare Scheduled Scaling e configurare la capacità target in base alle necessità. Il monitoraggio dell’obiettivo è ideale per carichi di lavoro non deterministici e per il cluster per un funzionamento con la metrica obiettivo richiesta, con aumento orizzontale quando occorrono più risorse e riduzione orizzontale quando occorrono meno risorse.
-
Disattiva Scale-In: la scalabilità automatica su Target Tracking è la soluzione ideale per i cluster con carichi di lavoro graduali, poiché spikes/dip le metriche possono increase/decrease innescare oscillazioni di scala consecutive. out/in Per evitare tali oscillazioni, puoi iniziare con la riduzione orizzontale disabilitata e utilizzarla manualmente in un secondo momento in base alla necessità.
-
Testa la tua applicazione: ti consigliamo di testare l'applicazione con i Min/Max carichi di lavoro stimati per determinare il minimo e il massimo assoluti shards/replicas richiesti per il cluster, creando al contempo politiche di scalabilità per evitare problemi di disponibilità. La scalabilità automatica può effettuare l’aumento orizzontale fino alla soglia massima e la riduzione orizzontale fino alla soglia minima configurata per l’obiettivo.
-
Definizione del valore target: è possibile analizzare le CloudWatch metriche corrispondenti per l'utilizzo del cluster in un periodo di quattro settimane per determinare la soglia del valore target. Se non sei ancora certo del valore da scegliere, ti consigliamo di iniziare con il valore predefinito minimo supportato della metrica.
-
AutoScaling on Target Tracking è più adatto per i cluster con distribuzione uniforme dei carichi di lavoro tra le dimensioni. shards/replicas Avere una distribuzione non uniforme può portare a:
-
Scalabilità quando non necessaria a causa del carico di lavoro spike/dip su pochi hot. shards/replicas
-
Non scalabile quando richiesto a causa della media complessiva vicina all'obiettivo anche se la temperatura è elevata. shards/replicas
-
Nota
Durante la scalabilità orizzontale del cluster, ElastiCache replicherà automaticamente le funzioni caricate in uno dei nodi esistenti (selezionati a caso) sui nuovi nodi. Se il cluster utilizza Valkey o Redis OSS 7.0 o versioni successive e l'applicazione utilizza Functions, consigliamo di caricare tutte le funzioni
Dopo la registrazione a, tieni presente quanto segue: AutoScaling
-
Esistono limitazioni sulle configurazioni del dimensionamento automatico supportate, per cui è preferibile non modificare la configurazione di un gruppo di replica registrato per il dimensionamento automatico. Di seguito vengono mostrati gli esempi:
-
Modifica manuale del tipo di istanza in tipi non supportati.
-
Associazione del gruppo di replica a un Global Datastore.
-
Modifica
ReservedMemoryPercentparametro . -
increasing/decreasing shards/replicas Oltre manualmente la Min/Max capacità configurata durante la creazione delle policy.
-
