Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Alta disponibilità utilizzando gruppi di replica
Single-node I cluster Amazon ElastiCache Valkey e Redis OSS sono entità in memoria con servizi di protezione dei dati (AOF) limitati. Se il cluster non viene eseguito per qualsiasi motivo, tutti i dati del cluster vengono persi. Tuttavia, se utilizzi un motore Valkey o Redis OSS, puoi raggruppare da 2 a 6 nodi in un cluster con repliche in cui da 1 a 5 nodi di sola lettura contengono dati replicati del singolo nodo primario del gruppo. read/write In questo scenario, se un nodo non viene eseguito per qualsiasi motivo, non tutti i dati vengono persi poiché vengono replicati in uno o più nodi. A causa della latenza di replica, alcuni dati potrebbero andare persi se è il nodo primario a fallire. read/write
Come illustrato nell'immagine seguente, la struttura di replica è contenuta all'interno di uno shard (chiamato gruppo di nodi in the API/CLI) contenuto all'interno di un cluster Valkey o Redis OSS. I cluster Valkey o Redis OSS (modalità cluster disabilitata) hanno sempre uno shard. I cluster Valkey o Redis OSS (modalità cluster abilitata) possono avere fino a 500 shard con i dati del cluster partizionati tra gli shard. Puoi creare un cluster con un numero più alto dle partizioni e un numero più basso di repliche per un totale di 90 nodi per cluster. Questa configurazione del cluster può andare da 90 partizioni e 0 repliche a 15 partizioni e 5 repliche che è il numero massimo consentito di repliche.
Il limite di nodi o shard può essere aumentato fino a un massimo di 500 per cluster con Valkey e con la versione 5.0.6 o ElastiCache successiva per Redis OSS. ElastiCache Ad esempio, è possibile scegliere di configurare un cluster a 500 nodi che varia tra 83 partizioni (un primario e 5 repliche per partizione) e 500 partizioni (un singolo primario e nessuna replica). Assicurati che esistano abbastanza indirizzi IP disponibili per soddisfare l'aumento. Le problematiche comuni sono che le le sottoreti nel gruppo di sottoreti hanno un intervallo CIDR troppo piccolo o che le sottoreti sono condivise e utilizzate pesantemente da altri cluster. Per ulteriori informazioni, consulta Creazione di un gruppo di sottoreti.
Per le versioni inferiori alla 5.0.6, il limite è 250 per cluster.
Per richiedere un aumento dei limiti, consulta Limiti dei servizi AWS e seleziona il tipo di limite Nodi per cluster per tipo di istanza.
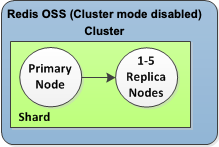
Il cluster Valkey o Redis OSS (modalità cluster disabilitata) ha uno shard e da 0 a 5 nodi di replica
Se il cluster con repliche è Multi-AZ abilitato e il nodo primario si guasta, il principale esegue il failover su una replica di lettura. Poiché i dati sui nodi di replica vengono aggiornati in maniera asincrona, è possibile che alcuni dati vengano persi a causa della latenza di aggiornamento dei nodi di replica. Per ulteriori informazioni, consulta Mitigazione degli errori durante l'esecuzione di Valkey o Redis OSS.
Nota
Per i cluster con durabilità abilitata, i dati vengono conservati in un registro Multi-AZ transazionale e possono essere ripristinati anche in caso di guasto di tutti i nodi. Con le scritture sincrone, nessun dato riconosciuto viene perso durante il failover. Con le scritture asincrone, è possibile perdere fino a 10 secondi di dati in caso di errore.
Argomenti
Replica con durabilità abilitata
Per i cluster Valkey 9.0+ con durabilità abilitata, la replica è mediata dal log Multi-AZ transazionale anziché dallo streaming diretto dal principale alla replica. Il nodo primario scrive nel log transazionale e le repliche utilizzano in modo indipendente le scritture impegnate dal log. Questa architettura consente il ripristino delle repliche in modo indipendente senza imporre un carico sul nodo primario.
Sincronizzazione e backup con durabilità
Per i cluster con durabilità abilitata, le operazioni di sincronizzazione e backup differiscono dai cluster standard:
Off-box snapshotting: le istantanee vengono create da istanze temporanee che leggono dal log delle transazioni, eliminando l'impatto sulle prestazioni del cluster. Multi-AZ
Log-based ripristino: le repliche non riuscite vengono ripristinate dal registro delle transazioni e dalle istantanee anziché richiedere una sincronizzazione completa dal primario.
