Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Gestione Aurora PostgreSQL connessione: zangola con piscina
In caso di connessione e disconnessione frequente delle applicazioni client, è possibile che il tempo di risposta del cluster database Aurora PostgreSQL rallenti. In questo caso si dice che nel cluster si verifica un abbandono della connessione. Ogni nuova connessione all'endpoint del cluster database Aurora PostgreSQL consuma risorse, riducendo pertanto quelle che possono essere utilizzate per elaborare il carico di lavoro effettivo. È consigliabile gestire il problema dell’abbandono della connessione seguendo alcune delle best practice descritte di seguito.
Per prima cosa, i tempi di risposta sui cluster database Aurora PostgreSQL che hanno frequenze elevate di abbandono della connessione possono essere migliorati. A questo scopo, puoi utilizzare un pool di connessioni come RDS Proxy. Un pool di connessioni fornisce una cache di connessioni pronte all'uso per i client. Quasi tutte le versioni di Aurora PostgreSQL supportano RDS Proxy. Per ulteriori informazioni, consulta Amazon RDS Proxy con Aurora PostgreSQL.
Se la tua versione specifica di Aurora PostgreSQL non supporta RDS Proxy, puoi utilizzare un altro pool di connessioni compatibile con PostgreSQL, ad esempio. PgBouncer Per PgBouncer
Per verificare se il cluster database Aurora PostgreSQL può trarne vantaggio dal pooling delle connessioni, puoi controllare il file postgresql.log per verificare la presenza di connessioni e disconnessioni. Puoi anche utilizzare Performance Insights per individuare il numero di abbandoni della connessione che si verificano nel cluster database Aurora PostgreSQL. Di seguito sono disponibili informazioni su entrambi gli argomenti.
Registrazione di connessioni e disconnessioni
I parametri log_connections e log_disconnections PostgreSQL possono acquisire connessioni e disconnessioni all’istanza di scrittura del cluster database Aurora PostgreSQL. Per impostazione predefinita, questi parametro sono disattivati. Per attivare questi parametri, utilizza un gruppo di parametri personalizzati e attivali modificando il valore in 1. Per ulteriori informazioni sui gruppi di parametri, consulta Gruppi di parametri del cluster di database per i cluster di database Amazon Aurora. Per verificare le impostazioni, esegui la connessione all'endpoint del cluster database per Aurora PostgreSQL utilizzando psql ed esegui le query come segue.
labdb=>SELECT setting FROM pg_settings WHERE name = 'log_connections';setting --------- on (1 row)labdb=>SELECT setting FROM pg_settings WHERE name = 'log_disconnections';setting --------- on (1 row)
Con entrambi questi parametri attivati, il registro acquisisce tutte le nuove connessioni e disconnessioni. Per ogni nuova connessione autorizzata, vengono visualizzati utente e database. Al momento della disconnessione, viene registrata anche la durata della sessione, come mostrato nell'esempio seguente.
2022-03-07 21:44:53.978 UTC [16641] LOG: connection authorized: user=labtek database=labdb application_name=psql
2022-03-07 21:44:55.718 UTC [16641] LOG: disconnection: session time: 0:00:01.740 user=labtek database=labdb host=[local]
Per verificare l’abbandono della connessione nell'applicazione, attiva questi parametri se non è già stato fatto. Quindi raccogli i dati nel registro PostgreSQL per l'analisi eseguendo l'applicazione con un carico di lavoro e un periodo di tempo realistici. Puoi visualizzare i file di registro nella console RDS. Scegli l'istanza di scrittura del cluster database Aurora PostgreSQL, quindi seleziona la scheda Logs & events (Log ed eventi). Per ulteriori informazioni, consulta Visualizzazione ed elenco dei file di log del database.
Oppure, puoi scaricare il file di registro dalla console e utilizzare la seguente sequenza di comandi. Questa sequenza individua il numero totale di connessioni autorizzate e interrotte al minuto.
grep "connection authorized\|disconnection: session time:" postgresql.log.2022-03-21-16|\ awk {'print $1,$2}' |\ sort |\ uniq -c |\ sort -n -k1
Nell'output di esempio, è possibile visualizzare un picco nelle connessioni autorizzate seguito da disconnessioni a partire dalle 16:12:10.
.....
,......
.........
5 2022-03-21 16:11:55 connection authorized:
9 2022-03-21 16:11:55 disconnection: session
5 2022-03-21 16:11:56 connection authorized:
5 2022-03-21 16:11:57 connection authorized:
5 2022-03-21 16:11:57 disconnection: session
32 2022-03-21 16:12:10 connection authorized:
30 2022-03-21 16:12:10 disconnection: session
31 2022-03-21 16:12:11 connection authorized:
27 2022-03-21 16:12:11 disconnection: session
27 2022-03-21 16:12:12 connection authorized:
27 2022-03-21 16:12:12 disconnection: session
41 2022-03-21 16:12:13 connection authorized:
47 2022-03-21 16:12:13 disconnection: session
46 2022-03-21 16:12:14 connection authorized:
41 2022-03-21 16:12:14 disconnection: session
24 2022-03-21 16:12:15 connection authorized:
29 2022-03-21 16:12:15 disconnection: session
28 2022-03-21 16:12:16 connection authorized:
24 2022-03-21 16:12:16 disconnection: session
40 2022-03-21 16:12:17 connection authorized:
42 2022-03-21 16:12:17 disconnection: session
40 2022-03-21 16:12:18 connection authorized:
40 2022-03-21 16:12:18 disconnection: session
.....
,......
.........
1 2022-03-21 16:14:10 connection authorized:
1 2022-03-21 16:14:10 disconnection: session
1 2022-03-21 16:15:00 connection authorized:
1 2022-03-21 16:16:00 connection authorized:
Con queste informazioni, puoi decidere se il carico di lavoro può trarre vantaggio da un pool di connessioni. Per analisi più dettagliate, puoi utilizzare Performance Insights.
Rilevamento dell’abbandono della connessione con Performance Insights
È possibile utilizzare Performance Insights per valutare il tasso di abbandono delle connessioni sul cluster DB PostgreSQL-Compatible Aurora Edition. Durante la creazione di un cluster database Aurora PostgreSQL, l'impostazione per Performance Insights è attivata per impostazione predefinita. Se questa scelta è stata deselezionata al momento della creazione del cluster database, modifica il cluster per attivare la funzionalità. Per ulteriori informazioni, consulta Modifica di un cluster database Amazon Aurora.
Con Performance Insights in esecuzione sul cluster database Aurora PostgreSQL, puoi scegliere le metriche che desideri monitorare. Puoi accedere a Performance Insights dal riquadro di navigazione nella console. Puoi anche accedere a Performance Insights dalla scheda Monitoring (Monitoraggio) dell'istanza di scrittura per il cluster database Aurora PostgreSQL, come mostrato nell'immagine seguente.
Dalla console Performance Insights, scegli Manage metrics (Gestisci metriche). Per analizzare l'attività di connessione e disconnessione del cluster database Aurora PostgreSQL, scegli le seguenti metriche. Queste sono tutte metriche di PostgreSQL.
xact_commit: il numero di transazioni confermate.total_auth_attempts: il numero di tentativi di connessione dell'utente autenticate al minuto.numbackends: il numero di backend attualmente connessi al database.
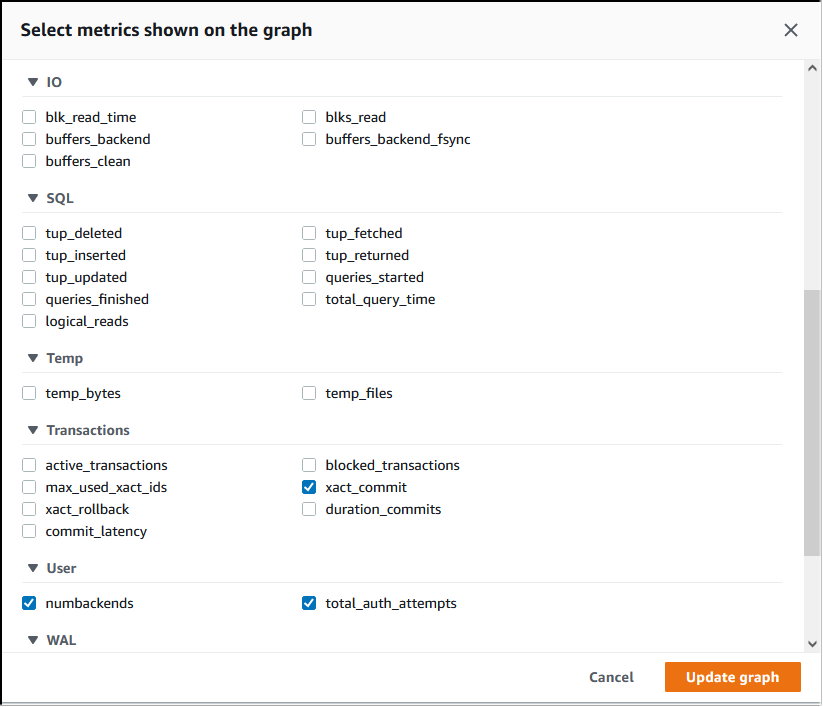
Per salvare le impostazioni e visualizzare l'attività di connessione, scegli Update graph (Aggiorna grafico).
Nell'immagine seguente è visibile l'impatto dell'esecuzione di pgbench con 100 utenti. La linea che mostra le connessioni ha una pendenza costante verso l'alto. Per ulteriori informazioni su pgbench e su come utilizzarlo, consulta pgbench
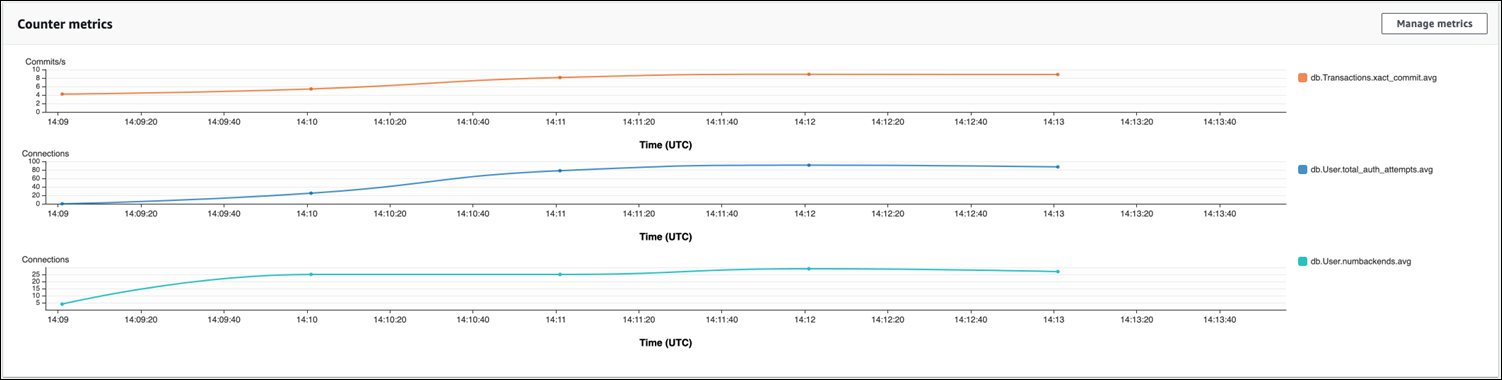
L'immagine mostra che l'esecuzione di un carico di lavoro con un minimo di 100 utenti senza un pool di connessioni può causare un aumento significativo del numero di total_auth_attempts per tutta la durata dell'elaborazione del carico di lavoro. Notare che è meglio mantenere total_auth_attempts più vicino possibile allo zero.
Con il pooling delle connessioni RDS Proxy, i tentativi di connessione aumentano all'inizio del carico di lavoro. Dopo aver impostato il pool di connessioni, la media diminuisce. Le risorse utilizzate dall’uso di transazioni e backend rimangono coerenti per tutta l'elaborazione del carico di lavoro.
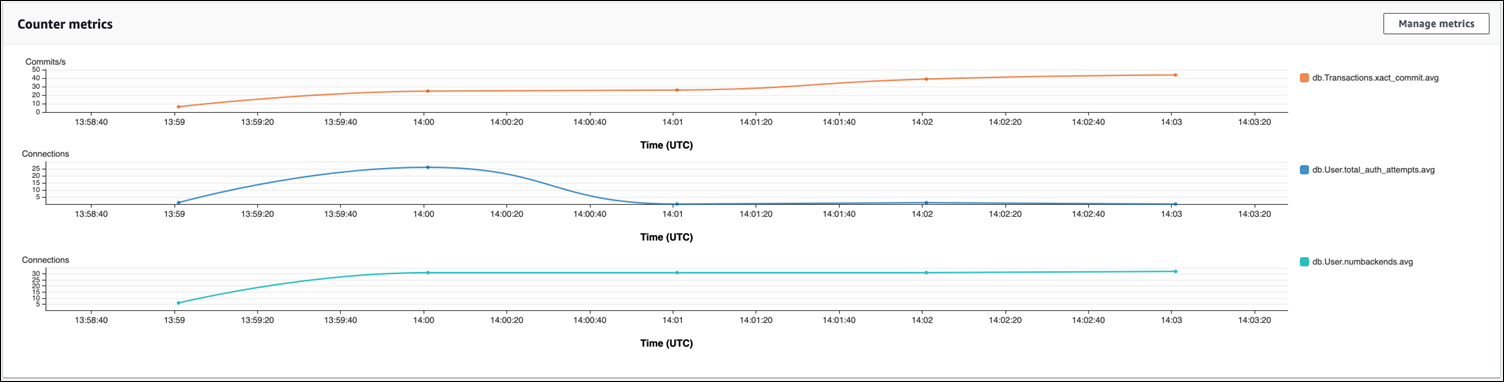
Per ulteriori informazioni sull'utilizzo di Performance Insights con il cluster database Aurora PostgreSQL, consulta Monitoraggio del carico del DB con Performance Insights su Amazon Aurora. Per analizzare le metriche, consulta Analisi delle metriche utilizzando il pannello di controllo Performance Insights.
Dimostrazione dei vantaggi del pooling delle connessioni
Come accennato in precedenza, se si determina che il cluster database Aurora PostgreSQL DB presenta un problema di abbandono della connessione, è possibile utilizzare RDS Proxy per migliorare le prestazioni. Di seguito, è disponibile un esempio che mostra le differenze nell'elaborazione di un carico di lavoro con e senza il pooling delle connessioni. L'esempio utilizza pgbench per modellare il carico di lavoro transazionale.
Analogamente a psql, pgbench è un'applicazione client PostgreSQL che può essere installata ed eseguita dal computer client locale. Può anche essere installata ed eseguita dall'istanza Amazon EC2 utilizzata per gestire il cluster database PostgreSQL Aurora. Per ulteriori informazioni, consulta pgbench
Per procedere con questo esempio, occorre creare innanzitutto l'ambiente pgbench nel database. Il seguente comando è il modello base per inizializzare le tabelle pgbench nel database specificato. Questo esempio utilizza l'account utente principale predefinito,postgres, per l’accesso. Modificarlo secondo necessità per il cluster database Aurora PostgreSQL. L'ambiente pgbench viene creato in un database sull'istanza di scrittura del cluster.
Nota
Il processo di inizializzazione di pgbench elimina e ricrea le tabelle denominate pgbench_accounts, pgbench_branches, pgbench_history e pgbench_tellers. Assicurarsi che il database scelto per dbname
pgbench -U postgres -hdb-cluster-instance-1.111122223333.aws-region.rds.amazonaws.com -p 5432 -d -i -s 50dbname
Per pgbench, specifica i seguenti parametri.
- -d
-
Genera un report di debug durante l'esecuzione di pgbench.
- -h
-
Specifica l’endpoint dell'istanza di scrittura del cluster database Aurora PostgreSQL.
- -i
-
Inizializza l'ambiente pgbench nel database per i test di benchmark.
- -p
-
Identifica la porta utilizzata per le connessioni al database. L'impostazione predefinita per Aurora PostgreSQL è in genere 5432 o 5433.
- -s
-
Specifica il fattore di dimensionamento da utilizzare per compilare le tabelle con righe. Il fattore di dimensionamento predefinito è 1, che genera 1 riga nella tabella
pgbench_branches, 10 righe nella tabellapgbench_tellerse 100000 righe nella tabellapgbench_accounts. - -U
-
Specifica l’account utente per l’istanza di scrittura del cluster database Aurora PostgreSQL.
Dopo aver impostato l'ambiente pgbench, puoi eseguire test di benchmarking con e senza pooling delle connessioni. Il test predefinito consiste in una serie di cinque comandi SELECT, UPDATE e INSERT per transazione che vengono eseguiti ripetutamente per il tempo specificato. Puoi specificare il fattore di dimensionamento, il numero di client e altri dettagli per modellare i tuoi casi d'uso.
Ad esempio, il comando seguente esegue il benchmark per 60 secondi (opzione -T, per il tempo) con 20 connessioni simultanee (l'opzione -c). L'opzione -C determina l’esecuzione del test utilizzando una nuova connessione ogni volta, anziché una volta per sessione client. Questa impostazione fornisce un'indicazione del sovraccarico delle connessioni.
pgbench -h docs-lab-apg-133-test-instance-1.c3zr2auzukpa.us-west-1.rds.amazonaws.com -U postgres -p 5432 -T 60 -c 20 -C labdbPassword:**********pgbench (14.3, server 13.3) starting vacuum...end. transaction type: <builtin: TPC-B (sort of)> scaling factor: 50 query mode: simple number of clients: 20 number of threads: 1 duration: 60 s number of transactions actually processed: 495 latency average = 2430.798 ms average connection time = 120.330 ms tps = 8.227750 (including reconnection times)
L'esecuzione di pgbench sull'istanza di scrittura di un cluster database Aurora PostgreSQL senza riutilizzare le connessioni mostra che vengono elaborate solo circa 8 transazioni al secondo. Ciò fornisce un totale di 495 transazioni durante il test di 1 minuto.
Se si riutilizzano le connessioni, la risposta del cluster database Aurora PostgreSQL per il numero di utenti è quasi 20 volte più veloce. Con il riutilizzo, viene elaborato un totale di 9.042 transazioni rispetto alle 495 nello stesso periodo di tempo e per lo stesso numero di connessioni utente. La differenza è che in quello seguente, ogni connessione viene riutilizzata.
pgbench -h docs-lab-apg-133-test-instance-1.c3zr2auzukpa.us-west-1.rds.amazonaws.com -U postgres -p 5432 -T 60 -c 20 labdbPassword:*********pgbench (14.3, server 13.3) starting vacuum...end. transaction type: <builtin: TPC-B (sort of)> scaling factor: 50 query mode: simple number of clients: 20 number of threads: 1 duration: 60 s number of transactions actually processed: 9042 latency average = 127.880 ms initial connection time = 2311.188 ms tps = 156.396765 (without initial connection time)
Questo esempio mostra che il pooling delle connessioni può migliorare significativamente i tempi di risposta. Per informazioni sulla configurazione di RDS Proxy per il cluster database Aurora PostgreSQL, consulta Server proxy per Amazon RDS per Aurora.
