Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
AWS CLI esempi di Performance Insights
Nelle sezioni seguenti, scopri di più su AWS Command Line Interface (AWS CLI) for Performance Insights ed AWS CLI esempi di utilizzo.
Argomenti
Recupero della media del carico del database per i principali eventi di attesa
Recupero della media del carico del database per il principale SQL
Recupero della media del carico del database filtrata da SQL
Creazione di un report di analisi delle prestazioni per un periodo di tempo
Elenco di tutti i report di analisi delle prestazioni per l'istanza database
Elenco di tutti i tag per un report di analisi delle prestazioni
Eliminazione di tag da un report di analisi delle prestazioni
Built-in aiuto per AWS CLI per Performance Insights
Puoi visualizzare i dati di Performance Insights utilizzando la AWS CLI. È possibile visualizzare la guida per i AWS CLI comandi di Performance Insights immettendo quanto segue nella riga di comando.
aws pi help
Se non lo hai AWS CLI installato, consulta Installazione di AWS CLI nella Guida per l'AWS CLI utente per informazioni sull'installazione.
Recupero dei parametri contatore
Lo screenshot seguente mostra due grafici dei parametri contatore nella AWS Management Console.
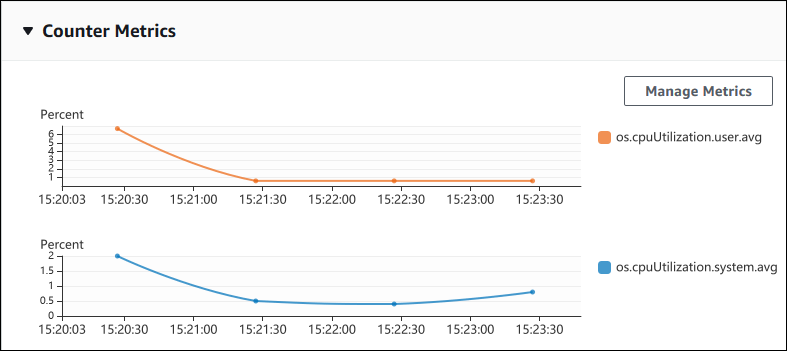
L'esempio seguente mostra come raccogliere gli stessi dati AWS Management Console utilizzati per generare i due grafici contimetrici.
Per Linux, macOS o Unix:
aws pi get-resource-metrics \ --service-type RDS \ --identifier db-ID\ --start-time2018-10-30T00:00:00Z\ --end-time2018-10-30T01:00:00Z\ --period-in-seconds60\ --metric-queries '[{"Metric": "os.cpuUtilization.user.avg" }, {"Metric": "os.cpuUtilization.idle.avg"}]'
Per Windows:
aws pi get-resource-metrics ^ --service-type RDS ^ --identifier db-ID^ --start-time2018-10-30T00:00:00Z^ --end-time2018-10-30T01:00:00Z^ --period-in-seconds60^ --metric-queries '[{"Metric": "os.cpuUtilization.user.avg" }, {"Metric": "os.cpuUtilization.idle.avg"}]'
Puoi agevolare la lettura del comando specificando un file per l'opzione --metrics-query. Il seguente esempio utilizza un file denominato query.json per l'opzione. Il file presenta i seguenti contenuti.
[ { "Metric": "os.cpuUtilization.user.avg" }, { "Metric": "os.cpuUtilization.idle.avg" } ]
Esegui il comando seguente per utilizzare il file.
Per Linux, macOS o Unix:
aws pi get-resource-metrics \ --service-type RDS \ --identifier db-ID\ --start-time2018-10-30T00:00:00Z\ --end-time2018-10-30T01:00:00Z\ --period-in-seconds60\ --metric-queries file://query.json
Per Windows:
aws pi get-resource-metrics ^ --service-type RDS ^ --identifier db-ID^ --start-time2018-10-30T00:00:00Z^ --end-time2018-10-30T01:00:00Z^ --period-in-seconds60^ --metric-queries file://query.json
L'esempio precedente specifica i seguenti valori per le opzioni:
-
--service-type–RDSfor Amazon RDS -
--identifier– L'ID risorsa per l'istanza database -
--start-timee--end-time– I valori ISO 8601DateTimeper il periodo su cui eseguire le query, con supporto di più formati
Esegue query per un intervallo di tempo di un'ora:
-
--period-in-seconds–60per una query al minuto -
--metric-queries– Una serie di due query, ognuna solo per un parametroIl nome del parametro utilizza punti per classificare il parametro in una categoria utile, dove l'ultimo elemento è una funzione. Nell'esempio, la funzione è
avgper ciascuna query. Come per Amazon CloudWatch, le funzioni supportate sonominmax,total, eavg.
La risposta è simile a quella riportata di seguito.
{ "Identifier": "db-XXX", "AlignedStartTime": 1540857600.0, "AlignedEndTime": 1540861200.0, "MetricList": [ { //A list of key/datapoints "Key": { "Metric": "os.cpuUtilization.user.avg" //Metric1 }, "DataPoints": [ //Each list of datapoints has the same timestamps and same number of items { "Timestamp": 1540857660.0, //Minute1 "Value": 4.0 }, { "Timestamp": 1540857720.0, //Minute2 "Value": 4.0 }, { "Timestamp": 1540857780.0, //Minute 3 "Value": 10.0 } //... 60 datapoints for the os.cpuUtilization.user.avg metric ] }, { "Key": { "Metric": "os.cpuUtilization.idle.avg" //Metric2 }, "DataPoints": [ { "Timestamp": 1540857660.0, //Minute1 "Value": 12.0 }, { "Timestamp": 1540857720.0, //Minute2 "Value": 13.5 }, //... 60 datapoints for the os.cpuUtilization.idle.avg metric ] } ] //end of MetricList } //end of response
La risposta presenta un Identifier, un AlignedStartTime e un AlignedEndTime. Poiché il valore --period-in-seconds era 60, l'ora di inizio e fine è stata allineata al minuto. Se --period-in-seconds fosse stato 3600, l'ora di inizio e fine sarebbe stata allineata all'ora.
MetricList nella risposta ha una serie di voci, ciascuna con una voce Key e una voce DataPoints. Ciascun DataPoint ha un Timestamp e un Value. Ciascun elenco Datapoints ha 60 punti di dati in quanto le query sono per dati al minuto nell'arco di un'ora, con Timestamp1/Minute1, Timestamp2/Minute2 e così via, fino a Timestamp60/Minute60.
Poiché la query è per due diversi parametri contatore, la risposta contiene due element MetricList.
Recupero della media del carico del database per i principali eventi di attesa
L'esempio seguente è la stessa query AWS Management Console utilizzata per generare un grafico a linee ad area impilata. L'esempio recupera db.load.avg per l'ultima ora con carico diviso in base ai sette principali eventi di attesa. Il comando è come quello in Recupero dei parametri contatore. Tuttavia, il file query.json presenta i seguenti contenuti.
[ { "Metric": "db.load.avg", "GroupBy": { "Group": "db.wait_event", "Limit": 7 } } ]
Eseguire il comando riportato qui di seguito.
Per Linux, macOS o Unix:
aws pi get-resource-metrics \ --service-type RDS \ --identifier db-ID\ --start-time2018-10-30T00:00:00Z\ --end-time2018-10-30T01:00:00Z\ --period-in-seconds60\ --metric-queries file://query.json
Per Windows:
aws pi get-resource-metrics ^ --service-type RDS ^ --identifier db-ID^ --start-time2018-10-30T00:00:00Z^ --end-time2018-10-30T01:00:00Z^ --period-in-seconds60^ --metric-queries file://query.json
L'esempio specifica il parametro di db.load.avg e un GroupBy dei sette principali eventi di attesa. Per i dettagli sui valori validi per questo esempio, consulta il riferimento DimensionGroupall'API Performance Insights.
La risposta è simile a quella riportata di seguito.
{ "Identifier": "db-XXX", "AlignedStartTime": 1540857600.0, "AlignedEndTime": 1540861200.0, "MetricList": [ { //A list of key/datapoints "Key": { //A Metric with no dimensions. This is the total db.load.avg "Metric": "db.load.avg" }, "DataPoints": [ //Each list of datapoints has the same timestamps and same number of items { "Timestamp": 1540857660.0, //Minute1 "Value": 0.5166666666666667 }, { "Timestamp": 1540857720.0, //Minute2 "Value": 0.38333333333333336 }, { "Timestamp": 1540857780.0, //Minute 3 "Value": 0.26666666666666666 } //... 60 datapoints for the total db.load.avg key ] }, { "Key": { //Another key. This is db.load.avg broken down by CPU "Metric": "db.load.avg", "Dimensions": { "db.wait_event.name": "CPU", "db.wait_event.type": "CPU" } }, "DataPoints": [ { "Timestamp": 1540857660.0, //Minute1 "Value": 0.35 }, { "Timestamp": 1540857720.0, //Minute2 "Value": 0.15 }, //... 60 datapoints for the CPU key ] }, //... In total we have 8 key/datapoints entries, 1) total, 2-8) Top Wait Events ] //end of MetricList } //end of response
In questa risposta, ci sono otto voci in MetricList. C'è una voce per il db.load.avg totale e sette voci ciascuno per il db.load.avg suddivise secondo uno dei sette principali eventi di attesa. A differenza del primo esempio, poiché era presente una dimensione di raggruppamento, deve esserci una chiave per ciascun raggruppamento del parametro. Può esserci una sola chiave per ciascun parametro, come nel caso d'uso del parametro contatore di base.
Recupero della media del carico del database per il principale SQL
L'esempio seguente raggruppa db.wait_events in base alle 10 principali istruzioni SQL. Ci sono due diversi gruppi per le istruzioni SQL:
-
db.sql– L'istruzione SQL completa, comeselect * from customers where customer_id = 123 -
db.sql_tokenized– L'istruzione SQL in formato token, comeselect * from customers where customer_id = ?
Quando si analizzano le prestazioni del database, può essere utile considerare le istruzioni SQL che si differenziano solo per i loro parametri come un unico elemento logico. Pertanto, puoi utilizzare db.sql_tokenized durante le query. Tuttavia, soprattutto se ti interessano piani explain, a volte è più utile esaminare le istruzioni SQL complete con parametri e raggruppamento di query per db.sql. Vi è una relazione padre-figlio tra SQL in formato token e completo, con più SQL completi (figli) raggruppati nello stesso SQL in formato token (padre).
Il comando in questo esempio è simile a quello in Recupero della media del carico del database per i principali eventi di attesa. Tuttavia, il file query.json presenta i seguenti contenuti.
[ { "Metric": "db.load.avg", "GroupBy": { "Group": "db.sql_tokenized", "Limit": 10 } } ]
Nell'esempio seguente viene utilizzato db.sql_tokenized.
Per Linux, macOS o Unix:
aws pi get-resource-metrics \ --service-type RDS \ --identifier db-ID\ --start-time2018-10-29T00:00:00Z\ --end-time2018-10-30T00:00:00Z\ --period-in-seconds3600\ --metric-queries file://query.json
Per Windows:
aws pi get-resource-metrics ^ --service-type RDS ^ --identifier db-ID^ --start-time2018-10-29T00:00:00Z^ --end-time2018-10-30T00:00:00Z^ --period-in-seconds3600^ --metric-queries file://query.json
In questo esempio vengono eseguite query su 24 ore, con un periodo in secondi di un'ora.
L'esempio specifica il parametro di db.load.avg e un GroupBy dei sette principali eventi di attesa. Per i dettagli sui valori validi per questo esempio, consulta il riferimento DimensionGroupall'API Performance Insights.
La risposta è simile a quella riportata di seguito.
{ "AlignedStartTime": 1540771200.0, "AlignedEndTime": 1540857600.0, "Identifier": "db-XXX", "MetricList": [ //11 entries in the MetricList { "Key": { //First key is total "Metric": "db.load.avg" } "DataPoints": [ //Each DataPoints list has 24 per-hour Timestamps and a value { "Value": 1.6964980544747081, "Timestamp": 1540774800.0 }, //... 24 datapoints ] }, { "Key": { //Next key is the top tokenized SQL "Dimensions": { "db.sql_tokenized.statement": "INSERT INTO authors (id,name,email) VALUES\n( nextval(?) ,?,?)", "db.sql_tokenized.db_id": "pi-2372568224", "db.sql_tokenized.id": "AKIAIOSFODNN7EXAMPLE" }, "Metric": "db.load.avg" }, "DataPoints": [ //... 24 datapoints ] }, // In total 11 entries, 10 Keys of top tokenized SQL, 1 total key ] //End of MetricList } //End of response
Questa risposta ha 11 voci in MetricList (1 SQL totale, 10 SQL principali in formato token), dove ciascuna ha 24 DataPoints ogni ora.
Per SQL in formato token, ci sono tre voci in ciascun elenco di dimensioni:
-
db.sql_tokenized.statement– L'istruzione SQL in formato token. -
db.sql_tokenized.db_id– L'ID database nativo utilizzato per fare riferimento a SQL o un ID sintetico che Performance Insights genera nel caso in cui l'ID database nativo non sia disponibile. Questo esempio restituisce l'ID sinteticopi-2372568224. -
db.sql_tokenized.id– L'ID della query all'interno di Performance Insights.Nel AWS Management Console, questo ID è denominato Support ID. Si chiama così perché l'ID è costituito da dati che AWS Support può esaminare per aiutarti a risolvere un problema con il tuo database. AWS prende molto sul serio la sicurezza e la privacy dei dati e quasi tutti i dati vengono archiviati crittografati con la AWS KMS chiave dell'utente. Pertanto, nessuno all'interno AWS può guardare questi dati. Nell'esempio precedente, sia
tokenized.statementchetokenized.db_idvengono archiviati crittografati. Se hai un problema con il tuo database, AWS Support può aiutarti facendo riferimento al Support ID.
Quando si eseguo query, potrebbe essere utile specificare un Group in GroupBy. Tuttavia, per un controllo più dettagliato dei dati restituiti, occorre specificare l'elenco delle dimensioni. Ad esempio, se tutto ciò di cui si necessita è db.sql_tokenized.statement, è possibile aggiungere l'attributo Dimensions al file query.json.
[ { "Metric": "db.load.avg", "GroupBy": { "Group": "db.sql_tokenized", "Dimensions":["db.sql_tokenized.statement"], "Limit": 10 } } ]
Recupero della media del carico del database filtrata da SQL
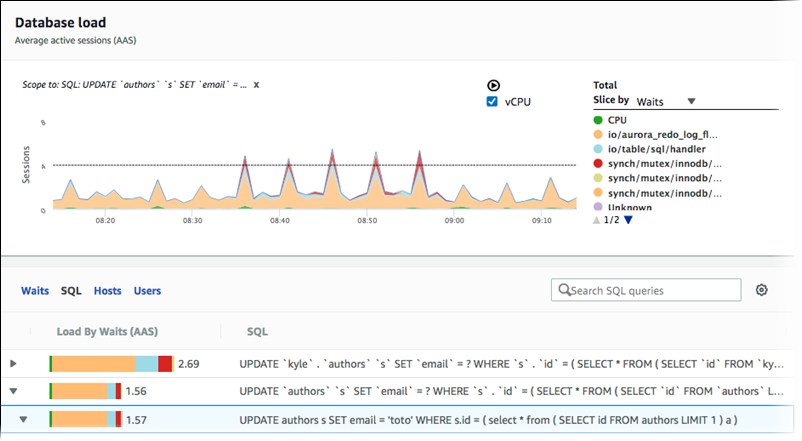
L'immagine precedente mostra che è stata selezionata una particolare query e che il grafico a linee ad area in pila con sessioni attive della media in alto è definito in base a tale query. Sebbene la query sia ancora per i sette principali eventi di attesa complessivi, il valore della risposta è filtrato. Il filtro fa sì che vengano prese in considerazione solo le sessioni che corrispondono al filtro specifico.
La query dell'API corrispondente in questo esempio è simile al comando in Recupero della media del carico del database per il principale SQL. Tuttavia, il file query.json presenta i seguenti contenuti.
[ { "Metric": "db.load.avg", "GroupBy": { "Group": "db.wait_event", "Limit": 5 }, "Filter": { "db.sql_tokenized.id": "AKIAIOSFODNN7EXAMPLE" } } ]
Per Linux, macOS o Unix:
aws pi get-resource-metrics \ --service-type RDS \ --identifier db-ID\ --start-time2018-10-30T00:00:00Z\ --end-time2018-10-30T01:00:00Z\ --period-in-seconds60\ --metric-queries file://query.json
Per Windows:
aws pi get-resource-metrics ^ --service-type RDS ^ --identifier db-ID^ --start-time2018-10-30T00:00:00Z^ --end-time2018-10-30T01:00:00Z^ --period-in-seconds60^ --metric-queries file://query.json
La risposta è simile a quella riportata di seguito.
{ "Identifier": "db-XXX", "AlignedStartTime": 1556215200.0, "MetricList": [ { "Key": { "Metric": "db.load.avg" }, "DataPoints": [ { "Timestamp": 1556218800.0, "Value": 1.4878117913832196 }, { "Timestamp": 1556222400.0, "Value": 1.192823803967328 } ] }, { "Key": { "Metric": "db.load.avg", "Dimensions": { "db.wait_event.type": "io", "db.wait_event.name": "wait/io/aurora_redo_log_flush" } }, "DataPoints": [ { "Timestamp": 1556218800.0, "Value": 1.1360544217687074 }, { "Timestamp": 1556222400.0, "Value": 1.058051341890315 } ] }, { "Key": { "Metric": "db.load.avg", "Dimensions": { "db.wait_event.type": "io", "db.wait_event.name": "wait/io/table/sql/handler" } }, "DataPoints": [ { "Timestamp": 1556218800.0, "Value": 0.16241496598639457 }, { "Timestamp": 1556222400.0, "Value": 0.05163360560093349 } ] }, { "Key": { "Metric": "db.load.avg", "Dimensions": { "db.wait_event.type": "synch", "db.wait_event.name": "wait/synch/mutex/innodb/aurora_lock_thread_slot_futex" } }, "DataPoints": [ { "Timestamp": 1556218800.0, "Value": 0.11479591836734694 }, { "Timestamp": 1556222400.0, "Value": 0.013127187864644107 } ] }, { "Key": { "Metric": "db.load.avg", "Dimensions": { "db.wait_event.type": "CPU", "db.wait_event.name": "CPU" } }, "DataPoints": [ { "Timestamp": 1556218800.0, "Value": 0.05215419501133787 }, { "Timestamp": 1556222400.0, "Value": 0.05805134189031505 } ] }, { "Key": { "Metric": "db.load.avg", "Dimensions": { "db.wait_event.type": "synch", "db.wait_event.name": "wait/synch/mutex/innodb/lock_wait_mutex" } }, "DataPoints": [ { "Timestamp": 1556218800.0, "Value": 0.017573696145124718 }, { "Timestamp": 1556222400.0, "Value": 0.002333722287047841 } ] } ], "AlignedEndTime": 1556222400.0 } //end of response
In questa risposta, tutti i valori sono filtrati in base al contributo di SQL in formato token AKIAIOSFODNN7EXAMPLE specificato nel file query.json. Le chiavi potrebbero inoltre seguire un ordine diverso rispetto a una query senza filtro, in quanto sono i cinque principali eventi di attesa che influenzano l'SQL filtrato.
Recupero del testo completo di un'istruzione SQL
L'esempio seguente recupera il testo completo di un'istruzione SQL per l'istanza database db-10BCD2EFGHIJ3KL4M5NO6PQRS5. --group è db.sql, e --group-identifier è db.sql.id. In questo esempio, my-sql-id rappresenta un ID SQL recuperato richiamando o. pi
get-resource-metrics pi describe-dimension-keys
Eseguire il seguente comando seguente.
Per Linux, macOS o Unix:
aws pi get-dimension-key-details \ --service-type RDS \ --identifier db-10BCD2EFGHIJ3KL4M5NO6PQRS5 \ --group db.sql \ --group-identifiermy-sql-id\ --requested-dimensions statement
Per Windows:
aws pi get-dimension-key-details ^ --service-type RDS ^ --identifier db-10BCD2EFGHIJ3KL4M5NO6PQRS5 ^ --group db.sql ^ --group-identifiermy-sql-id^ --requested-dimensions statement
In questo esempio, sono disponibili i dettagli delle dimensioni. Pertanto, Performance Insights recupera il testo completo dell’istruzione SQL, senza troncarla.
{ "Dimensions":[ { "Value": "SELECT e.last_name, d.department_name FROM employees e, departments d WHERE e.department_id=d.department_id", "Dimension": "db.sql.statement", "Status": "AVAILABLE" }, ... ] }
Creazione di un report di analisi delle prestazioni per un periodo di tempo
L'esempio seguente crea un report di analisi delle prestazioni con l'ora di inizio 1682969503 e l'ora di fine 1682979503 per il database db-loadtest-0.
aws pi create-performance-analysis-report \ --service-type RDS \ --identifier db-loadtest-0 \ --start-time 1682969503 \ --end-time 1682979503 \ --region us-west-2
La risposta è l'identificatore univoco report-0234d3ed98e28fb17 per il report.
{ "AnalysisReportId": "report-0234d3ed98e28fb17" }
Recupero di un report di analisi delle prestazioni
L'esempio seguente recupera i dettagli del report di analisi per il report report-0d99cc91c4422ee61.
aws pi get-performance-analysis-report \ --service-type RDS \ --identifier db-loadtest-0 \ --analysis-report-id report-0d99cc91c4422ee61 \ --region us-west-2
La risposta fornisce lo stato, l’ID, i dettagli temporali e gli approfondimenti del report.
{ "AnalysisReport": { "Status": "Succeeded", "ServiceType": "RDS", "Identifier": "db-loadtest-0", "StartTime": 1680583486.584, "AnalysisReportId": "report-0d99cc91c4422ee61", "EndTime": 1680587086.584, "CreateTime": 1680587087.139, "Insights": [ ... (Condensed for space) ] } }
Elenco di tutti i report di analisi delle prestazioni per l'istanza database
L'esempio seguente elenca tutti i report di analisi delle prestazioni disponibili per il database db-loadtest-0.
aws pi list-performance-analysis-reports \ --service-type RDS \ --identifier db-loadtest-0 \ --region us-west-2
La risposta elenca tutti i report con i dettagli relativi all'ID, allo stato e al periodo di tempo del report.
{ "AnalysisReports": [ { "Status": "Succeeded", "EndTime": 1680587086.584, "CreationTime": 1680587087.139, "StartTime": 1680583486.584, "AnalysisReportId": "report-0d99cc91c4422ee61" }, { "Status": "Succeeded", "EndTime": 1681491137.914, "CreationTime": 1681491145.973, "StartTime": 1681487537.914, "AnalysisReportId": "report-002633115cc002233" }, { "Status": "Succeeded", "EndTime": 1681493499.849, "CreationTime": 1681493507.762, "StartTime": 1681489899.849, "AnalysisReportId": "report-043b1e006b47246f9" }, { "Status": "InProgress", "EndTime": 1682979503.0, "CreationTime": 1682979618.994, "StartTime": 1682969503.0, "AnalysisReportId": "report-01ad15f9b88bcbd56" } ] }
Eliminazione di un report di analisi delle prestazioni
L'esempio seguente elimina il report di analisi per il database db-loadtest-0.
aws pi delete-performance-analysis-report \ --service-type RDS \ --identifier db-loadtest-0 \ --analysis-report-id report-0d99cc91c4422ee61 \ --region us-west-2
Aggiunta di un tag a un report di analisi delle prestazioni
L'esempio seguente aggiunge un tag con una chiave name e un valore test-tag al report report-01ad15f9b88bcbd56.
aws pi tag-resource \ --service-type RDS \ --resource-arn arn:aws:pi:us-west-2:356798100956:perf-reports/RDS/db-loadtest-0/report-01ad15f9b88bcbd56 \ --tags Key=name,Value=test-tag \ --region us-west-2
Elenco di tutti i tag per un report di analisi delle prestazioni
Nell'esempio seguente vengono elencati tutti i tag per il report report-01ad15f9b88bcbd56.
aws pi list-tags-for-resource \ --service-type RDS \ --resource-arn arn:aws:pi:us-west-2:356798100956:perf-reports/RDS/db-loadtest-0/report-01ad15f9b88bcbd56 \ --region us-west-2
La risposta elenca il valore e la chiave per tutti i tag aggiunti al report:
{ "Tags": [ { "Value": "test-tag", "Key": "name" } ] }
Eliminazione di tag da un report di analisi delle prestazioni
Nell'esempio seguente viene eliminato il tag name dal report report-01ad15f9b88bcbd56.
aws pi untag-resource \ --service-type RDS \ --resource-arn arn:aws:pi:us-west-2:356798100956:perf-reports/RDS/db-loadtest-0/report-01ad15f9b88bcbd56 \ --tag-keys name \ --region us-west-2
Dopo che il tag è stato eliminato, se si chiama l'API list-tags-for-resource questo tag non viene elencato.
